
無卷積骨干網(wǎng)絡:金字塔Transformer,提升目標檢測/分割等任務精度(附源代碼)
點擊下方“AI算法與圖像處理”,一起進步!
重磅干貨,第一時間送達

在將金字塔結(jié)構(gòu)嵌入到Transformer結(jié)構(gòu)用于生成多尺度特征,并最終用于稠密預測任務。

在今天分享的工作中,研究者設計了一個新穎的Transformer模塊,針對稠密預測任務的主干網(wǎng)絡,利用Transformer架構(gòu)設計進行了一次創(chuàng)新性的探索,將特征金字塔結(jié)構(gòu)與Transformer進行了一次融合,使其可以更好的輸出多尺度特征,進而更方便與其他下游任務相結(jié)合。
盡管卷積神經(jīng)網(wǎng)絡 (CNN) 在計算機視覺方面取得了巨大成功,但今天分享的這項工作研究了一種更簡單、無卷積的主干網(wǎng)絡,可用于許多密集預測任務。
目標檢測

語義分割

實例分割
與最近提出的專為圖像分類設計的Vision Transformer(ViT)不同,研究者引入了Pyramid Vision Transformer(PVT),它克服了將Transformer移植到各種密集預測任務的困難。與當前的技術(shù)狀態(tài)相比,PVT 有幾個優(yōu)點:
與通常產(chǎn)生低分辨率輸出并導致高計算和內(nèi)存成本的ViT不同,PVT不僅可以在圖像的密集分區(qū)上進行訓練以獲得對密集預測很重要的高輸出分辨率,而且還使用漸進式收縮金字塔以減少大型特征圖的計算;
PVT繼承了CNN和Transformer的優(yōu)點,使其成為各種視覺任務的統(tǒng)一主干,無需卷積,可以直接替代CNN主干;
通過大量實驗驗證了PVT,表明它提高了許多下游任務的性能,包括對象檢測、實例和語義分割。
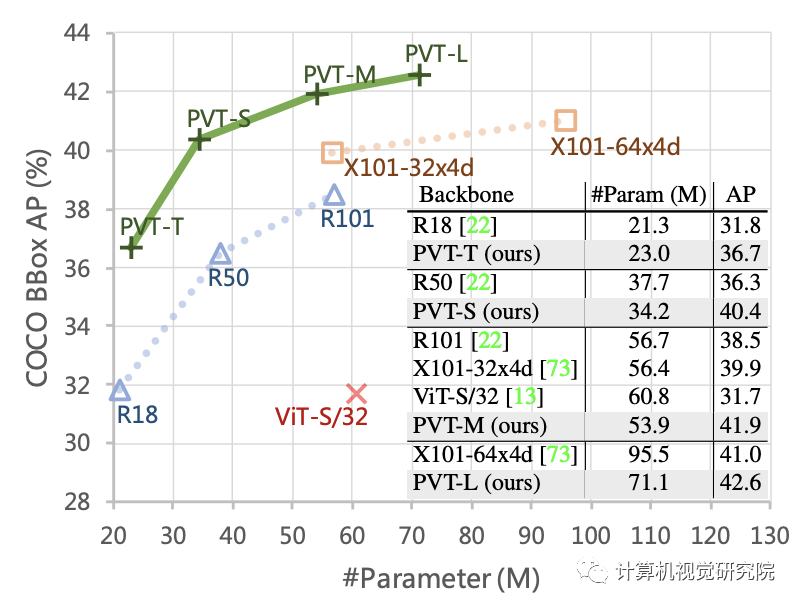
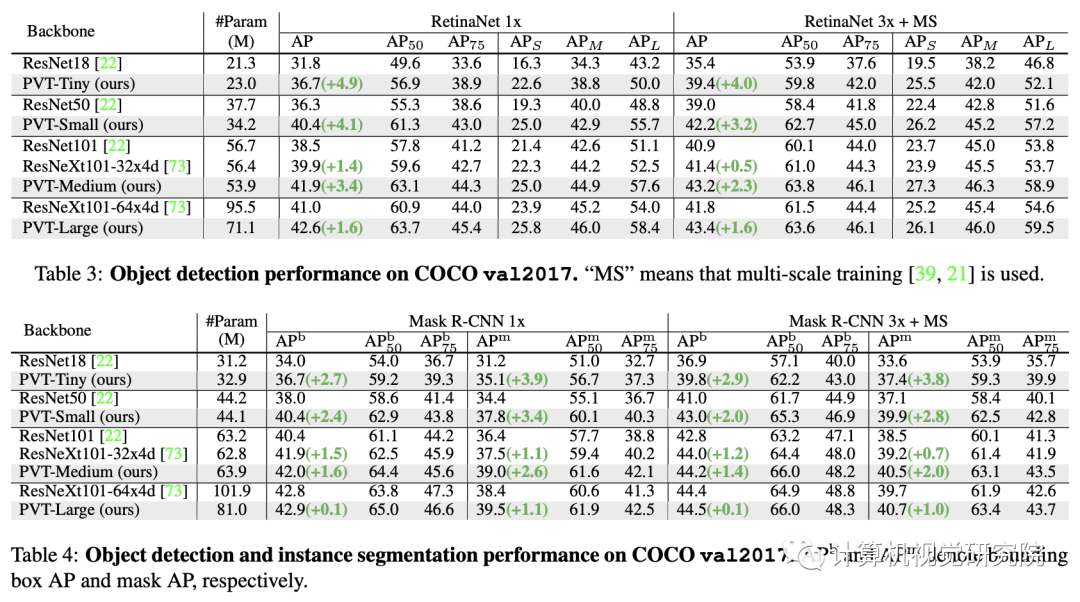
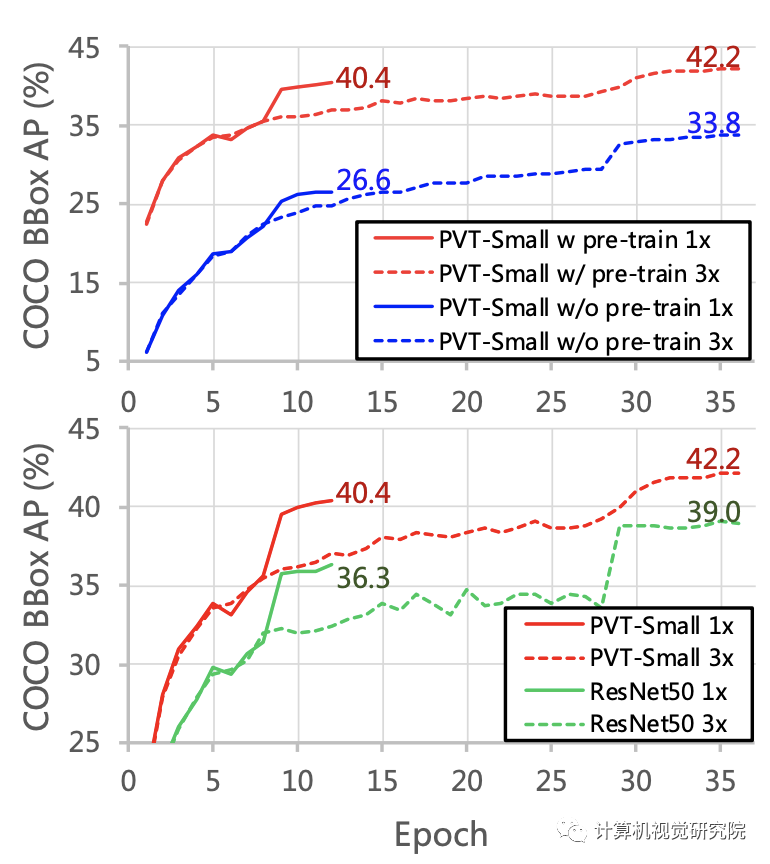
例如,在參數(shù)數(shù)量相當?shù)那闆r下,PVT+RetinaNet在COCO數(shù)據(jù)集上實現(xiàn)了40.4 AP,超過ResNet50+RetinNet(36.3 AP)4.1個絕對AP(見下圖)。研究者希望PVT可以作為像素級預測的替代和有用的主干,并促進未來的研究。
CNN Backbones
