
十大經(jīng)典排序算法最強(qiáng)總結(jié)
點(diǎn)擊上方藍(lán)色字體,選擇“標(biāo)星公眾號(hào)”
優(yōu)質(zhì)文章,第一時(shí)間送達(dá)
? 作者?|?郭耀華
來源 |? urlify.cn/VZRfEr
66套java從入門到精通實(shí)戰(zhàn)課程分享
引言
所謂排序,就是使一串記錄,按照其中的某個(gè)或某些關(guān)鍵字的大小,遞增或遞減的排列起來的操作。排序算法,就是如何使得記錄按照要求排列的方法。排序算法在很多領(lǐng)域得到相當(dāng)?shù)刂匾暎绕涫窃诖罅繑?shù)據(jù)的處理方面。一個(gè)優(yōu)秀的算法可以節(jié)省大量的資源。在各個(gè)領(lǐng)域中考慮到數(shù)據(jù)的各種限制和規(guī)范,要得到一個(gè)符合實(shí)際的優(yōu)秀算法,得經(jīng)過大量的推理和分析。
兩年前,我曾在博客園發(fā)布過一篇《十大經(jīng)典排序算法最強(qiáng)總結(jié)(含JAVA代碼實(shí)現(xiàn))》博文,簡要介紹了比較經(jīng)典的十大排序算法,不過在之前的博文中,僅給出了Java版本的代碼實(shí)現(xiàn),并且有一些細(xì)節(jié)上的錯(cuò)誤。所以,今天重新寫一篇文章,深入了解下十大經(jīng)典排序算法的原理及實(shí)現(xiàn)。
簡介
排序算法可以分為內(nèi)部排序和外部排序,內(nèi)部排序是數(shù)據(jù)記錄在內(nèi)存中進(jìn)行排序,而外部排序是因排序的數(shù)據(jù)很大,一次不能容納全部的排序記錄,在排序過程中需要訪問外存。常見的內(nèi)部排序算法有:插入排序、希爾排序、選擇排序、冒泡排序、歸并排序、快速排序、堆排序、基數(shù)排序等,本文只講解內(nèi)部排序算法。用一張圖概括:

圖片名詞解釋:
n:數(shù)據(jù)規(guī)模
k:“桶”的個(gè)數(shù)
In-place:占用常數(shù)內(nèi)存,不占用額外內(nèi)存
Out-place:占用額外內(nèi)存
術(shù)語說明
穩(wěn)定:如果A原本在B前面,而A=B,排序之后A仍然在B的前面。
不穩(wěn)定:如果A原本在B的前面,而A=B,排序之后A可能會(huì)出現(xiàn)在B的后面。
內(nèi)排序:所有排序操作都在內(nèi)存中完成。
外排序:由于數(shù)據(jù)太大,因此把數(shù)據(jù)放在磁盤中,而排序通過磁盤和內(nèi)存的數(shù)據(jù)傳輸才能進(jìn)行。
時(shí)間復(fù)雜度:定性描述一個(gè)算法執(zhí)行所耗費(fèi)的時(shí)間。
空間復(fù)雜度:定性描述一個(gè)算法執(zhí)行所需內(nèi)存的大小。
算法分類
十種常見排序算法可以分類兩大類別:比較類排序和非比較類排序。

常見的快速排序、歸并排序、堆排序以及冒泡排序等都屬于比較類排序算法。比較類排序是通過比較來決定元素間的相對(duì)次序,由于其時(shí)間復(fù)雜度不能突破O(nlogn),因此也稱為非線性時(shí)間比較類排序。在冒泡排序之類的排序中,問題規(guī)模為n,又因?yàn)樾枰容^n次,所以平均時(shí)間復(fù)雜度為O(n2)。在歸并排序、快速排序之類的排序中,問題規(guī)模通過分治法消減為logn次,所以時(shí)間復(fù)雜度平均O(nlogn)。
比較類排序的優(yōu)勢是,適用于各種規(guī)模的數(shù)據(jù),也不在乎數(shù)據(jù)的分布,都能進(jìn)行排序。可以說,比較排序適用于一切需要排序的情況。
而計(jì)數(shù)排序、基數(shù)排序、桶排序則屬于非比較類排序算法。非比較排序不通過比較來決定元素間的相對(duì)次序,而是通過確定每個(gè)元素之前,應(yīng)該有多少個(gè)元素來排序。由于它可以突破基于比較排序的時(shí)間下界,以線性時(shí)間運(yùn)行,因此稱為線性時(shí)間非比較類排序。非比較排序只要確定每個(gè)元素之前的已有的元素個(gè)數(shù)即可,所有一次遍歷即可解決。算法時(shí)間復(fù)雜度O(n)。
非比較排序時(shí)間復(fù)雜度底,但由于非比較排序需要占用空間來確定唯一位置。所以對(duì)數(shù)據(jù)規(guī)模和數(shù)據(jù)分布有一定的要求。
冒泡排序(Bubble Sort)
冒泡排序是一種簡單的排序算法。它重復(fù)地遍歷要排序的序列,依次比較兩個(gè)元素,如果它們的順序錯(cuò)誤就把它們交換過來。遍歷序列的工作是重復(fù)地進(jìn)行直到?jīng)]有再需要交換為止,此時(shí)說明該序列已經(jīng)排序完成。這個(gè)算法的名字由來是因?yàn)樵叫〉脑貢?huì)經(jīng)由交換慢慢“浮”到數(shù)列的頂端。
算法步驟
比較相鄰的元素。如果第一個(gè)比第二個(gè)大,就交換它們兩個(gè);
對(duì)每一對(duì)相鄰元素作同樣的工作,從開始第一對(duì)到結(jié)尾的最后一對(duì),這樣在最后的元素應(yīng)該會(huì)是最大的數(shù);
針對(duì)所有的元素重復(fù)以上的步驟,除了最后一個(gè);
重復(fù)步驟1~3,直到排序完成。
圖解算法

代碼實(shí)現(xiàn)
JAVA
/**
?*?冒泡排序
?*?@param?arr
?*?@return?arr
?*/
public?static?int[]?BubbleSort(int[]?arr)?{
????for?(int?i?=?1;?i?????????//?Set?a?flag,?if?true,?that?means?the?loop?has?not?been?swapped,?
