
深度學(xué)習(xí)模型大小與模型推理速度的探討
導(dǎo)讀
作者:田子宸,畢業(yè)于浙江大學(xué),就職于商湯,文章經(jīng)過作者同意轉(zhuǎn)載。
前言
常用的模型大小評估指標(biāo)
1. 計算量

2. 參數(shù)量
3. 訪存量

4. 內(nèi)存占用
5. 小結(jié)
計算量越小,模型推理就越快嗎
計算密度與 RoofLine 模型
計算密集型算子與訪存密集型算子
推理時間
1. 計算密度與 RoofLine 模型
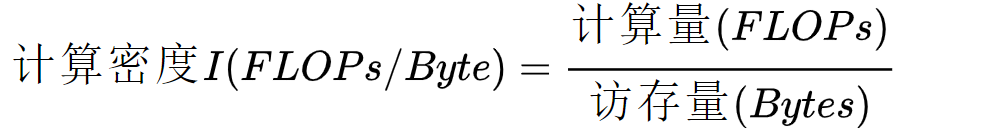
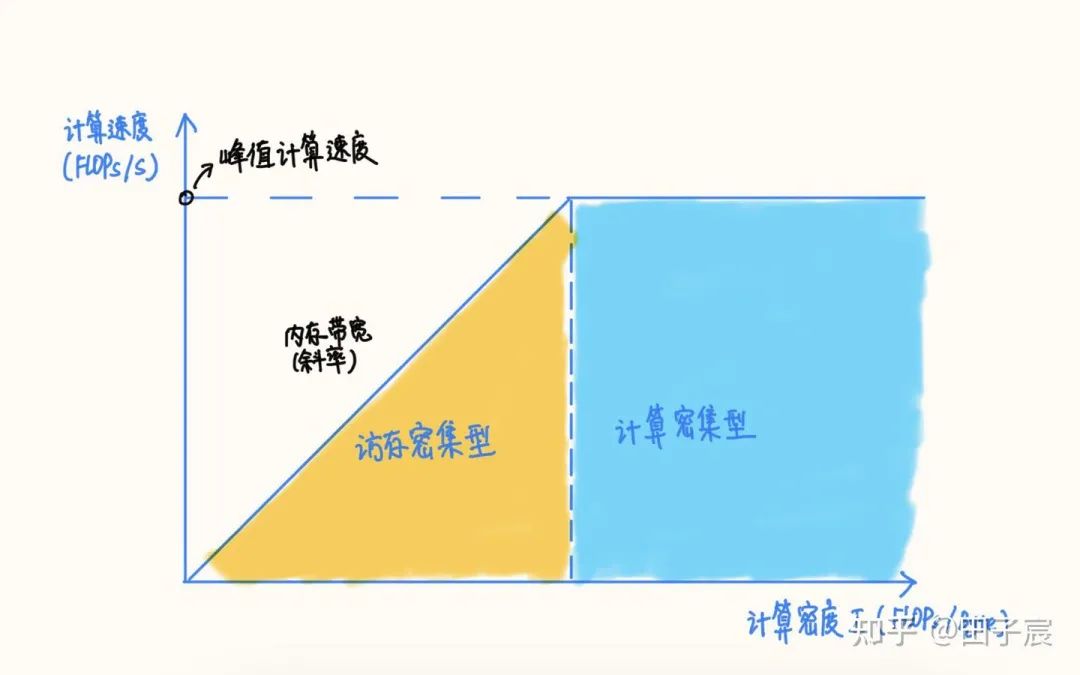 RoofLine 模型
RoofLine 模型
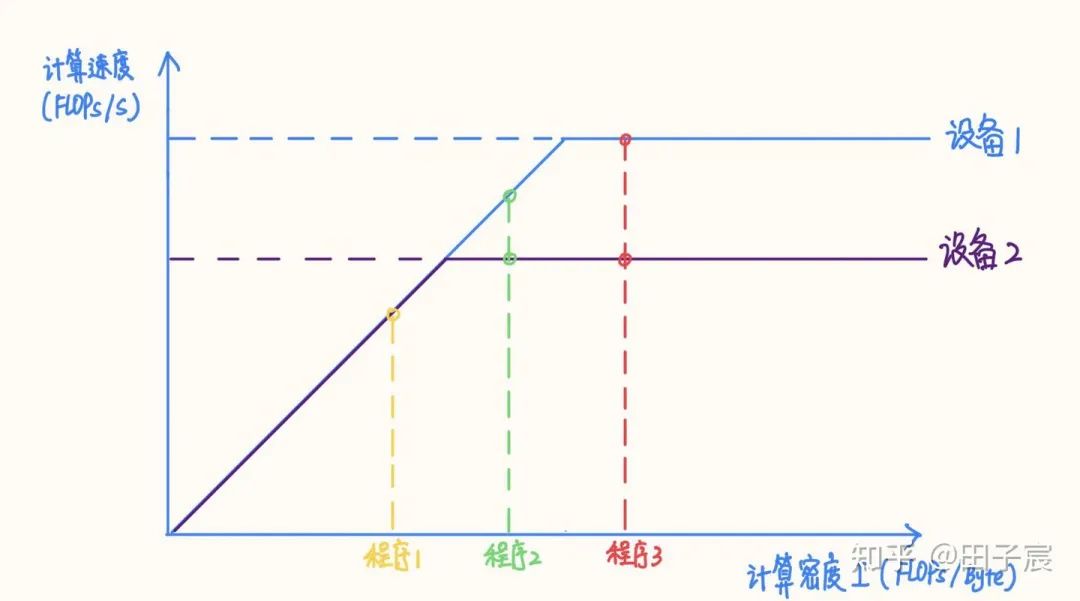
2. 計算密集型算子與訪存密集型算子

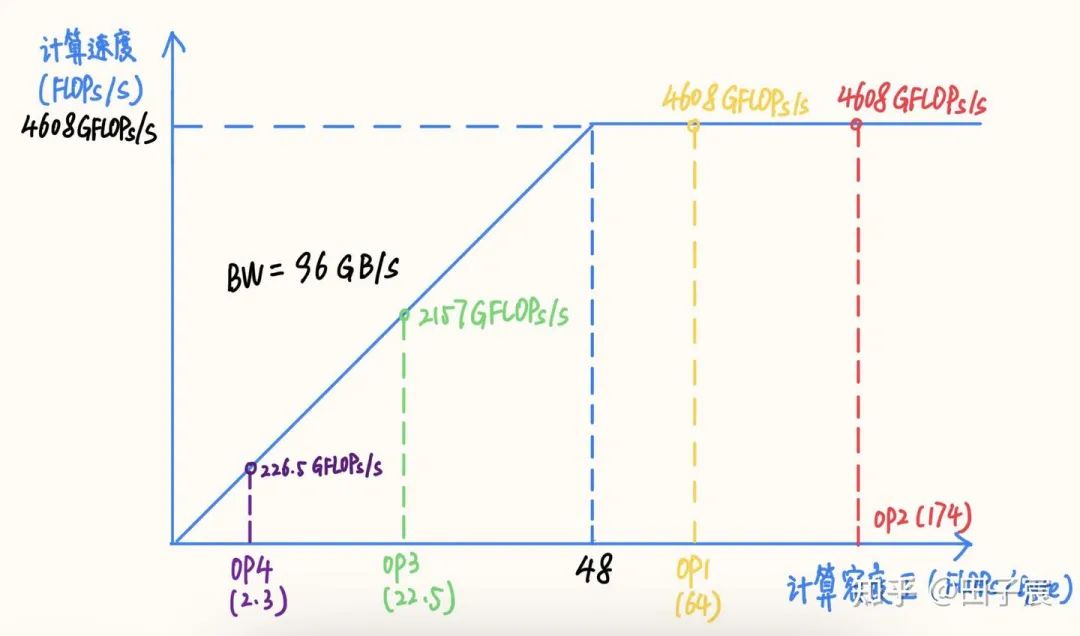
3. 推理時間




4. 小結(jié)
影響模型推理性能的其他因素
1. 硬件限制對性能上界的影響
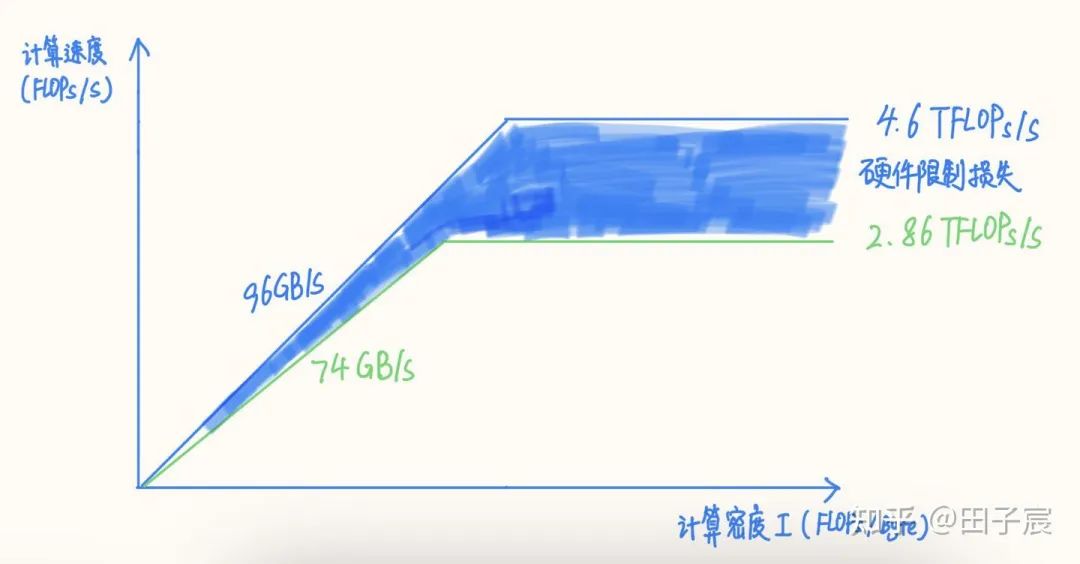
2. 系統(tǒng)環(huán)境對性能的影響
3. 軟件實現(xiàn)對性能的影響
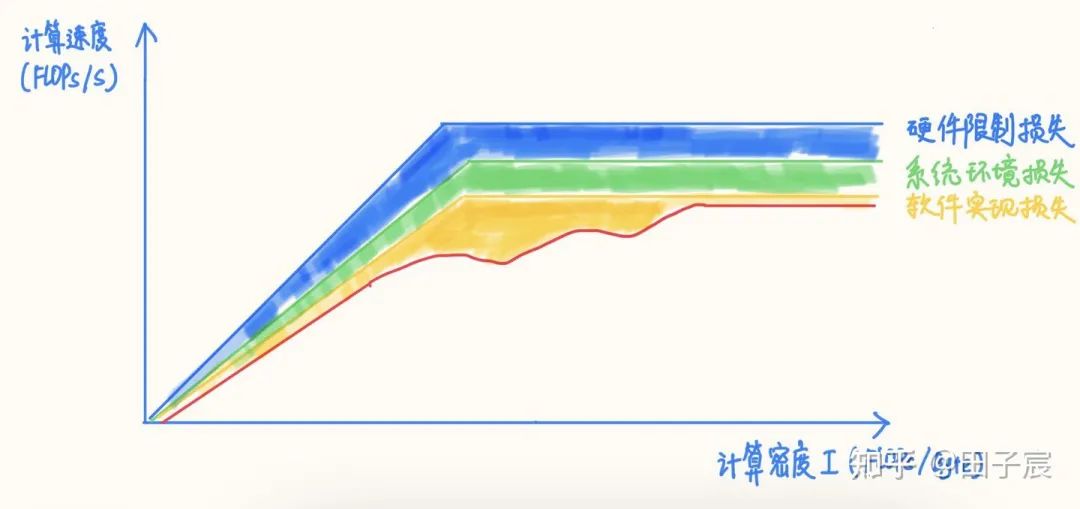
對于一些訪存非常密集且訪存 pattern 連續(xù)的算子,如 Concat、Eltwise Sum、ReLU、LeakyReLU、ReflectionPad 等,在 Tensor 數(shù)據(jù)量很大的情況下,軟件實現(xiàn)的損失會非常小,正常情況下基本都能達到內(nèi)存帶寬實測上限;如果框架采用了融合策略的話,基本可以達到 0 開銷。
