
基于深度卷積神經(jīng)網(wǎng)絡(luò)的小樣本分割算法綜述
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號
重磅干貨,第一時(shí)間送達(dá)

介紹
相關(guān)工作
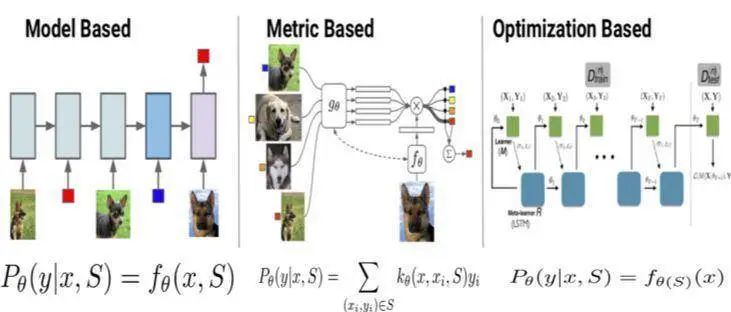
方法總結(jié)分類
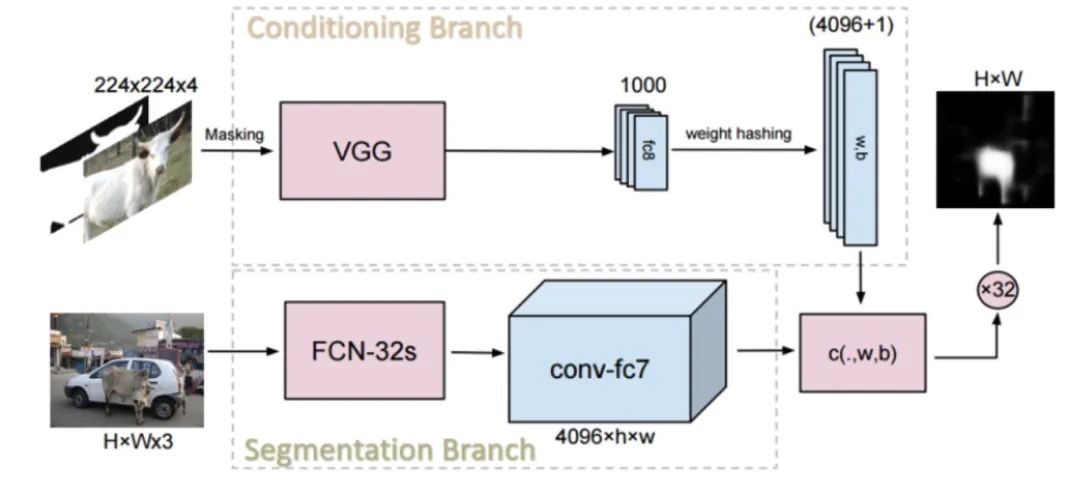