????????//?that?is,?the?sequence?has?been?ordered,?the?sorting?has?been?completed.
????????boolean?flag?=?true;
????????for?(int?j?=?0;?j?????????????if?(arr[j]?>?arr[j?+?1])?{
????????????????int?tmp?=?arr[j];
????????????????arr[j]?=?arr[j?+?1];
????????????????arr[j?+?1]?=?tmp;
???????//?Change?flag
????????????????flag?=?false;
????????????}
????????}
????????if?(flag)?{
????????????break;
????????}
????}
????return?arr;
}
Python
def?BubbleSort(arr):
????for?i?in?range(len(arr)):
????????is_sorted?=?True
????????for?j?in?range(len(arr)-i-1):
????????????if?arr[j]?>?arr[j+1]:
????????????????arr[j],?arr[j+1]?=?arr[j+1],?arr[j]
????????????????is_sorted?=?False
????????if?is_sorted:
????????????break
????return?arr
此處對(duì)代碼做了一個(gè)小優(yōu)化,加入了is_sorted?Flag,目的是將算法的最佳時(shí)間復(fù)雜度優(yōu)化為O(n),即當(dāng)原輸入序列就是排序好的情況下,該算法的時(shí)間復(fù)雜度就是O(n)。
選擇排序(Selection Sort)
選擇排序是一種簡單直觀的排序算法,無論什么數(shù)據(jù)進(jìn)去都是O(n2)的時(shí)間復(fù)雜度。所以用到它的時(shí)候,數(shù)據(jù)規(guī)模越小越好。唯一的好處可能就是不占用額外的內(nèi)存空間了吧。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
算法步驟
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
再從剩余未排序元素中繼續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。
重復(fù)第2步,直到所有元素均排序完畢。
圖解算法
代碼實(shí)現(xiàn)
JAVA
/**
?*?選擇排序
?*?@param?arr
?*?@return?arr
?*/
public?static?int[]?SelectionSort(int[]?arr)?{
????for?(int?i?=?0;?i?????????int?minIndex?=?i;
????????for?(int?j?=?i?+?1;?j?????????????if?(arr[j]?????????????????minIndex?=?j;
????????????}
????????}
????????if?(minIndex?!=?i)?{
????????????int?tmp?=?arr[i];
????????????arr[i]?=?arr[minIndex];
????????????arr[minIndex]?=?tmp;
????????}
????}
????return?arr;
}
Python
def?SelectionSort(arr):
????for?i?in?range(len(arr)-1):
????????#?記錄最小值的索引
????????minIndex?=?i
????????for?j?in?range(i+1,?len(arr)):
????????????if?arr[j]?????????????????minIndex?=?j
????????if?minIndex?!=?i:
????????????arr[i],?arr[minIndex]?=?arr[minIndex],?arr[i]
????return?arr
插入排序(Insertion Sort)
插入排序是一種簡單直觀的排序算法。它的工作原理是通過構(gòu)建有序序列,對(duì)于未排序數(shù)據(jù),在已排序序列中從后向前掃描,找到相應(yīng)位置并插入。插入排序在實(shí)現(xiàn)上,通常采用in-place排序(即只需用到O(1)的額外空間的排序),因而在從后向前掃描過程中,需要反復(fù)把已排序元素逐步向后挪位,為最新元素提供插入空間。
插入排序的代碼實(shí)現(xiàn)雖然沒有冒泡排序和選擇排序那么簡單粗暴,但它的原理應(yīng)該是最容易理解的了,因?yàn)橹灰蜻^撲克牌的人都應(yīng)該能夠秒懂。插入排序是一種最簡單直觀的排序算法,它的工作原理是通過構(gòu)建有序序列,對(duì)于未排序數(shù)據(jù),在已排序序列中從后向前掃描,找到相應(yīng)位置并插入。
插入排序和冒泡排序一樣,也有一種優(yōu)化算法,叫做拆半插入。
算法步驟
從第一個(gè)元素開始,該元素可以認(rèn)為已經(jīng)被排序;
取出下一個(gè)元素,在已經(jīng)排序的元素序列中從后向前掃描;
如果該元素(已排序)大于新元素,將該元素移到下一位置;
重復(fù)步驟3,直到找到已排序的元素小于或者等于新元素的位置;
將新元素插入到該位置后;
重復(fù)步驟2~5。
圖解算法

代碼實(shí)現(xiàn)
JAVA
/**
?*?插入排序
?*?@param?arr
?*?@return?arr
?*/
public?static?int[]?InsertionSort(int[]?arr)?{
????for?(int?i?=?1;?i?????????int?preIndex?=?i?-?1;
????????int?current?=?arr[i];
????????while?(preIndex?>=?0?&&?current?????????????arr[preIndex?+?1]?=?arr[preIndex];
????????????preIndex?-=?1;
????????}
????????arr[preIndex?+?1]?=?current;
????}
????return?arr;
}
Python
def?InsertionSort(arr):
????for?i?in?range(1,?len(arr)):
????????preIndex?=?i-1
????????current?=?arr[i]