對于 Conv/FC/Deconv 等算子,在計算密度很高的情況下,大多數(shù)框架是能夠很接近算力峰值的。但對于計算密度不是特別高的 case,不同框架的表現(xiàn)不一,需要實測才能確定。不過從大趨勢而言,都是計算密度越高,硬件的利用率越高的。
盡量使用常用的算子參數(shù),例如 Conv 盡量使用 3x3_s1/s2,1x1_s1/s2 等,這些常用參數(shù)往往會被特殊優(yōu)化,性能更好。
4. 小結(jié)
面向推理速度的模型設(shè)計建議
了解目標(biāo)硬件的峰值算力和內(nèi)存帶寬,最好是實測值,用于指導(dǎo)網(wǎng)絡(luò)設(shè)計和算子參數(shù)選擇。
明確測試環(huán)境和實際部署環(huán)境的差異,最好能夠在實際部署環(huán)境下測試性能,或者在測試環(huán)境下模擬實際部署環(huán)境。
針對不同的硬件平臺,可以設(shè)計不同計算密度的網(wǎng)絡(luò),以在各個平臺上充分發(fā)揮硬件計算能力(雖然工作量可能會翻好幾倍【捂臉)。
除了使用計算量來表示/對比模型大小外,建議引入訪存量、特定平臺執(zhí)行時間,來綜合反映模型大小。
實測是最準(zhǔn)確的性能評估方式,如果有條件快速實測的話,建議以實測與理論分析相結(jié)合的方式設(shè)計并迭代網(wǎng)絡(luò)。
遇到性能問題時,可以逐層 profiling,并與部署/優(yōu)化同學(xué)保持緊密溝通,具體問題具體分析(適當(dāng)了解一下計算相關(guān)理論的話,可以更高效的溝通)。
對于低算力平臺(CPU、低端 GPU 等),模型很容易受限于硬件計算能力,因此可以采用計算量低的網(wǎng)絡(luò)來降低推理時間。