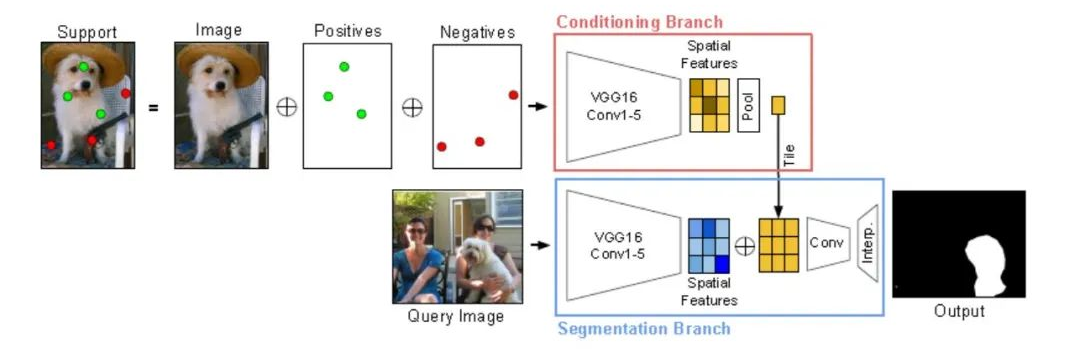
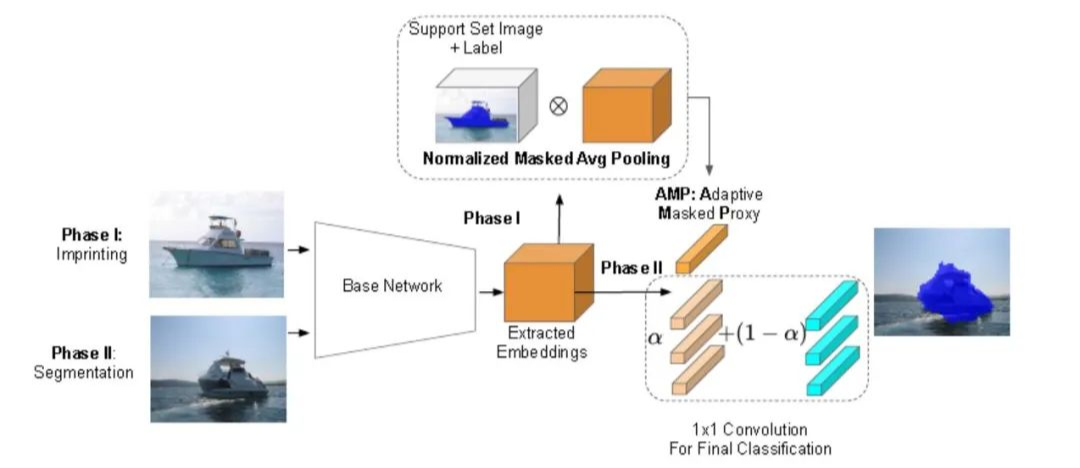
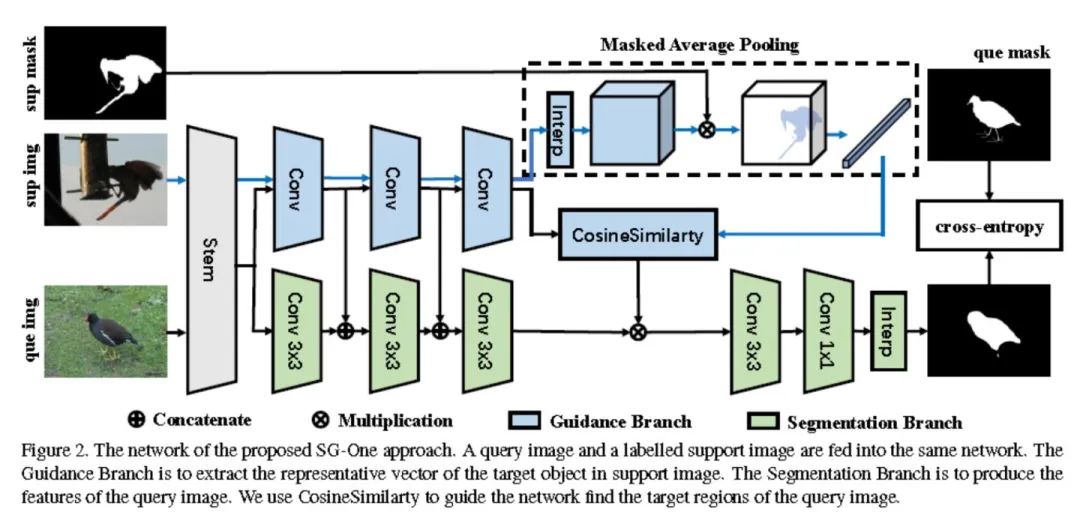
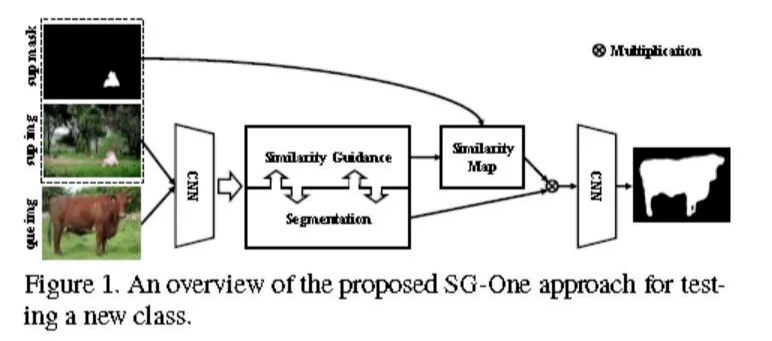
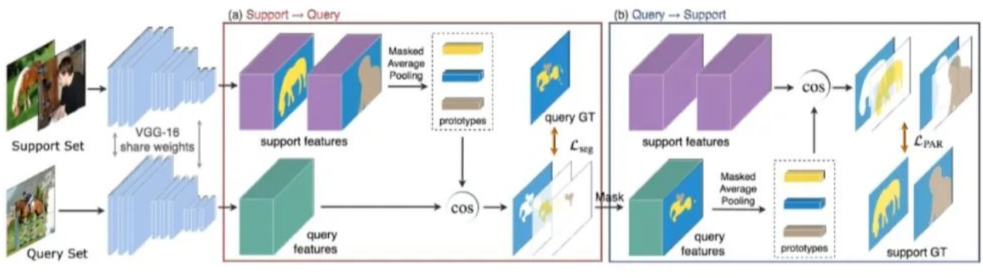
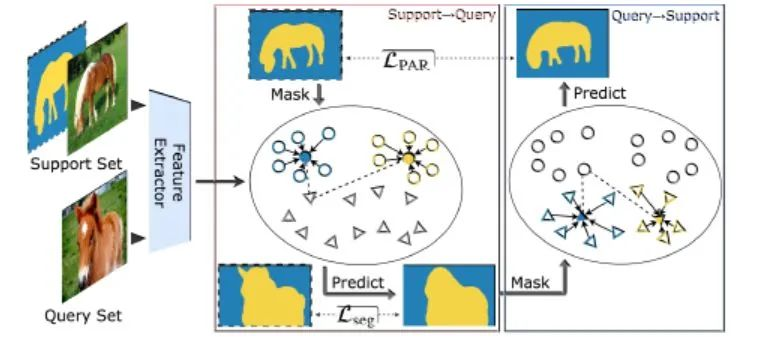