????????while?preIndex?>=?0?and?current?????????????arr[preIndex+1]?=?arr[preIndex]
????????????preIndex?-=?1
????????arr[preIndex+1]?=?current
????return?arr
希爾排序(Shell Sort)
希爾排序是希爾(Donald Shell)于1959年提出的一種排序算法。希爾排序也是一種插入排序,它是簡單插入排序經(jīng)過改進(jìn)之后的一個(gè)更高效的版本,也稱為遞減增量排序算法,同時(shí)該算法是沖破O(n2)的第一批算法之一。
希爾排序的基本思想是:先將整個(gè)待排序的記錄序列分割成為若干子序列分別進(jìn)行直接插入排序,待整個(gè)序列中的記錄“基本有序”時(shí),再對(duì)全體記錄進(jìn)行依次直接插入排序。
算法步驟
我們來看下希爾排序的基本步驟,在此我們選擇增量gap=length/2,縮小增量繼續(xù)以gap = gap/2的方式,這種增量選擇我們可以用一個(gè)序列來表示,{n/2, (n/2)/2, ..., 1},稱為增量序列。希爾排序的增量序列的選擇與證明是個(gè)數(shù)學(xué)難題,我們選擇的這個(gè)增量序列是比較常用的,也是希爾建議的增量,稱為希爾增量,但其實(shí)這個(gè)增量序列不是最優(yōu)的。此處我們做示例使用希爾增量。
先將整個(gè)待排序的記錄序列分割成為若干子序列分別進(jìn)行直接插入排序,具體算法描述:
選擇一個(gè)增量序列
{t1, t2, …, tk},其中(ti>tj, i;按增量序列個(gè)數(shù)k,對(duì)序列進(jìn)行k趟排序;
每趟排序,根據(jù)對(duì)應(yīng)的增量
t,將待排序列分割成若干長度為m的子序列,分別對(duì)各子表進(jìn)行直接插入排序。僅增量因子為1時(shí),整個(gè)序列作為一個(gè)表來處理,表長度即為整個(gè)序列的長度。
圖解算法

代碼實(shí)現(xiàn)
JAVA
/**
?*?希爾排序
?*
?*?@param?arr
?*?@return?arr
?*/
public?static?int[]?ShellSort(int[]?arr)?{
????int?n?=?arr.length;
????int?gap?=?n?/?2;
????while?(gap?>?0)?{
????????for?(int?i?=?gap;?i?????????????int?current?=?arr[i];
????????????int?preIndex?=?i?-?gap;
????????????//?Insertion?sort
????????????while?(preIndex?>=?0?&&?arr[preIndex]?>?current)?{
????????????????arr[preIndex?+?gap]?=?arr[preIndex];
????????????????preIndex?-=?gap;
????????????}
????????????arr[preIndex?+?gap]?=?current;
????????}
????????gap?/=?2;
????}
????return?arr;
}
Python
def?ShellSort(arr):
????n?=?len(arr)
????#?初始步長
????gap?=?n?//?2
????while?gap?>?0:
????????for?i?in?range(gap,?n):
????????????#?根據(jù)步長進(jìn)行插入排序
????????????current?=?arr[i]
????????????preIndex?=?i?-?gap
????????????#?插入排序
????????????while?preIndex?>=?0?and?arr[preIndex]?>?current:
????????????????arr[preIndex+gap]?=?arr[preIndex]
????????????????preIndex?-=?gap
????????????arr[preIndex+gap]?=?current
????????#?得到新的步長
????????gap?=?gap?//?2
????return?arr
歸并排序(Merge Sort)
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個(gè)非常典型的應(yīng)用。歸并排序是一種穩(wěn)定的排序方法。將已有序的子序列合并,得到完全有序的序列;即先使每個(gè)子序列有序,再使子序列段間有序。若將兩個(gè)有序表合并成一個(gè)有序表,稱為2-路歸并。
和選擇排序一樣,歸并排序的性能不受輸入數(shù)據(jù)的影響,但表現(xiàn)比選擇排序好的多,因?yàn)槭冀K都是O(nlogn)的時(shí)間復(fù)雜度。代價(jià)是需要額外的內(nèi)存空間。
算法步驟
歸并排序算法是一個(gè)遞歸過程,邊界條件為當(dāng)輸入序列僅有一個(gè)元素時(shí),直接返回,具體過程如下:
如果輸入內(nèi)只有一個(gè)元素,則直接返回,否則將長度為
n的輸入序列分成兩個(gè)長度為n/2的子序列;分別對(duì)這兩個(gè)子序列進(jìn)行歸并排序,使子序列變?yōu)橛行驙顟B(tài);
設(shè)定兩個(gè)指針,分別指向兩個(gè)已經(jīng)排序子序列的起始位置;
比較兩個(gè)指針?biāo)赶虻脑兀x擇相對(duì)小的元素放入到合并空間(用于存放排序結(jié)果),并移動(dòng)指針到下一位置;
重復(fù)步驟3 ~4直到某一指針達(dá)到序列尾;
將另一序列剩下的所有元素直接復(fù)制到合并序列尾。
圖解算法
代碼實(shí)現(xiàn)
JAVA
/**
?*?歸并排序
?*
?*?@param?arr
?*?@return?arr
?*/
public?static?int[]?MergeSort(int[]?arr)?{
????if?(arr.length?<=?1)?{
????????return?arr;
????}
????int?middle?=?arr.length?/?2;
????int[]?arr_1?=?Arrays.copyOfRange(arr,?0,?middle);
????int[]?arr_2?=?Arrays.copyOfRange(arr,?middle,?arr.length);
????return?Merge(MergeSort(arr_1),?MergeSort(arr_2));
}
/**
?*?Merge?two?sorted?arrays
?*?
