
Transformer代碼完全解讀!
點擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時間送達(dá)
2017年谷歌在一篇名為《Attention Is All You Need》的論文中,提出了一個基于attention(自注意力機(jī)制)結(jié)構(gòu)來處理序列相關(guān)的問題的模型,名為Transformer。
Transformer在很多不同nlp任務(wù)中獲得了成功,例如:文本分類、機(jī)器翻譯、閱讀理解等。在解決這類問題時,Transformer模型摒棄了固有的定式,并沒有用任何CNN或者RNN的結(jié)構(gòu),而是使用了Attention注意力機(jī)制,自動捕捉輸入序列不同位置處的相對關(guān)聯(lián),善于處理較長文本,并且該模型可以高度并行地工作,訓(xùn)練速度很快。
本文將按照Transformer的模塊進(jìn)行講解,每個模塊配合代碼+注釋+講解來介紹,最后會有一個玩具級別的序列預(yù)測任務(wù)進(jìn)行實戰(zhàn)。
通過本文,希望可以幫助大家,初探Transformer的原理和用法,下面直接進(jìn)入正式內(nèi)容:
1 模型結(jié)構(gòu)概覽
如下是Transformer的兩個結(jié)構(gòu)示意圖:
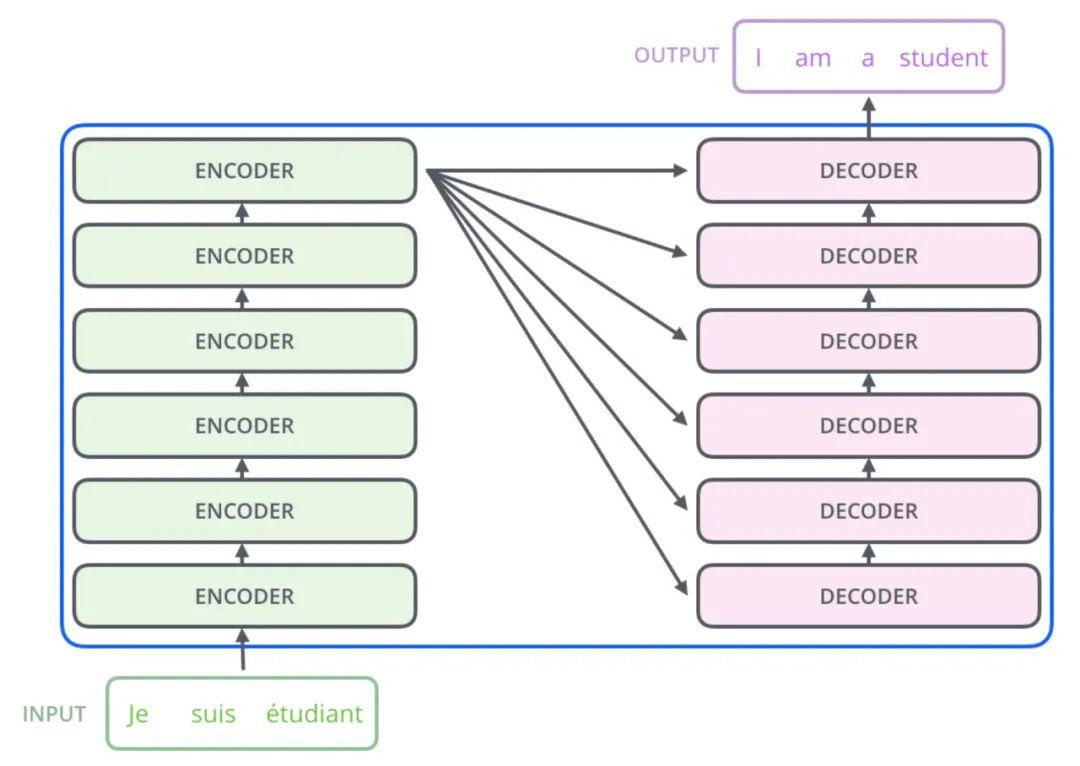
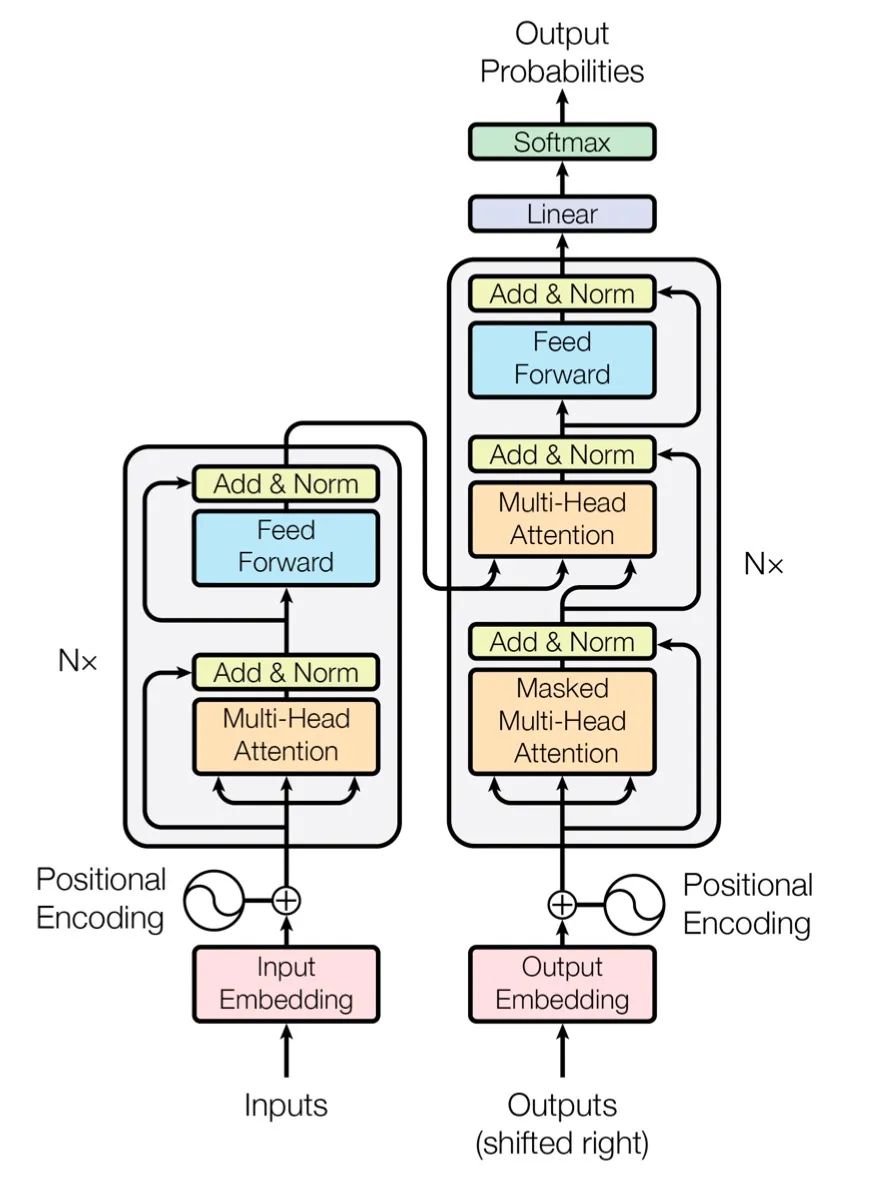
上圖是從一篇英文博客中截取的Transformer的結(jié)構(gòu)簡圖,下圖是原論文中給出的結(jié)構(gòu)簡圖,更細(xì)粒度一些,可以結(jié)合著來看。
模型大致分為Encoder(編碼器)和Decoder(解碼器)兩個部分,分別對應(yīng)上圖中的左右兩部分。
其中編碼器由N個相同的層堆疊在一起(我們后面的實驗取N=6),每一層又有兩個子層。
第一個子層是一個Multi-Head Attention(多頭的自注意機(jī)制),第二個子層是一個簡單的Feed Forward(全連接前饋網(wǎng)絡(luò))。兩個子層都添加了一個殘差連接+layer normalization的操作。
模型的解碼器同樣是堆疊了N個相同的層,不過和編碼器中每層的結(jié)構(gòu)稍有不同。對于解碼器的每一層,除了編碼器中的兩個子層Multi-Head Attention和Feed Forward,解碼器還包含一個子層Masked Multi-Head Attention,如圖中所示每個子層同樣也用了residual以及l(fā)ayer normalization。
模型的輸入由Input Embedding和Positional Encoding(位置編碼)兩部分組合而成,模型的輸出由Decoder的輸出簡單的經(jīng)過softmax得到。
