
【算法基礎(chǔ)】十大經(jīng)典排序算法(動(dòng)圖)
算法分類
冒泡排序(重點(diǎn))
選擇排序
插入排序
歸并排序(重點(diǎn))
快速排序(重點(diǎn))
堆排序(重點(diǎn))
計(jì)數(shù)排序
基數(shù)排序
文末有學(xué)習(xí)資料免費(fèi)分享~
算法分類
十種常見排序算法可以分為兩大類:
比較類排序:通過比較來決定元素間的相對(duì)次序,由于其時(shí)間復(fù)雜度不能突破O(nlogn),因此也稱為非線性時(shí)間比較類排序。非比較類排序:不通過比較來決定元素間的相對(duì)次序,它可以突破基于比較排序的時(shí)間下界,以線性時(shí)間運(yùn)行,因此也稱為線性時(shí)間非比較類排序。
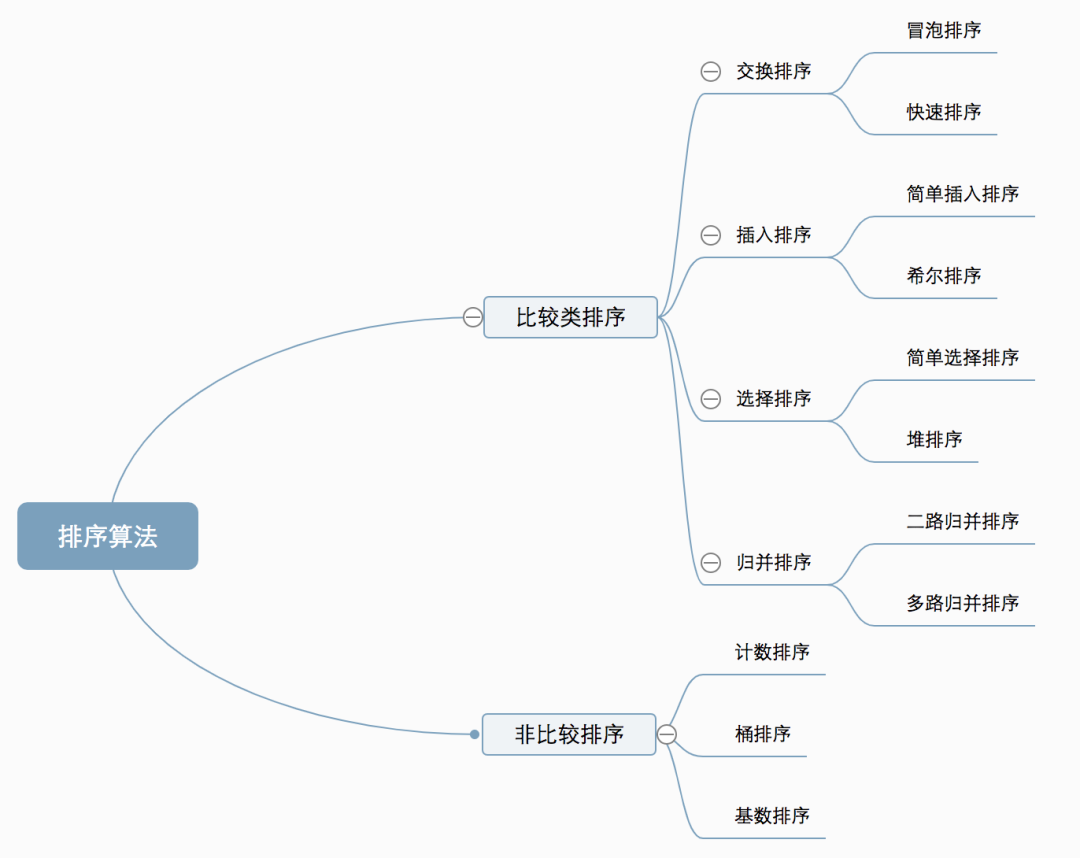
【算法復(fù)雜度】
【相關(guān)概念】
穩(wěn)定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。 不穩(wěn)定:如果a原本在b的前面,而a=b,排序之后 a 可能會(huì)出現(xiàn)在 b 的后面。 時(shí)間復(fù)雜度:對(duì)排序數(shù)據(jù)的總的操作次數(shù)。反映當(dāng)n變化時(shí),操作次數(shù)呈現(xiàn)什么規(guī)律。 **空間復(fù)雜度:**是指算法在計(jì)算機(jī)內(nèi)執(zhí)行時(shí)所需存儲(chǔ)空間的度量,它也是數(shù)據(jù)規(guī)模n的函數(shù)。
冒泡排序(重點(diǎn))
Bubble Sort
【算法描述】