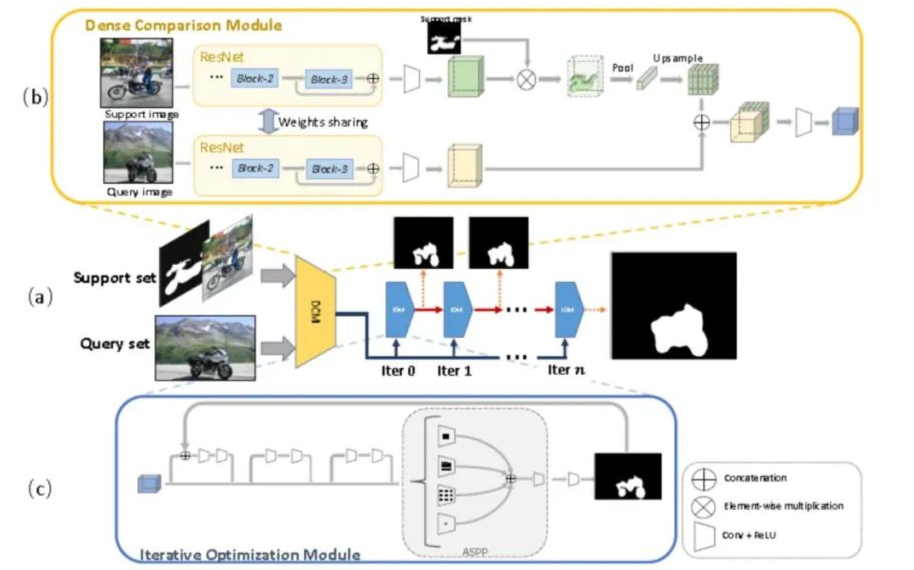
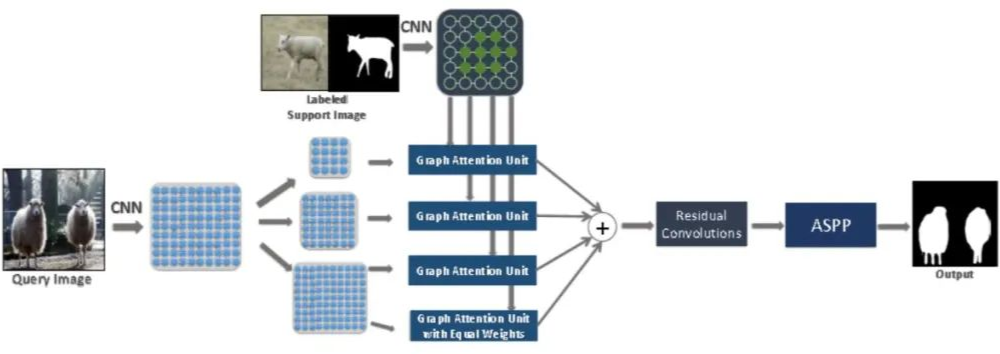
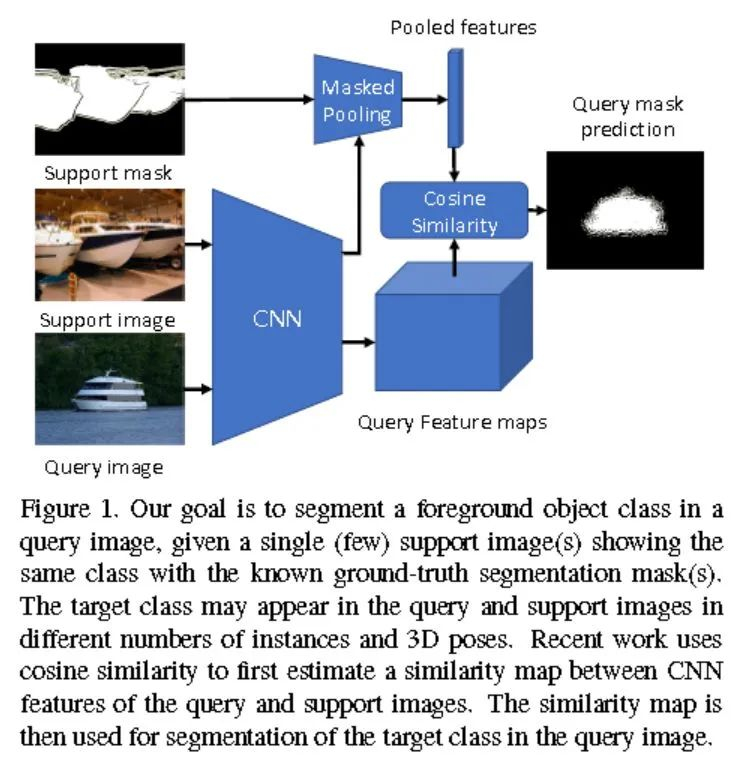
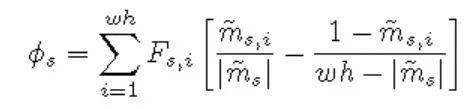
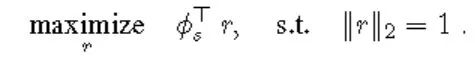