結(jié)合上圖,我們對Transformer模型的結(jié)構(gòu)做了個大致的梳理,只需要先有個初步的了解,下面對提及的每個模塊進(jìn)行詳細(xì)介紹。
2 模型輸入
首先我們來看模型的輸入是什么樣的,先明確模型輸入,后面的模塊理解才會更直觀。
輸入部分包含兩個模塊,Embedding 和 Positional Encoding。
2.1 Embedding層
Embedding層的作用是將某種格式的輸入數(shù)據(jù),例如文本,轉(zhuǎn)變?yōu)槟P涂梢蕴幚淼南蛄勘硎荆瑏砻枋鲈紨?shù)據(jù)所包含的信息。
Embedding層輸出的可以理解為當(dāng)前時間步的特征,如果是文本任務(wù),這里就可以是Word Embedding,如果是其他任務(wù),就可以是任何合理方法所提取的特征。
構(gòu)建Embedding層的代碼很簡單,核心是借助torch提供的nn.Embedding,如下:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""
類的初始化函數(shù)
d_model:指詞嵌入的維度
vocab:指詞表的大小
"""
super(Embeddings, self).__init__()
#之后就是調(diào)用nn中的預(yù)定義層Embedding,獲得一個詞嵌入對象self.lut
self.lut = nn.Embedding(vocab, d_model)
#最后就是將d_model傳入類中
self.d_model =d_model
def forward(self, x):
"""
Embedding層的前向傳播邏輯
參數(shù)x:這里代表輸入給模型的單詞文本通過詞表映射后的one-hot向量
將x傳給self.lut并與根號下self.d_model相乘作為結(jié)果返回
"""
embedds = self.lut(x)
return embedds * math.sqrt(self.d_model)
2.2 位置編碼:
Positional Encodding位置編碼的作用是為模型提供當(dāng)前時間步的前后出現(xiàn)順序的信息。因為Transformer不像RNN那樣的循環(huán)結(jié)構(gòu)有前后不同時間步輸入間天然的先后順序,所有的時間步是同時輸入,并行推理的,因此在時間步的特征中融合進(jìn)位置編碼的信息是合理的。
位置編碼可以有很多選擇,可以是固定的,也可以設(shè)置成可學(xué)習(xí)的參數(shù)。
這里,我們使用固定的位置編碼。具體地,使用不同頻率的sin和cos函數(shù)來進(jìn)行位置編碼,如下所示:
其中pos代表時間步的下標(biāo)索引,向量 也就是第pos個時間步的位置編碼,編碼長度同Embedding層,這里我們設(shè)置的是512。上面有兩個公式,代表著位置編碼向量中的元素,奇數(shù)位置和偶數(shù)位置使用兩個不同的公式。
思考:為什么上面的公式可以作為位置編碼?