比較相鄰的元素。如果第一個(gè)比第二個(gè)大,就交換它們兩個(gè); 對(duì)每一對(duì)相鄰元素作同樣的工作,從開始第一對(duì)到結(jié)尾的最后一對(duì),這樣在最后的元素應(yīng)該會(huì)是最大的數(shù); 針對(duì)所有的元素重復(fù)以上的步驟,除了最后一個(gè); 重復(fù)步驟1~3,直到排序完成。
【動(dòng)圖演示】
選擇排序
Selection Sort 表現(xiàn)最穩(wěn)定的排序算法之一,因?yàn)闊o(wú)論什么數(shù)據(jù)進(jìn)去都是O(n2)的時(shí)間復(fù)雜度,所以用到它的時(shí)候,數(shù)據(jù)規(guī)模越小越好。唯一的好處可能就是不占用額外的內(nèi)存空間了吧。理論上講,選擇排序可能也是平時(shí)排序一般人想到的最多的排序方法了吧。【算法描述】
選擇排序(Selection-sort)是一種簡(jiǎn)單直觀的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再?gòu)氖S辔磁判蛟刂欣^續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
【動(dòng)圖演示】
插入排序
Insertion Sort
【算法描述】
一般來說,插入排序都采用in-place在數(shù)組上實(shí)現(xiàn)。具體算法描述如下:
從第一個(gè)元素開始,該元素可以認(rèn)為已經(jīng)被排序; 取出下一個(gè)元素,在已經(jīng)排序的元素序列中從后向前掃描; 如果該元素(已排序)大于新元素,將該元素移到下一位置; 重復(fù)步驟3,直到找到已排序的元素小于或者等于新元素的位置; 將新元素插入到該位置后; 重復(fù)步驟2~5。