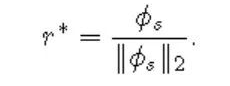
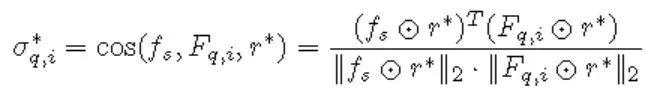
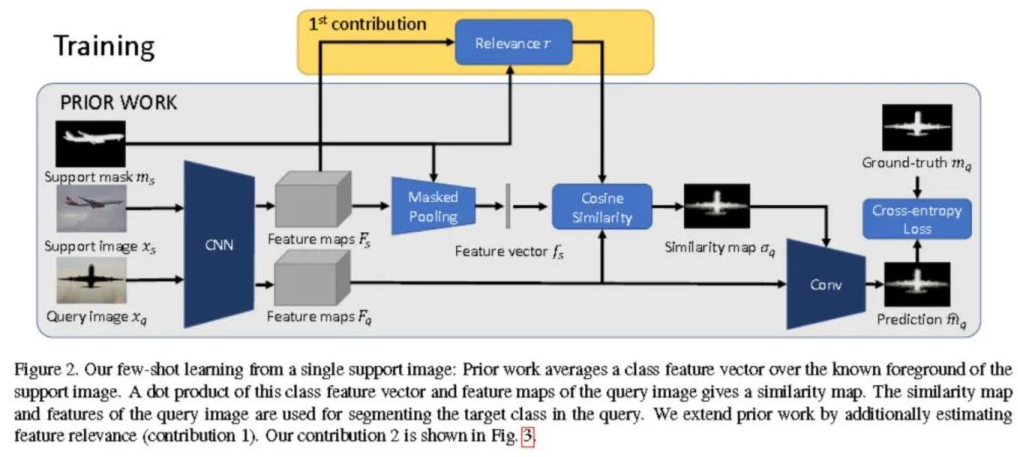
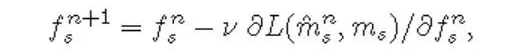
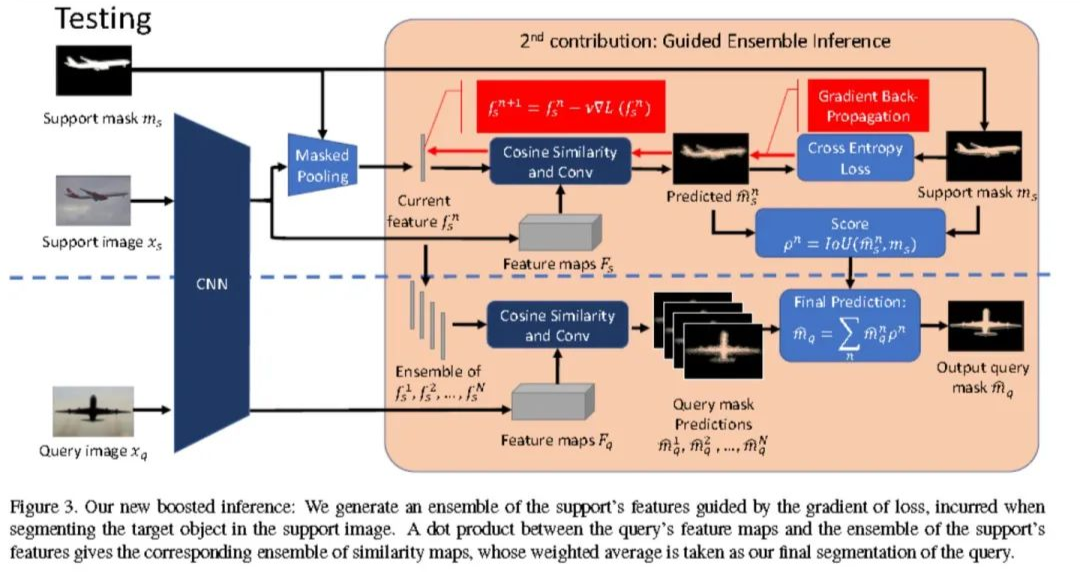