我的理解:在上面公式的定義下,時間步p和時間步p+k的位置編碼的內(nèi)積,即 是與p無關(guān),只與k有關(guān)的定值(不妨自行證明下試試)。也就是說,任意兩個相距k個時間步的位置編碼向量的內(nèi)積都是相同的,這就相當(dāng)于蘊含了兩個時間步之間相對位置關(guān)系的信息。此外,每個時間步的位置編碼又是唯一的,這兩個很好的性質(zhì)使得上面的公式作為位置編碼是有理論保障的。
下面是位置編碼模塊的代碼實現(xiàn):
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
位置編碼器類的初始化函數(shù)
共有三個參數(shù),分別是
d_model:詞嵌入維度
dropout: dropout觸發(fā)比率
max_len:每個句子的最大長度
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings
# 注意下面代碼的計算方式與公式中給出的是不同的,但是是等價的,你可以嘗試簡單推導(dǎo)證明一下。
# 這樣計算是為了避免中間的數(shù)值計算結(jié)果超出float的范圍,
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
因此,可以認(rèn)為,最終模型的輸入是若干個時間步對應(yīng)的embedding,每一個時間步對應(yīng)一個embedding,可以理解為是當(dāng)前時間步的一個綜合的特征信息,即包含了本身的語義信息,又包含了當(dāng)前時間步在整個句子中的位置信息。
2.3 Encoder和Decoder都包含輸入模塊
此外有一個點剛剛接觸Transformer的同學(xué)可能不太理解,編碼器和解碼器兩個部分都包含輸入,且兩部分的輸入的結(jié)構(gòu)是相同的,只是推理時的用法不同,編碼器只推理一次,而解碼器是類似RNN那樣循環(huán)推理,不斷生成預(yù)測結(jié)果的。
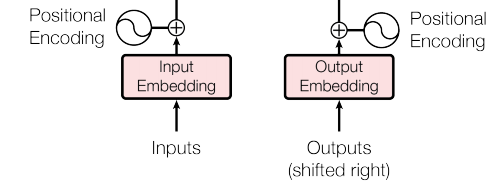
怎么理解?假設(shè)我們現(xiàn)在做的是一個法語-英語的機(jī)器翻譯任務(wù),想把Je suis étudiant翻譯為I am a student。
那么我們輸入給編碼器的就是時間步數(shù)為3的embedding數(shù)組,編碼器只進(jìn)行一次并行推理,即獲得了對于輸入的法語句子所提取的若干特征信息。
而對于解碼器,是循環(huán)推理,逐個單詞生成結(jié)果的。最開始,由于什么都還沒預(yù)測,我們會將編碼器提取的特征,以及一個句子起始符傳給解碼器,解碼器預(yù)期會輸出一個單詞I。然后有了預(yù)測的第一個單詞,我們就將I輸入給解碼器,會再預(yù)測出下一個單詞am,再然后我們將I am作為輸入喂給解碼器,以此類推直到預(yù)測出句子終止符完成預(yù)測。
3 Encoder
這一小節(jié)介紹編碼器部分的實現(xiàn)。
3.1 編碼器
編碼器作用是用于對輸入進(jìn)行特征提取,為解碼環(huán)節(jié)提供有效的語義信息
整體來看編碼器由N個編碼器層簡單堆疊而成,因此實現(xiàn)非常簡單,代碼如下:
# 定義一個clones函數(shù),來更方便的將某個結(jié)構(gòu)復(fù)制若干份
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"""
Encoder
The encoder is composed of a stack of N=6 identical layers.
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
# 調(diào)用時會將編碼器層傳進(jìn)來,我們簡單克隆N分,疊加在一起,組成完整的Encoder
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
上面的代碼中有一個小細(xì)節(jié),就是編碼器的輸入除了x,也就是embedding以外,還有一個mask,為了介紹連續(xù)性,這里先忽略,后面會講解。
下面我們來看看單個的編碼器層都包含什么,如何實現(xiàn)。
3.2 編碼器層
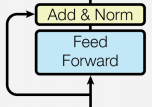
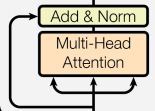
每個編碼器層由兩個子層連接結(jié)構(gòu)組成:
第一個子層包括一個多頭自注意力層和規(guī)范化層以及一個殘差連接;
第二個子層包括一個前饋全連接層和規(guī)范化層以及一個殘差連接;
如下圖所示:
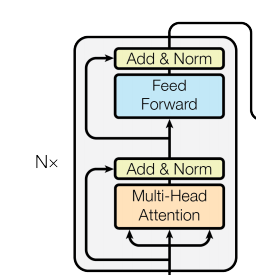
可以看到,兩個子層的結(jié)構(gòu)其實是一致的,只是中間核心層的實現(xiàn)不同
我們先定義一個SubLayerConnection類來描述這種結(jié)構(gòu)關(guān)系
class SublayerConnection(nn.Module):
"""
實現(xiàn)子層連接結(jié)構(gòu)的類
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# 原paper的方案
#sublayer_out = sublayer(x)
#x_norm = self.norm(x + self.dropout(sublayer_out))
# 稍加調(diào)整的版本
sublayer_out = sublayer(x)
sublayer_out = self.dropout(sublayer_out)
x_norm = x + self.norm(sublayer_out)
return x_norm
注:上面的實現(xiàn)中,我對殘差的鏈接方案進(jìn)行了小小的調(diào)整,和原論文有所不同。把x從norm中拿出來,保證永遠(yuǎn)有一條“高速公路”,這樣理論上會收斂的快一些,但我無法確保這樣做一定是對的,請一定注意。
定義好了SubLayerConnection,我們就可以實現(xiàn)EncoderLayer的結(jié)構(gòu)了
class EncoderLayer(nn.Module):
"EncoderLayer is made up of two sublayer: self-attn and feed forward"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size # embedding's dimention of model, 默認(rèn)512
def forward(self, x, mask):