【動(dòng)圖演示】
歸并排序(重點(diǎn))
Merge Sort 歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個(gè)非常典型的應(yīng)用。將已有序的子序列合并,得到完全有序的序列;即先使每個(gè)子序列有序,再使子序列段間有序。若將兩個(gè)有序表合并成一個(gè)有序表,稱為2-路歸并。 是遞歸的思想 歸并排序是一種穩(wěn)定的排序方法。和選擇排序一樣,歸并排序的性能不受輸入數(shù)據(jù)的影響,但表現(xiàn)比選擇排序好的多,因?yàn)槭冀K都是O(nlogn)的時(shí)間復(fù)雜度。代價(jià)是需要額外的內(nèi)存空間。【算法描述】 把長(zhǎng)度為n的輸入序列分成兩個(gè)長(zhǎng)度為n/2的子序列; 對(duì)這兩個(gè)子序列分別采用歸并排序; 將兩個(gè)排序好的子序列合并成一個(gè)最終的排序序列。
【動(dòng)圖演示】
快速排序(重點(diǎn))
Quite Sort 快速排序的基本思想:通過一趟排序?qū)⒋庞涗浄指舫瑟?dú)立的兩部分,其中一部分記錄的關(guān)鍵字均比另一部分的關(guān)鍵字小,則可分別對(duì)這兩部分記錄繼續(xù)進(jìn)行排序,以達(dá)到整個(gè)序列有序。 之前一直以為快排和二分法有關(guān),但是其實(shí)是分治法的應(yīng)用。
【算法描述】
快速排序使用分治法來把一個(gè)串(list)分為兩個(gè)子串(sub-lists)。具體算法描述如下:
從數(shù)列中挑出一個(gè)元素,稱為 “基準(zhǔn)”(pivot); 重新排序數(shù)列,所有元素比基準(zhǔn)值小的擺放在基準(zhǔn)前面,所有元素比基準(zhǔn)值大的擺在基準(zhǔn)的后面(相同的數(shù)可以到任一邊)。在這個(gè)分區(qū)退出之后,該基準(zhǔn)就處于數(shù)列的中間位置。這個(gè)稱為分區(qū)(partition)操作; 遞歸地(recursive)把小于基準(zhǔn)值元素的子數(shù)列和大于基準(zhǔn)值元素的子數(shù)列排序。
【動(dòng)圖演示】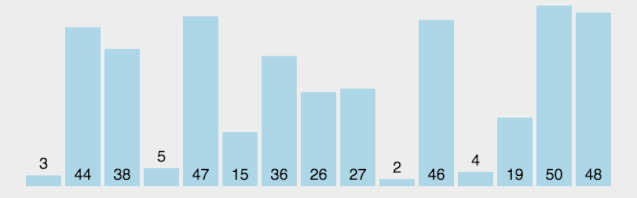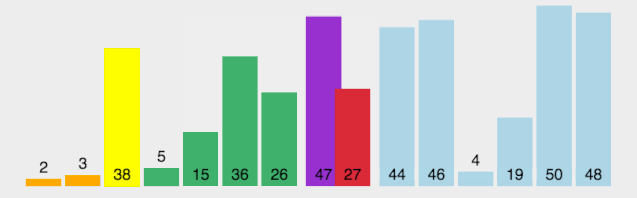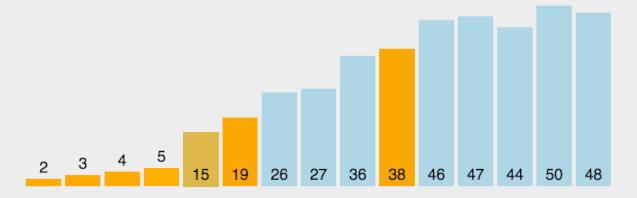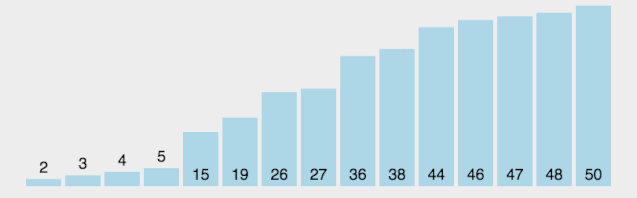
堆排序(重點(diǎn))
python中sort排序的方法就是堆排序 堆排序(Heapsort)是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計(jì)的一種排序算法。堆積是一個(gè)近似完全二叉樹的結(jié)構(gòu),并同時(shí)滿足堆積的性質(zhì):即子結(jié)點(diǎn)的鍵值或索引總是小于(或者大于)它的父節(jié)點(diǎn)。
【算法描述】
這個(gè)比較復(fù)雜。先看動(dòng)圖然后慢慢細(xì)說。
【動(dòng)圖演示】