CNN是視覺識別中深度神經(jīng)網(wǎng)絡的主力軍。標準CNN最初是在【Gradient-based learning applied to document recognition】中區(qū)分手寫數(shù)字。該模型包含具有特定感受野的卷積核捕捉有利的視覺環(huán)境。為了提供平移等方差,卷積核的權(quán)重在整個圖像空間中共享。最近,隨著計算資源的快速發(fā)展(例如,GPU),堆疊卷積塊成功在大規(guī)模圖像分類數(shù)據(jù)集上訓練(例如,ImageNet)已經(jīng)成為可能。例如,GoogLeNet證明了包含多個內(nèi)核路徑的卷積算子可以實現(xiàn)非常有競爭力的性能。
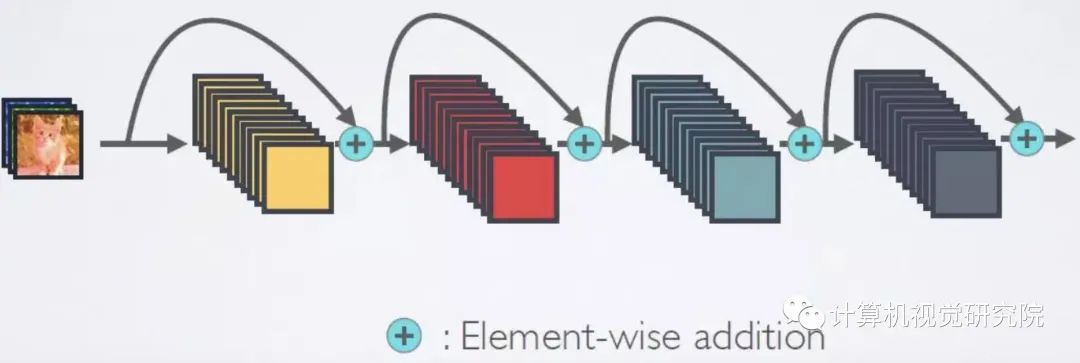
multi-path convolutional block的有效性在Inception系列、ResNeXt、DPN、MixNet和SKNet中得到了進一步驗證。此外,ResNet將跳過連接引入到卷積塊中,從而可以創(chuàng)建/訓練非常深的網(wǎng)絡并在計算機視覺領域獲得令人印象深刻的結(jié)果。DenseNet引入了一個密集連接的拓撲,它將每個卷積塊連接到所有先前的塊。更多最新進展可以在最近的論文中找到。
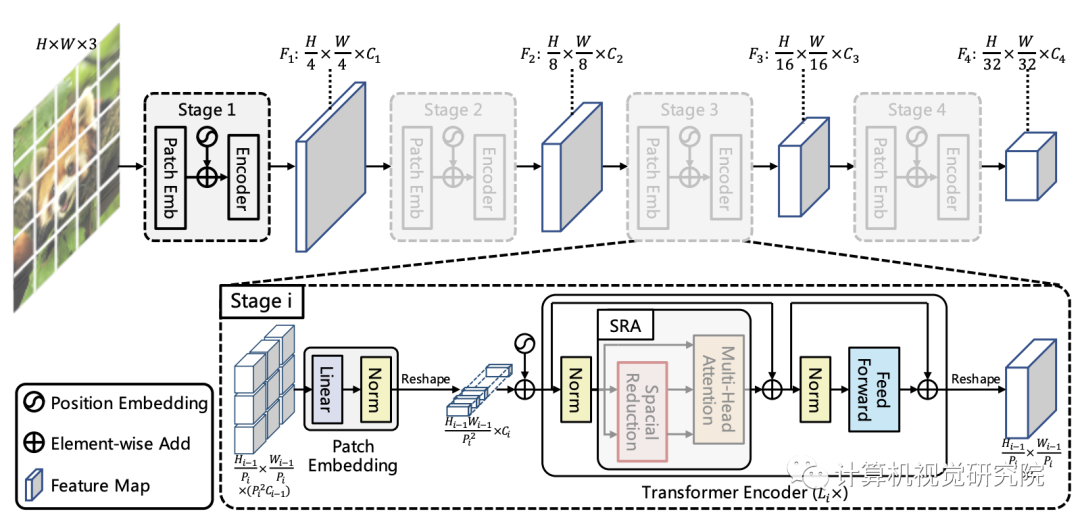
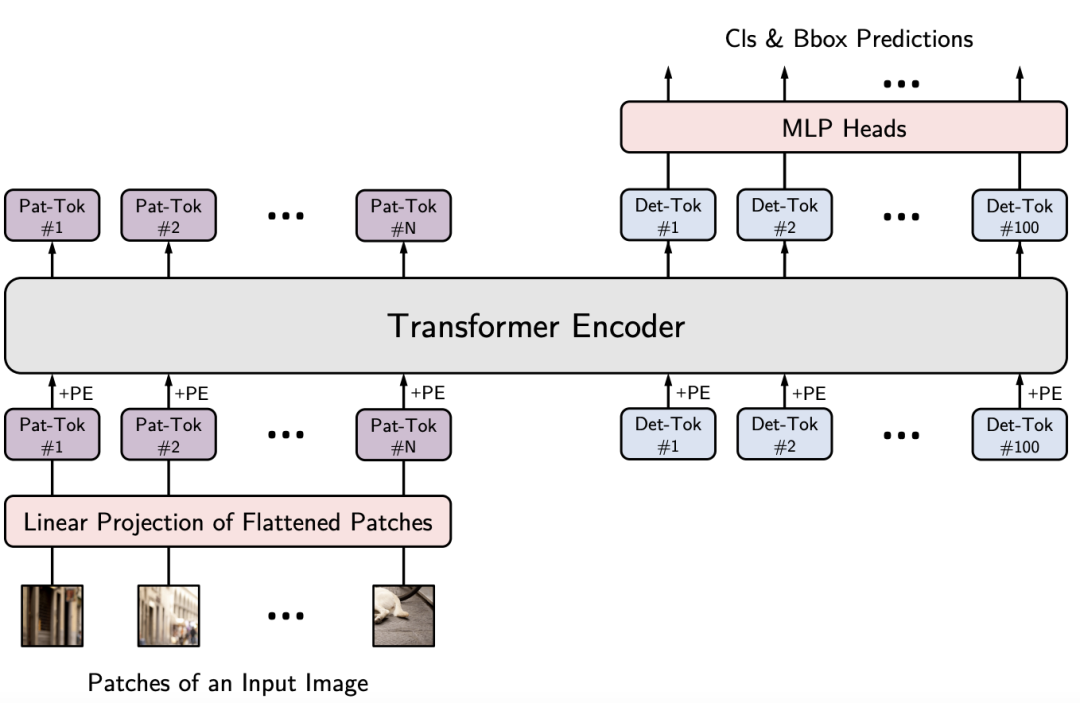