# attention sub layer
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# feed forward sub layer
z = self.sublayer[1](x, self.feed_forward)
return z
繼續(xù)往下拆解,我們需要了解 attention層 和 feed_forward層的結(jié)構(gòu)以及如何實現(xiàn)。
3.3 注意力機(jī)制
人類在觀察事物時,無法同時仔細(xì)觀察眼前的一切,只能聚焦到某一個局部。通常我們大腦在簡單了解眼前的場景后,能夠很快把注意力聚焦到最有價值的局部來仔細(xì)觀察,從而作出有效判斷。或許是基于這樣的啟發(fā),大家想到了在算法中利用注意力機(jī)制。
注意力計算:它需要三個指定的輸入Q(query),K(key),V(value),然后通過下面公式得到注意力的計算結(jié)果。
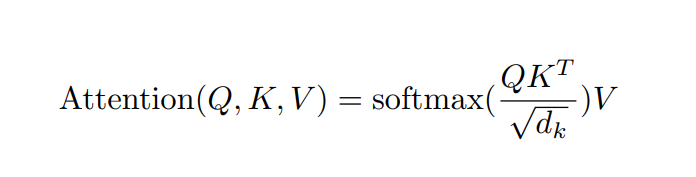
計算流程圖如下:
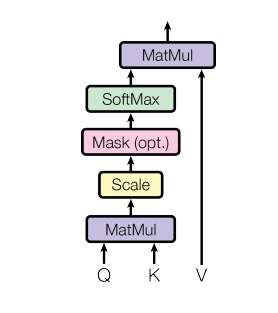
可以這么簡單的理解,當(dāng)前時間步的注意力計算結(jié)果,是一個組系數(shù) * 每個時間步的特征向量value的累加,而這個系數(shù),通過當(dāng)前時間步的query和其他時間步對應(yīng)的key做內(nèi)積得到,這個過程相當(dāng)于用自己的query對別的時間步的key做查詢,判斷相似度,決定以多大的比例將對應(yīng)時間步的信息繼承過來。
注意力機(jī)制的原理和思考十分值得深究,鑒于本文篇幅已經(jīng)很長,這里只著眼于代碼實現(xiàn),如果你在閱讀前對Transformer的原理完全不了解,獲取更多的原理講解,這里推薦兩個學(xué)習(xí)資料:
李宏毅老師的B站視頻:https://www.bilibili.com/video/BV1J441137V6?from=search&seid=3530913447603589730
DataWhale開源項目:https://github.com/datawhalechina/learn-nlp-with-transformer
下面是注意力模塊的實現(xiàn)代碼:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
#首先取query的最后一維的大小,對應(yīng)詞嵌入維度
d_k = query.size(-1)
#按照注意力公式,將query與key的轉(zhuǎn)置相乘,這里面key是將最后兩個維度進(jìn)行轉(zhuǎn)置,再除以縮放系數(shù)得到注意力得分張量scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
#接著判斷是否使用掩碼張量
if mask is not None:
#使用tensor的masked_fill方法,將掩碼張量和scores張量每個位置一一比較,如果掩碼張量則對應(yīng)的scores張量用-1e9這個置來替換
scores = scores.masked_fill(mask == 0, -1e9)
#對scores的最后一維進(jìn)行softmax操作,使用F.softmax方法,這樣獲得最終的注意力張量
p_attn = F.softmax(scores, dim = -1)
#之后判斷是否使用dropout進(jìn)行隨機(jī)置0
if dropout is not None:
p_attn = dropout(p_attn)
#最后,根據(jù)公式將p_attn與value張量相乘獲得最終的query注意力表示,同時返回注意力張量
return torch.matmul(p_attn, value), p_attn
3.4 多頭注意力機(jī)制
剛剛介紹了attention機(jī)制,在搭建EncoderLayer時候所使用的Attention模塊,實際使用的是多頭注意力,可以簡單理解為多個注意力模塊組合在一起。
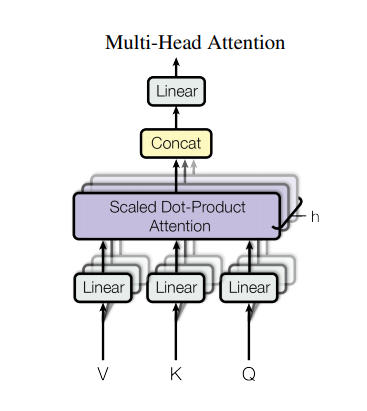
多頭注意力機(jī)制的作用:這種結(jié)構(gòu)設(shè)計能讓每個注意力機(jī)制去優(yōu)化每個詞匯的不同特征部分,從而均衡同一種注意力機(jī)制可能產(chǎn)生的偏差,讓詞義擁有來自更多元表達(dá),實驗表明可以從而提升模型效果。
舉個更形象的例子,bank是銀行的意思,如果只有一個注意力模塊,那么它大概率會學(xué)習(xí)去關(guān)注類似money、loan貸款這樣的詞。如果我們使用多個多頭機(jī)制,那么不同的頭就會去關(guān)注不同的語義,比如bank還有一種含義是河岸,那么可能有一個頭就會去關(guān)注類似river這樣的詞匯,這時多頭注意力的價值就體現(xiàn)出來了。
下面是多頭注意力機(jī)制的實現(xiàn)代碼:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
#在類的初始化時,會傳入三個參數(shù),h代表頭數(shù),d_model代表詞嵌入的維度,dropout代表進(jìn)行dropout操作時置0比率,默認(rèn)是0.1
super(MultiHeadedAttention, self).__init__()
#在函數(shù)中,首先使用了一個測試中常用的assert語句,判斷h是否能被d_model整除,這是因為我們之后要給每個頭分配等量的詞特征,也就是embedding_dim/head個
assert d_model % h == 0
#得到每個頭獲得的分割詞向量維度d_k
self.d_k = d_model // h
#傳入頭數(shù)h
self.h = h
#創(chuàng)建linear層,通過nn的Linear實例化,它的內(nèi)部變換矩陣是embedding_dim x embedding_dim,然后使用,為什么是四個呢,這是因為在多頭注意力中,Q,K,V各需要一個,最后拼接的矩陣還需要一個,因此一共是四個
self.linears = clones(nn.Linear(d_model, d_model), 4)
#self.attn為None,它代表最后得到的注意力張量,現(xiàn)在還沒有結(jié)果所以為None
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
#前向邏輯函數(shù),它輸入?yún)?shù)有四個,前三個就是注意力機(jī)制需要的Q,K,V,最后一個是注意力機(jī)制中可能需要的mask掩碼張量,默認(rèn)是None
if mask is not None:
# Same mask applied to all h heads.
#使用unsqueeze擴(kuò)展維度,代表多頭中的第n頭
mask = mask.unsqueeze(1)
#接著,我們獲得一個batch_size的變量,他是query尺寸的第1個數(shù)字,代表有多少條樣本
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
# 首先利用zip將輸入QKV與三個線性層組到一起,然后利用for循環(huán),將輸入QKV分別傳到線性層中,做完線性變換后,開始為每個頭分割輸入,這里使用view方法對線性變換的結(jié)構(gòu)進(jìn)行維度重塑,多加了一個維度h代表頭,這樣就意味著每個頭可以獲得一部分詞特征組成的句子,其中的-1代表自適應(yīng)維度,計算機(jī)會根據(jù)這種變換自動計算這里的值,然后對第二維和第三維進(jìn)行轉(zhuǎn)置操作,為了讓代表句子長度維度和詞向量維度能夠相鄰,這樣注意力機(jī)制才能找到詞義與句子位置的關(guān)系,從attention函數(shù)中可以看到,利用的是原始輸入的倒數(shù)第一和第二維,這樣我們就得到了每個頭的輸入
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
# 得到每個頭的輸入后,接下來就是將他們傳入到attention中,這里直接調(diào)用我們之前實現(xiàn)的attention函數(shù),同時也將mask和dropout傳入其中
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
# 通過多頭注意力計算后,我們就得到了每個頭計算結(jié)果組成的4維張量,我們需要將其轉(zhuǎn)換為輸入的形狀以方便后續(xù)的計算,因此這里開始進(jìn)行第一步處理環(huán)節(jié)的逆操作,先對第二和第三維進(jìn)行轉(zhuǎn)置,然后使用contiguous方法。這個方法的作用就是能夠讓轉(zhuǎn)置后的張量應(yīng)用view方法,否則將無法直接使用,所以,下一步就是使用view重塑形狀,變成和輸入形狀相同。
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
#最后使用線性層列表中的最后一個線性變換得到最終的多頭注意力結(jié)構(gòu)的輸出
return self.linears[-1](x)
3.5 前饋全連接層
EncoderLayer中另一個核心的子層是 Feed Forward Layer,我們這就介紹一下。
在進(jìn)行了Attention操作之后,encoder和decoder中的每一層都包含了一個全連接前向網(wǎng)絡(luò),對每個position的向量分別進(jìn)行相同的操作,包括兩個線性變換和一個ReLU激活輸出:
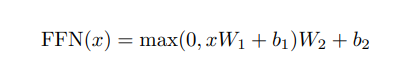
Feed Forward Layer 其實就是簡單的由兩個前向全連接層組成,核心在于,Attention模塊每個時間步的輸出都整合了所有時間步的信息,而Feed Forward Layer每個時間步只是對自己的特征的一個進(jìn)一步整合,與其他時間步無關(guān)。
實現(xiàn)代碼如下:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
#初始化函數(shù)有三個輸入?yún)?shù)分別是d_model,d_ff,和dropout=0.1,第一個是線性層的輸入維度也是第二個線性層的輸出維度,因為我們希望輸入通過前饋全連接層后輸入和輸出的維度不變,第二個參數(shù)d_ff就是第二個線性層的輸入維度和第一個線性層的輸出,最后一個是dropout置0比率。
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
#輸入?yún)?shù)為x,代表來自上一層的輸出,首先經(jīng)過第一個線性層,然后使用F中的relu函數(shù)進(jìn)行激活,之后再使用dropout進(jìn)行隨機(jī)置0,最后通過第二個線性層w2,返回最終結(jié)果
return self.w_2(self.dropout(F.relu(self.w_1(x))))
到這里Encoder中包含的主要結(jié)構(gòu)就都介紹了,上面的代碼中涉及了兩個小細(xì)節(jié)還沒有介紹,layer normalization 和 mask,下面來簡單講解一下。
3.6. 規(guī)范化層
規(guī)范化層的作用:它是所有深層網(wǎng)絡(luò)模型都需要的標(biāo)準(zhǔn)網(wǎng)絡(luò)層,因為隨著網(wǎng)絡(luò)層數(shù)的增加,通過多層的計算后輸出可能開始出現(xiàn)過大或過小的情況,這樣可能會導(dǎo)致學(xué)習(xí)過程出現(xiàn)異常,模型可能收斂非常慢。因此都會在一定層后接規(guī)范化層進(jìn)行數(shù)值的規(guī)范化,使其特征數(shù)值在合理范圍內(nèi)。
Transformer中使用的normalization手段是layer norm,實現(xiàn)代碼很簡單,如下:
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, feature_size, eps=1e-6):
#初始化函數(shù)有兩個參數(shù),一個是features,表示詞嵌入的維度,另一個是eps它是一個足夠小的數(shù),在規(guī)范化公式的分母中出現(xiàn),防止分母為0,默認(rèn)是1e-6。
super(LayerNorm, self).__init__()
#根據(jù)features的形狀初始化兩個參數(shù)張量a2,和b2,第一初始化為1張量,也就是里面的元素都是1,第二個初始化為0張量,也就是里面的元素都是0,這兩個張量就是規(guī)范化層的參數(shù)。因為直接對上一層得到的結(jié)果做規(guī)范化公式計算,將改變結(jié)果的正常表征,因此就需要有參數(shù)作為調(diào)節(jié)因子,使其即能滿足規(guī)范化要求,又能不改變針對目標(biāo)的表征,最后使用nn.parameter封裝,代表他們是模型的參數(shù)
self.a_2 = nn.Parameter(torch.ones(feature_size))
self.b_2 = nn.Parameter(torch.zeros(feature_size))
#把eps傳到類中
self.eps = eps
def forward(self, x):
#輸入?yún)?shù)x代表來自上一層的輸出,在函數(shù)中,首先對輸入變量x求其最后一個維度的均值,并保持輸出維度與輸入維度一致,接著再求最后一個維度的標(biāo)準(zhǔn)差,然后就是根據(jù)規(guī)范化公式,用x減去均值除以標(biāo)準(zhǔn)差獲得規(guī)范化的結(jié)果。