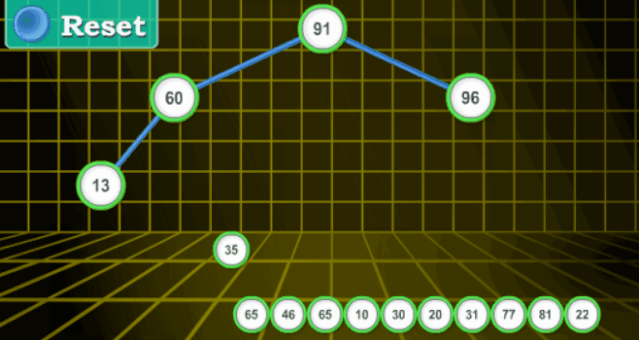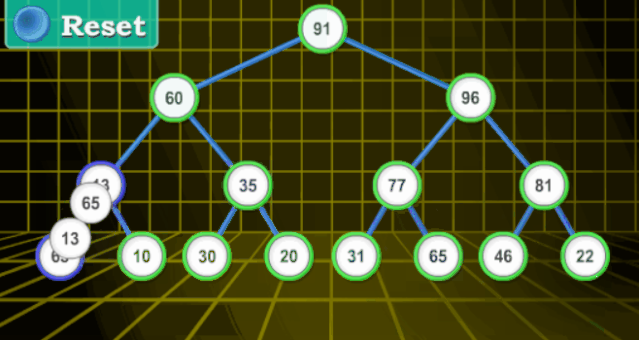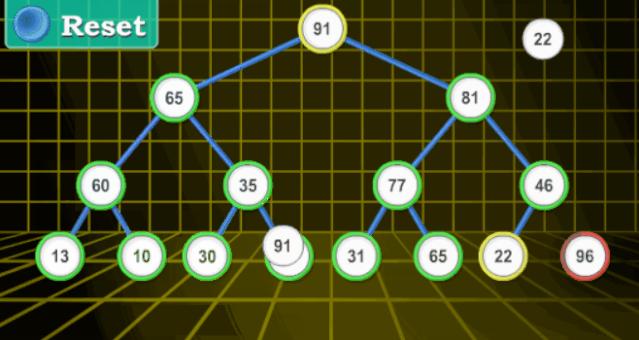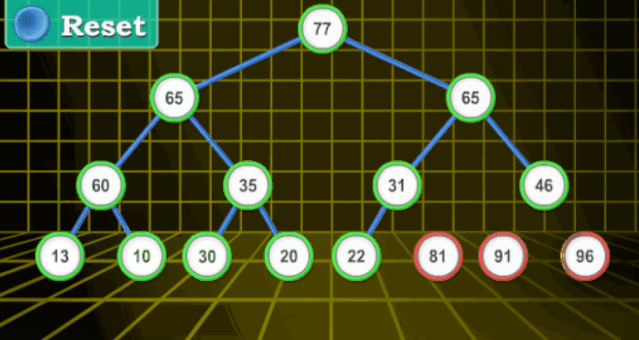
【分步詳解】
堆(二叉堆)可以視為一棵完全的二叉樹。完全二叉樹的一個(gè)優(yōu)秀的性質(zhì)就是,除了最底層之外,每一層都是滿的
二叉堆一般分為兩種:最大堆和最小堆。
最大堆 :最大堆中的最大元素在根結(jié)點(diǎn)(堆頂);堆中每個(gè)父節(jié)點(diǎn)的元素值都大于等于其子結(jié)點(diǎn)(如果子節(jié)點(diǎn)存在)
最小堆:最小堆中的最小元素出現(xiàn)在根結(jié)點(diǎn)(堆頂);堆中每個(gè)父節(jié)點(diǎn)的元素值都小于等于其子結(jié)點(diǎn)(如果子節(jié)點(diǎn)存在)
假設(shè)我們要對(duì)目標(biāo)數(shù)組A {57, 40, 38, 11, 13, 34, 48, 75, 6, 19, 9, 7}進(jìn)行堆排序。
首先第一步和第二步,創(chuàng)建堆,這里我們用最大堆;創(chuàng)建過程中,保證調(diào)整堆的特性。從最后一個(gè)分支的節(jié)點(diǎn)開始進(jìn)行調(diào)整為最大堆。
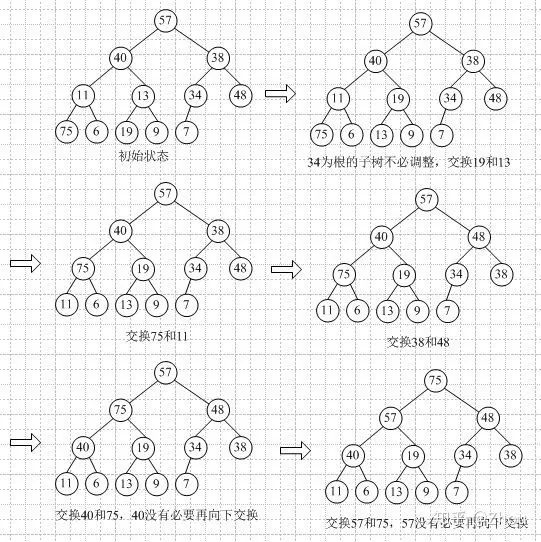
現(xiàn)在得到的最大堆的存儲(chǔ)結(jié)構(gòu)如下:
接著,最后一步,堆排序,進(jìn)行(n-1)次循環(huán)。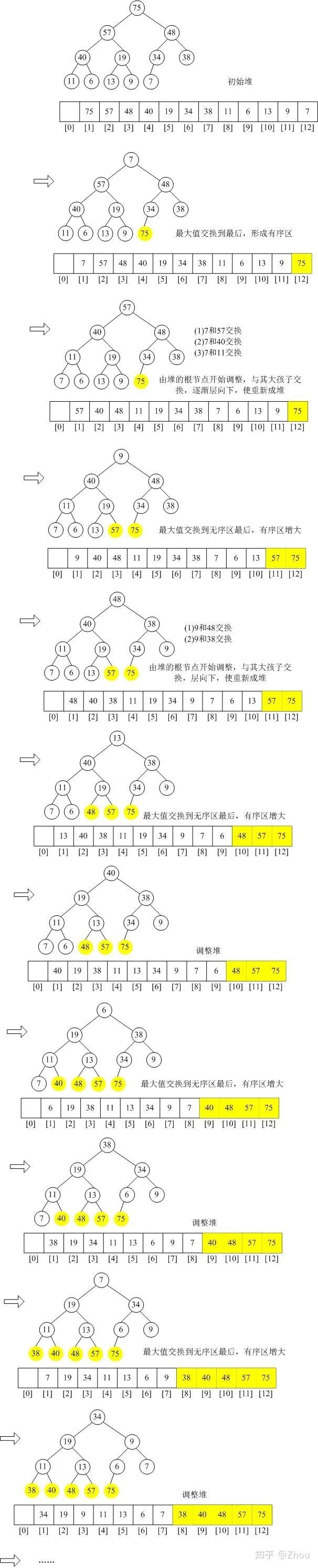