該框架旨在將金字塔結(jié)構(gòu)嵌入到Transformer結(jié)構(gòu)用于生成多尺度特征,并最終用于稠密預測任務。上圖給出了所提出的PVT架構(gòu)示意圖,類似與CNN主干結(jié)構(gòu),PVT同樣包含四個階段用于生成不同尺度的特征,所有階段具有相類似的結(jié)構(gòu):Patch Embedding+Transformer Encoder。
在第一個階段,給定尺寸為H*W*3的輸入圖像,按照如下流程進行處理:
首先,將其劃分為HW/4^2的塊,每個塊的大小為4*4*3; 然后,將展開后的塊送入到線性投影,得到尺寸為HW/4^2 * C1的嵌入塊; 其次,將前述嵌入塊與位置嵌入信息送入到Transformer的Encoder,其輸出將為reshap為H/4 * W/4 * C1。
采用類似的方式,以前一階段的輸出作為輸入即可得到特征F2,F(xiàn)3和F4。基于特征金字塔F1、F2、F3、F4,所提方案可以輕易與大部分下游任務(如圖像分類、目標檢測、語義分割)進行集成。
Feature Pyramid for Transforme
不同于CNN采用stride卷積獲得多尺度特征,PVT通過塊嵌入按照progressive shrinking策略控制特征的尺度。