#最后對結(jié)果乘以我們的縮放參數(shù),即a2,*號代表同型點乘,即對應(yīng)位置進(jìn)行乘法操作,加上位移參b2,返回即可
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
3.7 掩碼及其作用
掩碼:掩代表遮掩,碼就是我們張量中的數(shù)值,它的尺寸不定,里面一般只有0和1;代表位置被遮掩或者不被遮掩。
掩碼的作用:在transformer中,掩碼主要的作用有兩個,一個是屏蔽掉無效的padding區(qū)域,一個是屏蔽掉來自“未來”的信息。Encoder中的掩碼主要是起到第一個作用,Decoder中的掩碼則同時發(fā)揮著兩種作用。
屏蔽掉無效的padding區(qū)域:我們訓(xùn)練需要組batch進(jìn)行,就以機(jī)器翻譯任務(wù)為例,一個batch中不同樣本的輸入長度很可能是不一樣的,此時我們要設(shè)置一個最大句子長度,然后對空白區(qū)域進(jìn)行padding填充,而填充的區(qū)域無論在Encoder還是Decoder的計算中都是沒有意義的,因此需要用mask進(jìn)行標(biāo)識,屏蔽掉對應(yīng)區(qū)域的響應(yīng)。
屏蔽掉來自未來的信息:我們已經(jīng)學(xué)習(xí)了attention的計算流程,它是會綜合所有時間步的計算的,那么在解碼的時候,就有可能獲取到未來的信息,這是不行的。因此,這種情況也需要我們使用mask進(jìn)行屏蔽。現(xiàn)在還沒介紹到Decoder,如果沒完全理解,可以之后再回過頭來思考下。
mask的構(gòu)造代碼如下:
def subsequent_mask(size):
#生成向后遮掩的掩碼張量,參數(shù)size是掩碼張量最后兩個維度的大小,它最后兩維形成一個方陣
"Mask out subsequent positions."
attn_shape = (1, size, size)
#然后使用np.ones方法向這個形狀中添加1元素,形成上三角陣
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
#最后將numpy類型轉(zhuǎn)化為torch中的tensor,內(nèi)部做一個1- 的操作。這個其實是做了一個三角陣的反轉(zhuǎn),subsequent_mask中的每個元素都會被1減。
#如果是0,subsequent_mask中的該位置由0變成1
#如果是1,subsequect_mask中的該位置由1變成0
return torch.from_numpy(subsequent_mask) == 0
以上便是編碼器部分的全部內(nèi)容,有了這部分內(nèi)容的鋪墊,解碼器的介紹就會輕松一些。
4 Decoder
本小節(jié)介紹解碼器部分的實現(xiàn)
4.1 解碼器整體結(jié)構(gòu)
解碼器的作用:根據(jù)編碼器的結(jié)果以及上一次預(yù)測的結(jié)果,輸出序列的下一個結(jié)果。
整體結(jié)構(gòu)上,解碼器也是由N個相同層堆疊而成。構(gòu)造代碼如下:
#使用類Decoder來實現(xiàn)解碼器
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
#初始化函數(shù)的參數(shù)有兩個,第一個就是解碼器層layer,第二個是解碼器層的個數(shù)N
super(Decoder, self).__init__()
#首先使用clones方法克隆了N個layer,然后實例化一個規(guī)范化層,因為數(shù)據(jù)走過了所有的解碼器層后最后要做規(guī)范化處理。
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
#forward函數(shù)中的參數(shù)有4個,x代表目標(biāo)數(shù)據(jù)的嵌入表示,memory是編碼器層的輸出,source_mask,target_mask代表源數(shù)據(jù)和目標(biāo)數(shù)據(jù)的掩碼張量,然后就是對每個層進(jìn)行循環(huán),當(dāng)然這個循環(huán)就是變量x通過每一個層的處理,得出最后的結(jié)果,再進(jìn)行一次規(guī)范化返回即可。
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
4.2 解碼器層
每個解碼器層由三個子層連接結(jié)構(gòu)組成,第一個子層連接結(jié)構(gòu)包括一個多頭自注意力子層和規(guī)范化層以及一個殘差連接,第二個子層連接結(jié)構(gòu)包括一個多頭注意力子層和規(guī)范化層以及一個殘差連接,第三個子層連接結(jié)構(gòu)包括一個前饋全連接子層和規(guī)范化層以及一個殘差連接。
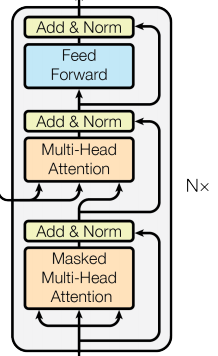
解碼器層中的各個子模塊,如,多頭注意力機(jī)制,規(guī)范化層,前饋全連接都與編碼器中的實現(xiàn)相同。
有一個細(xì)節(jié)需要注意,第一個子層的多頭注意力和編碼器中完全一致,第二個子層,它的多頭注意力模塊中,query來自上一個子層,key 和 value 來自編碼器的輸出。可以這樣理解,就是第二層負(fù)責(zé),利用解碼器已經(jīng)預(yù)測出的信息作為query,去編碼器提取的各種特征中,查找相關(guān)信息并融合到當(dāng)前特征中,來完成預(yù)測。
#使用DecoderLayer的類實現(xiàn)解碼器層
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
#初始化函數(shù)的參數(shù)有5個,分別是size,代表詞嵌入的維度大小,同時也代表解碼器的尺寸,第二個是self_attn,多頭自注意力對象,也就是說這個注意力機(jī)制需要Q=K=V,第三個是src_attn,多頭注意力對象,這里Q!=K=V,第四個是前饋全連接層對象,最后就是dropout置0比率
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
#按照結(jié)構(gòu)圖使用clones函數(shù)克隆三個子層連接對象
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
#forward函數(shù)中的參數(shù)有4個,分別是來自上一層的輸入x,來自編碼器層的語義存儲變量memory,以及源數(shù)據(jù)掩碼張量和目標(biāo)數(shù)據(jù)掩碼張量,將memory表示成m之后方便使用。
"Follow Figure 1 (right) for connections."
