
數(shù)據(jù)分析之缺失值處理(方法+代碼)
圣人曾說過:數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個上限而已。
再好的模型,如果沒有好的數(shù)據(jù)和特征質(zhì)量,那訓(xùn)練出來的效果也不會有所提高。數(shù)據(jù)質(zhì)量對于數(shù)據(jù)分析而言是至關(guān)重要的,有時候它的意義會在某種程度上會勝過模型算法。
https://blog.csdn.net/SeafyLiang/article/details/115671683
數(shù)據(jù)缺失的原因
首先我們應(yīng)該知道:**數(shù)據(jù)為什么缺失?**數(shù)據(jù)的缺失是我們無法避免的,可能的原因有很多種,博主總結(jié)有以下三大類:
- 無意的:信息被遺漏,比如由于工作人員的疏忽,忘記而缺失;或者由于數(shù)據(jù)采集器等故障等原因造成的缺失,比如系統(tǒng)實時性要求較高的時候,機(jī)器來不及判斷和決策而造成缺失;- ?有意的:有些數(shù)據(jù)集在特征描述中會規(guī)定將缺失值也作為一種特征值,這時候缺失值就可以看作是一種特殊的特征值;- ?不存在:有些特征屬性根本就是不存在的,比如一個未婚者的配偶名字就沒法填寫,再如一個孩子的收入狀況也無法填寫;總而言之,對于造成缺失值的原因,我們需要明確:是因為疏忽或遺漏無意而造成的,還是說故意造成的,或者說根本不存在。只有知道了它的來源,我們才能對癥下藥,做相應(yīng)的處理。
數(shù)據(jù)缺失的類型
在對缺失數(shù)據(jù)進(jìn)行處理前,了解數(shù)據(jù)缺失的機(jī)制和形式是十分必要的。將數(shù)據(jù)集中不含缺失值的變量稱為完全變量,數(shù)據(jù)集中含有缺失值的變量稱為不完全變量。而從缺失的分布來將缺失可以分為完全隨機(jī)缺失,隨機(jī)缺失和完全非隨機(jī)缺失。
- 完全隨機(jī)缺失(missing completely at random,MCAR):指的是數(shù)據(jù)的缺失是完全隨機(jī)的,不依賴于任何不完全變量或完全變量,不影響樣本的無偏性,如家庭地址缺失;- ?隨機(jī)缺失(missing at random,MAR):指的是數(shù)據(jù)的缺失不是完全隨機(jī)的,即該類數(shù)據(jù)的缺失依賴于其他完全變量,如財務(wù)數(shù)據(jù)缺失情況與企業(yè)的大小有關(guān);- ?非隨機(jī)缺失(missing not at random,MNAR):指的是數(shù)據(jù)的缺失與不完全變量自身的取值有關(guān),如高收入人群不原意提供家庭收入;對于隨機(jī)缺失和非隨機(jī)缺失,直接刪除記錄是不合適的,原因上面已經(jīng)給出。隨機(jī)缺失可以通過已知變量對缺失值進(jìn)行估計,而非隨機(jī)缺失的非隨機(jī)性還沒有很好的解決辦法。
缺失處理
方式1:刪除
直接去除含有缺失值的記錄,這種處理方式是簡單粗暴的,適用于數(shù)據(jù)量較大(記錄較多)且缺失比較較小的情形,去掉后對總體影響不大。一般不建議這樣做,因為很可能會造成數(shù)據(jù)丟失、數(shù)據(jù)偏移。
func:?df.dropna(axis=0,?how='any',?thresh=None,?subset=None,?inplace=False)
#?1、刪除‘a(chǎn)ge’列
df.drop('age',?axis=1,?inplace=True)
#?2、刪除數(shù)據(jù)表中含有空值的行
df.dropna()
#?3、丟棄某幾列有缺失值的行
df.dropna(axis=0,?subset=['a','b'],?inplace=True)
直接去除缺失變量,基于第一步我們已經(jīng)知道每個變量的缺失比例,如果一個變量的缺失比例過高,基本也就失去了預(yù)測意義,這樣的變量我們可以嘗試把它直接去掉。
