
基于深度學(xué)習(xí)的語義分割綜述
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

本文轉(zhuǎn)自 | 計算機(jī)視覺工坊
圖像分割是圖像處理和計算機(jī)視覺領(lǐng)域的一個重要課題,在場景理解、醫(yī)學(xué)圖像分析、機(jī)器人感知、視頻監(jiān)控、增強(qiáng)現(xiàn)實、圖像壓縮等領(lǐng)域有著廣泛的應(yīng)用。近年來,由于深度學(xué)習(xí)模型在視覺應(yīng)用中的成功,已有大量的工作致力于利用深度學(xué)習(xí)模型開發(fā)圖像分割方法。本文全面回顧了撰寫本文時的文獻(xiàn),涵蓋了語義和實例級分割的大量開創(chuàng)性工作,包括完全卷積像素標(biāo)記網(wǎng)絡(luò)、編碼器-解碼器架構(gòu)、多尺度和基于金字塔的方法、遞歸網(wǎng)絡(luò),視覺attention模型,以及生成對抗模型。論文研究了這些深度學(xué)習(xí)模型的相似性、優(yōu)勢和挑戰(zhàn),研究了最廣泛使用的數(shù)據(jù)集、報告性能,并討論了這一領(lǐng)域未來有希望的研究方向。
圖像分割是許多視覺理解系統(tǒng)的重要組成部分。它包括將圖像(或視頻幀)分割成多個片段或?qū)ο蟆7指钤卺t(yī)學(xué)圖像分析(例如,腫瘤邊界提取和組織體積測量),自主載體(例如,可導(dǎo)航表面和行人檢測),視頻監(jiān)控,和增強(qiáng)現(xiàn)實起到了非常重要的作用。文獻(xiàn)中已經(jīng)開發(fā)了許多圖像分割算法,從最早的方法,如閾值化、基于直方圖的方法、區(qū)域劃分、k-均值聚類、分水嶺,到更先進(jìn)的算法,如活動輪廓、基于Graph的分割、馬爾可夫隨機(jī)場和稀疏方法。然而,在過去的幾年里,深度學(xué)習(xí)網(wǎng)絡(luò)已經(jīng)產(chǎn)生了新一代的圖像分割模型,其性能得到了顯著的提高——通常在流行的基準(zhǔn)上達(dá)到了最高的準(zhǔn)確率——這導(dǎo)致了許多人認(rèn)為是該領(lǐng)域的范式轉(zhuǎn)變。
圖像分割可以表述為帶有語義標(biāo)簽的像素分類問題(語義分割)或單個對象分割問題(實例分割)。語義分割對所有圖像像素使用一組對象類別(如人、車、樹、天空)進(jìn)行像素級標(biāo)記,因此通常比預(yù)測整個圖像的單個標(biāo)簽的圖像分類困難。實例分割通過檢測和描繪圖像中的每個感興趣對象(例如,個體的分割),進(jìn)一步擴(kuò)展了語義分割的范圍。論文調(diào)查涵蓋了圖像分割的最新文獻(xiàn),討論了到2019年為止提出的100多種基于深度學(xué)習(xí)的分割方法。本文對這些方法的不同方面提供了全面的了解和認(rèn)識,包括訓(xùn)練數(shù)據(jù)、網(wǎng)絡(luò)架構(gòu)的選擇、損失函數(shù)、訓(xùn)練策略及其主要貢獻(xiàn)。我們比較總結(jié)了這些方法的性能,并討論了基于深度學(xué)習(xí)的圖像分割模型面臨的挑戰(zhàn)和未來的發(fā)展方向。根據(jù)其主要技術(shù)貢獻(xiàn),將基于深度學(xué)習(xí)的作品分為以下幾類:
1)Fully convolutional networks
2)Convolutional models with graphical models
3)Encoder-decoder based models
4) Multi-scaleand pyramid network based models
5)R-CNN based models (for instance segmentation)
6)Dilated convolutional models and DeepLab family
7)Recurrent neural network based models
8)Attention-based models
9)Generative models and adversarial training
10)Convolutional models with active contour models
11)Other models
本文的一些主要貢獻(xiàn)可以總結(jié)如下:本次調(diào)查涵蓋了截至2019年提出的100多種算法,分為10類。通過深入學(xué)習(xí),對分割算法的不同方面提供了全面的了解和具體的分析,包括訓(xùn)練數(shù)據(jù)、網(wǎng)絡(luò)結(jié)構(gòu)的選擇、損失函數(shù)、訓(xùn)練策略及其關(guān)鍵貢獻(xiàn)。除此之外,還提供了大約20個流行的圖像分割數(shù)據(jù)集的概述,這些數(shù)據(jù)集分為2D、2.5D(RGBD)和3D圖像。在流行的基準(zhǔn)上提供了一個比較性總結(jié),說明了用于分割目的的已審查方法的性質(zhì)和性能,并為基于深度學(xué)習(xí)的圖像分割提供了若干挑戰(zhàn)和潛在的發(fā)展方向。
回顧了截至2019年提出的100多種基于深度學(xué)習(xí)的分割方法,共分為10類。值得一提的是,在這些作品中,有一些是常見的,例如具有編碼器和解碼器部分、skip連接、多尺度分析,以及最近使用的dilated卷積。因此,很難提及每個算法的獨特貢獻(xiàn),但更容易根據(jù)其在結(jié)構(gòu)方面的貢獻(xiàn)將其歸類。
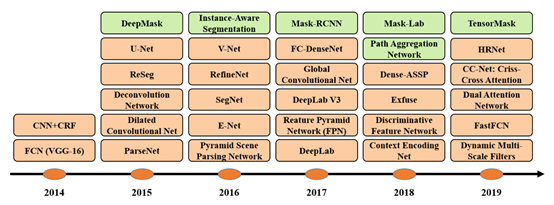
1.Fully ConvolutionalNetworks
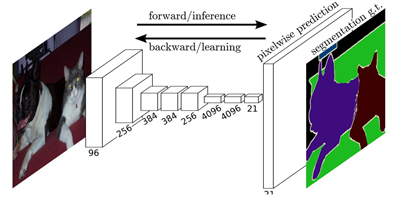
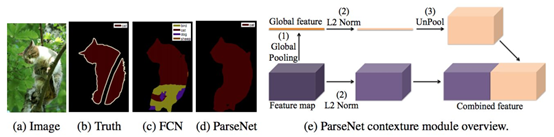
這項工作被認(rèn)為是圖像分割中的一個里程碑,證明了可以在可變大小的圖像上以端到端的方式訓(xùn)練深層網(wǎng)絡(luò)進(jìn)行語義分割。然而,傳統(tǒng)的FCN模型雖然具有普遍性和有效性,但也存在一定的局限性,它不能快速地進(jìn)行實時推理,不能有效地考慮全局上下文信息,也不容易轉(zhuǎn)換為3D圖像。有幾項努力試圖克服FCN的一些局限性。例如,Liu等人提出了一個名為ParseNet的模型,以解決FCN忽略全局context information的問題. ParseNet通過使用層的平均特征來增加每個位置的特征,將全局contextinformation添加到FCN。
FCNs已經(jīng)應(yīng)用于多種分割問題,如腦腫瘤分割[34]、實例感知語義分割、皮膚損傷分割和虹膜分割。
2.Convolutional ModelsWith Graphical Models
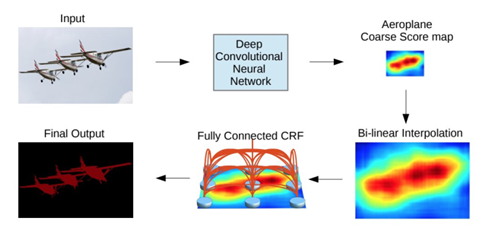
Chen等人提出了一種基于CNN和全連接CRF組合的語義分割算法。他們表明,對于精確的目標(biāo)分割來說,來自深層CNN最終層的響應(yīng)并沒有得到足夠的定位(因為CNN的不變性使得它適合于高層次的任務(wù),比如分類)。為了克服深CNN定位性能差的問題,他們將最終CNN層的響應(yīng)與全連接的CRF相結(jié)合,論文表明,模型能夠以比以前的方法更高的準(zhǔn)確率定位。
Schwing和Urtasun提出了一種用于圖像分割的全連通深結(jié)構(gòu)網(wǎng)絡(luò)。他們提出了一種聯(lián)合訓(xùn)練CNNs和全連接CRF進(jìn)行語義圖像分割的方法,并在PASCAL VOC 2012數(shù)據(jù)集上取得了令人鼓舞的結(jié)果。Zheng等人提出了一種結(jié)合CRF和CNN的相似語義分割方法。在另一項相關(guān)工作中,Lin等人提出了一種基于上下文深度CRF的高效語義分割算法。Liuatal提出了一種將豐富的信息集成到MRF中的語義分類算法,包括高階關(guān)系和混合標(biāo)簽文本。與以往使用迭代算法優(yōu)化MRF的工作不同,他們提出了一種CNN模型,即一個解析網(wǎng)絡(luò),它可以在一次轉(zhuǎn)發(fā)過程中實現(xiàn)確定性的端到端計算。
3.Encoder-Decoder BasedModels
另一個流行的用于圖像分割的深度模型家族是基于卷積編碼器-解碼器體系結(jié)構(gòu)的。大多數(shù)基于DL的分割工作都使用某種編碼-解碼模型。論文將這些工作分為兩類,用于一般分割的編碼器-解碼器模型和用于醫(yī)學(xué)圖像分割的編碼器-解碼器模型(以更好地區(qū)分應(yīng)用程序)。
Badrinarayanan等人提出了一種用于圖像分割的卷積編碼器架構(gòu),SegNet的核心由一個編碼器網(wǎng)絡(luò)(在拓?fù)渖吓cVGG16網(wǎng)絡(luò)中的13個卷積層相同)和一個對應(yīng)的解碼器網(wǎng)絡(luò)以及一個像素級分類層組成。SegNet的主要新穎之處在于解碼器對其低分辨率輸入特征映射進(jìn)行上采樣;具體來說,它使用在相應(yīng)編碼器的最大池步驟中計算的池索引來執(zhí)行非線性上采樣。這消除了學(xué)習(xí)向上采樣的必要性。然后(稀疏的)上采樣地圖與可訓(xùn)練濾波器卷積以產(chǎn)生密集的特征圖。SegNet在可訓(xùn)練參數(shù)的數(shù)量上也比其他結(jié)構(gòu)小得多。同一作者還提出了SegNet的Bayesian版本,用于建模場景分割的卷積編碼器-解碼器網(wǎng)絡(luò)固有的不確定性。這一類中另一個流行的模型是最近的一些分割網(wǎng)絡(luò),高分辨率網(wǎng)絡(luò)(HRNet)。除了像在DeConvNet、SegNet、U-Net和V-Net中那樣恢復(fù)高分辨率表示之外,HRNet通過并行連接高分辨率和低分辨率卷積流并在多個分辨率之間重復(fù)交換信息來通過編碼過程保持高分辨率表示。
近年來,許多關(guān)于語義分割的研究都是以HRNet為骨干,利用上下文模型,如self-attention及其擴(kuò)展等。其他一些工作采用轉(zhuǎn)置卷積或編碼器-解碼器進(jìn)行圖像分割,如堆疊反卷積網(wǎng)絡(luò)(SDN)、Linknet、W-Net和局部敏感反卷積網(wǎng)絡(luò)進(jìn)行RGBD分割。
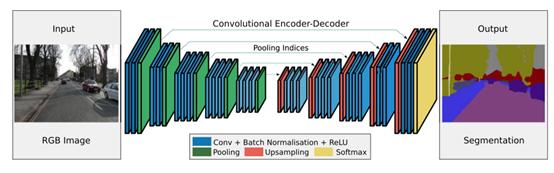

在FCNs和編解碼模型的啟發(fā)下,醫(yī)學(xué)/生物醫(yī)學(xué)圖像分割初步發(fā)展了幾種模型。U-Net和V-Net是兩種著名的此類架構(gòu),它們現(xiàn)在也被用于醫(yī)療領(lǐng)域之外。
Ronnebergeretal提出了用于分割生物顯微鏡圖像的U-Net。他們的網(wǎng)絡(luò)和訓(xùn)練策略依賴于使用數(shù)據(jù)增強(qiáng)來更有效地從可用的注釋圖像中學(xué)習(xí)。V-Net是另一個著名的基于FCN的模型,由Milletari等人提出,用于三維醫(yī)學(xué)圖像分割。對于模型訓(xùn)練,他們引入了一個新目標(biāo)函數(shù),使模型能夠處理前景和背景中體素數(shù)量之間存在嚴(yán)重不平衡的情況。該網(wǎng)絡(luò)在描述前列腺的MRI體積上進(jìn)行端到端的訓(xùn)練,并學(xué)習(xí)同時預(yù)測整個體積的分割。醫(yī)學(xué)圖像分割的其他相關(guān)工作包括漸進(jìn)密集V-net(PDV-net)等。用于從胸部CT圖像中快速自動分割肺葉,以及用于病變分割的3D-CNN編碼器。


4.Multi-Scale and PyramidNetwork Based Models
多尺度分析(Multi-scale analysis,Multi-scaleanalysis)是圖像處理中的一個古老的思想,已經(jīng)被廣泛應(yīng)用于各種神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)中。其中最突出的一種模型是Lin等人提出的特征金字塔網(wǎng)絡(luò)(FPN)。雖然主要用于目標(biāo)檢測,但也應(yīng)用于分割,利用深CNNs的內(nèi)在多尺度金字塔層次結(jié)構(gòu)構(gòu)造具有邊際額外成本的特征金字塔。為了融合低分辨率和高分辨率特征,F(xiàn)PN由自下而上的路徑、自上而下的路徑和橫向連接組成。然后,通過3×3卷積處理連接的特征映射,以產(chǎn)生每個階段的輸出。最后,自上而下路徑的每個階段都生成一個預(yù)測來檢測對象。對于圖像分割,作者使用兩個多層感知器(MLPs)來生成掩模。

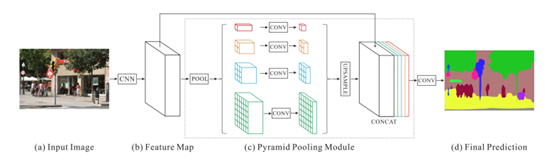
Zhao等人開發(fā)了金字塔場景解析網(wǎng)絡(luò)(PSPN),這是一個多尺度網(wǎng)絡(luò),可以更好地學(xué)習(xí)場景的全局上下文表示。使用殘差網(wǎng)絡(luò)(ResNet)作為特征提取器,通過擴(kuò)展網(wǎng)絡(luò)從輸入圖像中提取不同的模式。然后將這些特征映射輸入金字塔池模塊,以區(qū)分不同尺度的模式。它們在四個不同的尺度上集合,每個尺度對應(yīng)一個金字塔層,并由1×1卷積層處理以減小它們的維數(shù)。金字塔層的輸出被上采樣,并與初始特征映射連接,以捕獲本地和全局上下文信息。最后,使用卷積層來產(chǎn)生逐像素預(yù)測。
Ghiasi和Fowlkes開發(fā)了一種基于拉普拉斯金字塔的多分辨率重建體系結(jié)構(gòu),該結(jié)構(gòu)使用高分辨率特征映射的跳躍連接和乘法選通來連續(xù)重建低分辨率映射的細(xì)分邊界。研究表明,卷積特征映射的空間分辨率較低,但高維特征表示包含了大量的亞像素定位信息。還有其他使用多尺度分析進(jìn)行分割的模型,如DM-Net(動態(tài)多尺度濾波器網(wǎng)絡(luò))、上下文對比網(wǎng)絡(luò)和門控多尺度聚集(CCN)、APC-Net、MSCI和顯著對象分割。
5.R-CNN Based Models (實例分割)
何凱明提出了一個用于對象實例分割的Mask R-CNN,它在許多COCO挑戰(zhàn)上超過了所有先前的基準(zhǔn)。該模型在為每個實例生成高質(zhì)量分段掩碼的同時,有效地檢測圖像中的對象。
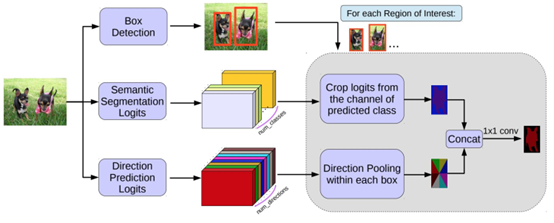
Hu等人提出了一種新的部分監(jiān)督訓(xùn)練范式和一種新的權(quán)值轉(zhuǎn)移函數(shù),該范式使約束狀態(tài)分類模型成為一個大類別集,所有類別都有框注釋,但只有一小部分類別有掩碼注釋。Chen等人開發(fā)了一個實例分割模型MaskLab,該模型基于更快的R-CNN,具有語義和方向特征。另一個有趣的模型是Tensormask,由Chen等人提出,基于密集滑動窗口實例分割。他們將密集實例分割作為4D張量上的預(yù)測任務(wù),并提出了一個通用框架,使4D張量上的新算子成為可能。他們證明了張量視圖比基線有更大的增益,產(chǎn)生的結(jié)果與掩模R-CNN相當(dāng)。TensorMask在密集對象分割方面取得了很有希望的結(jié)果(許多其他的實例分割模型是基于R-CNN開發(fā)的,例如那些為掩碼建議開發(fā)的模型,包括R-FCN、DeepMask、SharpMask、PolarMask和邊界感知實例分割。值得注意的是,還有一個很有前途的研究方向是嘗試通過學(xué)習(xí)用于自底向上分割的分組線索來解決實例分割問題,例如深分水嶺變換和通過深度量學(xué)習(xí)進(jìn)行語義實例分割。

6.DilatedConvolutional Models and DeepLab Family
擴(kuò)張/膨脹卷積為卷積層引入了另一個參數(shù),即膨脹率。它可以在在不增加計算成本的情況下擴(kuò)大了感受野。膨脹卷積在實際時間段中已被廣泛應(yīng)用,其中一些最重要的包括DeepLab家族、多尺度Context Aggregation、密集上采樣卷積和混合擴(kuò)張卷積(DUC-HDC)、Densespp和ENet。
DeepLabv1和DeepLabv2是Chenetal開發(fā)的最流行的圖像分割方法之一,后者有三個關(guān)鍵特性:第一,使用擴(kuò)展卷積來解決網(wǎng)絡(luò)中分辨率降低的問題(由max pooling和striding引起)。第二種是atrus空間金字塔池(ASPP),它在多個采樣率下使用濾波器探測傳入的卷積特征層,從而在多個尺度上捕獲對象和圖像上下文,以在多個尺度上可靠地分割對象。第三種是結(jié)合深CNNs和概率圖形模型的方法改進(jìn)目標(biāo)邊界的定位。最佳的DeepLab(使用ResNet-101作為主干)在2012年pascal VOC挑戰(zhàn)賽中達(dá)到79.7%的mIoU分?jǐn)?shù),在cityscape挑戰(zhàn)賽中達(dá)到70.4%的mIoU分?jǐn)?shù)。
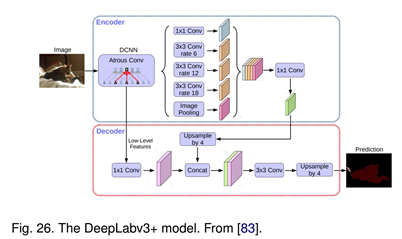
隨后,Chen等人提出了DeepLabv3,它結(jié)合了級聯(lián)和并行的擴(kuò)展卷積模塊。并行卷積模塊分組在ASPP中。在ASPP中加入了1×1卷積和批量正態(tài)化。2018年,Chen等人發(fā)布的Deeplabv3+,它使用編碼器-解碼器架構(gòu),包括Atrus separable convolution、每個輸入通道的空間卷積和點卷積。他們使用DeepLabv3框架作為編碼器。在COCO和JFT數(shù)據(jù)集上預(yù)訓(xùn)練的最佳DeepLabv3+在2012年pascal VOC挑戰(zhàn)賽中獲得89.0%的mIoU分?jǐn)?shù)。
7.Recurrent NeuralNetwork Based Models
雖然CNN是解決計算機(jī)視覺問題的一種天然手段,但它并不是唯一的可能性。RNNs在建立像素間的短期/長期依賴關(guān)系模型以(潛在地)改善分割圖的估計方面非常有用。使用RNNs,像素可以被連接在一起并按順序處理,以建模全局信息進(jìn)行語義分割。
主要工作包括:
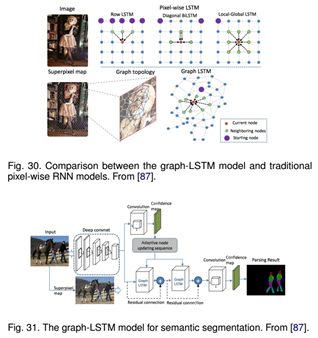
1. Scenelabeling with lstm recurrent neural networks
2. Semanticobject parsing with graph lstm
3. Da-rnn:Semantic mapping with data associated recurrent neural networks
