
老潘的思考(AI部署、方向、就業(yè))!

最近工作內(nèi)容陷入了瓶頸,不知道自己想干啥了,總會有些重復(fù)性較強的工作。雖然也有些空閑時間看看其他東西,但發(fā)現(xiàn)看的東西越多,越發(fā)感到迷茫。不清楚自己該學什么,該看什么東西,或者說對自己未來的發(fā)展道路、發(fā)展方向有一點迷茫,不確定未來方向。
順其自然地,有一些想法,不吐不快罷,也順便講下自己的一些心得體會,希望能幫助大家少走些彎路。

個人之言,也不是啥大佬哈,有相似或不同想法的,歡迎各位留言交流。
初識AI
5年前,剛上研究生的時候,AI、深度學習、人工智能剛開始火起來。對深度學習啥也不懂的我,不知從哪兒找了李宏毅那個時候比較火的一個介紹深度學習的PPT,叫做《一天搞懂深度學習》,恐怖如斯。整整300頁,我斷斷續(xù)續(xù)看了一天,雖然有點蒙逼,總算對深度學習有了一點點了解。

當晚回去立馬百度了下該學什么,看了很多前輩的帖子,最后從閑魚上淘了幾本書:
《周志華的機器學習》 《機器學習實戰(zhàn)》 《TensorFlow實戰(zhàn)Google深度學習框架》 《深度學習》(大家熟知的圣經(jīng))
這幾本書之前有介紹過,這里再提下,《周志華的機器學習》都是理論,《機器學習實戰(zhàn)》主要是代碼實戰(zhàn),這兩本書可以配合起來看。然后再看《深度學習》圣經(jīng)這本書,差不多會對機器學習、深度學習有一定的理解,這些書放到現(xiàn)在都依然合適。

其中最沒用的就是《TensorFlow實戰(zhàn)Google深度學習框架》,那會Pytorch還不出名,大家都是直接上手TensorFlow,跟著書或者教程學習很費勁,這與TensorFlow靜態(tài)圖的設(shè)計有很大關(guān)系(不過實話實說TF的靜態(tài)圖設(shè)計很優(yōu)秀,比如dynamic分支的實現(xiàn)),加上TF各種經(jīng)常變化的API,學起來難度極大。
偶然一個機會看到Pytorch(那會Pytorch剛出來0.2版本),看了下示例代碼,感覺很清爽,學了一陣順利復(fù)現(xiàn)了一個基于keras的小項目,就認定Pytorch了。
后來Pytorch出來0.4、1.0,到現(xiàn)在的1.12。無論是在學術(shù)界還是工程界,Pytorch相比TensorFlow來說已經(jīng)很不差了,強烈建議新入門的小伙伴直接上手Pytorch。至于TF1或者TF2好不好用,智者見智仁者見仁,我的建議還是Pytorch。
歸根結(jié)底,不論是Pytorch還是TensorFlow都只是你學習的一個工具,而且這倆庫都很牛逼,哪個你用的舒服,就用哪個就對了。不順手就扔掉,只不過現(xiàn)在tf1還是tf2可能都沒有Pytorch順手,所以用Pytorch上手的人更多,更有甚者,import torch as tf
除了上述這些資料,還看了其他的書和資料:
程序員的數(shù)學系列(線性代數(shù)、數(shù)學、概率論) OpenCV系列(星云大佬、OpenCV3官方文檔) C++各種亂七八槽的書(primer、effective、more effective) 圖像處理相關(guān)的書

就這樣看看學習視頻、看看相關(guān)的書、看看代碼,學一段時間就入門了。
2017年那會資料就挺多了的,現(xiàn)在2022資料只會更多,不過伴隨而來的就是不知道看哪個了,可以按照我的建議來看,也可以自己按照自己喜歡的看,其實看啥都能入門,就是是否系統(tǒng)、或者學習時間快慢的問題,沒必要糾結(jié)非要最好最快的,行動起來才是關(guān)鍵
深度學習 && CV
初步入門之后,決定做圖像方向的深度學習,無論是那會還是現(xiàn)在,CV深度學習的熱度和資料都比NLP要高不少,雖然學習難度低一些,但學習的人也很多,同樣很卷。