?*?@param?arr_1
?*?@param?arr_2
?*?@return?sorted_arr
?*/
public?static?int[]?Merge(int[]?arr_1,?int[]?arr_2)?{
????int[]?sorted_arr?=?new?int[arr_1.length?+?arr_2.length];
????int?idx?=?0,?idx_1?=?0,?idx_2?=?0;
????while?(idx_1?????????if?(arr_1[idx_1]?????????????sorted_arr[idx]?=?arr_1[idx_1];
????????????idx_1?+=?1;
????????}?else?{
????????????sorted_arr[idx]?=?arr_2[idx_2];
????????????idx_2?+=?1;
????????}
????????idx?+=?1;
????}
????if?(idx_1?????????while?(idx_1?????????????sorted_arr[idx]?=?arr_1[idx_1];
????????????idx_1?+=?1;
????????????idx?+=?1;
????????}
????}?else?{
????????while?(idx_2?????????????sorted_arr[idx]?=?arr_2[idx_2];
????????????idx_2?+=?1;
????????????idx?+=?1;
????????}
????}
????return?sorted_arr;
}
Python
def?Merge(arr_1,?arr_2):
????sorted_arr?=?[]
????idx_1?=?0
????idx_2?=?0
????while?idx_1?????????if?arr_1[idx_1]?????????????sorted_arr.append(arr_1[idx_1])
????????????idx_1?+=?1
????????else:
????????????sorted_arr.append(arr_2[idx_2])
????????????idx_2?+=?1
????if?idx_1?????????while?idx_1?????????????sorted_arr.append(arr_1[idx_1])
????????????idx_1?+=?1
????else:
????????while?idx_2?????????????sorted_arr.append(arr_2[idx_2])
????????????idx_2?+=?1
????return?sorted_arr
def?MergeSort(arr):
????if?len(arr)?<=?1:
????????return?arr
????mid?=?int(len(arr)/2)
????arr_1,?arr_2?=?arr[:mid],?arr[mid:]
????return?Merge(MergeSort(arr_1),?MergeSort(arr_2))
算法分析
穩(wěn)定性:穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(nlogn) 最差:O(nlogn) 平均:O(nlogn)
空間復(fù)雜度:O(n)
快速排序(Quick Sort)
快速排序用到了分治思想,同樣的還有歸并排序。乍看起來快速排序和歸并排序非常相似,都是將問題變小,先排序子串,最后合并。不同的是快速排序在劃分子問題的時(shí)候經(jīng)過多一步處理,將劃分的兩組數(shù)據(jù)劃分為一大一小,這樣在最后合并的時(shí)候就不必像歸并排序那樣再進(jìn)行比較。但也正因?yàn)槿绱耍瑒澐值牟欢ㄐ允沟每焖倥判虻臅r(shí)間復(fù)雜度并不穩(wěn)定。
快速排序的基本思想:通過一趟排序?qū)⒋判蛄蟹指舫瑟?dú)立的兩部分,其中一部分記錄的元素均比另一部分的元素小,則可分別對(duì)這兩部分子序列繼續(xù)進(jìn)行排序,以達(dá)到整個(gè)序列有序。
算法步驟
快速排序使用分治法(Divide and conquer)策略來把一個(gè)序列分為較小和較大的2個(gè)子序列,然后遞回地排序兩個(gè)子序列。具體算法描述如下:
從序列中隨機(jī)挑出一個(gè)元素,做為 “基準(zhǔn)”(
pivot);重新排列序列,將所有比基準(zhǔn)值小的元素?cái)[放在基準(zhǔn)前面,所有比基準(zhǔn)值大的擺在基準(zhǔn)的后面(相同的數(shù)可以到任一邊)。在這個(gè)操作結(jié)束之后,該基準(zhǔn)就處于數(shù)列的中間位置。這個(gè)稱為分區(qū)(partition)操作;
遞歸地把小于基準(zhǔn)值元素的子序列和大于基準(zhǔn)值元素的子序列進(jìn)行快速排序。
圖解算法
代碼實(shí)現(xiàn)
JAVA
/**
?*?Swap?the?two?elements?of?an?array
?*?@param?array
?*?@param?i
?*?@param?j
?*/
private?static?void?swap(int[]?arr,?int?i,?int?j)?{
????int?tmp?=?arr[i];
????arr[i]?=?arr[j];
????arr[j]?=?tmp;
}
/**
?*?Partition?function
?*?@param?arr
?*?@param?left
?*?@param?right
?*?@return?small_idx
?*/
private?static?int?Partition(int[]?arr,?int?left,?int?right)?{
????if?(left?==?right)?{
????????return?left;
????}
????//?random?pivot