對于高算力平臺(GPU、DSP 等),一味降低計算量來降低推理時間就并不可取了,往往更需要關(guān)注訪存量。單純降低計算量,很容易導(dǎo)致網(wǎng)絡(luò)落到硬件的訪存密集區(qū),導(dǎo)致推理時間與計算量不成線性關(guān)系,反而跟訪存量呈強相關(guān)(而這類硬件往往內(nèi)存弱于計算)。相對于低計算密度網(wǎng)絡(luò)而言,高計算密度網(wǎng)絡(luò)有可能因為硬件效率更高,耗時不變乃至于更短。
面向推理性能設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)時,盡量采用經(jīng)典結(jié)構(gòu),大部分框架會對這類結(jié)構(gòu)進行圖優(yōu)化,能夠有效減少計算量與訪存量。例如 Conv->BN->ReLU 就會融合成一個算子,但 Conv->ReLU->BN 就無法直接融合 BN 層
算子的參數(shù)盡量使用常用配置,如 Conv 盡量使用 3x3_s1/s2、1x1_s1/s2 等,軟件會對這些特殊參數(shù)做特殊優(yōu)化。
CNN 網(wǎng)絡(luò) channel 數(shù)盡量選擇 4/8/16/32 的冪次,很多框架的很多算子實現(xiàn)在這樣的 channel 數(shù)下效果更好(具體用多少不同平臺不同框架不太一樣)。
框架除了計算耗時外,也處理網(wǎng)絡(luò)拓?fù)洹?nèi)存池、線程池等開銷,這些開銷跟網(wǎng)絡(luò)層數(shù)成正比。因此相比于“大而淺”的網(wǎng)絡(luò),“小而深”的網(wǎng)絡(luò)這部分開銷更大。一般情況下這部分開銷占比不大。但在網(wǎng)絡(luò)算子非常碎、層數(shù)非常多的時候,這部分開銷有可能會影響多線程的擴展性,乃至于成為不可忽視的耗時因素。
除了優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)、推理框架性能外,還可以考慮通過一些其他工程技巧來提升系統(tǒng)整體的性能。例如:對推理服務(wù)流水化,并行數(shù)據(jù)讀取與計算的過程,掩蓋 IO 延時。