假設第i階段的塊尺寸為Pi,在每個階段的開始,將輸入特征均勻的拆分為Hi-1Wi-1/Pi個塊,然后每個塊展開并投影到Ci維度的嵌入信息,經(jīng)過線性投影后,嵌入塊的尺寸可以視作Hi-1/Pi * Wi-1/Pi * Ci。通過這種方式就可以靈活的調(diào)整每個階段的特征尺寸,使其可以針對Transformer構(gòu)建特征金字塔。
Transformer Encoder
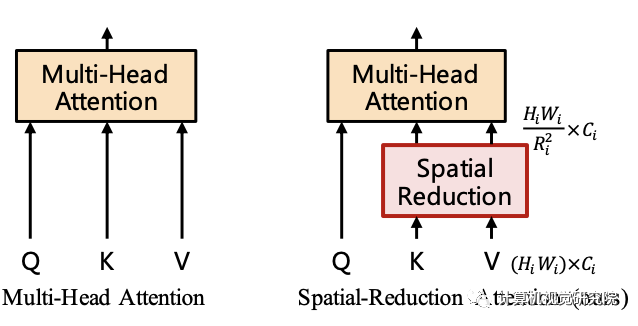
對于Transformer encoder的第i階段,它具有Li個encoder層,每個encoder層由注意力層與MLP構(gòu)成。由于所提方法需要處理高分辨率特征,所以提出了一種SRA(spatial-reduction attention)用于替換傳統(tǒng)的MHA(multi-head-attention)。
類似于MHA,SRA同樣從輸入端接收到了Q、K、V作為輸入,并輸出精煉后特征。SRA與MHA的區(qū)別在于:SRA會降低K和V的空間尺度,見下圖。
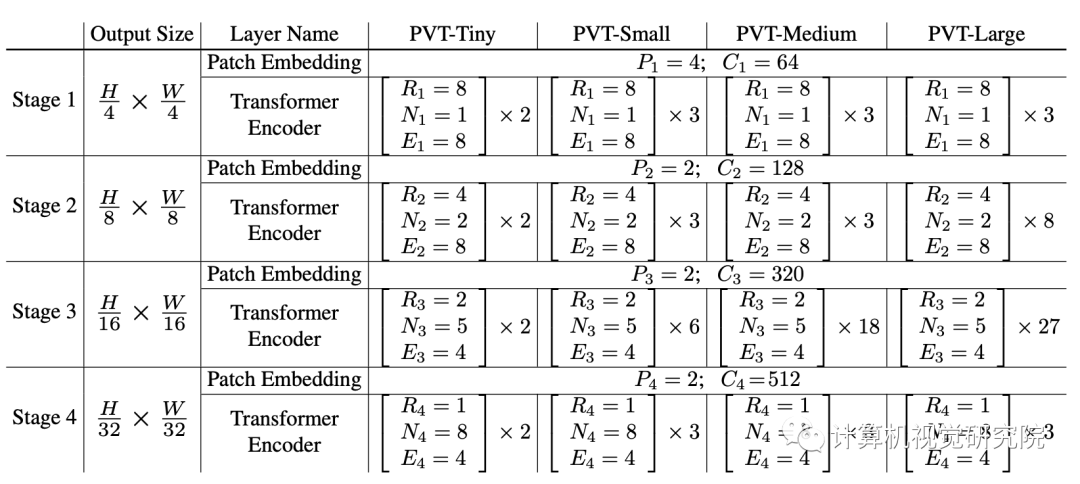
Detailed settings of PVT series
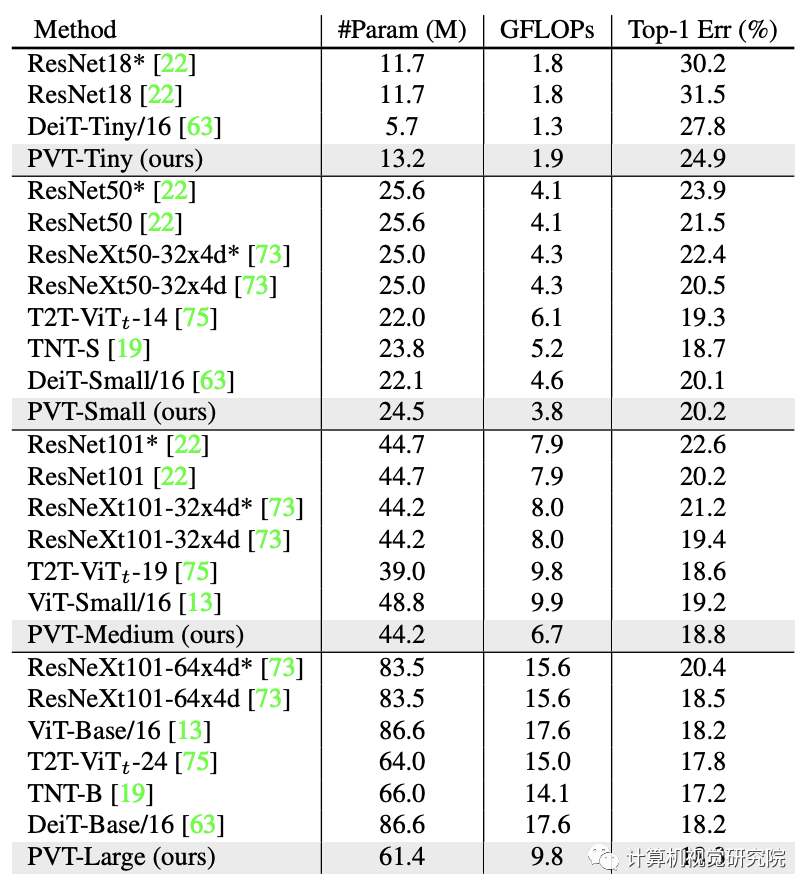