所以說選擇很重要。一開始選擇Pytorch上手算是比較正確的選擇;而一開始學CV,最近幾年就不是很吃香了,除了CV本來就非常卷,另外因為transformer的大火,很多NLP、語音識別類的應(yīng)用也隨之不斷冒出來了,生態(tài)都很不錯。很多比賽也是搞一些transformer系列的模型,而很多CV類的模型,比如檢測場景,做的人太多了,已經(jīng)有點審美疲勞了。

現(xiàn)在來看,CV方向還是有很多有意思的項目,比如mediapipe[1],里頭集成了很多有意思的CV應(yīng)用,已經(jīng)覆蓋大部分場景了。NLP的話,我本身也對transformer感興趣,一直沒有時間好好看一個transformer的項目,近期打算好好看下。
話說回來,在入門后,后續(xù)又看了些比較有名氣的課:
吳恩達的機器學習課 CS231n
可能還看了別的但是不記得了,印象比較深的就這倆,吳恩達的課太偏理論,看的我快睡著了;CS231n的課質(zhì)量很高,干貨超多,作業(yè)也很有質(zhì)量,這個是強烈推薦初學者去過一遍的,不過難度會稍微大一點。
然后也可以跑幾個項目,我是先用Pytorch復(fù)現(xiàn)了幾個用keras搭的項目,然后自己跑了跑一些檢測模型(那會比較火的是faster-R-CNN、Mask-R-CNN、YOLOv1-YOLOv3、SSD等),也有一些其他的風格遷移、GAN、圖像分割相關(guān)任務(wù),總之都過一遍就了解了差不多了。
現(xiàn)在也是一樣,無非就是換了一批明星,可能是YOLOX、YOLOv5、Centernet、CornerNet等等。其他任務(wù)也是類似,深度學習領(lǐng)域模型發(fā)展的也很快,一年一個baseline,但是我對這些設(shè)計這些算法不是很感興趣(雖然人家設(shè)計確實巧妙),哪個好就用那個唄。
大概就是這些,我那會沒有報任何收費的培訓班,好像從閑魚買過一些盜版課(記得是優(yōu)達學城的),其他的就都是公開免費的了,再推薦一次CS231N,這門課的質(zhì)量真的是很高,英文好的建議直接看英文版。
關(guān)于算法工程師和訓練
在實際業(yè)務(wù)中,我們會針對場景訓練模型,不過大部分的業(yè)務(wù)場景,比如說你要實現(xiàn)一個檢測人的模型,我們要做的其實就三件事兒:
收集數(shù)據(jù)(從公司的query中找,通過腳本或者人力來篩選) 整理數(shù)據(jù)、標注數(shù)據(jù)、制作label 挑選模型進行訓練、調(diào)優(yōu)
其實吧,收集數(shù)據(jù)和整理數(shù)據(jù)花費的時間最多,而訓練在你熟悉或者有自己的一套框架之后,分分鐘搞定。所以真實情況就是這樣:
收集數(shù)據(jù)和整理數(shù)據(jù)制作label,每個新任務(wù)新場景都會重頭來一遍,不過如果這個流程熟悉了,你有腳本可以自動化了,其實也挺快的 配環(huán)境、解環(huán)境bug;一開始配環(huán)境比較耗時,配好之后下次就直接用了,或者,人生苦短,我用docker 設(shè)計模型,做實驗,分析loss,再跑幾個實驗。大部分任務(wù)你直接套一個框架(yolo系列、centernet系列、fcos系列),初版沒什么問題,剩下的就是根據(jù)產(chǎn)品反饋的badcase來針對性優(yōu)化了
當這套框架定型之后,大部分新的業(yè)務(wù)來了,直接按照流程來整體進度是很快的,唯一慢的步驟可能是標注,畢竟標注數(shù)據(jù)是無法完全自動化的。

其實訓練這個活,相關(guān)領(lǐng)域你熟悉了,之后的大部分任務(wù)都可以快速上手,沒啥難度。假如遇到個新的任務(wù),直接github上找個開源庫clone下來根據(jù)實際業(yè)務(wù)修改下就行了。雖然說可以自己實現(xiàn)吧,但現(xiàn)實中沒有時間讓你慢慢搞慢慢預(yù)研的。怎么快怎么來,如何快速產(chǎn)出才是最重要的。
