
論文速遞:金字塔Transformer,更適合稠密預測任務的Transformer骨干架構

極市導讀
本文是南京大學&港中文&南理工&商湯在Transformer方面的又一次探索,該文主要針對稠密預測任務的骨干的Transformer架構設計進行了一次創(chuàng)新性的探索,將特征金字塔結構與Transformer進行了一次融合,使其可以更好的輸出多尺度特征,進而更方便與其他下游任務相結合。 >>加入極市CV技術交流群,走在計算機視覺的最前沿

本文是南京大學&港中文&南理工&商湯在Transformer方面的又一次探索,該文主要針對稠密預測任務的骨干的Transformer架構設計進行了一次創(chuàng)新性的探索,將特征金字塔結構與Transformer進行了一次融合,使其可以更好的輸出多尺度特征,進而更方便與其他下游任務相結合。本文為Transformer在計算機視覺領域的應用提供了一個非常好的開頭,期待有更優(yōu)秀的Transformer在CV領域的應用于探索。
Abstract
以CNN為骨干的方案在計算機視覺的各個領域均取得極大的成功,本文研究了一種簡單的無卷積骨干網(wǎng)絡用于諸多稠密預測任務(包含檢測、分割等)。近來提出的Transformer(ViT)主要是針對圖像分類任務而設計,我們提出稠密預測任務提出了一種PVT方案(Pyramid Vision Transformer),它克服了將ViT向稠密預測任務遷移的困難。
(1) 不同于ViT的低分辨率輸出、高計算復雜度與內存消耗,PVT不僅可以得到更高分辨率的輸出(這對于稠密預測任務尤為重要),同時按照金字塔形式漸進式收縮特征分辨率;
(2) PVT繼承了CNN與Transformer的優(yōu)勢,通過簡單的替換CNN骨干使其成為不同視覺任務的統(tǒng)一骨干結構;
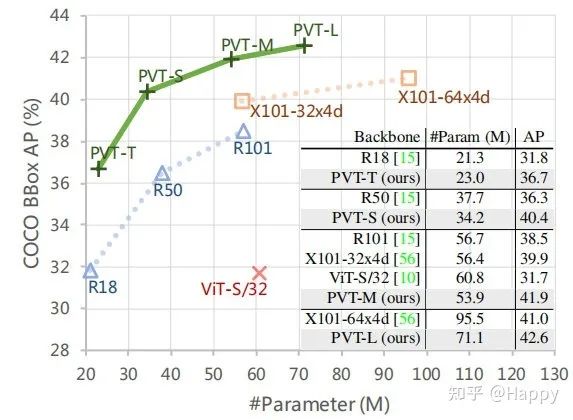
(3) 通過充分的實驗驗證了PVT的優(yōu)越性,在目標檢測、語義分割、實例分割等任務上PVT均取得了優(yōu)異性能。比如RetinaNet+PVT在COCO數(shù)據(jù)集上取得了40.4AP指標,超越了RetinaNet+ResNet50的36.3AP。
Method
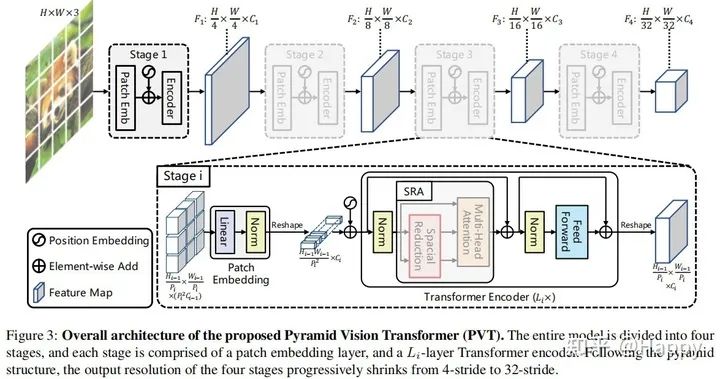
本文旨在將金字塔結構嵌入到Transformer結構用于生成多尺度特征,并最終用于稠密預測任務。上圖給出了本文所提PVT的架構示意圖,類似與CNN骨干結構,PVT同樣包含四個階段用于生成不同尺度的特征,所有階段具有相類似的結構:Patch Embedding+Transformer Encoder。
在第一個階段,給定尺寸為的輸入圖像,我們按照如下流程進行處理:
首先,將其劃分為的塊(這里是為了與ResNet對標,最大輸出特征的尺寸為原始分辨率的1/4),每個塊的大小為; 然后,將展開后的塊送入到線性投影曾得到尺寸為的嵌入塊; 其次,將前述嵌入塊與位置嵌入信息送入到Transformer的Encoder,其輸出將為reshap為.
