
MySQL:從B樹(shù)到B+樹(shù)到索引再到存儲(chǔ)引擎
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


來(lái)源:blog.csdn.net/that_is_cool/article/details/81069945
索引其實(shí)是一種數(shù)據(jù)結(jié)構(gòu),在數(shù)據(jù)庫(kù)中,讀寫的比例是在10:1,所以如果每一次查找都全表查找的話,效率將會(huì)變的十分的低下。所以,本文將會(huì)按照題目,按部就班地講解MySql的索引。
##B樹(shù)和B+樹(shù) B樹(shù)和B+樹(shù)算是數(shù)據(jù)結(jié)構(gòu)中出現(xiàn)頻率十分高的模型了,在筆者之前的幾篇博客,有對(duì)二叉查找樹(shù)和二叉平衡樹(shù)進(jìn)行過(guò)講解和代碼分析,但是那些都是在程序中使用比較多的樹(shù),在數(shù)據(jù)庫(kù)中,數(shù)據(jù)量相對(duì)較大,多路查找樹(shù)顯然更加適合數(shù)據(jù)庫(kù)的應(yīng)用場(chǎng)景,接下來(lái)我們就介紹這兩類多路查找樹(shù),畢竟作為程序員,心里沒(méi)點(diǎn)B樹(shù)怎么能行呢?
B樹(shù):B樹(shù)就是B-樹(shù),他有著如下的特性:
B樹(shù)不同于二叉樹(shù),他們的一個(gè)節(jié)點(diǎn)可以存儲(chǔ)多個(gè)關(guān)鍵字和多個(gè)子樹(shù)指針,這也是B+樹(shù)的特點(diǎn); 一個(gè)m階的B樹(shù)要求除了根節(jié)點(diǎn)以外,所有的非葉子子節(jié)點(diǎn)必須要有[m/2,m]個(gè)子樹(shù); 根節(jié)點(diǎn)必須只能有兩個(gè)子樹(shù),當(dāng)然,如果只有根節(jié)點(diǎn)一個(gè)節(jié)點(diǎn)的情況存在; B樹(shù)是一個(gè)查找二叉樹(shù),這點(diǎn)和二叉查找樹(shù)很像,他都是越靠前的子樹(shù)越小,并且,同一個(gè)節(jié)點(diǎn)內(nèi),關(guān)鍵字按照大小排序; B樹(shù)的一個(gè)節(jié)點(diǎn)要求子樹(shù)的個(gè)數(shù)等于關(guān)鍵字的個(gè)數(shù)+1;