至于算法能不能搞,行不行,卷不卷,我的看法是一直很卷。而且因為疫情,現(xiàn)在幾乎所有崗位都縮減不少,目前找工作來說難度可是真的大(真的大)。算法肯定還是有需求,門檻的話,沒有那么高,訓練模型這一整套流程,只要有點基礎(chǔ)熟悉起來還是很快的。至于開發(fā)新的算法,說實話確實很牛逼,只是大部分場景下不需要,很多業(yè)務(wù)場景算法做到極致還是比較難的,從0-90提升好說,從98-99就難的很了。大部分的瓶頸也在訓練數(shù)據(jù),模型的改動后期對精度的影響微乎甚微。
相關(guān)的話題,感興趣的可以看我之前寫作的兩篇:
最近也給我推送了一些新聞,也不知道是真是假。不過可以肯定的是,不管是阿里的達摩院、華為的2012實驗室啥的,我問了一些在里頭的朋友,搞的和咱們正常算法工程師相差不大。人家可能更注重發(fā)paper,搞預(yù)研,咱們可能更注重實際業(yè)務(wù)需求,但都是用Pytorch呀、TF呀,跑一些算法,改改結(jié)構(gòu)、弄弄數(shù)據(jù),都差不多。
總的來說,算法工程師這個需求還是有的,畢竟深度學習在CV和NLP領(lǐng)域都有很多很好的應(yīng)用。會用、用的好、會根據(jù)實際場景選取不同的模型,產(chǎn)出模型并且實際部署應(yīng)用起來,會這些就可以滿足算法工程師的基本要求了。
AI部署
在工作還有在學校的一段時間,我都做了一些部署的工作,也寫了幾篇關(guān)于部署的文章(當然還有有很多坑沒填):
AI部署簡單來說就是將訓練好的模型放在各種平臺運行,不過:
平臺很多(PC端、移動端、服務(wù)器、編譯端側(cè)、嵌入式) 模型種類也很多(檢測、識別、NLP、分類、分割、GAN) 要求也很多(速度快、穩(wěn)定、功耗低、占用內(nèi)存小、延遲度) 場景也很多(單模型、多模型分時調(diào)用、多模型pipeline、復(fù)雜模型前后處理pipeline) 會遇到各種問題(結(jié)果對不上、動態(tài)庫ABI不兼容、性能問題)
部署場景多種多樣,和算法相比更偏向于實際一點,好的算法能夠解決問題,形成一套方案,但是方案的實施,就需要部署了。現(xiàn)在部署的概念我認為其實很雜很泛,你訓好了一個模型,用flask + pytorch搭了一個服務(wù)給外部調(diào)用,就是部署;你把一個模型轉(zhuǎn)化為TensorRT,然后寫了個C++服務(wù)跑起來,也是部署;你把Pytorch的模型遷移到Caffe中燒錄到板子里頭,也是部署。

部署不一定非要寫C++,也不一定非要使用TensorRT這種高性能庫,不過既然你都部署了,性能當然是越高越好嘛。要深入底層去優(yōu)化模型,那么C++和一些其他的高性能庫就少不了了。
部署我認為當下還是很重要的,各種需要部署AI模型的設(shè)備:
手機(蘋果的ANE、高通的DSP、以及手機端GPU) 服務(wù)端(最出名的英偉達,也有很多國產(chǎn)優(yōu)秀的GPU加速卡) 電腦(intel的cpu,我們平時使用的電腦都可以跑) 智能硬件(比如智能學習筆、智能臺燈、智能XXX) VR/AR/XR設(shè)備(一般都是高通平臺,比如Oculus Quest2) 自動駕駛系統(tǒng)(英偉達和高通) 各種開發(fā)板(樹莓派、rk3399、NVIDIA-Xavier、orin) 各種工業(yè)裝置設(shè)備(各種五花八門的平臺,不是很了解) 其他等等
坑都不少,需要學習的也比較雜,畢竟在某一個平臺部署,這個平臺的相關(guān)知識相關(guān)信息也要理解,不過有一些經(jīng)驗是可以遷移的,因此經(jīng)驗也比較重要,什么AI部署、AI工程化、落地都是一個概念。能讓模型在某個平臺順利跑起來就行。
