
使用.Net Core做個爬蟲
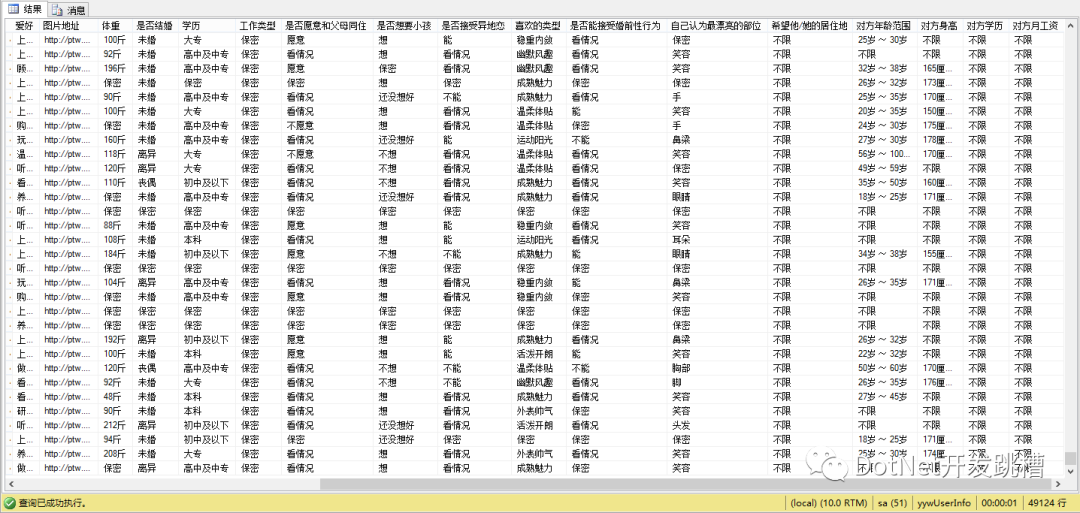
最近接手一個新項目,爬亞馬遜分類、商品數(shù)據(jù)。記得大學的時候,自己瞎玩,寫過一個爬有緣網(wǎng)數(shù)據(jù)的程序,那個時候沒有考慮那么多,寫的還是單線程,因為網(wǎng)站沒有反爬,就不停的一直請求,記得放到實驗室電腦上一天,跑了30w+的數(shù)據(jù)。然后當前晚上有緣網(wǎng)網(wǎng)站顯示維護中。。。。
?畢竟小打小鬧,沒有真正的寫過爬蟲。就翻別人博客了解了下爬蟲所用到的技術、技巧、套路。然后就翻到這個老哥寫的博客, 雖然語言是有點囂張,但是我還是比較認同的 哈哈哈哈。

?
?下面從爬蟲涉及的幾任務調度、數(shù)據(jù)去重、數(shù)據(jù)解析、并發(fā)控制、斷點續(xù)爬、代理來聊聊項目遇到的坑。
一、數(shù)據(jù)解析
數(shù)據(jù)解析就是提取網(wǎng)頁上的有效數(shù)據(jù)。.Net下有個HtmlAgilityPack組件,可以很好地解析HMTL。想都沒想 就直接用了它(這就為后面挖了一個大坑)。剛開始單線程測試的時候,一切正常,但是當我開了50個線程的時候,內(nèi)存在90s內(nèi)飆升到了3G,而且持續(xù)爬升。
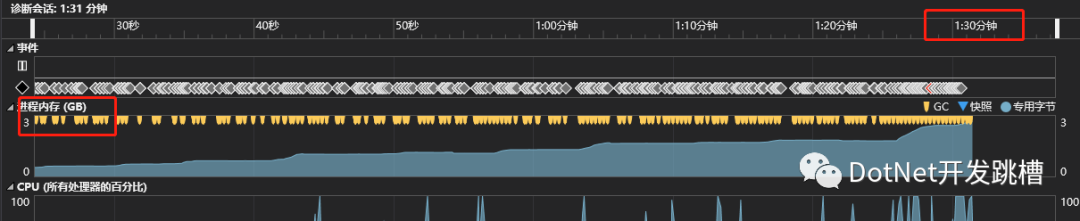
用.Net Memory工具分析發(fā)現(xiàn) 內(nèi)存被大對象沾滿了,所以每次GC的時候內(nèi)存并沒有被回收,有5w多HtmlNode,每個對象大小都超過 85000byte。

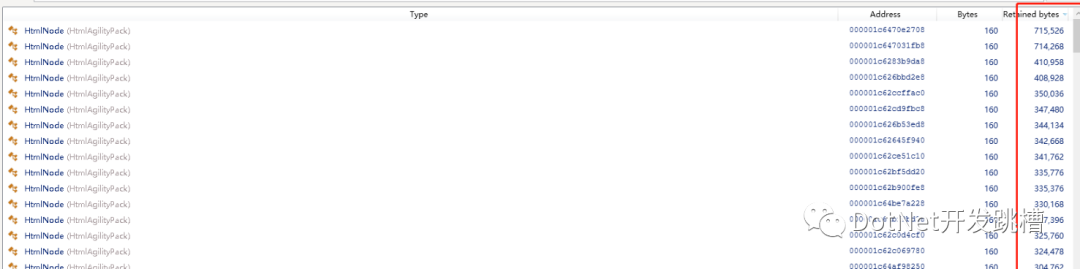
?因為亞馬遜的圖片不是通過鏈接外鏈的,而是通過base64編碼的,所以導致下載的網(wǎng)頁Html超過1M,而85000byte就算大對象了。導致每爬取一個商品詳情頁,都會加載到HtmlNode中變成一個大對象,由于GC不壓縮大對象,而C對大對象的回收只有在回收2代的時候才觸發(fā)。所以只能改變策略,通過正則、切分字符串來處理。
二、任務調度、并行爬取
目的是爬取亞馬遜的分類和分類下的商品,我做了個3個任務,
1、找到分類入口,爬取分類Id、標題、url 、分類等級存儲到數(shù)據(jù)庫。
2、根據(jù)1任務爬取的分類Id,獲取分類下商品列表。爬取列表上商品部分信息,包括商品的Id、名稱、縮略圖。
3、根據(jù)2任務爬取的商品Id,獲取商品詳情頁,爬取商品詳情頁的其他信息。
一個分類下有幾百頁商品列表,而每個列表一般有22個商品。所以1任務爬取完一次,2任務要爬取幾百次(當然不會將分類下的所有頁碼都爬完,設定只爬20頁) ,3任務要爬 20 x 22次。這樣分任務的好處就是 3個任務中,不論哪個任務掛了,其他2個任務是不受影響的,可以繼續(xù)跑。
比如2任務掛掉了,1任務不受它影響,雖然3任務的需要2任務的數(shù)據(jù),但是3任務的速度是比2任務慢了22倍還多(獲取詳情的時候 還需要在請求其他頁面)所以任務線程相同的情況下 2任務的會有很多剩余商品 3還沒有來得及跑。
調度采用了QuartZ 使用Cron配置定時任務。使用Parallel并行爬取,線程數(shù)量可以配只需要將方法和方法所需要的參數(shù)集合放到ForEach
?
合理配置每個任務的線程數(shù)量,我設置爬取分類線程數(shù)1,商品列表的線程是2,商品詳情爬取線程為50。爬取的速度不同線程數(shù)量就不同,而且并不是線程越高越好,這個值是不斷的調試采集相同時間的數(shù)據(jù)分析得出來的。

三、代理
現(xiàn)在有很多代理商,普遍分為兩種:
第一種通過接口返回代理IP和這個代理的可用時間,在這個時間段內(nèi),這個代理是可用的。注意:這種代理方式需要有個代理池,因為爬蟲一般都是多線程,如果在代理IP可用時間段內(nèi),多個線程一直使用同一個代理IP,很大可能會被封。所以保險的做法就是一個線程一個代理,降低每個代理的請求次數(shù)。
第二種代理直接給你一個固定的IP,這個代理IP沒有時間限制,代理商那邊會幫你自動幫你換不同的IP請求目標地址。
.Net Core中使用代理很簡單,因為我使用的是HttpClientFactory,所以在添加服務的時候配置 HttpClientHandler的代理就可以,需要實現(xiàn)一個IWebProxy類,返回對應的代理IP和端口號就可以了。

?剛開始使用的是第一種代理,為了實現(xiàn)一個線程一個代理,我創(chuàng)建了一個代理池,在程序啟動的時候,每個線程都會從代理商那獲取到一個代理IP,然后放到代理池中,每次獲取代理的時候,通過代理池中隨機挑選一個代理IP,在挑選前會判斷當前代理池中的代理數(shù)量,如果小于線程數(shù)據(jù),就會去獲取填充到代理池中。

后面發(fā)現(xiàn)國內(nèi)的代理商的IP訪問國外網(wǎng)址太慢了,就換了國外代理,國外代理使用的是第二種方案。但是這個代理商不是自動幫你更換IP,而是需要每次傳遞一個隨機數(shù) SessionId,隨機數(shù)不同,代理商訪問目標網(wǎng)站的IP就不同,而且要傳用戶名和密碼。
?開始 我是這么做的: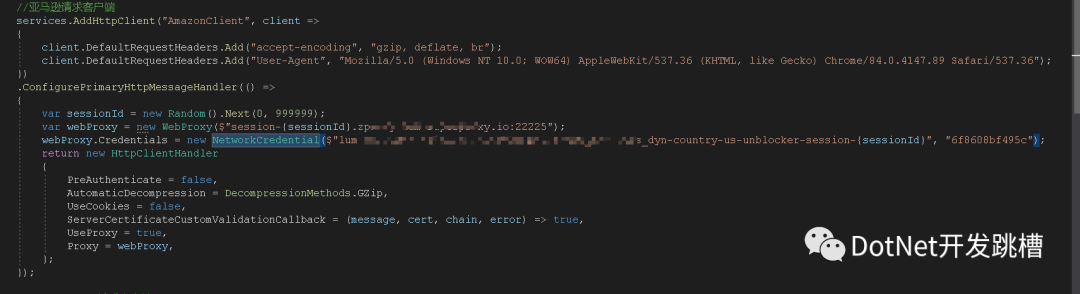
?發(fā)現(xiàn)這種只有在第一次創(chuàng)建HttpClient的時候才會去走配置ConfigurePrimaryHttpMessageHandler方法,之后創(chuàng)建HttpClient都不會走。就導致一直在使用同一個IP請求。
所以沒辦法,只能放棄使用HttpClientFactory,自己手動創(chuàng)建HttpClient ,然后釋放。但這種又隨之帶來一個問題HttpClient雖然釋放了,但是端口還是被占用著,目前還沒有好的解決辦法。
?四、斷點續(xù)爬、數(shù)據(jù)去重
我這個業(yè)務中這兩個功能就很好實現(xiàn),每次爬取完成商品頁碼,就存儲下一頁的頁碼和當前爬取的頁碼數(shù)。配置一個參數(shù)是否是斷點續(xù)爬,如果是斷點續(xù)爬,就從上次記錄的頁碼爬取商品。
數(shù)據(jù)去重,因為直接可以拿到亞馬遜的商品Id和分類Id,所以去重就變的很簡單,任務啟動的時候,會將已經(jīng)爬取過的商品Id和分類Id放到緩存中,爬取的時候對比數(shù)據(jù)。
?
項目在服務器上跑了2個晚上,表現(xiàn)還是可以的,數(shù)據(jù)都正確采集到了117w數(shù)據(jù)(包含未爬取詳情的商品),最后的最后。。。。項目被砍了,因為亞馬遜的商品詳情頁數(shù)據(jù)太大,導致爬了12個小時用了40G流量,1G=6美元 ,一個月就要40x2x6x30=14400美元。忙碌了兩周,也算從零寫了一個小小的爬蟲,還算有所得。
出處:https://www.cnblogs.com/MicroHeart/p/14115853.html


再見,VIP,臥槽又來一個看片神器!

推薦這10個優(yōu)秀的.NET Core開源項目!