看到評論區(qū)有人問有沒有訪存量小的模型結(jié)構(gòu)。一些研究工作,例如 ShuffleNetV2, 已經(jīng)在設(shè)計網(wǎng)絡(luò)的時候兼顧訪存量了。但據(jù)我所知目前還沒有像 DepthWise Conv 一樣經(jīng)典的節(jié)省訪存量的模型結(jié)構(gòu)。
關(guān)于這個問題,我個人是這么看的:
1. 訪存量可以減小,但網(wǎng)絡(luò)精度很難保證不變,因此需要一系列的研究來探索
2. 一些白給訪存量的技巧可以用上,一些白白浪費訪存量的操作不要搞
3. 低精度/量化有的時候節(jié)省訪存量的意義遠(yuǎn)大于節(jié)省計算量
回顧 Xception/ MobileNet 的研究就可以看出,DWConv 3X3 + Conv 1X1 的結(jié)構(gòu)之所以成為經(jīng)典結(jié)構(gòu),一方面是計算量確實減少了,另一方面也是其精度確實沒有太大的損失。計算量可以在設(shè)計完網(wǎng)絡(luò)時就可以算出,但網(wǎng)絡(luò)精度只有在網(wǎng)絡(luò)訓(xùn)練完之后才能評估,需要花費大量的時間與精力反復(fù)探索才能找到這一結(jié)構(gòu)。
一些研究確實開始關(guān)注訪存量對推理速度的影響,例如 ShuffleNetV2 在選定 group 的時候就是以訪存量為依據(jù)的,但并不是整體的 block 都是圍繞降低訪存量來設(shè)計的。由于本人很久沒有關(guān)注算法的研究進展了,據(jù)我所知目前是沒有專注于減少放存量的模型結(jié)構(gòu)及研究工作的(如果有的話歡迎在評論區(qū)留言)。