這個(gè)迭代持續(xù)直至最后一個(gè)元素即完成堆排序步驟。
【個(gè)人理解】
通過堆這個(gè)結(jié)構(gòu),讓隨機(jī)兩個(gè)數(shù)組進(jìn)行比大小,然后讓獲勝者之間再比大小,這樣就可以通過復(fù)雜都logn得到一個(gè)最大的數(shù)字。然后不考慮這個(gè)數(shù)字,在剩下的數(shù)字中重復(fù)這個(gè)過程。有點(diǎn)類似比賽半決賽,四分之一決賽,八強(qiáng)這樣的感覺。
計(jì)數(shù)排序
Counting Sort 計(jì)數(shù)排序不是基于比較的排序算法,其核心在于將輸入的數(shù)據(jù)值轉(zhuǎn)化為鍵存儲(chǔ)在額外開辟的數(shù)組空間中。作為一種線性時(shí)間復(fù)雜度的排序,計(jì)數(shù)排序要求輸入的數(shù)據(jù)必須是有確定范圍的整數(shù)。敲黑板!計(jì)數(shù)排序不是基于比較的,所以是線性時(shí)間復(fù)雜度,但是速度快的代價(jià)就是對(duì)輸入數(shù)據(jù)有限制要求:確定范圍的整數(shù)
【算法描述】
這部分不怎么用看,直接看動(dòng)圖就理解了
找出待排序的數(shù)組中最大和最小的元素; 統(tǒng)計(jì)數(shù)組中每個(gè)值為i的元素出現(xiàn)的次數(shù),存入數(shù)組C的第i項(xiàng); 對(duì)所有的計(jì)數(shù)累加(從C中的第一個(gè)元素開始,每一項(xiàng)和前一項(xiàng)相加); 反向填充目標(biāo)數(shù)組:將每個(gè)元素i放在新數(shù)組的第C(i)項(xiàng),每放一個(gè)元素就將C(i)減去1。