采用類似的方式,我們以前一階段的輸出作為輸入即可得到特征。基于特征金字塔,所提方案可以輕易與大部分下游任務(如圖像分類、目標檢測、語義分割)進行集成。
Feature Pyramid for Transformer
不同于CNN采用stride卷積獲得多尺度特征,PVT通過塊嵌入曾按照progressive shrinking策略控制特征的尺度。
我們假設第i階段的塊尺寸為,在每個階段的開始,我們將輸入特征均勻的拆分為個塊,然后每個塊展開并投影到維度的嵌入信息,經(jīng)過線性投影后,嵌入塊的尺寸可以視作。通過這種方式我們就可以靈活的調整每個階段的特征尺寸,使其可以針對Transformer構建特征金字塔。該過程的code描述如下:
class PatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)self.img_size = img_sizeself.patch_size = patch_sizeassert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \f"img_size {img_size} should be divided by patch_size {patch_size}."self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]self.num_patches = self.H * self.Wself.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = nn.LayerNorm(embed_dim)def forward(self, x):B, C, H, W = x.shapex = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)H, W = H // self.patch_size[0], W // self.patch_size[1]return x, (H, W)
從實現(xiàn)上來看,其實這里還是通過stride=2的卷積進行的實現(xiàn),汗一個。
Transformer Encoder
對于Transformer encoder的第i階段,它具有個encoder層,每個encoder層由注意力層與MLP構成。由于所提方法需要處理高分辨率特征,所以我們提出了一種SRA(spatial-reduction attention)用于替換傳統(tǒng)的MHA(multi-head-attention)。
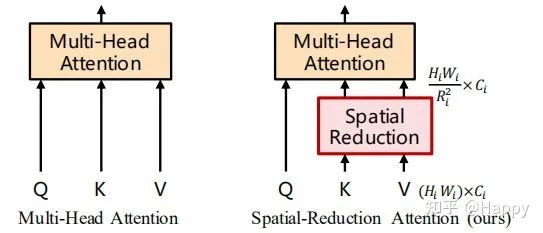
類似于MHA,SRA同樣從輸入端接收到了Q、K、V作為輸入,并輸出精煉后特征。SRA與MHA的區(qū)別在于:SRA會降低K和V的空間尺度,見上圖。SRA的處理過程可以描述如下:
也就是說每個head的維度等于,為空間尺度下采樣操作,定義如下:
其他的就跟MHA沒什么區(qū)別了,這里提供一下SRA的code實現(xiàn),關鍵區(qū)別就是sr_ratio相關的那一部分。
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):super().__init__()assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."self.dim = dimself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.q = nn.Linear(dim, dim, bias=qkv_bias)self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.sr_ratio = sr_ratioif sr_ratio > 