
Flink 在伴魚的實踐:如何保障數(shù)據(jù)的準確性
隨著伴魚業(yè)務(wù)的快速發(fā)展,離線數(shù)據(jù)日漸無法滿足運營同學的需求,數(shù)據(jù)的實時性要求越來越高。之前的實時任務(wù)是通過實時同步至 TiDB 的數(shù)據(jù),利用 TiDB 進行微批計算。隨著越來越多的實時場景涌現(xiàn)出來,TiDB 已經(jīng)無法滿足實時數(shù)據(jù)計算場景,計算和查詢都在一套集群中,導致集群壓力過大,可能影響正常的業(yè)務(wù)使用。根據(jù)業(yè)務(wù)形態(tài)搭建實時數(shù)倉已經(jīng)是必要的建設(shè)了。伴魚實時數(shù)倉主要以 Flink 為計算引擎,搭配 Redis ,Kafka 等分布式數(shù)據(jù)存儲介質(zhì),以及 ClickHouse 等多維分析引擎。
基于平臺提供了穩(wěn)定的環(huán)境 (統(tǒng)一調(diào)度方式,統(tǒng)一管理,統(tǒng)一監(jiān)控等)。我們構(gòu)建了一些實時服務(wù),通過服務(wù)化的方式去支持各個業(yè)務(wù)方。
實時數(shù)倉:數(shù)據(jù)同步,業(yè)務(wù)數(shù)據(jù)清洗去重,相關(guān)主題業(yè)務(wù)數(shù)據(jù)關(guān)聯(lián)拼接,以及數(shù)據(jù)聚合提煉等,逐步構(gòu)建多維度,多覆蓋面的實時數(shù)倉體系。
實時特征平臺:實時數(shù)據(jù)提取,計算,以及特征回寫。
簡單介紹下:目前數(shù)據(jù)在伴魚內(nèi)的流動架構(gòu)圖:
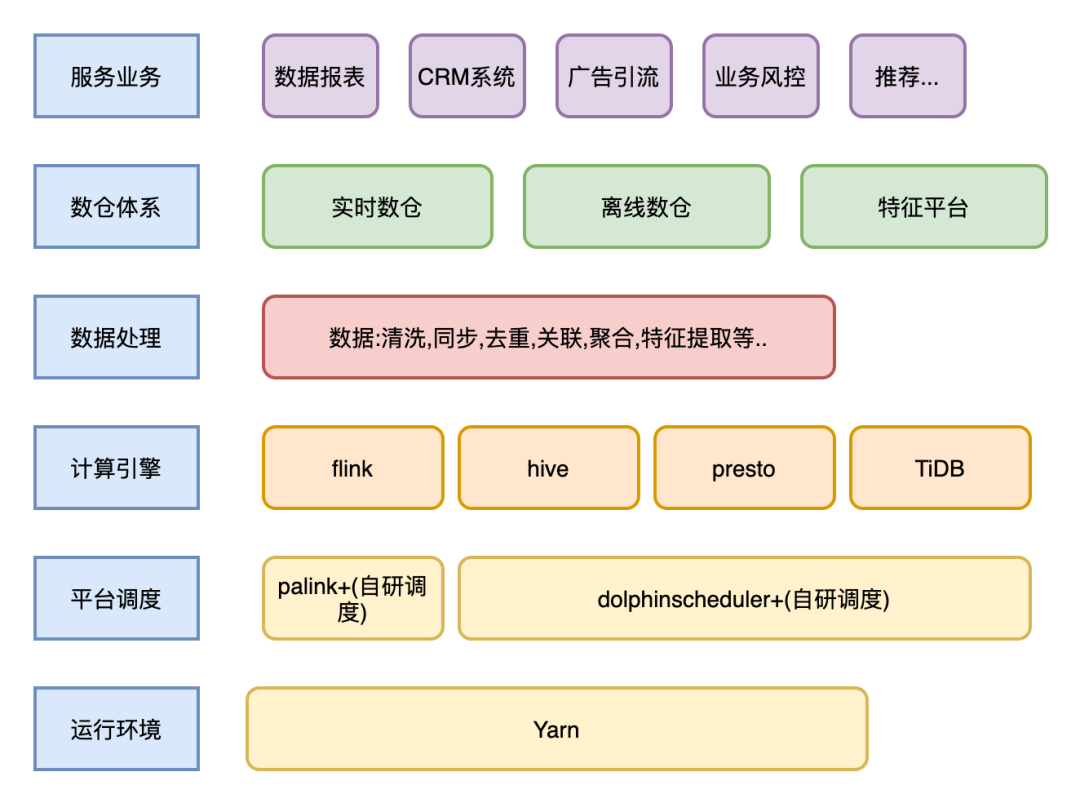
下面主要介紹伴魚實時數(shù)倉的建設(shè)體系:
ODS 層數(shù)據(jù)平臺統(tǒng)一進行數(shù)據(jù)解析處理, 寫入 Kafka 。
DWD 比較關(guān)鍵,會將來自同一業(yè)務(wù)域數(shù)據(jù)表對應(yīng)的多條數(shù)據(jù)流,按最細粒度關(guān)聯(lián)成一條完整的日志,并關(guān)聯(lián)相應(yīng)維度,描述一個完整事實。
DWS 將每個小業(yè)務(wù)域數(shù)據(jù)按相同維度進行聚合,寫入 TiDB 和 ClickHouse 。在 TiDB ,ClickHouse ,再次進行關(guān)聯(lián),形成跨業(yè)務(wù)域聚合數(shù)據(jù)。供業(yè)務(wù)和分析人員使用。
如圖:
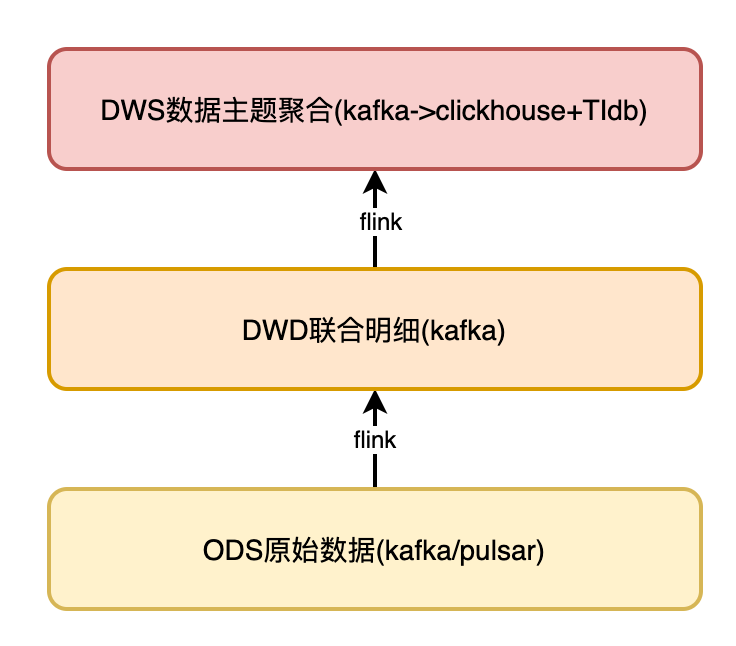
數(shù)據(jù)從 ODS 層采集后,數(shù)據(jù)的處理和加工主要集中在 DWD 層,我們的場景中面臨了很多復雜的加工邏輯,本章重點對 DWD 層數(shù)據(jù)處理方案進行詳細的闡述。