ImageNet數(shù)據(jù)集上的性能對比,結(jié)果見上表。從中可以看到:
相比CNN,在同等參數(shù)量與計算約束下,PVT-Small達到20.2%的誤差率,優(yōu)于ResNet50的21.5%; 相比其他Transformer(如ViT、DeiT),所提PVT以更少的計算量取得了相當?shù)男阅堋?/span>
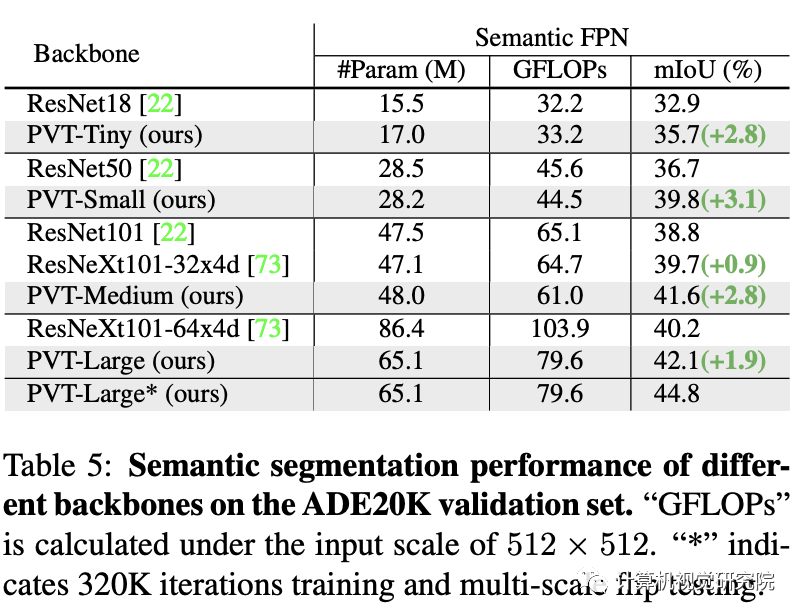
在語義分割中的性能對比,見上表。可以看到:不同參數(shù)配置下,PVT均可取得優(yōu)于ResNet與ResNeXt的性能。這側(cè)面說明:相比CNN,受益于全局注意力機制,PVT可以提取更好的特征用于語義分割。

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復:何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風格指南
在「AI算法與圖像處理」公眾號后臺回復:c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復:CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