????int?pivot?=?(int)?(left?+?Math.random()?*?(right?-?left?+?1));
????swap(arr,?pivot,?right);
????int?small_idx?=?left;
????for?(int?i?=?small_idx;?i?????????if?(arr[i]?????????????swap(arr,?i,?small_idx);
????????????small_idx++;
????????}
????}
????swap(arr,?small_idx,?right);
????return?small_idx;
}
/**
?*?Quick?sort?function
?*?@param?arr
?*?@param?left
?*?@param?right
?*?@return?arr
?*/
public?static?int[]?QuickSort(int[]?arr,?int?left,?int?right)?{
????if?(left?????????int?pivotIndex?=?Partition(arr,?left,?right);
????????sort(arr,?left,?pivotIndex?-?1);
????????sort(arr,?pivotIndex?+?1,?right);
????}
????return?arr;
}
Python
def?QuickSort(arr,?left=None,?right=None):
????left?=?0?if?left?==?None?else?left
????right?=?len(arr)-1?if?right?==?None?else?right
????if?left?????????pivotIndex?=?Partition(arr,?left,?right)
????????QuickSort(arr,?left,?pivotIndex-1)
????????QuickSort(arr,?pivotIndex+1,?right)
????return?arr
def?Partition(arr,?left,?right):
????if?left?==?right:
????????return?left
????#?隨機(jī)pivot
????swap(arr,?random.randint(left,?right),?right)
????pivot?=?right
????small_idx?=?left
????for?i?in?range(small_idx,?pivot):
????????if?arr[i]?????????????swap(arr,?i,?small_idx)
????????????small_idx?+=?1
????swap(arr,?small_idx,?pivot)
????return?small_idx
def?swap(arr,?i,?j):
????arr[i],?arr[j]?=?arr[j],?arr[i]
算法分析
穩(wěn)定性:不穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(nlogn) 最差:O(nlogn) 平均:O(nlogn)
空間復(fù)雜度:O(nlogn)
堆排序(Heap Sort)
堆排序是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計(jì)的一種排序算法。堆是一個(gè)近似完全二叉樹的結(jié)構(gòu),并同時(shí)滿足堆的性質(zhì):即子結(jié)點(diǎn)的值總是小于(或者大于)它的父節(jié)點(diǎn)。
算法步驟
將初始待排序列
(R1, R2, ……, Rn)構(gòu)建成大頂堆,此堆為初始的無序區(qū);將堆頂元素
R[1]與最后一個(gè)元素R[n]交換,此時(shí)得到新的無序區(qū)(R1, R2, ……, Rn-1)和新的有序區(qū)(Rn),且滿足R[1, 2, ……, n-1]<=R[n];由于交換后新的堆頂
R[1]可能違反堆的性質(zhì),因此需要對(duì)當(dāng)前無序區(qū)(R1, R2, ……, Rn-1)調(diào)整為新堆,然后再次將R[1]與無序區(qū)最后一個(gè)元素交換,得到新的無序區(qū)(R1, R2, ……, Rn-2)和新的有序區(qū)(Rn-1, Rn)。不斷重復(fù)此過程直到有序區(qū)的元素個(gè)數(shù)為n-1,則整個(gè)排序過程完成。
圖解算法
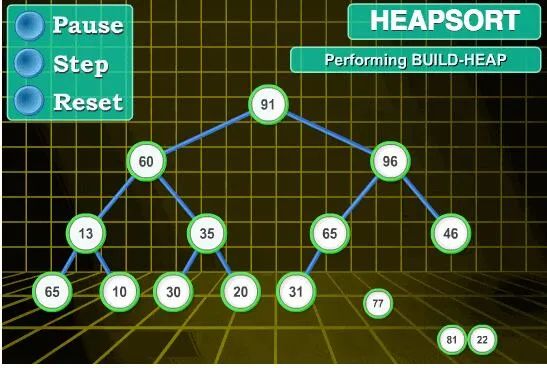
代碼實(shí)現(xiàn)
JAVA
//?Global?variable?that?records?the?length?of?an?array;
static?int?heapLen;
/**
?*?Swap?the?two?elements?of?an?array
?*?@param?arr
?*?@param?i
?*?@param?j
?*/
private?static?void?swap(int[]?arr,?int?i,?int?j)?{
????int?tmp?=?arr[i];
????arr[i]?=?arr[j];
????arr[j]?=?tmp;
}
/**
?*?Build?Max?Heap
?*?@param?arr
?*/
private?static?void?buildMaxHeap(int[]?arr)?{
????for?(int?i?=?arr.length?/?2?-?1;?i?>=?0;?i--)?{
????????heapify(arr,?i);
????}
}
/**
?*?Adjust?it?to?the?maximum?heap
?*?@param?arr
?*?@param?i
?*/
private?static?void?heapify(int[]?arr,?int?i)?{
????int?left?=?2?*?i?+?1;
????int?right?=?2?*?i?+?2;