4. Segmentationfrom natural language expressions
8.Attention-Based Models
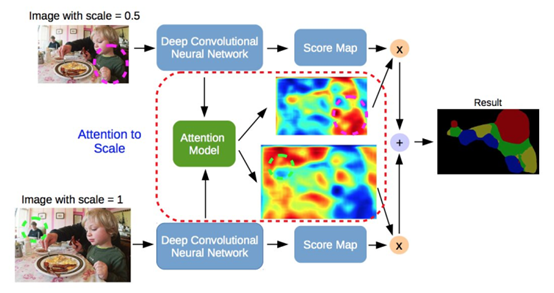
多年來,注意機(jī)制一直在計算機(jī)視覺中被不斷探索,因此,發(fā)現(xiàn)將這種機(jī)制應(yīng)用于語義分割的出版物也就不足為奇了。Chen等人提出了一種attention機(jī)制,學(xué)習(xí)在每個像素位置對多尺度特征進(jìn)行軟加權(quán)。它們采用了一個強(qiáng)大的語義分割模型,并與多尺度圖像和attention模型聯(lián)合訓(xùn)練。attention機(jī)制的性能優(yōu)于平均值和最大值池,使模型能夠在不同的位置和尺度上評估特征的重要性。
與其他作品不同,在這些作品中,卷積分類學(xué)被訓(xùn)練來學(xué)習(xí)標(biāo)記對象的典型語義特征,Huang等人提出了一種基于反向attention機(jī)制的語義分割方法。他們的反向attention網(wǎng)絡(luò)(RAN)架構(gòu)也訓(xùn)練模型捕捉相反的概念(即,與目標(biāo)類無關(guān)的特征)。

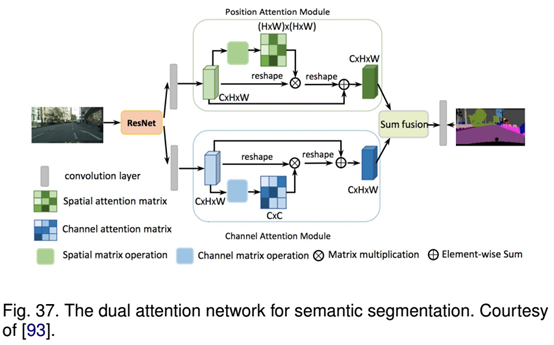
RAN是一個同時執(zhí)行直接和反向attention學(xué)習(xí)過程的三分支網(wǎng)絡(luò)。Li等人開發(fā)了一個用于語義分割的金字塔attention網(wǎng)絡(luò)。該模型充分利用了全局上下文信息對語義分割的影響。他們將注意力機(jī)制和空間金字塔結(jié)合起來,提取精確的密集特征用于像素標(biāo)記,而不是復(fù)雜的擴(kuò)展卷積和精心設(shè)計的解碼網(wǎng)絡(luò)。最近,F(xiàn)u等人提出了一種用于場景分割的雙attention網(wǎng)絡(luò),該網(wǎng)絡(luò)能夠基于自注意機(jī)制捕獲豐富的上下文依賴關(guān)系。
其他許多研究探索了語義切分的注意機(jī)制,如OCNet提出了一種受自我注意機(jī)制啟發(fā)的對象上下文池、期望最大化attention(EMANet)、Criss交叉attention網(wǎng)絡(luò)(CCNet)、具有重復(fù)attention的端到端實例切分,用于場景分析的點式空間attention網(wǎng)絡(luò)和判別特征網(wǎng)絡(luò)(DFN)。
9.Generative Models andAdversarial Training
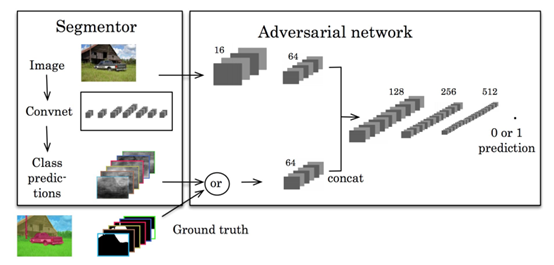
GANs自提出以來,已被廣泛應(yīng)用于計算機(jī)視覺領(lǐng)域,并被用于圖像分割。Luc等人提出了一種對抗性的語義分割訓(xùn)練方法。他們訓(xùn)練了一個卷積式語義分割網(wǎng)絡(luò),以及一個對抗性網(wǎng)絡(luò),該網(wǎng)絡(luò)將地面真值分割圖與分割網(wǎng)絡(luò)生成的真值分割圖區(qū)分開來。他們展示了這種差異訓(xùn)練方法提高了在PASCAL VOC 2012數(shù)據(jù)集上的準(zhǔn)確性。
蘇利等人提出了使用Gans的半弱監(jiān)督語義分類。它包括代理網(wǎng)絡(luò),為多類分類器提供額外的訓(xùn)練示例,在GAN框架中充當(dāng)鑒別器,從K個可能類中分配樣本標(biāo)簽y或?qū)⑵錁?biāo)記為假樣本(額外類)。在另一部作品中,Hung等人開發(fā)了一個使用對抗性網(wǎng)絡(luò)的半監(jiān)督語義分割框架。他們設(shè)計了一個FCN鑒別器,在考慮空間分辨率的情況下,將預(yù)測概率圖與地面真值分割分布區(qū)分開來。該模型考慮的損失函數(shù)包括三個項:分割地面真實性的交叉熵?fù)p失、鑒別網(wǎng)絡(luò)的對抗性損失和基于置信圖的半監(jiān)督損失,即鑒別器的輸出。
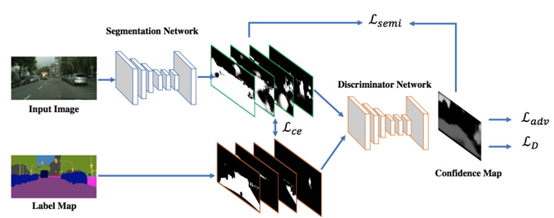
薛等人提出了一種多尺度L1損失的對抗性醫(yī)學(xué)圖像分割網(wǎng)絡(luò)。他們使用分段或生成率分段標(biāo)簽映射,并提出了一個具有多尺度L1損失函數(shù)的網(wǎng)絡(luò),以強(qiáng)制批評者和分段者學(xué)習(xí)捕獲像素之間長距離和短距離空間關(guān)系的全局和局部特征。

10.CNN Models With ActiveContour Models
FCNs和活動輪廓模型(ACMs)之間協(xié)同作用的探索最近引起了研究興趣。一種方法是根據(jù)ACM原理建立新的損失函數(shù)。例如Chen等人提出了一個有監(jiān)督的丟失層,該層在FCN訓(xùn)練過程中包含了預(yù)測掩模的面積和大小信息,解決了心臟MRI中心室分割的問題。同樣,Gur等人提出了一種基于無邊緣形態(tài)學(xué)活動輪廓的無監(jiān)督損失函數(shù),用于微血管圖像分割。一種不同的方法最初試圖將ACM僅僅用作FCN輸出的后處理程序,一些努力試圖通過對FCN進(jìn)行預(yù)訓(xùn)練來實現(xiàn)適度的共同學(xué)習(xí)。Le等人的工作是一個用于自然圖像語義分割的ACM后處理器的例子。Hatamizadeh等人提出了一個集成的深部活動損傷(DALS)模型,用于訓(xùn)練背根骨預(yù)測新的局部參數(shù)化水平集能函數(shù)的參數(shù)函數(shù)。在其他相關(guān)工作中,Marcos等人提出了深結(jié)構(gòu)活動輪廓(DSAC),它將ACMs和預(yù)先訓(xùn)練的FCNs結(jié)合在一個結(jié)構(gòu)化的預(yù)測框架中,用于在航空圖像中建立實例分割(盡管需要手動初始化)。對于相同的應(yīng)用程序,Cheng等人提出了與DSAC相似的深度主動射線網(wǎng)絡(luò)(DarNet),但采用了基于極坐標(biāo)的不同顯式ACM公式來防止輪廓自相交。Hatamizadeh等人最近推出了一種真正的端到端反向傳播可訓(xùn)練、完全集成的FCN-ACM組合被稱為深卷積活動輪廓(DCAC)。
圖像分割數(shù)據(jù)集
1.2D datasets
PASCALVisual Object Classes (VOC)
PASCALContext
MicrosoftCommon Objects in Context (MS COCO)
Cityscapes
ADE20K/MITScene Parsing (SceneParse150)
SiftFlow
Stanfordbackground
BerkeleySegmentation Dataset (BSD)
Youtube-Objects
KITTI
Semantic Boundaries Dataset(SBD)
SYNTHIA
Adobes Portrait Segmentation
2.2.5D datasets
NYU-DV2
SUN-3D
SUNRGB-D
ScanNet
UWRGB-D Object Dataset
3.3D Datasets
Stanford2D-3D
ShapeNetCore
SydneyUrban Objects Dataset
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~