m = memory
#將x傳入第一個子層結(jié)構(gòu),第一個子層結(jié)構(gòu)的輸入分別是x和self-attn函數(shù),因為是自注意力機(jī)制,所以Q,K,V都是x,最后一個參數(shù)時目標(biāo)數(shù)據(jù)掩碼張量,這時要對目標(biāo)數(shù)據(jù)進(jìn)行遮掩,因為此時模型可能還沒有生成任何目標(biāo)數(shù)據(jù)。
#比如在解碼器準(zhǔn)備生成第一個字符或詞匯時,我們其實已經(jīng)傳入了第一個字符以便計算損失,但是我們不希望在生成第一個字符時模型能利用這個信息,因此我們會將其遮掩,同樣生成第二個字符或詞匯時,模型只能使用第一個字符或詞匯信息,第二個字符以及之后的信息都不允許被模型使用。
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
#接著進(jìn)入第二個子層,這個子層中常規(guī)的注意力機(jī)制,q是輸入x;k,v是編碼層輸出memory,同樣也傳入source_mask,但是進(jìn)行源數(shù)據(jù)遮掩的原因并非是抑制信息泄露,而是遮蔽掉對結(jié)果沒有意義的padding。
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
#最后一個子層就是前饋全連接子層,經(jīng)過它的處理后就可以返回結(jié)果,這就是我們的解碼器結(jié)構(gòu)
return self.sublayer[2](x, self.feed_forward)
5 模型輸出
輸出部分就很簡單了,每個時間步都過一個 線性層 + softmax層
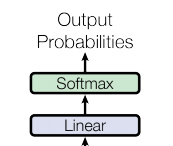
線性層的作用:通過對上一步的線性變化得到指定維度的輸出,也就是轉(zhuǎn)換維度的作用。轉(zhuǎn)換后的維度對應(yīng)著輸出類別的個數(shù),如果是翻譯任務(wù),那就對應(yīng)的是文字字典的大小。
代碼如下:
#將線性層和softmax計算層一起實現(xiàn),因為二者的共同目標(biāo)是生成最后的結(jié)構(gòu)
#因此把類的名字叫做Generator,生成器類
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
#初始化函數(shù)的輸入?yún)?shù)有兩個,d_model代表詞嵌入維度,vocab.size代表詞表大小
super(Generator, self).__init__()
#首先就是使用nn中的預(yù)定義線性層進(jìn)行實例化,得到一個對象self.proj等待使用
#這個線性層的參數(shù)有兩個,就是初始化函數(shù)傳進(jìn)來的兩個參數(shù):d_model,vocab_size
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
#前向邏輯函數(shù)中輸入是上一層的輸出張量x,在函數(shù)中,首先使用上一步得到的self.proj對x進(jìn)行線性變化,然后使用F中已經(jīng)實現(xiàn)的log_softmax進(jìn)行softmax處理。
return F.log_softmax(self.proj(x), dim=-1)
6 模型構(gòu)建
下面是Transformer總體架構(gòu)圖,回顧一下,再看這張圖,是不是每個模塊的作用都有了基本的認(rèn)知。
下面我們就可以搭建出整個網(wǎng)絡(luò)的結(jié)構(gòu)
# Model Architecture
#使用EncoderDecoder類來實現(xiàn)編碼器-解碼器結(jié)構(gòu)
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture.
Base for this and many other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
#初始化函數(shù)中有5個參數(shù),分別是編碼器對象,解碼器對象,源數(shù)據(jù)嵌入函數(shù),目標(biāo)數(shù)據(jù)嵌入函數(shù),以及輸出部分的類別生成器對象.