由于伴魚內(nèi)部業(yè)務(wù)大面積使用 MongoDB ,MongoDB 本身存儲的是半結(jié)構(gòu)化的數(shù)據(jù),它不具有固定的 schema 。在同步 Mongo 的 oplog 時,實時數(shù)倉的 dwd 層并不需要所有字段參與,我們只會抽取日常使用率相對較高的字段進行表建設(shè)。這就可能由于不相干的數(shù)據(jù)發(fā)生變化,我們也會收到一條相同的數(shù)據(jù)記錄。例如在對用戶訂單金額進行分類分析時,如果用戶訂單地址發(fā)生了變化,我們同樣也會收到一條業(yè)務(wù)日志,因為我們并不關(guān)注地址維度,所以這條日志是無用的重復數(shù)據(jù)。這種未經(jīng)處理的數(shù)據(jù)是不方便 BI 工程師直接使用的,甚至直接影響計算結(jié)果的準確性。所以我們針對這種非 Append-only 數(shù)據(jù),我們進行了定制化的日志格式。在經(jīng)由平臺方解析后的 binlog 或者 oplog ,我們?nèi)匀欢ㄖ苹尤肓艘恍┰獢?shù)據(jù)信息,用來讓 BI 工程師更好的理解這條數(shù)據(jù)進入實時計算引擎時,對應(yīng)的時間點到底發(fā)生了什么事情,這件實事到底是否參與計算。所以,我們加入了 metadata_table (原始表名), metadata_changes(修改字段名) , metadata_op_type (DML 類型) ,metadata_commit_ts (修改時間戳) 等字段,輔助我們對業(yè)務(wù)上認為的重復數(shù)據(jù),做更好的過濾。
如圖:

實時計算相較于離線不同,因為數(shù)據(jù)具有一過性,流過的數(shù)據(jù),如果不做特殊記錄,很難在找回,從而降低了實時作業(yè)準確性,這是實時計算的一個痛點問題,這個問題主要表現(xiàn)在多流關(guān)聯(lián)時,數(shù)據(jù)難以關(guān)聯(lián)準確,下面敘述一下在伴魚內(nèi)部,多流 join 的場景是如何解決的。數(shù)據(jù)關(guān)聯(lián)常用的 inner join ,left join 。inner join 近似可以看做 left join + where 的操作。
從時間角度來講分為:
兩條實時數(shù)據(jù)流相關(guān)聯(lián)。
實時流與過去發(fā)生的事實數(shù)據(jù)相關(guān)聯(lián)。
利用 Redis 基于內(nèi)存,支持單位時間大量 QPS ,快速訪問的特性:
首先我們應(yīng)觀察一定范圍內(nèi)數(shù)據(jù),觀察數(shù)據(jù)在時間維度上的亂序情況. 設(shè)定數(shù)據(jù)延遲的時間和數(shù)據(jù)緩存時間。
