
如何對大模型有效地微調增強?
▼ 最近直播超級多, 預約 保你有收獲
今晚直播: 《 基于LoRA微調大模型應用實戰(zhàn) 》
—1 —
如何對 LLM 大模型增強?
對 LLM 大模型能力增強在企業(yè)級有兩種實踐路線:RAG 和 Fine-tuning。接下來我們詳細剖析下這兩種增強實現(xiàn)方式。 第一:檢索增強生成 RAG(Retrieval Augmented Generation)實現(xiàn)方式 。 2020 年,Lewis et al. 的論文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》提出了一種更為靈活的技術:檢索增強生成(RAG)。在這篇論文中,研究者將生成模型與一個檢索模塊組合到了一起;這個檢索模塊可以用一個更容易更新的外部知識源提供附加信息。 用大白話來講:RAG 之于 LLM 就像開卷考試之于人類。在開卷考試時,學生可以攜帶教材和筆記等參考資料,他們可以從中查找用于答題的相關信息。開卷考試背后的思想是:這堂考試考核的重點是學生的推理能力,而不是記憶特定信息的能力。 類似地,事實知識與 LLM 大模型的推理能力是分開的,并且可以保存在可輕松訪問和更新的外部知識源中:- 參數化知識:在訓練期間學習到的知識,以隱含的方式儲存在神經網絡權重之中。
- 非參數化知識:儲存于外部知識源,比如向量數據庫。
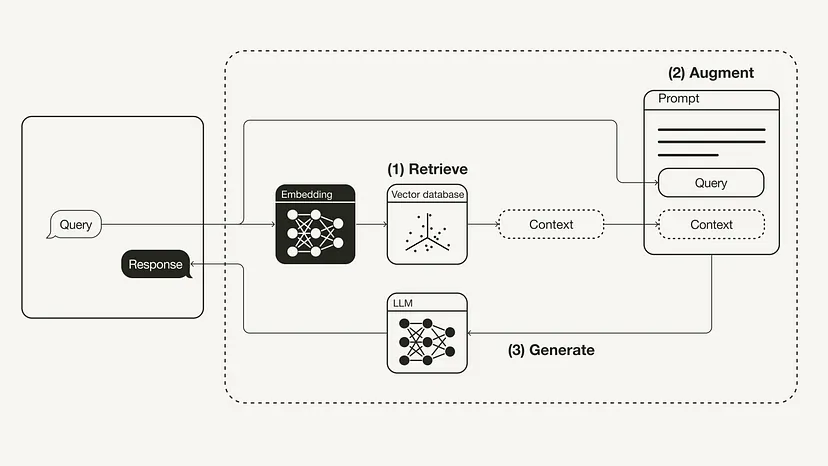 上圖檢索增強生成(RAG)的工作流程如下所示: 1、檢索(Retrieval):將用戶查詢用于檢索外部知識源中的相關上下文。為此,要使用一個嵌入模型將該用戶查詢嵌入到同一個向量空間中,使其作為該向量數據庫中的附加上下文。這樣一來,就可以執(zhí)行相似性搜索,并返回該向量數據庫中與用戶查詢最接近的 k 個數據對象。 2、增強(Augmented):然后將用戶查詢和檢索到的附加上下文填充到一個 prompt 模板中。 3、生成(Generation):最后,將經過檢索增強的 prompt 饋送給 LLM。 第二:微調(Fine-tuning) 實現(xiàn)方式 。 通過微調模型,可以讓神經網絡適應特定領域的或專有的信息。
上圖檢索增強生成(RAG)的工作流程如下所示: 1、檢索(Retrieval):將用戶查詢用于檢索外部知識源中的相關上下文。為此,要使用一個嵌入模型將該用戶查詢嵌入到同一個向量空間中,使其作為該向量數據庫中的附加上下文。這樣一來,就可以執(zhí)行相似性搜索,并返回該向量數據庫中與用戶查詢最接近的 k 個數據對象。 2、增強(Augmented):然后將用戶查詢和檢索到的附加上下文填充到一個 prompt 模板中。 3、生成(Generation):最后,將經過檢索增強的 prompt 饋送給 LLM。 第二:微調(Fine-tuning) 實現(xiàn)方式 。 通過微調模型,可以讓神經網絡適應特定領域的或專有的信息。 