1:self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)self.norm = nn.LayerNorm(dim)def forward(self, x, H, W):B, N, C = x.shapeq = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)if self.sr_ratio > 1:x_ = x.permute(0, 2, 1).reshape(B, C, H, W)x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)x_ = self.norm(x_)kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)else:kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)k, v = kv[0], kv[1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xModel Details
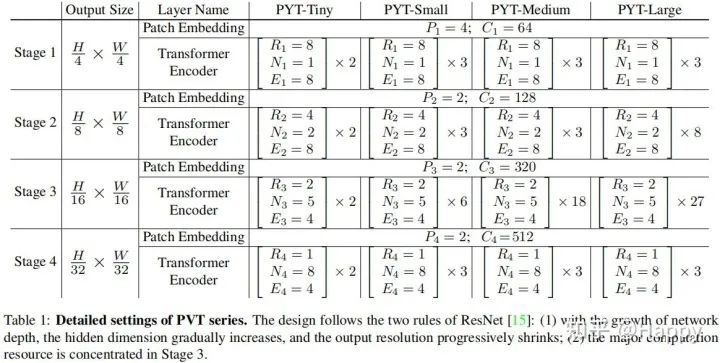
總而言之,所提方案涉及的超參數(shù)包含如下:
:階段i的塊尺寸; :階段i的通道數(shù); :階段i的encoder層數(shù); :階段i中SRA的下采樣比例; :階段i的head數(shù)量; :階段i中MLP的擴展比例。
延續(xù)ResNet的設計準則,我們在淺層采用較小的輸出通道數(shù);在中間階段聚焦主要的計算量。為更好的討論與分析,我們設計了不同大小的PVT模型,定義見下表。
Experiments
為說明所提方案的有效性,我們在圖像分類、目標檢測、語義分割、實例分割等任務上進行了對比分析。
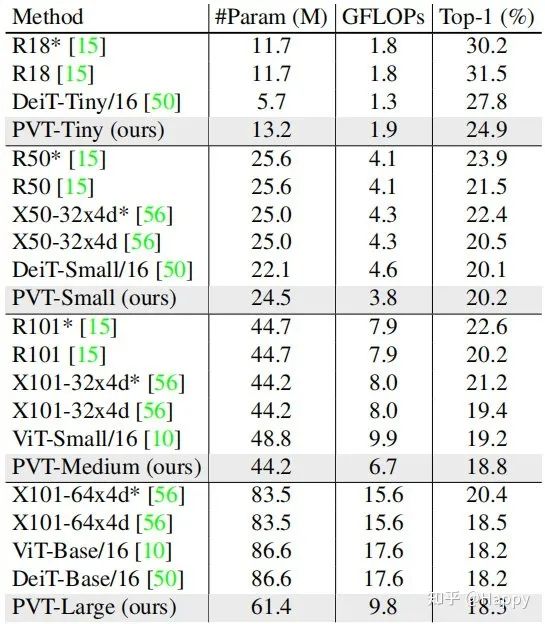
首先,我們來看一下ImageNet數(shù)據(jù)集上的性能對比,結果見上表。從中可以看到:
相比CNN,在同等參數(shù)量與計算約束下,PVT-Small達到20.2%的誤差率,優(yōu)于ResNet50的21.5%; 相比其他Transformer(如ViT、DeiT),所提PVT以更少的計算量取得了相當?shù)男阅堋?span style="color: black;font-family: mp-quote, apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0px;text-align: justify;">
然后,我們再來看一下目標檢測方面的性能對比,結果見上表。從中可以看到:在參數(shù)量相當?shù)那闆r下,PVT顯著性的優(yōu)于CNN方案,這說明PVT是一個CNN之外的一個好的選擇。類似的現(xiàn)象在Mask RCNN體系下仍可發(fā)現(xiàn),見下表。
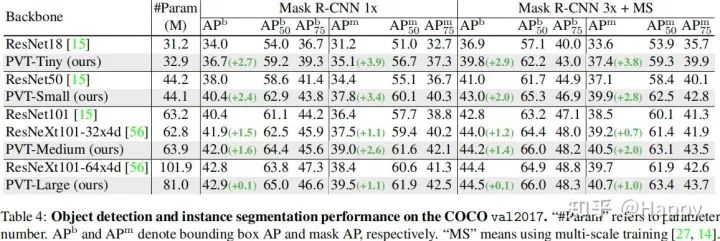
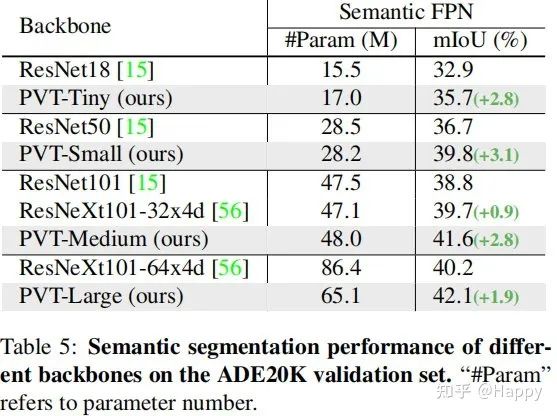
其次,我們看一下所提方案在語義分割中的性能對比,見上表。可以看到:不同參數(shù)配置下,PVT均可取得優(yōu)于ResNet與ResNeXt的性能。這側面說明:相比CNN,受益于全局注意力機制,PVT可以提取更好的特征用于語義分割。
全文到此結束,更多消融實驗與分析建議各位同學查看原文。
推薦閱讀
2021-01-12
2021-01-05
2020-12-06


# CV技術社群邀請函 #
備注:姓名-學校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術交流群
每月大咖直播分享、真實項目需求對接、求職內推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