伴魚的服務(wù)都相對較穩(wěn)定,數(shù)據(jù)亂序最多就是秒級差異,我們通常選擇數(shù)據(jù)量相對大的流做主流,對主數(shù)據(jù)流加窗口等待 (窗口時間不必太長,如 10s), 右邊數(shù)據(jù)流將數(shù)據(jù)寫入 Redis 緩存 (分鐘級),當主流的窗口到期,確保右邊流數(shù)據(jù)以及緩存在 Redis 中了。實現(xiàn)在 Flink job 內(nèi)部多 Operator 之間的內(nèi)存共享。這種方式的優(yōu)點是:足夠簡單,通用 ; Flink job 無需維護業(yè)務(wù)狀態(tài),job 輕量化、運行穩(wěn)定。缺點是,隨著數(shù)據(jù)量的上升,以及 job 的增多,會對 Redis 集群造成較大壓力。
如圖:
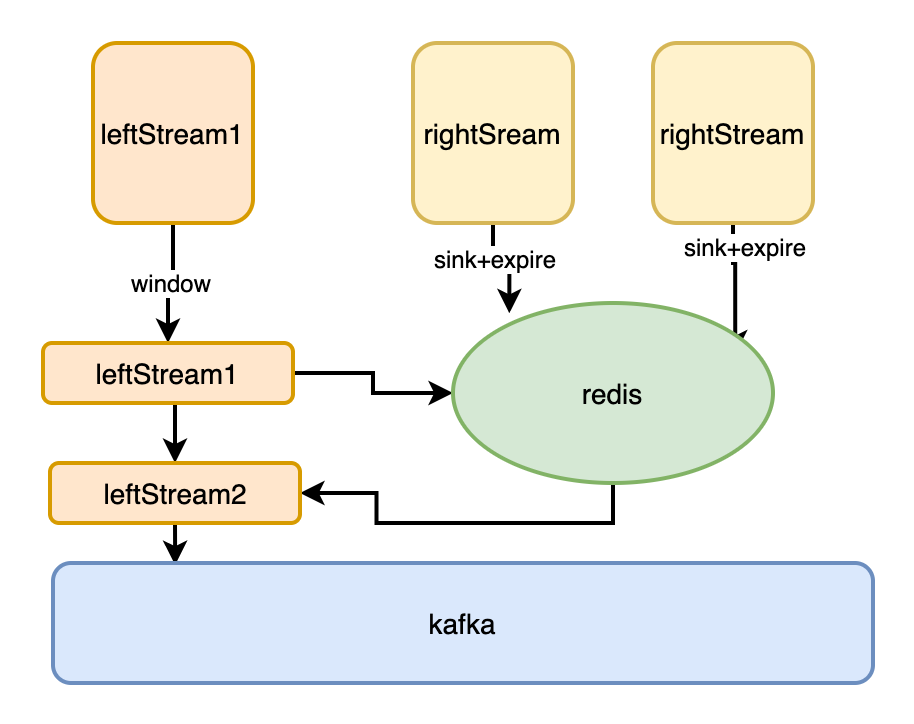
Flink 作業(yè)內(nèi)部,提供了完整的 user-state 狀態(tài)管理,包括狀態(tài)初始化,狀態(tài)更新,狀態(tài)快照,以及狀態(tài)恢復等:
將數(shù)據(jù) leftStream 與 rightStream 分別打上不同的 tag ,將 leftStream 與 rightStream 用 contect 算子聯(lián)合在一起。對 join 的條件進行 group by 操作,相同分組的數(shù)據(jù),在 precess 算子內(nèi)進行數(shù)據(jù)的 state 緩存與輸出。下游得到的即為能關(guān)聯(lián)上的數(shù)據(jù)。
對狀態(tài)操作的同時,調(diào)用定時器,比如我們可以按天為單位,每天凌晨設(shè)置定時器,清空狀態(tài),具體定時器觸發(fā)策略,看業(yè)務(wù)場景。
優(yōu)點: 整個作業(yè)所有處理邏輯不依賴其他外部存儲系統(tǒng),均在 Flink 內(nèi)部計算。
缺點: 如果多個數(shù)據(jù)流關(guān)聯(lián),整體作業(yè) code 量較大,開發(fā)成本相對較高;數(shù)據(jù)交由 Flink 狀態(tài)維護,整個作業(yè)內(nèi)存負載較高,數(shù)據(jù)量大的情況下,checkpoint 很大,對作業(yè)整體穩(wěn)定運行有影響。
Flink 社區(qū)已經(jīng)認識到多流 join 的痛點問題,提供了區(qū)別于離線 sql 的特殊 join 方式:
對 leftStream 與 rightStream 分別注冊 Watermark (最好用事件時間)。