【動(dòng)圖演示】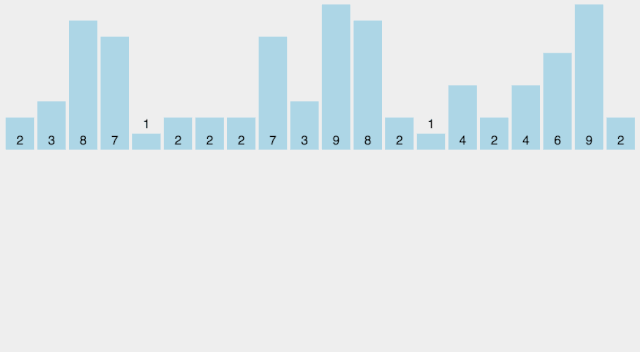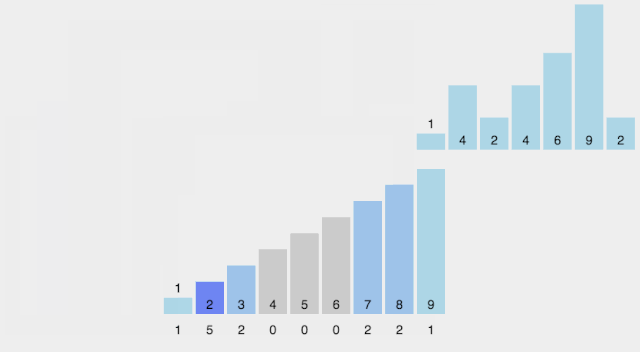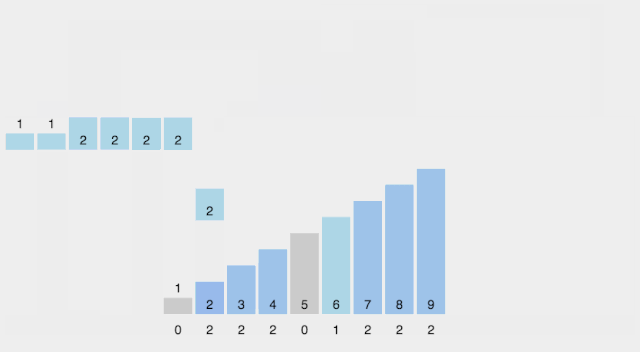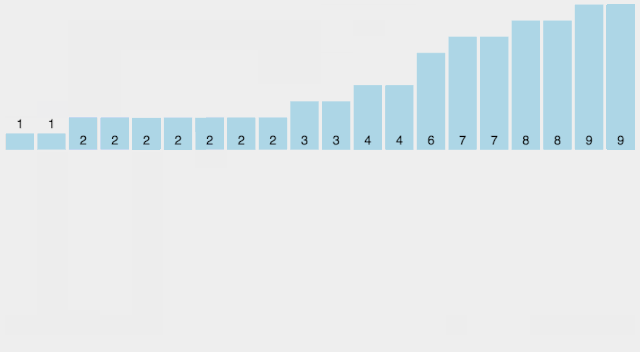
基數(shù)排序
Radix Sort 基數(shù)排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位。**有時(shí)候有些屬性是有優(yōu)先級(jí)順序的,先按低優(yōu)先級(jí)排序,再按高優(yōu)先級(jí)排序。**最后的次序就是高優(yōu)先級(jí)高的在前,高優(yōu)先級(jí)相同的低優(yōu)先級(jí)高的在前。
【算法描述】
取得數(shù)組中的最大數(shù),并取得位數(shù); arr為原始數(shù)組,從最低位開始取每個(gè)位組成radix數(shù)組; 對(duì)radix進(jìn)行計(jì)數(shù)排序(利用計(jì)數(shù)排序適用于小范圍數(shù)的特點(diǎn));
【動(dòng)圖演示】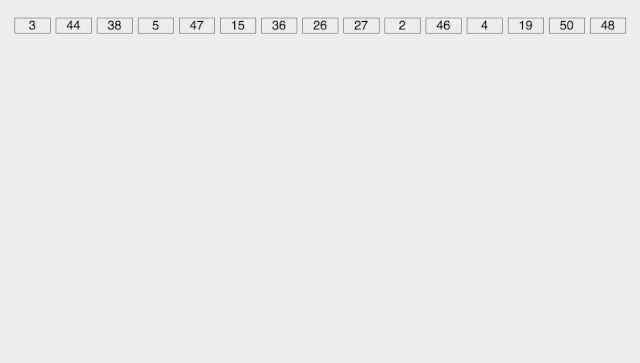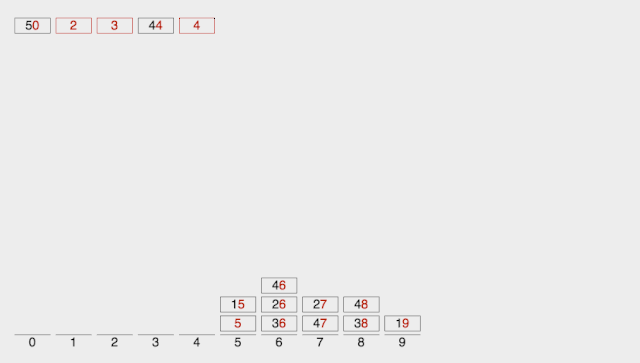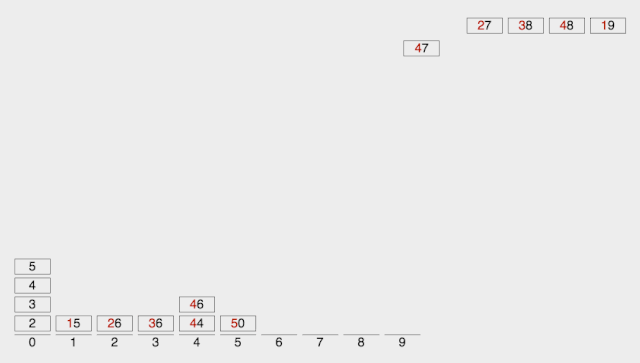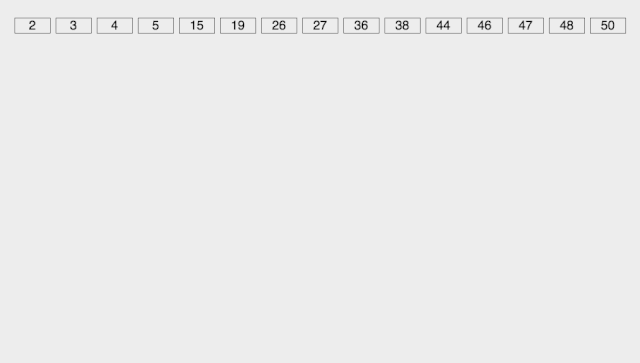
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群: