
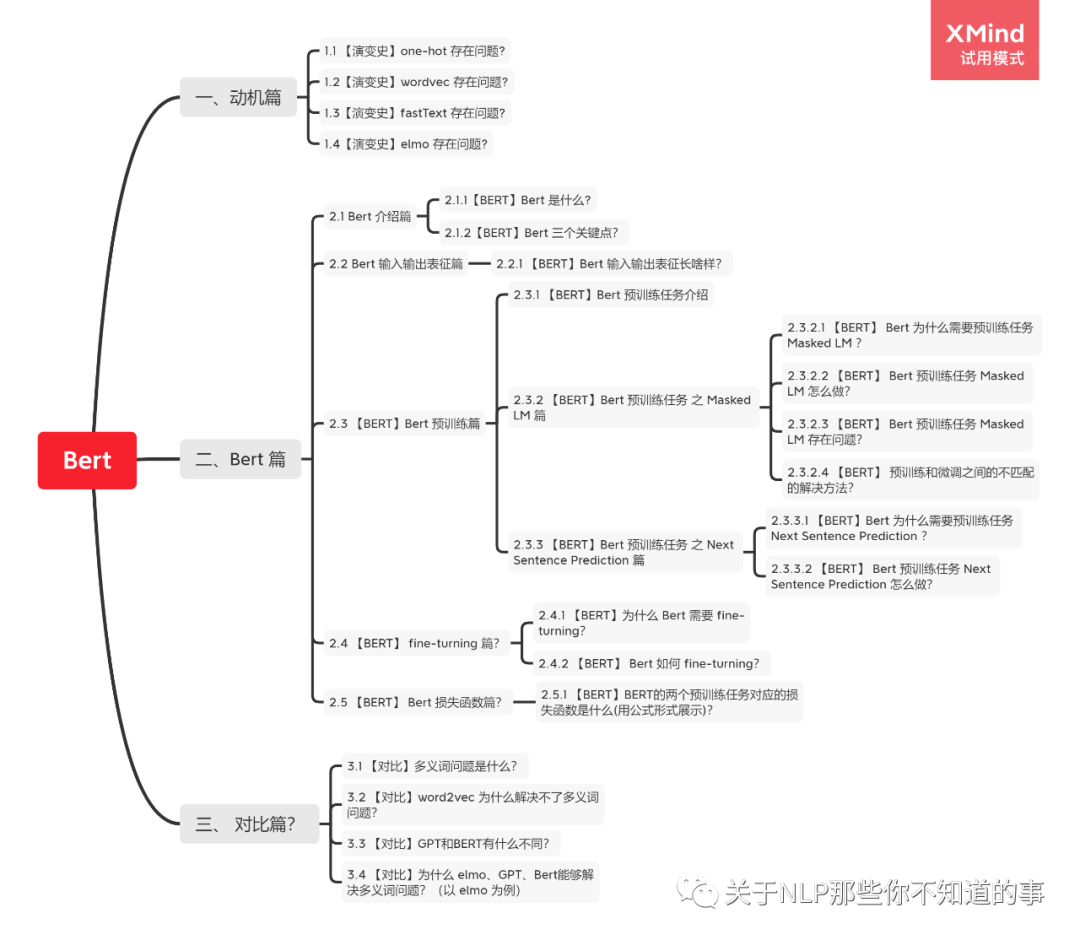
【關(guān)于Bert】 那些的你不知道的事(下)
?
作者簡(jiǎn)介
作者:楊夕
論文名稱:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
論文鏈接:https://arxiv.org/pdf/1706.03762.pdf
代碼鏈接:https://github.com/google-research/bert
推薦系統(tǒng) 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
個(gè)人 NLP 筆記:
https://github.com/km1994/nlp_paper_study
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。
引言
本博客 主要 是本人在學(xué)習(xí) Bert 時(shí)的所遇、所思、所解,通過以?十二連彈?的方式幫助大家更好的理解 該問題。
十二連彈
【演變史】one-hot 是什么及所存在問題?
【演變史】word2vec 是什么及所存在問題?
【演變史】fastText 是什么及所存在問題?
【演變史】elmo 是什么及所存在問題?
【BERT】Bert 是什么?
【BERT】Bert 三個(gè)關(guān)鍵點(diǎn)?
【BERT】Bert 輸入表征長(zhǎng)啥樣?
【BERT】Bert 預(yù)訓(xùn)練任務(wù)?
【BERT】Bert 預(yù)訓(xùn)練任務(wù) Masked LM 怎么做?
【BERT】Bert 預(yù)訓(xùn)練任務(wù) Next Sentence Prediction 怎么做?
【BERT】如何 fine-turning?
【對(duì)比】多義詞問題及解決方法?
問題解答
【BERT】Bert 是什么?
BERT(Bidirectional Encoder Representations from Transformers)是一種Transformer的雙向編碼器,旨在通過在左右上下文中共有的條件計(jì)算來預(yù)先訓(xùn)練來自無標(biāo)號(hào)文本的深度雙向表示。因此,經(jīng)過預(yù)先訓(xùn)練的BERT模型只需一個(gè)額外的輸出層就可以進(jìn)行微調(diào),從而為各種自然語(yǔ)言處理任務(wù)生成最新模型。
這個(gè)也是我們常說的 【預(yù)訓(xùn)練】+【微調(diào)】
【BERT】Bert 三個(gè)關(guān)鍵點(diǎn)?
基于 transformer 結(jié)構(gòu)
大量語(yǔ)料預(yù)訓(xùn)練:
介紹:在包含整個(gè)維基百科的無標(biāo)簽號(hào)文本的大語(yǔ)料庫(kù)中(足足有25億字!) 和圖書語(yǔ)料庫(kù)(有8億字)中進(jìn)行預(yù)訓(xùn)練;
優(yōu)點(diǎn):大語(yǔ)料 能夠 覆蓋 更多 的 信息;
雙向模型:
BERT是一個(gè)“深度雙向”的模型。雙向意味著BERT在訓(xùn)練階段從所選文本的左右上下文中汲取信息
舉例:
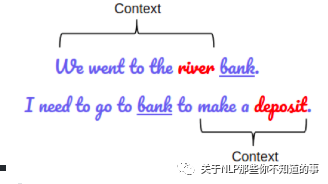