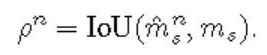
數(shù)據(jù)集介紹

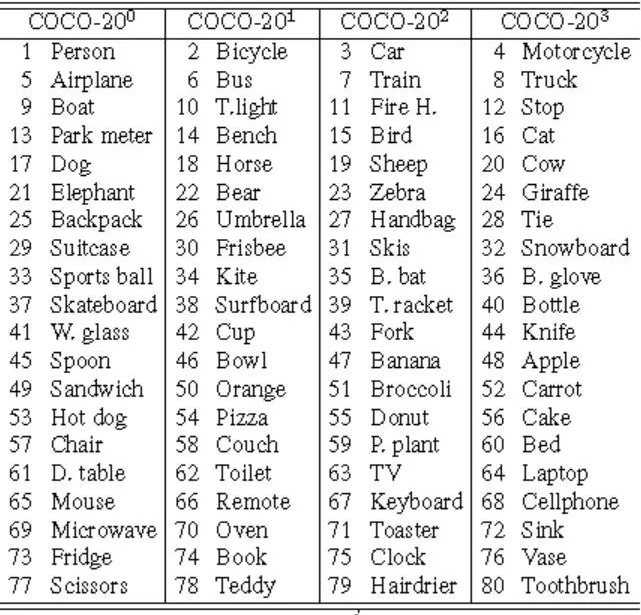
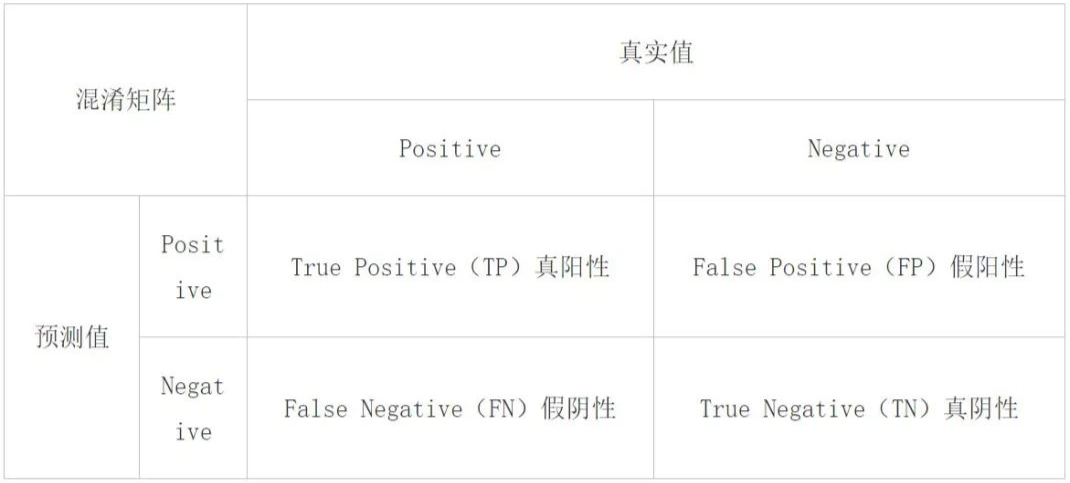
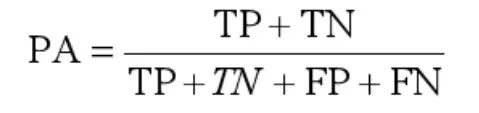
評測指標(biāo)介紹
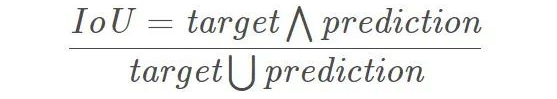
