
用Transformer完全替代CNN?

極市導(dǎo)讀
?本文不同于以往工作的地方在于,盡可能地將NLP領(lǐng)域的transformer不作修改地搬到了CV領(lǐng)域,并在大規(guī)模數(shù)據(jù)集上展現(xiàn)出了超過目前的一些SOTA的結(jié)果。>>加入極市CV技術(shù)交流群,走在計算機(jī)視覺的最前沿
這里將介紹一篇我認(rèn)為是比較新穎的一篇文章 ——《An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale》[1]。因為還是 ICLR 2021 under review,所以作者目前還是匿名的,但是看其實驗用到的TPU,能夠大概猜出應(yīng)該是Google爸爸的文章(看著實驗的配置,不得不感慨鈔能力的力量)。
1. Story
近年來,Transformer已經(jīng)成了NLP領(lǐng)域的標(biāo)準(zhǔn)配置,但是CV領(lǐng)域還是CNN(如ResNet, DenseNet等)占據(jù)了絕大多數(shù)的SOTA結(jié)果。
最近CV界也有很多文章將transformer遷移到CV領(lǐng)域,這些文章總的來說可以分為兩個大類:
將self-attention機(jī)制與常見的CNN架構(gòu)結(jié)合; 用self-attention機(jī)制完全替代CNN。
本文采用的也是第2種思路。雖然已經(jīng)有很多工作用self-attention完全替代CNN,且在理論上效率比較高,但是它們用了特殊的attention機(jī)制,無法從硬件層面加速,所以目前CV領(lǐng)域的SOTA結(jié)果還是被CNN架構(gòu)所占據(jù)。
文章不同于以往工作的地方,就是盡可能地將NLP領(lǐng)域的transformer不作修改地搬到CV領(lǐng)域來。但是NLP處理的語言數(shù)據(jù)是序列化的,而CV中處理的圖像數(shù)據(jù)是三維的(長、寬和channels)。
所以我們需要一個方式將圖像這種三維數(shù)據(jù)轉(zhuǎn)化為序列化的數(shù)據(jù)。文章中,圖像被切割成一個個patch,這些patch按照一定的順序排列,就成了序列化的數(shù)據(jù)。(具體將在下面講述)
在實驗中,作者發(fā)現(xiàn),在中等規(guī)模的數(shù)據(jù)集上(例如ImageNet),transformer模型的表現(xiàn)不如ResNets;而當(dāng)數(shù)據(jù)集的規(guī)模擴(kuò)大,transformer模型的效果接近或者超過了目前的一些SOTA結(jié)果。作者認(rèn)為是大規(guī)模的訓(xùn)練可以鼓勵transformer學(xué)到CNN結(jié)構(gòu)所擁有的translation equivariance?和locality.
translation equivariance解釋:
https://aboveintelligent.com/ml-cnn-translation-equivariance-and-invariance-da12e8ab7049
2. Model

Vision Transformer (ViT)結(jié)構(gòu)示意圖
模型的結(jié)構(gòu)其實比較簡單,可以分成以下幾個部分來理解:
a. 將圖像轉(zhuǎn)化為序列化數(shù)據(jù)
作者采用了了一個比較簡單的方式。如下圖所示。首先將圖像分割成一個個patch,然后將每個patch reshape成一個向量,得到所謂的flattened patch。
具體地,如果圖片是? 維的,用 大小的patch去分割圖片可以得到? 個patch,那么每個patch的shape就是? ,轉(zhuǎn)化為向量后就是? 維的向量,將? 個patch reshape后的向量concat在一起就得到了一個? 的二維矩陣,相當(dāng)于NLP中輸入transformer的詞向量。