我個人認(rèn)為這可以成為一個很好的研究主題,可以為模型部署帶來很大的幫助。一種方法是可以通過手工設(shè)計網(wǎng)絡(luò)結(jié)構(gòu),另一種方法是可以將訪存量作為 NAS 的一個參數(shù)進行搜索。前者可解釋性更強一些,后者可能研究起來更容易。但是有一點請務(wù)必注意:降低訪存量的最終目的一定是為了減少模型的推理時間。如果模型處在目標(biāo)設(shè)備的計算密集區(qū),降低訪存量的意義有限。
關(guān)于實際工程部署,有一些技巧/注意的點可以保證不浪費訪存量:
1. channel 數(shù)盡量保持在 4/8/16/32 的倍數(shù),不要設(shè)計 channel = 23 這種結(jié)構(gòu)。目前大部分推理框架為了加速計算,都會用特殊的數(shù)據(jù)排布,channel 會向上 pad。比如框架會把 channel pad 到 4 的倍數(shù),那么 channel = 23 和 24 在訪存量上其實是一致的。
2. 一些非常細(xì)碎乃至毫無意義的后處理算子,例如 Gather、Squeeze、Unsqueeze 等,最好給融合掉。這種現(xiàn)象往往見于 PyTorch 導(dǎo)出 onnx 的時候,可以嘗試使用 onnxsim 等工具來進行融合,或者手動添加大算子。
3. 嘗試一些部署無感的技巧,例如蒸餾、RepVGG(感謝
@OLDPAN
)等。
最后想聊一下低精度/量化。對于設(shè)備算力很強但模型很小的情況,低精度/量化我個人認(rèn)為其降低訪存量的作用要遠(yuǎn)大于節(jié)省計算量,可以有效加快模型推理速度。但是要注意兩點:一個是框架如果不支持 requant,而是每次計算前都量化一次,計算完之后再反量化,那么使用低精度/量化反而會增加訪存量,可能造成推理性能的下降;另一個是對于支持混合精度推理的框架,要注意不同精度轉(zhuǎn)換時是否會有額外的性能開銷。如果有的話,要盡量減少精度的轉(zhuǎn)換。
END

你的每一個“在看”,我都當(dāng)成了喜歡
▼