????int?largest?=?i;
????if?(right??arr[largest])?{
????????largest?=?right;
????}
????if?(left??arr[largest])?{
????????largest?=?left;
????}
????if?(largest?!=?i)?{
????????swap(arr,?largest,?i);
????????heapify(arr,?largest);
????}
}
/**
?*?Heap?Sort
?*?@param?arr
?*?@return
?*/
public?static?int[]?HeapSort(int[]?arr)?{
????//?index?at?the?end?of?the?heap
????heapLen?=?arr.length;
????//?build?MaxHeap
????buildMaxHeap(arr);
????for?(int?i?=?arr.length?-?1;?i?>?0;?i--)?{
????????//?Move?the?top?of?the?heap?to?the?tail?of?the?heap?in?turn
????????swap(arr,?0,?i);
????????heapLen?-=?1;
????????heapify(arr,?0);
????}
????return?arr;
}
Python
def?HeapSort(arr):
????global?heapLen
????#?用于標(biāo)記堆尾部的索引
????heapLen?=?len(arr)
????#?構(gòu)建最大堆
????buildMaxHeap(arr)
????for?i?in?range(len(arr)-1,?0,?-1):
????????#?依次將堆頂移至堆尾
????????swap(arr,?0,?i)
????????heapLen?-=?1
????????heapify(arr,?0)
????return?arr
def?buildMaxHeap(arr):
????for?i?in?range(len(arr)//2-1,?-1,?-1):
????????heapify(arr,?i)
def?heapify(arr,?i):
????left?=?2*i?+?1
????right?=?2*i?+?2
????largest?=?i
????if?right??arr[largest]:
????????largest?=?right
????if?left??arr[largest]:
????????largest?=?left
????if?largest?!=?i:
????????swap(arr,?largest,?i)
????????heapify(arr,?largest)
def?swap(arr,?i,?j):
????arr[i],?arr[j]?=?arr[j],?arr[i]
算法分析
穩(wěn)定性:不穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(nlogn) 最差:O(nlogn) 平均:O(nlogn)
空間復(fù)雜度:O(1)
計(jì)數(shù)排序(Counting Sort)
計(jì)數(shù)排序的核心在于將輸入的數(shù)據(jù)值轉(zhuǎn)化為鍵存儲(chǔ)在額外開辟的數(shù)組空間中。作為一種線性時(shí)間復(fù)雜度的排序,計(jì)數(shù)排序要求輸入的數(shù)據(jù)必須是有確定范圍的整數(shù)。
計(jì)數(shù)排序(Counting sort)是一種穩(wěn)定的排序算法。計(jì)數(shù)排序使用一個(gè)額外的數(shù)組C,其中第i個(gè)元素是待排序數(shù)組A中值等于i的元素的個(gè)數(shù)。然后根據(jù)數(shù)組C來將A中的元素排到正確的位置。它只能對(duì)整數(shù)進(jìn)行排序。
算法步驟
找出數(shù)組中的最大值
max、最小值min;創(chuàng)建一個(gè)新數(shù)組
C,其長度是max-min+1,其元素默認(rèn)值都為0;遍歷原數(shù)組
A中的元素A[i],以A[i]-min作為C數(shù)組的索引,以A[i]的值在A中元素出現(xiàn)次數(shù)作為C[A[i]-min]的值;對(duì)
C數(shù)組變形,新元素的值是該元素與前一個(gè)元素值的和,即當(dāng)i>1時(shí)C[i] = C[i] + C[i-1];創(chuàng)建結(jié)果數(shù)組
R,長度和原始數(shù)組一樣。從后向前遍歷原始數(shù)組
A中的元素A[i],使用A[i]減去最小值min作為索引,在計(jì)數(shù)數(shù)組C中找到對(duì)應(yīng)的值C[A[i]-min],C[A[i]-min]-1就是A[i]在結(jié)果數(shù)組R中的位置,做完上述這些操作,將count[A[i]-min]減小1。
圖解算法

代碼實(shí)現(xiàn)
JAVA
/**
?*?Gets?the?maximum?and?minimum?values?in?the?array
?*?
?*?@param?arr
?*?@return
?*/
private?static?int[]?getMinAndMax(int[]?arr)?{
????int?maxValue?=?arr[0];
????int?minValue?=?arr[0];
????for?(int?i?=?0;?i?????????if?(arr[i]?>?maxValue)?{
????????????maxValue?=?arr[i];
????????}?else?if?(arr[i]?????????????minValue?=?arr[i];
????????}
????}
????return?new?int[]?{?minValue,?maxValue?};
}
/**
?*?Counting?Sort
?*?