【BERT】Bert 輸入輸出表征長(zhǎng)啥樣?
input 組成:
Token embedding 字向量: BERT模型通過查詢字向量表將文本中的每個(gè)字轉(zhuǎn)換為一維向量,作為模型輸入;
Segment embedding 文本向量: 該向量的取值在模型訓(xùn)練過程中自動(dòng)學(xué)習(xí),用于刻畫文本的全局語(yǔ)義信息,并與單字/詞的語(yǔ)義信息相融合;
Position embedding 位置向量:由于出現(xiàn)在文本不同位置的字/詞所攜帶的語(yǔ)義信息存在差異(比如:“我愛你”和“你愛我”),因此,BERT模型對(duì)不同位置的字/詞分別附加一個(gè)不同的向量以作區(qū)分
output 組成:輸入各字對(duì)應(yīng)的融合全文語(yǔ)義信息后的向量表示

【BERT】Bert 預(yù)訓(xùn)練任務(wù)?
預(yù)訓(xùn)練 包含 兩個(gè) Task:
Task 1:Masked LM
Task 2:Next Sentence Prediction
【BERT】Bert 預(yù)訓(xùn)練任務(wù) Masked LM 怎么做?
動(dòng)機(jī):
雙向模型 由于 可以分別 從左到右 和 從右到左 訓(xùn)練,使得 每個(gè)詞 都能 通過多層 上下文 “看到自己”;
方法:Masked LM
做法:
s1:隨機(jī)遮蔽輸入詞塊的某些部分;
s2:僅預(yù)測(cè)那些被遮蔽詞塊;
s3:被遮蓋的標(biāo)記對(duì)應(yīng)的最終的隱藏向量被當(dāng)作softmax的關(guān)于該詞的一個(gè)輸出,和其他標(biāo)準(zhǔn)語(yǔ)言模型中相同


【BERT】Bert 預(yù)訓(xùn)練任務(wù) Next Sentence Prediction 怎么做?

【BERT】如何 fine-turning?

【BERT】BERT的兩個(gè)預(yù)訓(xùn)練任務(wù)對(duì)應(yīng)的損失函數(shù)是什么(用公式形式展示)?
Bert 損失函數(shù)組成:
第一部分是來自 Mask-LM 的單詞級(jí)別分類任務(wù);
另一部分是句子級(jí)別的分類任務(wù);
優(yōu)點(diǎn):通過這兩個(gè)任務(wù)的聯(lián)合學(xué)習(xí),可以使得 BERT 學(xué)習(xí)到的表征既有 token 級(jí)別信息,同時(shí)也包含了句子級(jí)別的語(yǔ)義信息。
損失函數(shù)
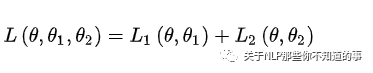
注:θ:BERT 中 Encoder 部分的參數(shù);θ1:是 Mask-LM 任務(wù)中在 Encoder 上所接的輸出層中的參數(shù);θ2:是句子預(yù)測(cè)任務(wù)中在 Encoder 接上的分類器參數(shù);
在第一部分的損失函數(shù)中,如果被 mask 的詞集合為 M,因?yàn)樗且粋€(gè)詞典大小 |V| 上的多分類問題,所用的損失函數(shù)叫做負(fù)對(duì)數(shù)似然函數(shù)(且是最小化,等價(jià)于最大化對(duì)數(shù)似然函數(shù)),那么具體說來有:
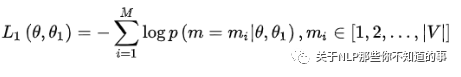
在第二部分的損失函數(shù)中,在句子預(yù)測(cè)任務(wù)中,也是一個(gè)分類問題的損失函數(shù):
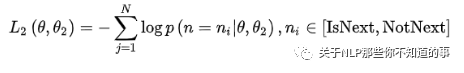
兩個(gè)任務(wù)聯(lián)合學(xué)習(xí)的損失函數(shù)是:
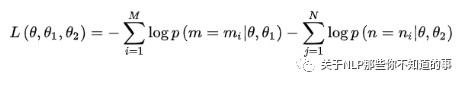
【對(duì)比】多義詞問題及解決方法?


參考
CS224n
關(guān)于BERT的若干問題整理記錄
所有文章
五谷雜糧
NLP百面百搭
Rasa 對(duì)話系統(tǒng)
知識(shí)圖譜入門
轉(zhuǎn)載記錄

? ??