好了,話不多說(shuō),看看B樹(shù)的模型吧:
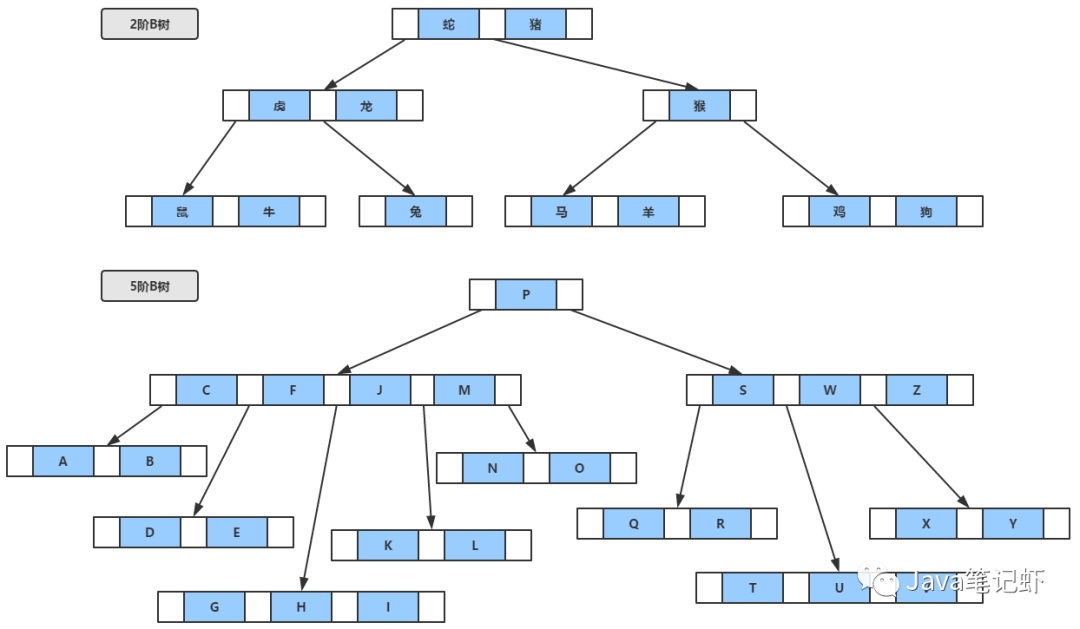
由于B樹(shù)將所有的查找關(guān)鍵字都放在節(jié)點(diǎn)中,所以查找方式和二叉查找十分相像,比如說(shuō)查找E:
先通過(guò)根節(jié)點(diǎn)找到了左子樹(shù),再順序地遍歷左子樹(shù),發(fā)現(xiàn)E在F和J的中間,于是查找葉子節(jié)點(diǎn),順序遍歷關(guān)鍵字以后就可以返回E了,如果未能查到E,則表示沒(méi)有找到。
B+樹(shù)
人人都喜歡plus,B+樹(shù)就是這么一個(gè)plus,后頭所講解的索引,就是用的B+樹(shù),我們先來(lái)看看他的特性吧:
B+樹(shù)將所有的查找結(jié)果放在葉子節(jié)點(diǎn)中,這也就意味著查找B+樹(shù),就必須到葉子節(jié)點(diǎn)才能返回結(jié)果; B+樹(shù)每一個(gè)節(jié)點(diǎn)的關(guān)鍵字個(gè)數(shù)和子樹(shù)指針個(gè)數(shù)相同; B+樹(shù)的非葉子節(jié)點(diǎn)的每一個(gè)關(guān)鍵字對(duì)應(yīng)一個(gè)指針,而關(guān)鍵字則是子樹(shù)的最大,或者最小值;
看看模型吧:
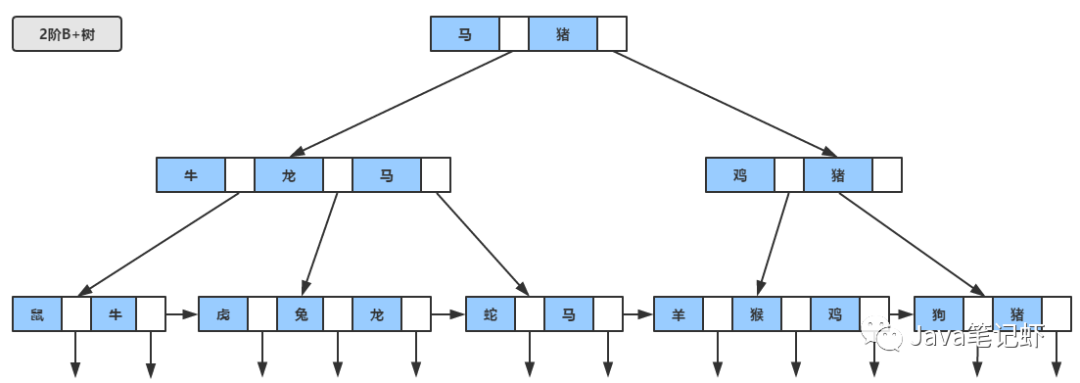
他的查找方式也是簡(jiǎn)單粗暴的,和B樹(shù)十分像,只不過(guò)他會(huì)在葉子節(jié)點(diǎn)中找到目標(biāo),比如我們找兔:
第一步比馬小,就會(huì)查找他的子樹(shù),第二部比龍小,就會(huì)查找他的子樹(shù),最后在葉子節(jié)點(diǎn)中的關(guān)鍵字命中目標(biāo)。
那么MySql是如何利用這數(shù)據(jù)結(jié)構(gòu)的呢?