?*?@param?arr
?*?@return
?*/
public?static?int[]?CountingSort(int[]?arr)?{
????if?(arr.length?????????return?arr;
????}
????int[]?extremum?=?getMinAndMax(arr);
????int?minValue?=?extremum[0];
????int?maxValue?=?extremum[1];
????int[]?countArr?=?new?int[maxValue?-?minValue?+?1];
????int[]?result?=?new?int[arr.length];
????for?(int?i?=?0;?i?????????countArr[arr[i]?-?minValue]?+=?1;
????}
????for?(int?i?=?1;?i?????????countArr[i]?+=?countArr[i?-?1];
????}
????for?(int?i?=?arr.length?-?1;?i?>=?0;?i--)?{
????????int?idx?=?countArr[arr[i]?-?minValue]?-?1;
????????result[idx]?=?arr[i];
????????countArr[arr[i]?-?minValue]?-=?1;
????}
????return?result;
}
Python
def?CountingSort(arr):
????if?arr.size?????????return?arr
????minValue,?maxValue?=?getMinAndMax(arr)
????countArr?=?[0]*(maxValue-minValue+1)
????resultArr?=?[0]*len(arr)
????for?i?in?range(len(arr)):
????????countArr[arr[i]-minValue]?+=?1
????for?i?in?range(1,?len(countArr)):
????????countArr[i]?+=?countArr[i-1]
????for?i?in?range(len(arr)-1,?-1,?-1):
????????idx?=?countArr[arr[i]-minValue]-1
????????resultArr[idx]?=?arr[i]
????????countArr[arr[i]-minValue]?-=?1
????return?resultArr
def?getMinAndMax(arr):
????maxValue?=?arr[0]
????minValue?=?arr[0]
????for?i?in?range(len(arr)):
????????if?arr[i]?>?maxValue:
????????????maxValue?=?arr[i]
????????elif?arr[i]?????????????minValue?=?arr[i]
????return?minValue,?maxValue
算法分析
當(dāng)輸入的元素是n個(gè)0到k之間的整數(shù)時(shí),它的運(yùn)行時(shí)間是?O(n+k)。計(jì)數(shù)排序不是比較排序,排序的速度快于任何比較排序算法。由于用來計(jì)數(shù)的數(shù)組C的長度取決于待排序數(shù)組中數(shù)據(jù)的范圍(等于待排序數(shù)組的最大值與最小值的差加上1),這使得計(jì)數(shù)排序?qū)τ跀?shù)據(jù)范圍很大的數(shù)組,需要大量額外內(nèi)存空間。
穩(wěn)定性:穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(n+k) 最差:O(n+k) 平均:O(n+k)
空間復(fù)雜度:O(k)
桶排序(Bucket Sort)
桶排序是計(jì)數(shù)排序的升級(jí)版。它利用了函數(shù)的映射關(guān)系,高效與否的關(guān)鍵就在于這個(gè)映射函數(shù)的確定。為了使桶排序更加高效,我們需要做到這兩點(diǎn):
在額外空間充足的情況下,盡量增大桶的數(shù)量
使用的映射函數(shù)能夠?qū)⑤斎氲?N 個(gè)數(shù)據(jù)均勻的分配到 K 個(gè)桶中
桶排序的工作的原理:假設(shè)輸入數(shù)據(jù)服從均勻分布,將數(shù)據(jù)分到有限數(shù)量的桶里,每個(gè)桶再分別排序(有可能再使用別的排序算法或是以遞歸方式繼續(xù)使用桶排序進(jìn)行。
算法步驟
設(shè)置一個(gè)BucketSize,作為每個(gè)桶所能放置多少個(gè)不同數(shù)值;
遍歷輸入數(shù)據(jù),并且把數(shù)據(jù)依次映射到對(duì)應(yīng)的桶里去;
對(duì)每個(gè)非空的桶進(jìn)行排序,可以使用其它排序方法,也可以遞歸使用桶排序;
從非空桶里把排好序的數(shù)據(jù)拼接起來。
圖解算法
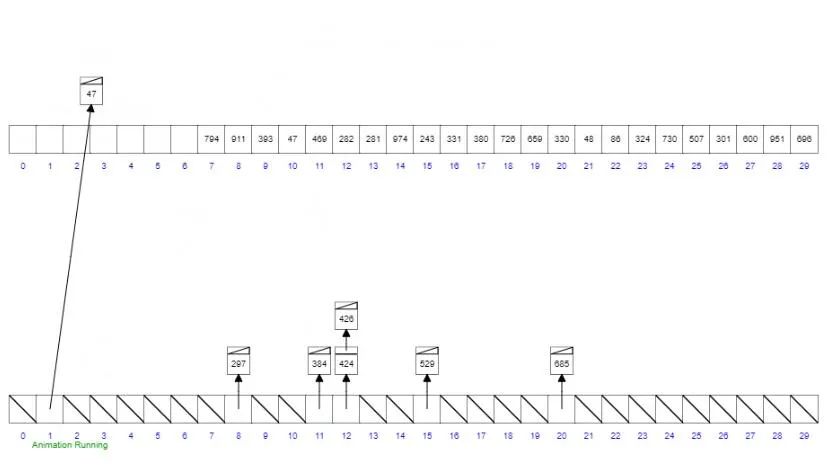
代碼實(shí)現(xiàn)
JAVA
/**
?*?Gets?the?maximum?and?minimum?values?in?the?array
?*?@param?arr
?*?@return
?*/
private?static?int[]?getMinAndMax(List?arr)?{
????int?maxValue?=?arr.get(0);
????int?minValue?=?arr.get(0);
????for?(int?i?:?arr)?{
????????if?(i?>?maxValue)?{
????????????maxValue?=?i;
????????}?else?if?(i?????????????minValue?=?i;
????????}
????}
????return?new?int[]?{?minValue,?maxValue?};
}
/**
?*?Bucket?Sort
?*?@param?arr
?*?@return
?*/
public?static?List?BucketSort(List?arr,?int?bucket_size)?{
????if?(arr.size()?????????return?arr;
????}
????int[]?extremum?=?getMinAndMax(arr);
????int?minValue?=?extremum[0];
????int?maxValue?=?extremum[1];
????int?bucket_cnt?=?(maxValue?-?minValue)?/?bucket_size?+?1;
????List>?buckets?=?new?ArrayList<>();
????for?(int?i?=?0;?i?????????buckets.add(new?ArrayList());
????}
????for?(int?element?:?arr)?{
????????int?idx?=?(element?-?minValue)?/?bucket_size;
????????buckets.get(idx).add(element);
????}
????for?(int?i?=?0;?i?????????if?(buckets.get(i).size()?>?1)?{
????????????buckets.set(i,?sort(buckets.get(i),?bucket_size?/?2));
????????}
????}
????ArrayList?result?=?new?ArrayList<>();
????for?(List?bucket?:?buckets)?{