部署也不是什么方向,或者說,公司招人的時候也不會搞個“AI部署工程師”的崗位,不像后端、前端這種相對比較固定,職責相對比較專一。而部署呢,相對來說干的活會比較雜一些:
中小公司來說,算法工程師也會做部署的事情,畢竟也是工程師嘛 大公司來說,會拆的比較細。除了算法工程師,其他崗位,如深度學習工程師、AI-SDK工程師、AI算法系統(tǒng)工程師、端智能應(yīng)用工程師、AI平臺開發(fā)工程師、AI框架工程師、高性能計算工程師、AI解決方案工程師等等都會重點做部署的工作,相比于傳統(tǒng)的算法工程師,他們一般不訓練模型,只會針對模型進行部署或者寫一些與模型部署密切相關(guān)的組件等等 其實不管大公司還是小公司,關(guān)于部署的界限也沒有那么死,要靈活起來也是非常的靈活
雖然比較雜吧,但這是確確實實的實際落地的工作,不管怎么吹,模型跑到實際的設(shè)備上才是最重要的。關(guān)于這方面,臟活累活也有很多,比如:
模型能不能轉(zhuǎn)成功、能不能跑起來,跑起來之后的速度、精度、占用內(nèi)存有沒有問題 模型這個算子在這個平臺上沒有實現(xiàn),怎么辦,怎么解決,怎么workaround 硬件版本、軟件版本、SDK版本,匹配不匹配,各種換各種試 遇到各種奇奇怪怪的bug,比如多個模型搶占資源,比如某個模型會core
等等等等。
說了這么多,其實我目前也不清楚自己最感興趣的方法到底是什么,雖然平時的工作也與上面介紹的有一些關(guān)系。接下來我也會梳理下自己曾經(jīng)做過的一些小項目,整理出來,可能是一系列文章,也可能是一個開源庫,總之,我再想想。
AI編譯器
AI編譯器是我一直向往的,原因也很簡單,大家都會對未知的、新鮮的東西感興趣。不過我這輩子可能也就是向往了哈哈。
AI編譯器涉及到的技術(shù)棧很多,基本的深度學習、編程語言、編譯原理、計算機系統(tǒng)原理,再細分C++、編譯優(yōu)化、函數(shù)式編程、LLVM等等,需要看的東西很多,沒有系統(tǒng)學習過的直接上手學習難度很高。
2022年,AI編譯器比之前火了不少,大家聽說過的可能有torchscript、Glow、XLA、TVM、MLIR、TensorRT等等。我一開始接觸的是TVM,那會并不是很懂AI編譯器具體是干啥的,只知道比較牛逼高級一點。簡單來說,就是加載一個模型文件(比如ONNX模型),然后輸出包含網(wǎng)絡(luò)結(jié)構(gòu)的序列化好的運行包,我們可以在自己的應(yīng)用上包含這個和對應(yīng)AI編譯器的運行時so,就可以推理運行了。
再具體點,和編譯器類似,AI編譯器輸入神經(jīng)網(wǎng)絡(luò)(前端代碼),進行一些優(yōu)化(計算圖優(yōu)化、公共表達式合并、loop unrolling等),輸出可以加載運行的網(wǎng)絡(luò)文件(可執(zhí)行文件)。一般來說經(jīng)過AI編譯器優(yōu)化的神經(jīng)網(wǎng)絡(luò),速度會比直接在原始框架要快一些(Pytorch、TensorFlow),究其原因也是AI編譯器所做的一些圖優(yōu)化工作和生成的算子性能要比原生的框架實現(xiàn)要好。
那會也寫過兩篇介紹TVM的文章:
AI編譯器很像黑盒子,一開始用的時候也不管那么多,總之能讓自己的模型性能提升就是好事兒,后續(xù)漸漸深入研究了一下,學問真的不少。很多算子優(yōu)化的細節(jié),如果對指令集或者編譯器不了解的話,肯定是一頭霧水,還是需要花時間研究一下,不需要太深,知道其大致工作原理就可以了,具體的細節(jié)什么的,有需要的時候再重點看。
舉個簡單的例子,TVM在優(yōu)化模型的時候,會按照設(shè)定的規(guī)則搜索優(yōu)化空間,而這個規(guī)則我們有必要了解下。可以使用TVM中的TVMScript[2],類似于python的語法去寫kernel(指高性能、手寫的CPU或者GPU算子),運行在各種硬件平臺,比如我們寫一個簡單的向量加法:
# 以下是一個簡單的向量相加
@tvm.script.ir_module
class Vector:
@T.prim_func
def main(A: T.Buffer[(256,), "float32"], B: T.Buffer[(256,), "float32"], C: T.Buffer[(256,), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i0 in T.serial(256):
with T.block("C"):
x = T.axis.spatial(256, i0)
T.reads(A[x], B[x])
T.writes(C[x])
C[x] = A[x] + B[x]
# 寫好kernel后,使用tvm.build編譯
mod = tvm.build(Vector, target="llvm")
這個kernel使用LLVM進行編譯,運行在CPU端。在調(diào)用tvm.build后會調(diào)用LLVM編譯器進行編譯,你編譯的最終代碼性能和你寫的這個kernel有很大關(guān)系,我們可以通過打印LLVM-IR來查看:
# 查看TVM生成的LLVM-IR
print(mod.get_source())
原始的沒有使用vector指令只使用標量指令的IR如下:
; Function Attrs: nofree noinline norecurse nosync nounwind
define internal fastcc void @main_compute_(i8* noalias nocapture align 128 %0, i8* noalias nocapture readonly align 128 %1, i8* noalias nocapture readonly align 128 %2) unnamed_addr #1 {
entry:
%3 = bitcast i8* %2 to <4 x float>*
%wide.load = load <4 x float>, <4 x float>* %3, align 128, !tbaa !113
%4 = getelementptr inbounds i8, i8* %2, i64 16
%5 = bitcast i8* %4 to <4 x float>*
%wide.load2 = load <4 x float>, <4 x float>* %5, align 16, !tbaa !113
%6 = bitcast i8* %1 to <4 x float>*
%wide.load3 = load <4 x float>, <4 x float>* %6, align 128, !tbaa !116
%7 = getelementptr inbounds i8, i8* %1, i64 16
# 省略很多 類似的讀取+加法+賦值操作
store <4 x float> %443, <4 x float>* %447, align 16, !tbaa !119
ret void
}
如這時候使用TVM的Schedule,來將我們剛才寫的這個script中的重要loops進行向量化,也就是將這個操作的C維向量化:
# TensorIR 使用schedule
sch = tvm.tir.Schedule(Vector)
# 得到那個名稱為 C 的loop
block_c = sch.get_block("C")
# 獲取loop的維度
(i,) = sch.get_loops(block_c)
# 向量化這個維度
sch.vectorize(i)
向量化之后的TVMScript為:
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[(256,), "float32"], B: T.Buffer[(256,), "float32"], C: T.Buffer[(256,), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0 in T.vectorized(256): # 這里使用了向量化命令
with T.block("C"):
x = T.axis.spatial(256, i0)
T.reads(A[x], B[x])
T.writes(C[x])
C[x] = A[x] + B[x]
調(diào)用向量指令后,打印的LLVM-IR如下,可以看到LLVM-IR按照你的要求將這個操作向量化了:
; Function Attrs: mustprogress nofree noinline norecurse nosync nounwind willreturn
define internal fastcc void @main_compute_(i8* noalias nocapture align 128 %0, i8* noalias nocapture readonly align 128 %1, i8* noalias nocapture readonly align 128 %2) unnamed_addr #1 {
entry:
%3 = bitcast i8* %2 to <256 x float>*
%4 = load <256 x float>, <256 x float>* %3, align 128, !tbaa !113
%5 = bitcast i8* %1 to <256 x float>*
%6 = load <256 x float>, <256 x float>* %5, align 128, !tbaa !127
%7 = fadd <256 x float> %4, %6
%8 = bitcast i8* %0 to <256 x float>*
store <256 x float> %7, <256 x float>* %8, align 128, !tbaa !141
ret void
}
使用這個LLVM-IR最終生成的匯編代碼,就會使用該CPU上的的向量指令,比如SSE、AVX2等等,相比原始的標量操作會快不少。
這只是其中一部分的細節(jié),涉及到的知識已經(jīng)有很多,比如LLVM、CPU指令集等等,想要好好深入的話,是需要花費一定的精力的。
對于AI編譯器,我了解的也不是很深,不過通過這幾年的嘗鮮到常用,發(fā)現(xiàn)這些工具確實在某些場景下是有一定用處的。比如某些corner case,常見的卷積shape已經(jīng)有很多人工寫的kernel庫去做(cudnn、cublas),但是不常見的卷積shape直接使用這些kernel庫性能就差些了,這個時候就可以使用AI編譯器設(shè)定shapes自動搜索,比自己寫的話,人力和時間成本都要低很多。
當然AI編譯器還有很多其他的用法,很多初創(chuàng)公司使用TVM作為自家硬件的編譯器,通過修改中端、后端去適配自己的硬件,快速搭建一套適合自家硬件的AI編譯器給客戶使用。通過AI編譯器生成的op算子,對于剛開始出生的硬件來說,可能比人工手寫性能好的概率更高一些。
AI編譯器,之前花了不少時間去研究,之后也會花些時間研究,不過也不是專職commit的,之后會嘗試更多地向開源社區(qū)貢獻下,寫一些關(guān)于TVM的文章。
之前也有很多小伙伴想和我一起學TVM,但因為種種原因沒有堅持下來(我也是),畢竟自身時間是有限,學習期間會被各種東西干擾,尤其是還有工作。其實學習這個東西大部分人不可能一直有大把時間投入的,我們只要堅持學就好,慢慢來,有時間就看看。
硬件底層
本科時我是搞嵌入式的,那會學51、學stm32,也參加一些亂七八槽的電子類比賽。后來研究生時期選擇了深度學習方向,出于對硬件的興趣,除了訓練也會做一些工程類的項目,搞過的板卡有樹莓派、jetson-TX2、FPGA等。