MySql中的兩種常見(jiàn)存儲(chǔ)引擎
MySql當(dāng)然不止兩種搜索引擎了,但是本次我們說(shuō)的B+樹(shù)索引,為接下來(lái)這兩種存儲(chǔ)引擎所用,一個(gè)是Innodb,一個(gè)Myisam。(搜索公眾號(hào)Java知音,回復(fù)“2021”,送你一份Java面試題寶典)
Innodb存儲(chǔ)引擎
Innodb使用的是B+樹(shù),他存在有一個(gè)主鍵索引和輔助索引兩種索引,主鍵索引是在生成主鍵時(shí)就有的索引,他的葉子節(jié)點(diǎn)中存放的就是數(shù)據(jù)行,所以又稱之為聚集索引。
而另一類索引,輔助索引,就是我們?nèi)藶樾陆ǖ乃饕娜~子節(jié)點(diǎn)中存放的是主鍵,當(dāng)我們通過(guò)輔助索引查找到主鍵之后,再通過(guò)查找的主鍵去查找主鍵索引,我們看看兩種索引的結(jié)構(gòu)吧:
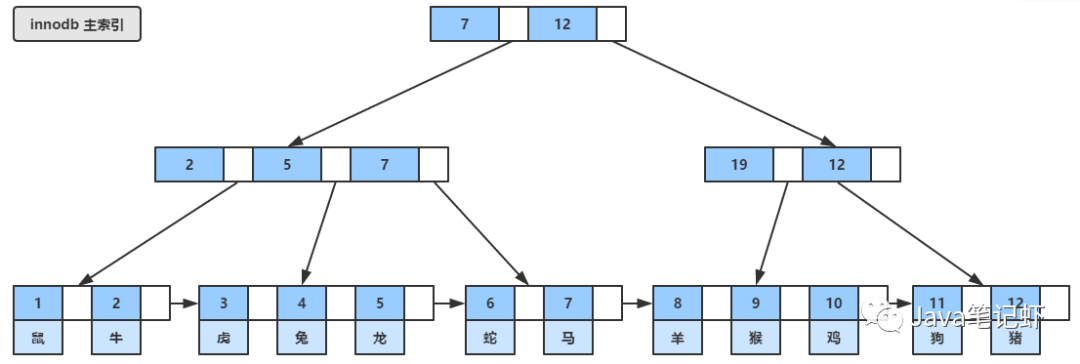
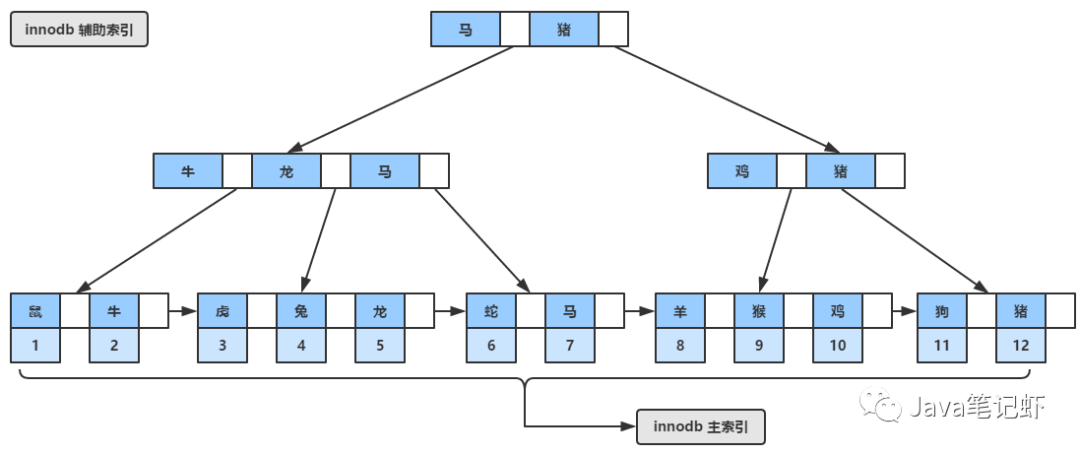
MyIsam存儲(chǔ)引擎
很顯然,MyIsam不可能再會(huì)用聚集索引了,雖然他用的是B+樹(shù),但是他的主鍵索引和輔助索引沒(méi)有任何區(qū)別,都是在葉子中存儲(chǔ)數(shù)據(jù)行的物理地址,這也使得他的讀性能更高,我們來(lái)看他的模型吧:
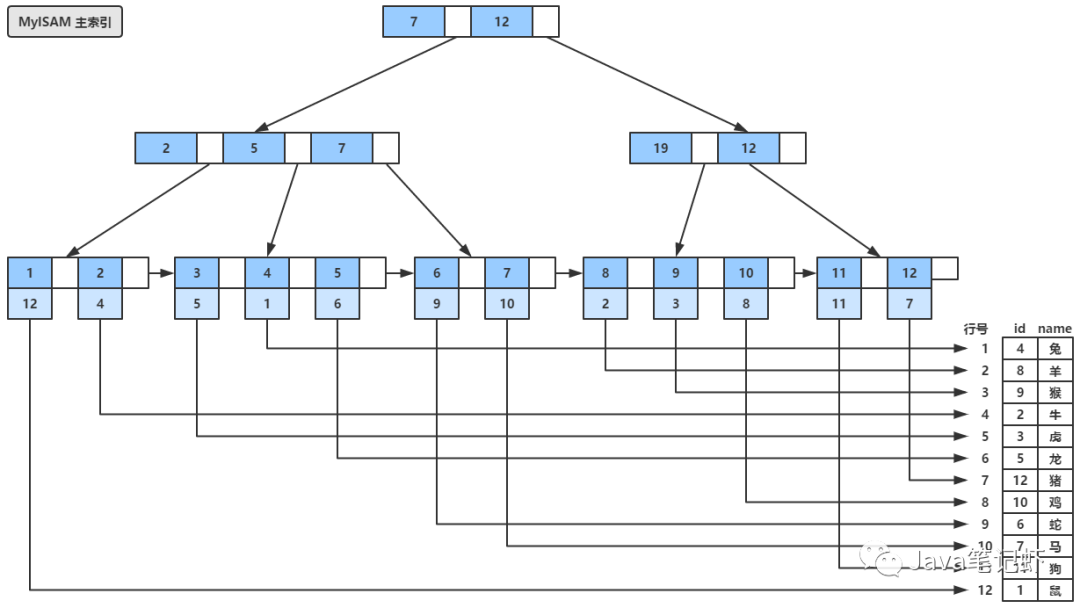
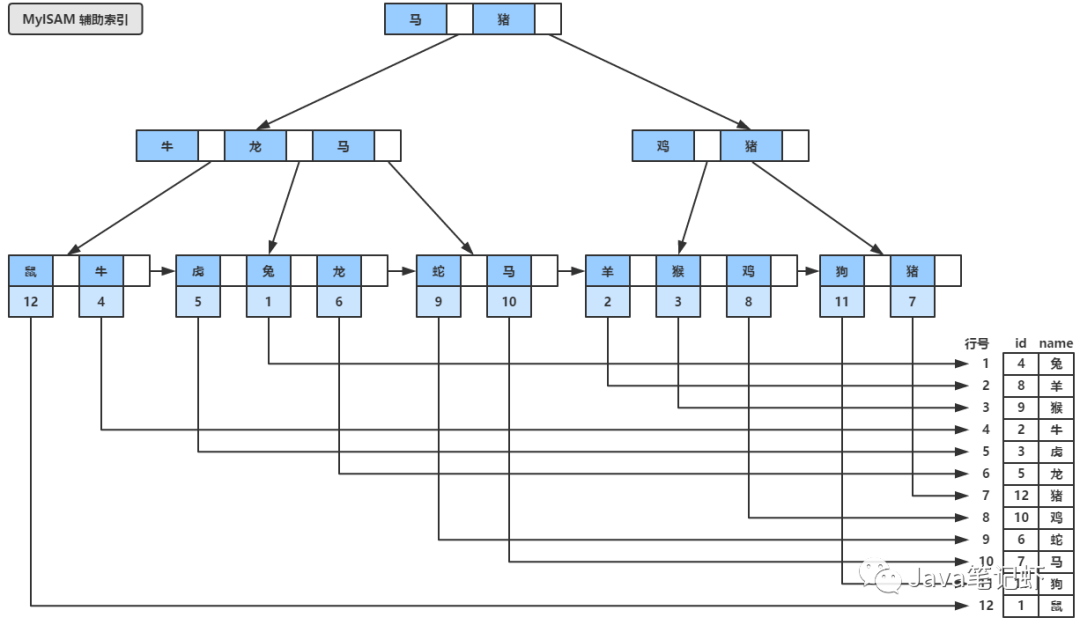
區(qū)別
1、innodb支持事務(wù),且默認(rèn)是Autocommit,所以每一條SQL語(yǔ)句都會(huì)封裝成一個(gè)事務(wù),如果執(zhí)行多條事務(wù),最好加上begin和commit。MyIsam不支持事務(wù),也就無(wú)法回滾;