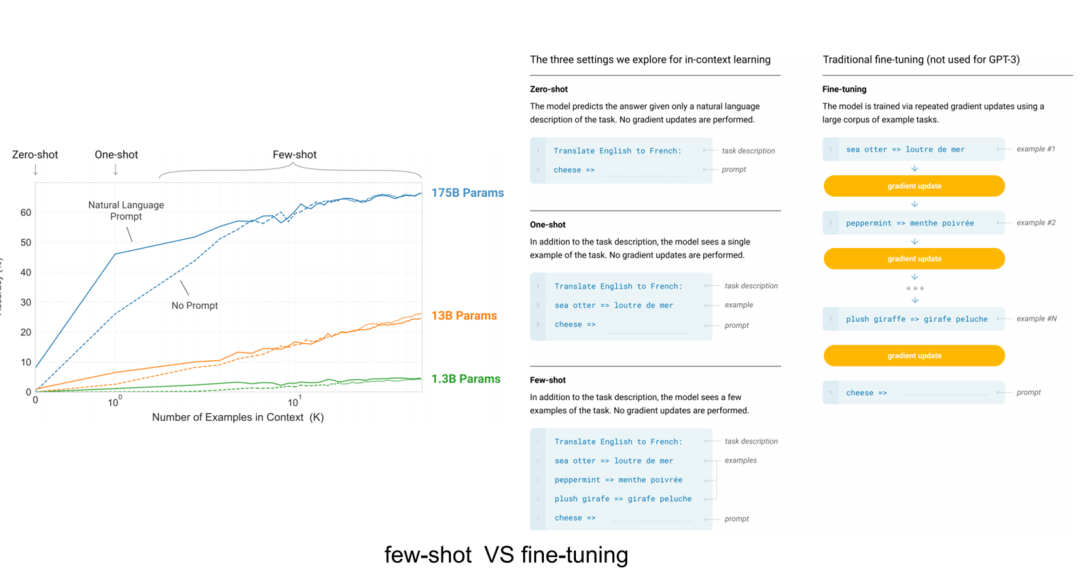 微調技術按照參數量不同,分為全參數微調和局部參數微調,由于全參數微調周期比較長,微調成本和一次預訓練成本差別不大,因此全參數微調在實際企業(yè)級生產環(huán)境中基本不使用,更有效的微調方式是少參數量微調,比如:基于 LoRA、P rompt tuning、P refix tuning、 Adapter、 LLaMA-adapter、 P-Tuning V2 等微調技術。 基于 LoRA 可以高效進行微調,通過把微調參數量減少為萬分之一,達成同樣的微調效果。
微調技術按照參數量不同,分為全參數微調和局部參數微調,由于全參數微調周期比較長,微調成本和一次預訓練成本差別不大,因此全參數微調在實際企業(yè)級生產環(huán)境中基本不使用,更有效的微調方式是少參數量微調,比如:基于 LoRA、P rompt tuning、P refix tuning、 Adapter、 LLaMA-adapter、 P-Tuning V2 等微調技術。 基于 LoRA 可以高效進行微調,通過把微調參數量減少為萬分之一,達成同樣的微調效果。
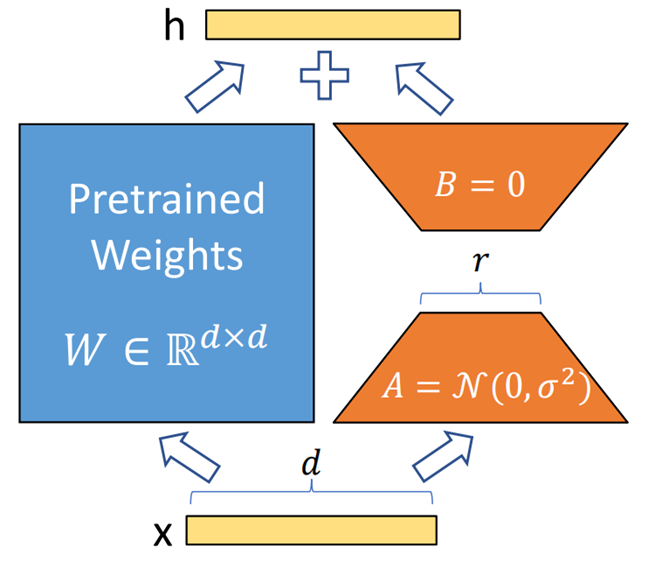 微調技術是有效的,但其需要密集的計算,成本高,還需要技術專家的支持,因此需要對微調技術有一定的認知和掌握,才能做好微調。
微調技術是有效的,但其需要密集的計算,成本高,還需要技術專家的支持,因此需要對微調技術有一定的認知和掌握,才能做好微調。
—2 —
免費超干貨大模型微調技術實戰(zhàn) 直播
為了幫助同學們掌握好 LLM 大模型微調技術架構和應用案例實戰(zhàn),今晚20點,我會開一場直播和同學們 深度聊聊 LLM 大模型高效微調 技術架構、高效微調案例實戰(zhàn)、 基于 Transformen 架構的高效微調核心技術 , 請同學點擊下方按鈕預約直播 ,咱們今晚20點不見不散哦~~
近期直播: 《 大模型Transformer架構剖析以及微調應用實踐 》—3 —
關于《LLM 大模型技術知識圖譜和學習路線》
最近很多同學在后臺留言:“玄姐,大模型技術的知識圖譜有沒?”、“大模型技術有學習路線嗎?” 我們傾心整理了大模型技術的知識圖譜《最全大模型技術知識圖譜》和學習路線《最佳大模型技術學習路線》快去領取吧!LLM 大模型技術體系的確是相對比較復雜的,如何構建一條清晰的學習路徑對每一個 IT 同學都是非常重要的,我們梳理了下 LLM 大模型的知識圖譜,主要包括12項核心技能: 大模型內核架構、大模型開發(fā)API、開發(fā)框架、向量數據庫、AI 編程、AI Agent、緩存、算力、RAG、大模型微調、大模型預訓練、LLMOps 等12項核心技能。
 為了幫助每一個程序員掌握以上12項核心技能,我們準備了一系列免費直播干貨,掃碼一鍵免費全部預約領取!
為了幫助每一個程序員掌握以上12項核心技能,我們準備了一系列免費直播干貨,掃碼一鍵免費全部預約領取!
END
評論
圖片
表情