分割圖像得到patch
從上面的過程可以看出,當(dāng)patch的大小變化時(即? 變化時),每個patch reshape后得到的? 維向量的長度也會變化。為了避免模型結(jié)構(gòu)受到patch size的影響,作者對上述過程得到的flattened patches向量做了Linear Projection(如下圖所示),將不同長度的flattened patch向量轉(zhuǎn)化為固定長度的向量(記做? 維向量)。
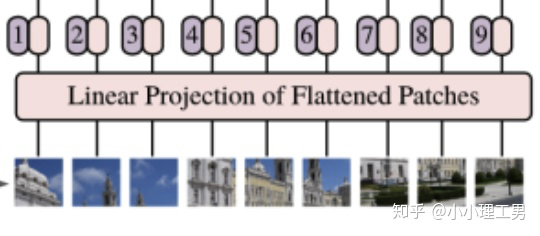
對flattened patches做linear projection
綜上,原本 維的圖片被轉(zhuǎn)化為了? 個? 維的向量(或者一個? 維的二維矩陣)。
b. Position embedding

positiion embedding示意圖
由于transformer模型本身是沒有位置信息的,和NLP中一樣,我們需要用position embedding將位置信息加到模型中去。
如上圖所示1,編號有0-9的紫色框表示各個位置的position embedding,而紫色框旁邊的粉色框則是經(jīng)過linear projection之后的flattened patch向量。文中采用將position embedding(即圖中紫色框)和patch embedding(即圖中粉色框)相加的方式結(jié)合position信息。
c. Learnable embedding
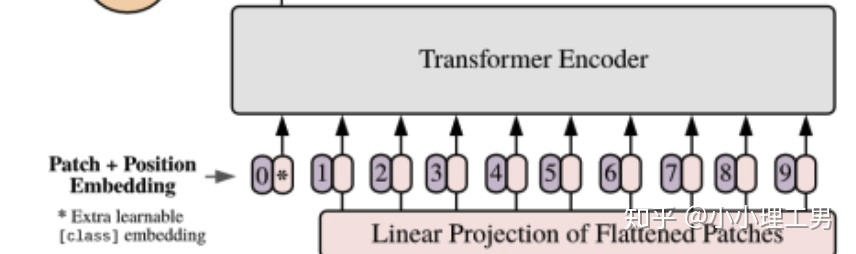
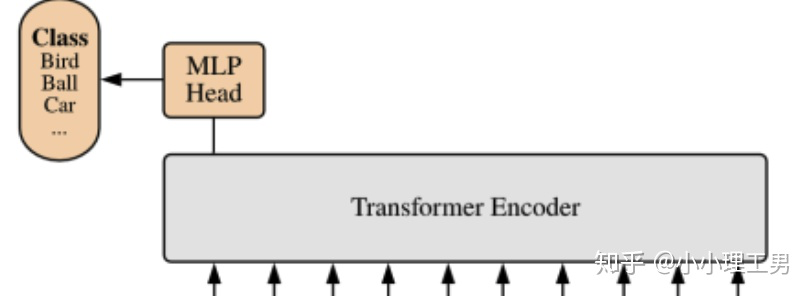
如果大家仔細(xì)看上圖,就會發(fā)現(xiàn)帶星號的粉色框(即0號紫色框右邊的那個)不是通過某個patch產(chǎn)生的。這個是一個learnable embedding(記作? ),其作用類似于BERT中的[class] token。在BERT中,[class] token經(jīng)過encoder后對應(yīng)的結(jié)果作為整個句子的表示;類似地,這里? 經(jīng)過encoder后對應(yīng)的結(jié)果也作為整個圖的表示。
至于為什么BERT或者這篇文章的ViT要多加一個token呢?因為如果人為地指定一個embedding(例如本文中某個patch經(jīng)過Linear Projection得到的embedding)經(jīng)過encoder得到的結(jié)果作為整體的表示,則不可避免地會使得整體表示偏向于這個指定embedding的信息(例如圖像的表示偏重于反映某個patch的信息)。而這個新增的token沒有語義信息(即在句子中與任何的詞無關(guān),在圖像中與任何的patch無關(guān)),所以不會造成上述問題,能夠比較公允地反映全圖的信息。
d. Transformer encoder
Transformer Encoder結(jié)構(gòu)和NLP中transformer結(jié)構(gòu)基本上相同,所以這里只給出其結(jié)構(gòu)圖,和公式化的計算過程,也是順便用公式表達(dá)了之前所說的幾個部分內(nèi)容。
Transformer Encoder的結(jié)構(gòu)如下圖所示:
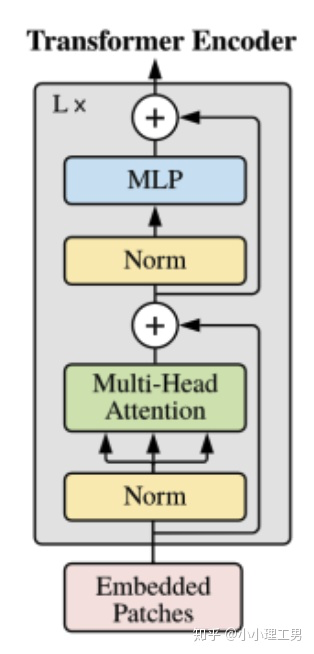
Transformer Encoder結(jié)構(gòu)圖
對于Encoder的第? 層,記其輸入為? ,輸出為? ,則計算過程為:
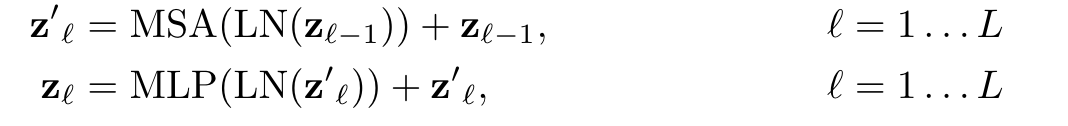
其中MSA為Multi-Head Self-Attention(即Transformer Encoder結(jié)構(gòu)圖中的綠色框),MLP為Multi-Layer Perceptron(即Transformer Encoder結(jié)構(gòu)圖中的藍(lán)色框),LN為Layer Norm(即Transformer Encoder結(jié)構(gòu)圖中的黃色框)。
Encoder第一層的輸入? 是通過下面的公式得到的:
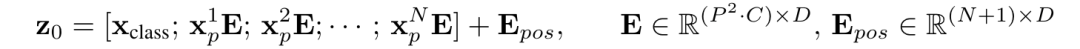
其中? 即未Linear Projection后的patch embedding(都是? 維),右乘? 維的矩陣 表示Linear Projection,得到的? 都是? 維向量;這? 個? 維向量和同樣是? 維向量的? concat就得到了? 維矩陣。加上? 個? 維position embedding拼成的 維矩陣? ,即得到了encoder的原始輸入? 。
3. 混合結(jié)構(gòu)
文中還提出了一個比較有趣的解決方案,將transformer和CNN結(jié)合,即將ResNet的中間層的feature map作為transformer的輸入。
和之前所說的將圖片分成patch然后reshape成sequence不同的是,在這種方案中,作者直接將ResNet某一層的feature map reshape成sequence,再通過Linear Projection變?yōu)門ransformer輸入的維度,然后直接輸入進(jìn)Transformer中。
4. Fine-tuning過程中高分辨率圖像的處理
在Fine-tuning到下游任務(wù)時,當(dāng)圖像的分辨率增大時(即圖像的長和寬增大時),如果保持patch大小不變,得到的patch個數(shù)將增加(記分辨率增大后新的patch個數(shù)為? )。但是由于在pretrain時,position embedding的個數(shù)和pretrain時分割得到的patch個數(shù)(即上文中的? )相同。則多出來的? 個positioin embedding在pretrain中是未定義或者無意義的。
為了解決這個問題,文章中提出用2D插值的方法,基于原圖中的位置信息,將pretrain中的? 個position embedding插值成? 個。這樣在得到? 個position embedding的同時也保證了position embedding的語義信息。
5. 實驗
實驗部分由于涉及到的細(xì)節(jié)較多就不具體介紹了,大家如果感興趣可以參看原文。(不得不說Google的實驗?zāi)芰外n能力不是一般人能比的...)
主要的實驗結(jié)論在story中就已經(jīng)介紹過了,這里復(fù)制粘貼一下:在中等規(guī)模的數(shù)據(jù)集上(例如ImageNet),transformer模型的表現(xiàn)不如ResNets;而當(dāng)數(shù)據(jù)集的規(guī)模擴(kuò)大,transformer模型的效果接近或者超過了目前的一些SOTA結(jié)果。
比較有趣的是,作者還做了很多其他的分析來解釋transfomer的合理性。大家如果感興趣也可以參看原文,這里放幾張文章中的圖。


參考
1.https://openreview.net/forum?id=YicbFdNTTy
推薦閱讀
?ACCV 2020國際細(xì)粒度網(wǎng)絡(luò)圖像識別競賽正式開賽!