#?去掉缺失比例大于80%以上的變量
data=data.dropna(thresh=len(data)*0.2,?axis=1)
方式2:常量填充
在進(jìn)行缺失值填充之前,我們要先對缺失的變量進(jìn)行業(yè)務(wù)上的了解,即變量的含義、獲取方式、計算邏輯,以便知道該變量為什么會出現(xiàn)缺失值、缺失值代表什么含義。比如,‘a(chǎn)ge’ 年齡缺失,每個人均有年齡,缺失應(yīng)該為隨機(jī)的缺失,‘loanNum’貸款筆數(shù),缺失可能代表無貸款,是有實在意義的缺失。全局常量填充:可以用0,均值、中位數(shù)、眾數(shù)等填充。平均值適用于近似正態(tài)分布數(shù)據(jù),觀測值較為均勻散布均值周圍;中位數(shù)適用于偏態(tài)分布或者有離群點數(shù)據(jù),中位數(shù)是更好地代表數(shù)據(jù)中心趨勢;眾數(shù)一般用于類別變量,無大小、先后順序之分。
#?均值填充
data['col']?=?data['col'].fillna(data['col'].means())
#?中位數(shù)填充
data['col']?=?data['col'].fillna(data['col'].median())
#?眾數(shù)填充
data['col']?=?data['col'].fillna(stats.mode(data['col'])[0][0])
也可以借助Imputer類處理缺失:
from?sklearn.preprocessing?import?Imputer
imr?=?Imputer(missing_values='NaN',?strategy='mean',?axis=0)
imputed_data?=pd.DataFrame(imr.fit_transform(df.values),columns=df.columns)
imputed_data
方式3:插值填充
采用某種插入模式進(jìn)行填充,比如取缺失值前后值的均值進(jìn)行填充:
#? interpolate()插值法,缺失值前后數(shù)值的均值,但是若缺失值前后也存在缺失,則不進(jìn)行計算插補(bǔ)。
df['c']?=?df['c'].interpolate()
#?用前面的值替換,?當(dāng)?shù)谝恍杏腥笔е禃r,該行利用向前替換無值可取,仍缺失
df.fillna(method='pad')
#?用后面的值替換,當(dāng)最后一行有缺失值時,該行利用向后替換無值可取,仍缺失
df.fillna(method='backfill')#用后面的值替換
下述2個方式需要先處理數(shù)據(jù)
#?需要先對a列數(shù)據(jù)做插值填充,后續(xù)作為訓(xùn)練數(shù)據(jù)
df['a']?=?df['a'].interpolate()
#?拆分空數(shù)據(jù)和非空數(shù)據(jù)
df_notnull?=?df[df.is_fill==0]?#?非空數(shù)據(jù)
df_null?=?df[df.is_fill==1]?#?空數(shù)據(jù)
x_train?=?df_notnull[['b',?'a']]?#?訓(xùn)練數(shù)據(jù)x,?a,b列
y_train?=?df_notnull['c']?#?訓(xùn)練數(shù)據(jù)y,?c列(目標(biāo))
test?=?df_null[['b',?'a']]?#?預(yù)測數(shù)據(jù)x,?a,b列
方式4:KNN填充
利用knn算法填充,其實是把目標(biāo)列當(dāng)做目標(biāo)標(biāo)量,利用非缺失的數(shù)據(jù)進(jìn)行knn算法擬合,最后對目標(biāo)列缺失進(jìn)行預(yù)測。(對于連續(xù)特征一般是加權(quán)平均,對于離散特征一般是加權(quán)投票) sklearn類