2、另外Innodb支持行鎖,MyIsam進(jìn)行寫操作會(huì)全表上鎖,所以MyIsam的寫操作性能會(huì)差些;
3、所以,在查詢較多的表中,使用MyIsam較優(yōu),寫比較多的表,使用Innodb;
拓展--復(fù)合索引
我們都知道我們可以對(duì)一個(gè)列創(chuàng)建一個(gè)索引,但是什么是復(fù)合索引呢?
創(chuàng)建:
create table test(
a int,
b int,
c int,
KEY a(a,b,c)
);
通過(guò)以上代碼我們就可以創(chuàng)建一個(gè)a、b、c三個(gè)字段的復(fù)合索引了,相對(duì)于維護(hù)三個(gè)索引,維護(hù)一個(gè)復(fù)合索引的開(kāi)銷肯定是更低的。
但是復(fù)合索引需要滿足一個(gè)最左匹配原則,也就是他會(huì)依次查找a、b、c三個(gè)字段,當(dāng)左邊的字段未作為判斷條件時(shí),就不會(huì)再去執(zhí)行接下來(lái)的索引了,測(cè)試如下:
EXPLAIN DELETE from test
where a=1 and c= 3 and b =2

EXPLAIN DELETE from test
where a=1 and c= 3

推薦閱讀
國(guó)產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(wàn)(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂(lè)于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!