????????for?(int?element?:?bucket)?{
????????????result.add(element);
????????}
????}
????return?result;
}
Python
def?BucketSort(arr,?bucket_size):
????if?len(arr)?????????return?arr
????minValue,?maxValue?=?getMinAndMax(arr)
????bucket_cnt?=?(maxValue-minValue)//bucket_size+1
????bucket?=?[[]?for?i?in?range(bucket_cnt)]
????for?i?in?range(len(arr)):
????????idx?=?(arr[i]-minValue)?//?bucket_size
????????bucket[idx].append(arr[i])
????for?i?in?range(len(bucket)):
????????if?len(bucket[i])?>?1:
????????????#?遞歸使用桶排序,也可使用其它排序算法
????????????bucket[i]?=?BucketSort(bucket[i],?bucket_size//2)
????result?=?[]
????for?i?in?range(len(bucket)):
????????for?j?in?range(len(bucket[i])):
????????????result.append(bucket[i][j])
????return?result
def?getMinAndMax(arr):
????maxValue?=?arr[0]
????minValue?=?arr[0]
????for?i?in?range(len(arr)):
????????if?arr[i]?>?maxValue:
????????????maxValue?=?arr[i]
????????elif?arr[i]?????????????minValue?=?arr[i]
????return?minValue,?maxValue
算法分析
穩(wěn)定性:穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(n+k) 最差:O(n2) 平均:O(n+k)
空間復(fù)雜度:O(k)
基數(shù)排序(Radix Sort)
基數(shù)排序也是非比較的排序算法,對(duì)元素中的每一位數(shù)字進(jìn)行排序,從最低位開始排序,復(fù)雜度為O(n×k),n為數(shù)組長度,k為數(shù)組中元素的最大的位數(shù);
基數(shù)排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位。有時(shí)候有些屬性是有優(yōu)先級(jí)順序的,先按低優(yōu)先級(jí)排序,再按高優(yōu)先級(jí)排序。最后的次序就是高優(yōu)先級(jí)高的在前,高優(yōu)先級(jí)相同的低優(yōu)先級(jí)高的在前。基數(shù)排序基于分別排序,分別收集,所以是穩(wěn)定的。
算法步驟
取得數(shù)組中的最大數(shù),并取得位數(shù),即為迭代次數(shù)
N(例如:數(shù)組中最大數(shù)值為1000,則N=4);A為原始數(shù)組,從最低位開始取每個(gè)位組成radix數(shù)組;對(duì)
radix進(jìn)行計(jì)數(shù)排序(利用計(jì)數(shù)排序適用于小范圍數(shù)的特點(diǎn));將
radix依次賦值給原數(shù)組;重復(fù)2~4步驟
N次
圖解算法

代碼實(shí)現(xiàn)
JAVA
/**
?*?Radix?Sort
?*?
?*?@param?arr
?*?@return
?*/
public?static?int[]?RadixSort(int[]?arr)?{
????if?(arr.length?????????return?arr;
????}
????int?N?=?1;
????int?maxValue?=?arr[0];
????for?(int?element?:?arr)?{
????????if?(element?>?maxValue)?{
????????????maxValue?=?element;
????????}
????}
????while?(maxValue?/?10?!=?0)?{
????????maxValue?=?maxValue?/?10;
????????N?+=?1;
????}
????for?(int?i?=?0;?i?????????List>?radix?=?new?ArrayList<>();
????????for?(int?k?=?0;?k?????????????radix.add(new?ArrayList());
????????}
????????for?(int?element?:?arr)?{
????????????int?idx?=?(element?/?(int)?Math.pow(10,?i))?%?10;
????????????radix.get(idx).add(element);
????????}
????????int?idx?=?0;
????????for?(List?l?:?radix)?{
????????????for?(int?n?:?l)?{
????????????????arr[idx++]?=?n;
????????????}
????????}
????}
????return?arr;
}
Python
def?RadixSort(arr):
????if?len(arr)?????????return?arr
????maxValue?=?arr[0]
????N?=?1
????for?i?in?range(len(arr)):
????????if?arr[i]?>?maxValue:
????????????maxValue?=?arr[i]
????while?maxValue?//?10?!=?0:
????????maxValue?=?maxValue//10
????????N?+=?1
????for?n?in?range(N):
????????radix?=?[[]?for?i?in?range(10)]
????????for?i?in?range(len(arr)):
????????????idx?=?arr[i]//(10**n)?%?10
????????????radix[idx].append(arr[i])
????????idx?=?0
????????for?j?in?range(len(radix)):
????????????for?k?in?range(len(radix[j])):
????????????????arr[idx]?=?radix[j][k]
????????????????idx?+=?1
????return?arr
算法分析
穩(wěn)定性:穩(wěn)定
時(shí)間復(fù)雜度:最佳:O(n×k) 最差:O(n×k) 平均:O(n×k)
空間復(fù)雜度:O(n+k)
基數(shù)排序 vs 計(jì)數(shù)排序 vs 桶排序
這三種排序算法都利用了桶的概念,但對(duì)桶的使用方法上有明顯差異:
基數(shù)排序:根據(jù)鍵值的每位數(shù)字來分配桶
計(jì)數(shù)排序:每個(gè)桶只存儲(chǔ)單一鍵值
桶排序:每個(gè)桶存儲(chǔ)一定范圍的數(shù)值
粉絲福利:Java從入門到入土學(xué)習(xí)路線圖
???

?長按上方微信二維碼?2 秒
感謝點(diǎn)贊支持下哈?