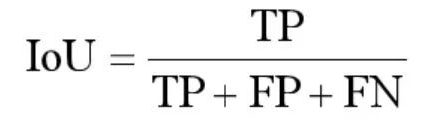

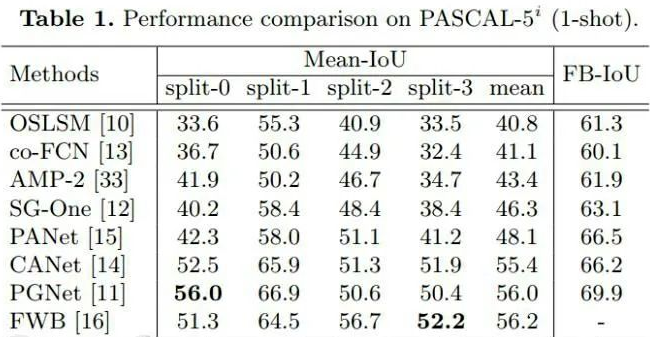
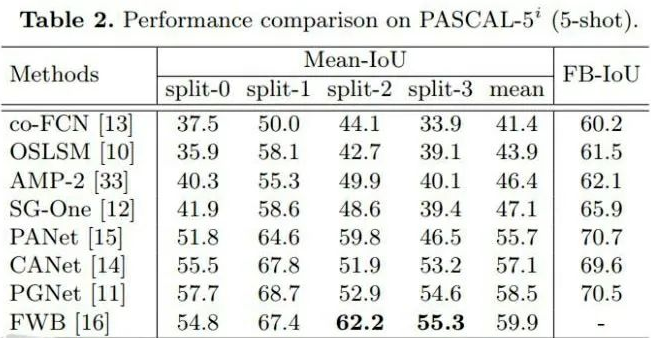
結(jié)果陳列
推薦閱讀
90后中國程序員“黑吃黑”博彩網(wǎng)站,半年獲利256萬
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!
評論
圖片
表情