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed # input embedding module(input embedding + positional encode)
self.tgt_embed = tgt_embed # ouput embedding module
self.generator = generator # output generation module
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
#在forward函數(shù)中,有四個參數(shù),source代表源數(shù)據(jù),target代表目標(biāo)數(shù)據(jù),source_mask和target_mask代表對應(yīng)的掩碼張量,在函數(shù)中,將source source_mask傳入編碼函數(shù),得到結(jié)果后與source_mask target 和target_mask一同傳給解碼函數(shù)
memory = self.encode(src, src_mask)
res = self.decode(memory, src_mask, tgt, tgt_mask)
return res
def encode(self, src, src_mask):
#編碼函數(shù),以source和source_mask為參數(shù),使用src_embed對source做處理,然后和source_mask一起傳給self.encoder
src_embedds = self.src_embed(src)
return self.encoder(src_embedds, src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
#解碼函數(shù),以memory即編碼器的輸出,source_mask target target_mask為參數(shù),使用tgt_embed對target做處理,然后和source_mask,target_mask,memory一起傳給self.decoder
target_embedds = self.tgt_embed(tgt)
return self.decoder(target_embedds, memory, src_mask, tgt_mask)
# Full Model
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
構(gòu)建模型
params:
src_vocab:
tgt_vocab:
N: 編碼器和解碼器堆疊基礎(chǔ)模塊的個數(shù)
d_model: 模型中embedding的size,默認(rèn)512
d_ff: FeedForward Layer層中embedding的size,默認(rèn)2048
h: MultiHeadAttention中多頭的個數(shù),必須被d_model整除
dropout:
"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
7 實戰(zhàn)案例
下面我們用一個人造的玩具級的小任務(wù),來實戰(zhàn)體驗下Transformer的訓(xùn)練,加深我們的理解,并且驗證我們上面所述代碼是否work。
任務(wù)描述:針對數(shù)字序列進(jìn)行學(xué)習(xí),學(xué)習(xí)的最終目標(biāo)是使模型學(xué)會輸出與輸入的序列刪除第一個字符之后的相同的序列,如輸入[1,2,3,4,5],我們嘗試讓模型學(xué)會輸出[2,3,4,5]。
顯然這對模型來說并不難,應(yīng)該簡單的若干次迭代就能學(xué)會。
代碼實現(xiàn)的基本的步驟是:
第一步:構(gòu)建并生成人工數(shù)據(jù)集
第二步:構(gòu)建Transformer模型及相關(guān)準(zhǔn)備工作
第三步:運行模型進(jìn)行訓(xùn)練和評估
第四步:使用模型進(jìn)行貪婪解碼
篇幅的原因,這里就不對數(shù)據(jù)構(gòu)造部分的代碼進(jìn)行介紹了,感興趣歡迎大家查看項目的源碼,并且親自運行起來跑跑看:https://github.com/datawhalechina/dive-into-cv-pytorch/tree/master/code/chapter06_transformer/6.1_hello_transformer
訓(xùn)練的大致流程如下:
# Train the simple copy task.
device = "cuda"
nrof_epochs = 20
batch_size = 32
V = 11 # 詞典的數(shù)量
sequence_len = 15 # 生成的序列數(shù)據(jù)的長度
nrof_batch_train_epoch = 30 # 訓(xùn)練時每個epoch多少個batch
nrof_batch_valid_epoch = 10 # 驗證時每個epoch多少個batch
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400, optimizer)
if device == "cuda":
model.cuda()
for epoch in range(nrof_epochs):
print(f"\nepoch {epoch}")
print("train...")
model.train()
data_iter = data_gen(V, sequence_len, batch_size, nrof_batch_train_epoch, device)
loss_compute = SimpleLossCompute(model.generator, criterion, model_opt)
train_mean_loss = run_epoch(data_iter, model, loss_compute, device)
print("valid...")
model.eval()
valid_data_iter = data_gen(V, sequence_len, batch_size, nrof_batch_valid_epoch, device)
valid_loss_compute = SimpleLossCompute(model.generator, criterion, None)
valid_mean_loss = run_epoch(valid_data_iter, model, valid_loss_compute, device)
print(f"valid loss: {valid_mean_loss}")
訓(xùn)好模型后,使用貪心解碼的策略,進(jìn)行預(yù)測。
推理得到預(yù)測結(jié)果的方法并不是唯一的,貪心解碼是最常用的,我們在 6.1.2 模型輸入的小節(jié)中已經(jīng)介紹過,其實就是先從一個句子起始符開始,每次推理解碼器得到一個輸出,然后將得到的輸出加到解碼器的輸入中,再次推理得到一個新的輸出,循環(huán)往復(fù)直到預(yù)測出句子的終止符,此時將所有預(yù)測連在一起便得到了完整的預(yù)測結(jié)果。
貪心解碼的代碼如下:
# greedy decode
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
# ys代表目前已生成的序列,最初為僅包含一個起始符的序列,不斷將預(yù)測結(jié)果追加到序列最后
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
print("greedy decode")
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]])).cuda()
src_mask = Variable(torch.ones(1, 1, 10)).cuda()
pred_result = greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)
print(pred_result[:, 1:])
運行我們的訓(xùn)練腳本,訓(xùn)練過程與預(yù)測結(jié)果打印如下:
...
epoch 18
train...
Epoch Step: 1 Loss: 0.078836 Tokens per Sec: 13734.076172
valid...
Epoch Step: 1 Loss: 0.029015 Tokens per Sec: 23311.662109
valid loss: 0.03555255010724068
epoch 19
train...
Epoch Step: 1 Loss: 0.042386 Tokens per Sec: 13782.227539
valid...
Epoch Step: 1 Loss: 0.022001 Tokens per Sec: 23307.326172
valid loss: 0.014436692930758
greedy decode
tensor([[ 2, 3, 4, 5, 6, 7, 8, 9, 10]], device='cuda:0')
可以看到,由于任務(wù)非常簡單,通過20epoch的簡單訓(xùn)練,loss已經(jīng)收斂到很低。
測試用例[1,2,3,4,5,6,7,8,9,10] 的預(yù)測結(jié)果為[2,3,4,5,6,7,8,9,10],符合預(yù)期,說明我們的Transformer模型搭建正確了,成功~
小結(jié)
本次我們介紹了Transformer的基本原理,并且由外向內(nèi)逐步拆解出每個模塊進(jìn)行了原理和代碼的講解,最后通過一個玩具級的demo實踐了Transformer的訓(xùn)練和推理流程。希望通過這些內(nèi)容,能夠讓初學(xué)者對Transformer有了更清晰的認(rèn)知。
本文參考:http://nlp.seas.harvard.edu/2018/04/03/attention.html
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