將 leftStream 與 rightStream 進行 Interval Join。(在流與流的 join 中, window join 只能關(guān)聯(lián)兩個流中對應(yīng)的 window 中的消息,跨窗口的消息關(guān)聯(lián)不上,所以摒棄。Interval Join 則沒有 window 的概念,直接用時間戳作為關(guān)聯(lián)的條件,更具表達力。Interval join 的實現(xiàn)基本邏輯比較簡單,主要依靠 TimeBoundedStreamJoin 完成消息的關(guān)聯(lián),其核心邏輯主要包含消息的緩存,不同關(guān)聯(lián)類型的處理,消息的清理,但實現(xiàn)起來并不簡單。一條流中的消息,可能需要和另一條流的多條消息關(guān)聯(lián),因此流流關(guān)聯(lián)時,通常需要類似如下關(guān)聯(lián)條件:)。
優(yōu)點: 編碼簡單;整個作業(yè) state 的修改訪問由 Flink 源碼自動完成,整體 state 負載與用戶手動編碼相對較小。
缺點: 特殊 join 方式受場景限制較大。
如圖:

Flink Table & SQL 時態(tài)表 Temporal Table:
在 Flink 中,從 1.7 開始,提出了時態(tài)表 (即 Temporal Table ) 的概念。Temporal Table 可以簡化和加速此類查詢,并減少對狀態(tài)的使用 Temporal Table 是將一個 Append-Only 表中追加的行,根據(jù)設(shè)置的主鍵和時間 (如上 productID 、updatedAt ),解釋成 Chanlog,并在特定時間提供數(shù)據(jù)的版本。
在使用時態(tài)表 ( Temporal Table ) 時,要注意以下問題。
Temporal Table 可提供歷史某個時間點上的數(shù)據(jù)。Temporal Table 根據(jù)時間來跟蹤版本。Temporal Table 需要提供時間屬性和主鍵。Temporal Table 一般和關(guān)鍵詞 LATERAL TABLE 結(jié)合使用。Temporal Table 在基于 ProcessingTime 時間屬性處理時,每個主鍵只保存最新版本的數(shù)據(jù)。Temporal Table 在基于 EventTime 時間屬性處理時,每個主鍵保存從上個 Watermark 到當前系統(tǒng)時間的所有版本。表 Join 右側(cè) Temporal Table ,本質(zhì)上還是左表驅(qū)動 Join ,即從左表拿到 Key ,根據(jù) Key 和時間 (可能是歷史時間) 去右側(cè) Temporal Table 表中查詢。Temporal Table Join 目前只支持 Inner Join。Temporal Table Join 時,右側(cè) Temporal Table 表返回最新一個版本的數(shù)據(jù)。
例如:
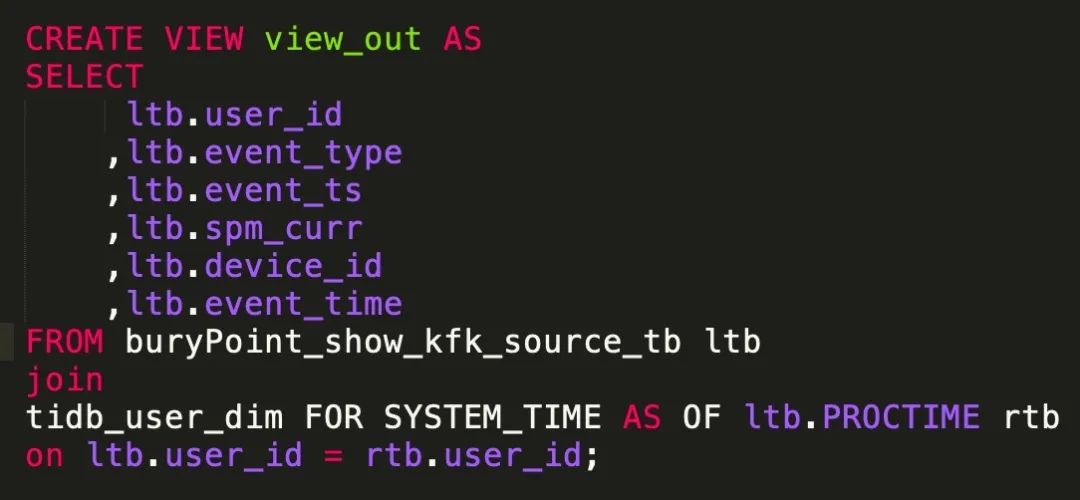
我們首先要分析歷史數(shù)據(jù)的過期性,例如伴魚業(yè)務(wù)場景中,用戶約課行為和用戶在線上課兩條數(shù)據(jù)流關(guān)聯(lián)到的數(shù)據(jù),可能相差幾天 (用戶提前約下周的課程)。此時數(shù)據(jù)的過期時間就需要我們特殊關(guān)系與處理,我們可以精確的計算先發(fā)生的事件,它的準確過期時間,例如:例如正式上課時間為三天后,所以,我們可將他們放入 Redis 中緩存 (3+1)*24 h, 以確保用戶上課時,他們的約課記錄還仍然在我們內(nèi)存中預熱。 如果無法判斷出歷史數(shù)據(jù)的過期性。例如在伴魚的業(yè)務(wù)場景中,經(jīng)常會關(guān)聯(lián)用戶某個重要行為 (下單) 時,對用的用戶等級,以及綁定的教師等細節(jié)信息,類似這種常用且重要的維度,我們只能將它們永久緩存在 Redis 中,供事實數(shù)據(jù)去訪問關(guān)聯(lián)。
從數(shù)據(jù) join 的方式來看,共分為三種,一對一,多對一, 多對多三種情形。
對于一對一,多對一,我們只需要用 Redis 或者 state 緩存住單一一方的數(shù)據(jù)流。 對于多對多的 join 情形:多對多的 join。我們只能將 leftStream 與 rightStream 先 connect 連接起來,天級別的 將數(shù)據(jù)分別緩存至 Redis 或者 job momery 中。無論 left Steam 還是 right Stream,數(shù)據(jù)來了都是統(tǒng)一先緩存,去遍歷另一方的所有已經(jīng)到來的數(shù)據(jù),輸出到下游。 對于多對多的 left join 情形:多對多的 left join 的場景,是比較復雜的,我們也只能將 leftStream 與 rightStream 先 connect 連接起來,將其緩存在 job momery 或者 Redis 中,leftSteam 或者 rightStream 數(shù)據(jù)來了就先統(tǒng)一先緩存,再去遍歷另一方的所有已經(jīng)到來的數(shù)據(jù),輸出到下游。只不過此時,對于下游沒有 join 上的數(shù)據(jù),并不能很好的判斷 數(shù)據(jù)到底是真的沒有 join 上,還是因為數(shù)據(jù)進入 Operator 的時間性的差異,沒有 join 上。此時我們會將數(shù)據(jù)寫入 TiDB ,或者 ClickHouse 中,在這種可以基于天級別數(shù)據(jù)量快速計算的 OLAP 引擎中,對因進入 Operator 算子時間差異而導致沒有 join 上的數(shù)據(jù)進行過濾。 注意如果用 Flink Operator State,需要設(shè)置定時器,或者使用 Flink TTL,對 state 定時清理,不然程序會 OOM 。如果使用 Redis ,需要對數(shù)據(jù)設(shè)置失效或者定時調(diào)用離線腳本對數(shù)據(jù)進行刪除。
我們在離線數(shù)倉中通常存放的是跨業(yè)務(wù)域的粗粒度數(shù)。在伴魚的實時數(shù)倉內(nèi)部,我們也同樣是這樣存儲的。只不過跨業(yè)務(wù)域的數(shù)據(jù)之間的關(guān)聯(lián),我們不在 Flink 實時處理引擎中做計算。而是把它們放到 TiDB 或者 ClickHouse 中做計算了。在 Flink 內(nèi)存,我們只計算當前業(yè)務(wù)域的聚合指標,以及會對數(shù)據(jù)進行 tag 標記,標記出數(shù)據(jù)是按哪些維度聚合而來,聚合粒度是如何的。(例如時間粒度上,我們通常會以 5min 或者 10min 為小單位對數(shù)據(jù)進行聚合),如果要查詢當天跨業(yè)務(wù)的聯(lián)合數(shù)據(jù)時,會基于 TiDB 或者 ClickHouse 預先定義好視圖,在視圖內(nèi)先對當天單個業(yè)務(wù)域主題內(nèi)數(shù)據(jù)先做聚合 sum ,再將不同業(yè)務(wù)域的數(shù),按提前在數(shù)據(jù)中標記的維度 tag 進行關(guān)聯(lián),得到跨業(yè)務(wù)的聚合指標。
未來我們?nèi)詴^續(xù)對比 Storm, Spark Streaming, Flink 等多種技術(shù)棧產(chǎn)品在使用和性能上的利弊。期待 Flink 生態(tài)的豐富,我們會嘗試讓 Flink CDC,F(xiàn)link ML,F(xiàn)link CEP 等一些特性發(fā)揮在我們的數(shù)倉建設(shè)中。 Flink SQL 最近幾個版本的迭代也是相當頻繁的。由于阿里對 Flink planner 的支持,使 Flink 的批流一體的概念更加趨近于現(xiàn)實,我們會嘗試使用 Flink 作為離線數(shù)倉的處理引擎,在公司數(shù)據(jù)組推開 Flink SQL 。 繼續(xù)完善實時平臺對 Flink 任務(wù)的監(jiān)控,以及資源管理的優(yōu)化。
作者:李震
原文:https://tech.ipalfish.com/blog/2021/06/29/flink_practice/
原文:Flink 在伴魚的實踐:如何保障數(shù)據(jù)的準確性
來源:伴魚技術(shù)博客
轉(zhuǎn)載:著作權(quán)歸作者所有。商業(yè)轉(zhuǎn)載請聯(lián)系作者獲得授權(quán),非商業(yè)轉(zhuǎn)載請注明出處。