依稀記得本科那會,51是89C51、stm32是stm32f103zet6(或者c8t6),一個8位、一個32位。學習嵌入式對理解計算機原理有大的幫助,51或者stm32都是小型計算機了,只不過缺少運行os的必要單元,只能跑跑RTOS(ucos-ii這種的)。后來更高級點的樹莓派系列就可以跑Ubuntu了。
拋開這些比較簡單的單片機,現(xiàn)在我們使用的GPU,比如NVIDIA的顯卡,結(jié)構(gòu)就復(fù)雜不少,指令集更多、寄存器也更多,支持的功能也相應(yīng)更多,想要實現(xiàn)極致的性能,就需要對芯片架構(gòu)特別了解,通過intrinsics或者匯編實現(xiàn)應(yīng)用的性能。不過做到這一點,門檻和難度大的不是一點半點。
不過所幸NVIDIA提供了很強大的編譯器NVCC,提供了用于并行異構(gòu)計算的編程模型CUDA (Compute Unified Device Architecture) ,也就是我們熟知的GPU編程。通過編寫C++和C語言代碼就可以實現(xiàn)性能很不錯的CUDA代碼,我們目前使用的CUDA代碼大部分也不需要嵌入?yún)R編,這與CUDA的優(yōu)秀脫不了關(guān)系。
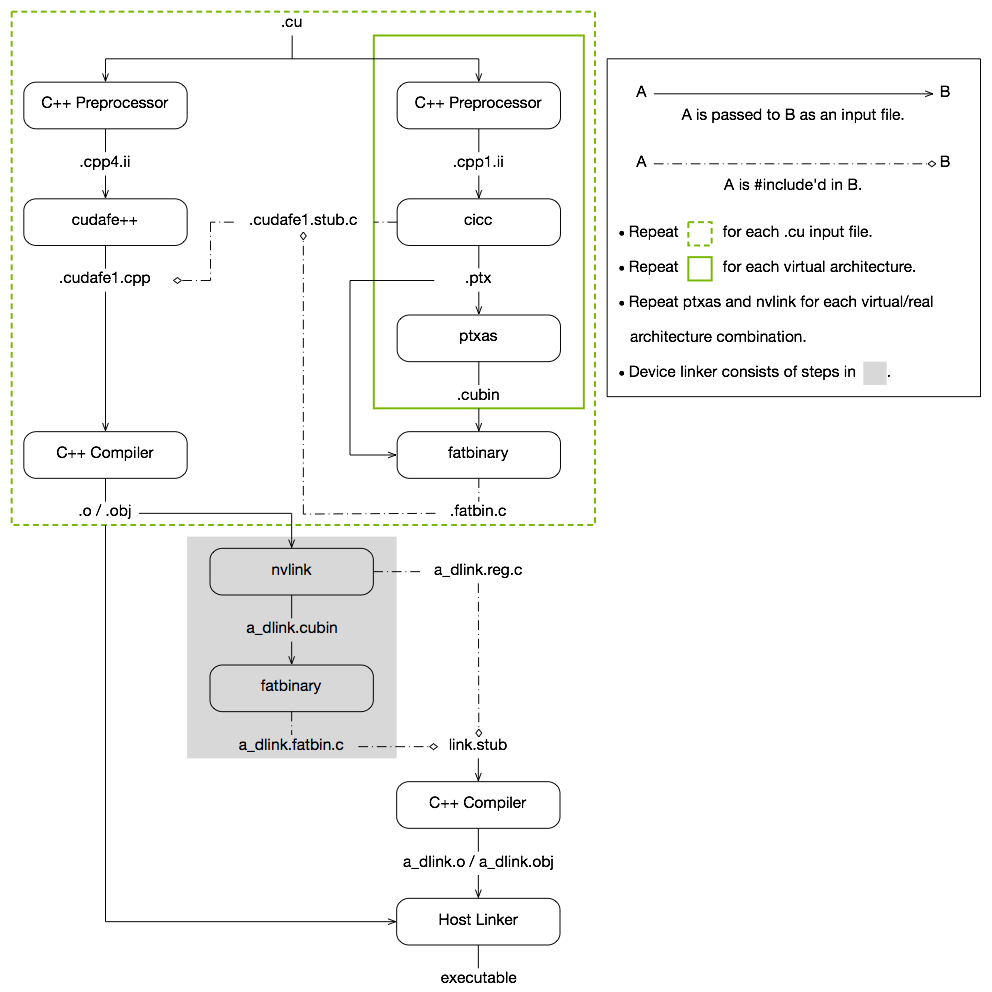
硬件是挺有意思的,各式各樣的硬件,CPU、GPU、NPU、VPU、DSP,每個硬件架構(gòu)設(shè)計也各不相用。比如CPU的向量化是SIMD,而GPU的多線程是SIMT,hexagon DSP則使用VLIW超長指令集去實現(xiàn)并行...
精通其中某一方向都是需要大把時間努力的,想要寫出極致性能的算子就需要對使用的硬件特別的了解。不過現(xiàn)在比較好的是深度學習編譯器的發(fā)展,自動生成的算子大概能滿足80%的場景,很多場景不需要手動去寫intrinsics或者匯編,利用生成的算子差不多能達到與純手工優(yōu)化媲美的性能。
硬件底層這個方向,個人感覺如果基礎(chǔ)打好,很多知識是可以遷移的,最近也在抽空看一本《計算機體系結(jié)構(gòu)——量化研究方法》的書。看的比較吃力,但是偶爾看看發(fā)現(xiàn)很多硬件都有相似的地方,比如GPU的一個warp32個thread的硬件線程,和DSP的一個cluster兩個硬件線程有類似的地方。
手機這種移動端AI部署落地也是目前需求較高的一個方向,畢竟手機芯片也是年年要更新的,關(guān)于這方面要學習的有很多,算法SDK、算法移植、算法op優(yōu)化、甚至具體到芯片層面,arm的指令、gpu、npu、dsp的優(yōu)化等等要做的東西很多很多,
計算機原理、計算機組成原理、匯編原理、深入理解計算機原理...這些基礎(chǔ)看看看完對于大部分的硬件都會有個直觀的印象。
哎,要看的東西太多,慢慢看吧。
就業(yè)方向
很多小伙伴問我,老潘我該學什么啊,我這樣做對不對啊,我學這個對以后找工作有沒有幫助啊等等。我只能這個說看情況,面試要準備什么要問什么問題這個分公司,不同公司不同jd側(cè)重點也不一樣。而且這個很看個人,每個人喜歡的也不一樣,比如說我喜歡的大概方向是部署,對于訓練沒有那么熱衷,喜歡一些比較實際的東西。
所以也看個人的興趣愛好,想做哪些點,比如部署的方向也有很多,如果不知道方向可以先把基礎(chǔ)打好,C++基礎(chǔ)、深度學習基礎(chǔ)、計算機原理、編譯原理、硬件什么的基礎(chǔ)打好吧。可以先慢慢來,一般一開始也不清楚自己喜歡什么想要什么,還是要慢慢看才會明白自己到底對什么感興趣。
之后在深入,可以根據(jù)自己的興趣方向選擇以下幾個學習點:
對算法、特征、業(yè)務(wù)、實際算法場景感興趣,可以專注深度學習各種算法知識(識別、檢測、分類、校準、損失函數(shù)),然后基于這些知識解決實際的問題,可以訓練模型,也可以結(jié)合傳統(tǒng)圖像或者其他方法一起解決。現(xiàn)實生活中的問題千奇百怪,一般只使用一個模型解決不了,可能會有多個模型一起上,解決方法也多種多樣 對AI落地、部署、移植、算法SDK感興趣,可以多看工程落地的一些知識(C++、Makefile、cmake、編譯相關(guān)、SDK),多參與一些實際項目攢攢經(jīng)驗,多熟悉一些常見的大廠造的部署輪子(libtorch、TensorRT、openvino、TVM、openppl、Caffe等),嘗試轉(zhuǎn)幾個模型(ONNX)、寫幾個op(主要是補充,性能不要最優(yōu))、寫幾個前后處理、debug下各種奇葩的錯誤,讓模型可以順利在一些平臺跑起來,平臺可以在PC、手機、服務(wù)器等等; 對算子優(yōu)化、底層硬件實現(xiàn)實現(xiàn)感興趣的,可以重點看某一平臺的硬件架構(gòu)(CPU、GPU、NPU、VPU、DSP),然后學學匯編語言,看看內(nèi)存結(jié)構(gòu),看看優(yōu)化方法等等,做一些算子的優(yōu)化,寫一些OP啥的,再者涉及到profile、算子優(yōu)化、內(nèi)存復(fù)用等等。 當然還有模型壓縮、模型剪枝、量化、蒸餾,這些其實也是部署的一部分,根據(jù)需要掌握即可。
以上只是不完全概括,差不多是這個樣子。很多情況下上述幾個都可以參與都可以做,沒有分那么絕對。去了公司你就是解決問題的人,來什么問題就解決什么問題,對于很多業(yè)務(wù)場景也不需要每一項都很牛逼,掌握80%就夠用了。
另外,除了工程技術(shù)這些硬能力,個人感覺還需要一些軟實力,隨著我們慢慢地成長,有時候會發(fā)現(xiàn)技術(shù)并不能解決所有事,或者說靠自己一個人并不能完成一個比較大的任務(wù)。因此也需要考慮下這些點:
了解產(chǎn)品需求。如何將需求轉(zhuǎn)化為實際的產(chǎn)品,咱們不能光知道開發(fā),貼近實際的使用者是最好的,雖然在公司有PM來弄了,但是如果你可以以用戶的角度來設(shè)計工具的話,或許會更好 和各種人打交道的能力,開發(fā)代碼不是一個人的事兒,一個大的項目肯定是好幾個人共同努力的結(jié)果,需要溝通聯(lián)調(diào)各個部門,協(xié)商一些問題,合作開發(fā)代碼等等 影響力,個人品牌,多寫寫文章、多幫助幫助他人、多參與一下開源、參與一下貢獻,都是不錯的
想躺平,還是走出舒適區(qū),還得看你自己。
后記
偶然在知乎上看到程序員35歲這個梗,這個看到過好多次,對此目前也沒有什么想法。能做的,也就是提前想想路子,同時學習學習。雖然未來五年、或者未來兩年技術(shù)會發(fā)展成什么樣,我們是無法預(yù)測的,但我們可以把自身的基礎(chǔ)打好,然后再適應(yīng)接下來的挑戰(zhàn)。
加油吧!
看到這里了,感謝你聽老潘的嘮叨,你說我文章又臭又長也罷、廢話也多也罷,總之我是把我的想法都寫出來了,贊同的,點個贊,不贊同的,歡迎留言哦。
參考資料
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html the-future-of-hardware-is-software[3] https://blog.csdn.net/shungry/article/details/89715468 算法工程師的落地能力具體指的是什么?
參考資料
mediapipe: https://mediapipe.dev/
[2]TVMScript: https://zhuanlan.zhihu.com/p/433540150
[3]the-future-of-hardware-is-software: https://octoml.ai/blog/the-future-of-hardware-is-software/