from?sklearn.neighbors?import?KNeighborsClassifier,?KNeighborsRegressor
def?knn_filled_func(x_train,?y_train,?test,?k?=?3,?dispersed?=?True):
????#?params:?x_train?為目標(biāo)列不含缺失值的數(shù)據(jù)(不包括目標(biāo)列)
????#?params:?y_train?為不含缺失值的目標(biāo)列
????#?params:?test?為目標(biāo)列為缺失值的數(shù)據(jù)(不包括目標(biāo)列)
????if?dispersed:
????????knn=?KNeighborsClassifier(n_neighbors?=?k,?weights?=?"distance")
????else:
????????knn=?KNeighborsRegressor(n_neighbors?=?k,?weights?=?"distance")
????knn.fit(x_train,?y_train.astype('int'))
????return?test.index,?knn.predict(test)
index,predict?=?knn_filled_func(x_train,?y_train,?test,?3,?True)
方式5:隨機(jī)森林填充
隨機(jī)森林算法填充的思想和knn填充是類似的,即利用已有數(shù)據(jù)擬合模型,對缺失變量進(jìn)行預(yù)測。
from?sklearn.ensemble?import?RandomForestRegressor,?RandomForestClassifier
def?RandomForest_filled_func(x_train,?y_train,?test,?dispersed?=?True):
????#?params:?x_train?為目標(biāo)列不含缺失值的數(shù)據(jù)(不包括目標(biāo)列)
????#?params:?y_train?為不含缺失值的目標(biāo)列
????#?params:?test?為目標(biāo)列為缺失值的數(shù)據(jù)(不包括目標(biāo)列)
????if?dispersed:
????????rf=?RandomForestRegressor()
????else:
????????rf=?RandomForestClassifier()
????rf.fit(x_train,?y_train.astype('int'))
????return?test.index,?rf.predict(test)
index,predict?=?RandomForest_filled_func(x_train,?y_train,?test,?True)
預(yù)測完成后處理操作
#?填充預(yù)測值
df_null['c']?=?predict
#?回填到原始數(shù)據(jù)中
df['c']?=?df['c'].fillna(df_null[['c']].c)
df.info()
效果預(yù)覽
紅色為填充數(shù)據(jù),綠色為原始數(shù)據(jù) 上圖為隨機(jī)森林填充 下圖為插值填充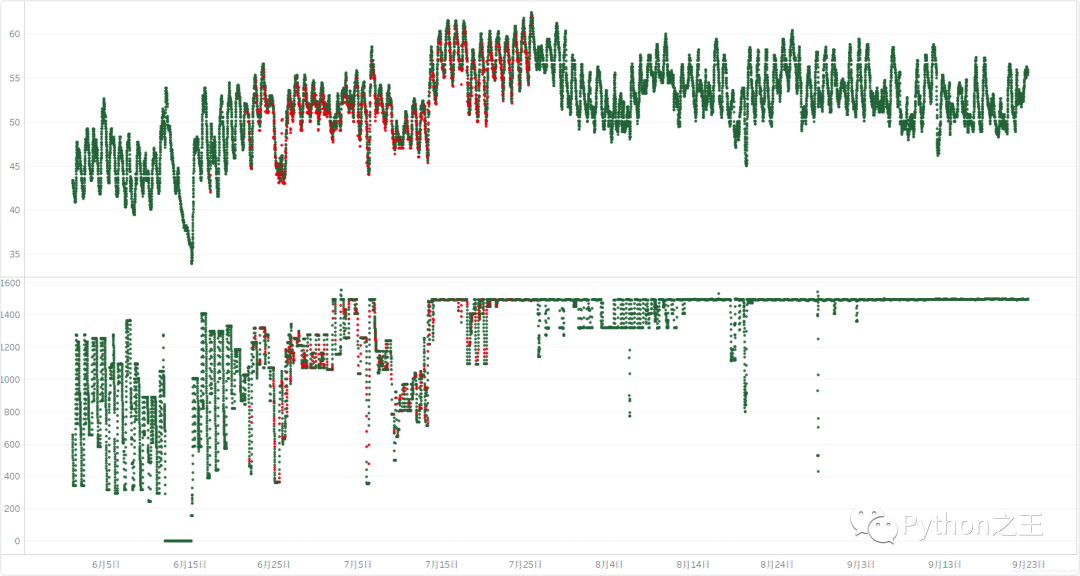


Python“寶藏級”公眾號【Python之王】專注于Python領(lǐng)域,會爬蟲,數(shù)分,C++,tensorflow和Pytorch等等。
近 2年共原創(chuàng) 100+ 篇技術(shù)文章。創(chuàng)作的精品文章系列有:
日常收集整理了一批不錯的?Python?學(xué)習(xí)資料,有需要的小伙可以自行免費領(lǐng)取。
獲取方式如下:公眾號回復(fù)資料。領(lǐng)取Python等系列筆記,項目,書籍,直接套上模板就可以用了。資料包含算法、python、算法小抄、力扣刷題手冊和 C++ 等學(xué)習(xí)資料!