
一文學(xué)會(huì)常用 MySQL 分庫(kù)分表方案

閱讀本文大概需要 4.7 分鐘。
來自:https://www.cnblogs.com/littlecharacter/p/9342129.html
一、數(shù)據(jù)庫(kù)瓶頸
1、IO瓶頸
2、CPU瓶頸
二、分庫(kù)分表
1、水平分庫(kù)
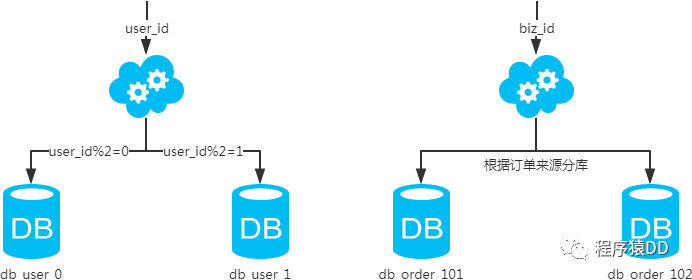
概念:以字段為依據(jù),按照一定策略(hash、range等),將一個(gè)庫(kù)中的數(shù)據(jù)拆分到多個(gè)庫(kù)中。 結(jié)果: 每個(gè)庫(kù)的結(jié)構(gòu)都一樣; 每個(gè)庫(kù)的數(shù)據(jù)都不一樣,沒有交集; 所有庫(kù)的并集是全量數(shù)據(jù); 場(chǎng)景:系統(tǒng)絕對(duì)并發(fā)量上來了,分表難以根本上解決問題,并且還沒有明顯的業(yè)務(wù)歸屬來垂直分庫(kù)。 分析:庫(kù)多了,io和cpu的壓力自然可以成倍緩解。
2、水平分表
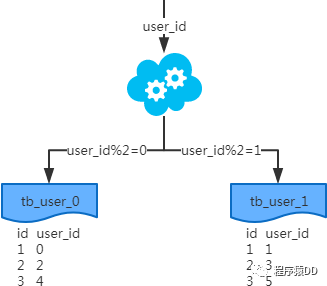
概念:以字段為依據(jù),按照一定策略(hash、range等),將一個(gè)表中的數(shù)據(jù)拆分到多個(gè)表中。 結(jié)果: 每個(gè)表的結(jié)構(gòu)都一樣; 每個(gè)表的數(shù)據(jù)都不一樣,沒有交集; 所有表的并集是全量數(shù)據(jù); 場(chǎng)景:系統(tǒng)絕對(duì)并發(fā)量并沒有上來,只是單表的數(shù)據(jù)量太多,影響了SQL效率,加重了CPU負(fù)擔(dān),以至于成為瓶頸。 分析:表的數(shù)據(jù)量少了,單次SQL執(zhí)行效率高,自然減輕了CPU的負(fù)擔(dān)。
3、垂直分庫(kù)
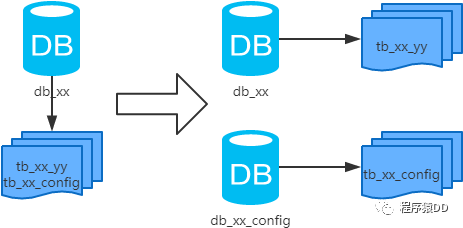
概念:以表為依據(jù),按照業(yè)務(wù)歸屬不同,將不同的表拆分到不同的庫(kù)中。 結(jié)果: 每個(gè)庫(kù)的結(jié)構(gòu)都不一樣; 每個(gè)庫(kù)的數(shù)據(jù)也不一樣,沒有交集; 所有庫(kù)的并集是全量數(shù)據(jù); 場(chǎng)景:系統(tǒng)絕對(duì)并發(fā)量上來了,并且可以抽象出單獨(dú)的業(yè)務(wù)模塊。 分析:到這一步,基本上就可以服務(wù)化了。例如,隨著業(yè)務(wù)的發(fā)展一些公用的配置表、字典表等越來越多,這時(shí)可以將這些表拆到單獨(dú)的庫(kù)中,甚至可以服務(wù)化。再有,隨著業(yè)務(wù)的發(fā)展孵化出了一套業(yè)務(wù)模式,這時(shí)可以將相關(guān)的表拆到單獨(dú)的庫(kù)中,甚至可以服務(wù)化。
4、垂直分表
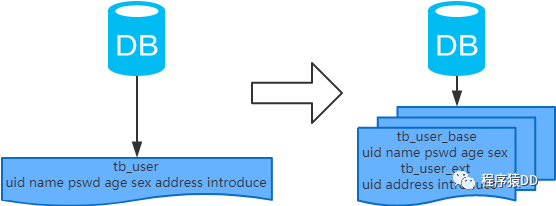
概念:以字段為依據(jù),按照字段的活躍性,將表中字段拆到不同的表(主表和擴(kuò)展表)中。 結(jié)果: 每個(gè)表的結(jié)構(gòu)都不一樣; 每個(gè)表的數(shù)據(jù)也不一樣,一般來說,每個(gè)表的字段至少有一列交集,一般是主鍵,用于關(guān)聯(lián)數(shù)據(jù); 所有表的并集是全量數(shù)據(jù); 場(chǎng)景:系統(tǒng)絕對(duì)并發(fā)量并沒有上來,表的記錄并不多,但是字段多,并且熱點(diǎn)數(shù)據(jù)和非熱點(diǎn)數(shù)據(jù)在一起,單行數(shù)據(jù)所需的存儲(chǔ)空間較大。以至于數(shù)據(jù)庫(kù)緩存的數(shù)據(jù)行減少,查詢時(shí)會(huì)去讀磁盤數(shù)據(jù)產(chǎn)生大量的隨機(jī)讀IO,產(chǎn)生IO瓶頸。 分析:可以用列表頁(yè)和詳情頁(yè)來幫助理解。垂直分表的拆分原則是將熱點(diǎn)數(shù)據(jù)(可能會(huì)冗余經(jīng)常一起查詢的數(shù)據(jù))放在一起作為主表,非熱點(diǎn)數(shù)據(jù)放在一起作為擴(kuò)展表。這樣更多的熱點(diǎn)數(shù)據(jù)就能被緩存下來,進(jìn)而減少了隨機(jī)讀IO。拆了之后,要想獲得全部數(shù)據(jù)就需要關(guān)聯(lián)兩個(gè)表來取數(shù)據(jù)。但記住,千萬別用join,因?yàn)閖oin不僅會(huì)增加CPU負(fù)擔(dān)并且會(huì)講兩個(gè)表耦合在一起(必須在一個(gè)數(shù)據(jù)庫(kù)實(shí)例上)。關(guān)聯(lián)數(shù)據(jù),應(yīng)該在業(yè)務(wù)Service層做文章,分別獲取主表和擴(kuò)展表數(shù)據(jù)然后用關(guān)聯(lián)字段關(guān)聯(lián)得到全部數(shù)據(jù)。
三、分庫(kù)分表工具
sharding-sphere:jar,前身是sharding-jdbc; TDDL:jar,Taobao Distribute Data Layer; Mycat:中間件。
四、分庫(kù)分表步驟
五、分庫(kù)分表問題
1、非partition key的查詢問題
端上除了partition key只有一個(gè)非partition key作為條件查詢
映射法
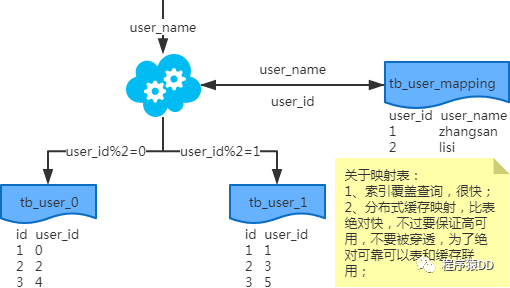
基因法

端上除了partition key不止一個(gè)非partition key作為條件查詢
映射法
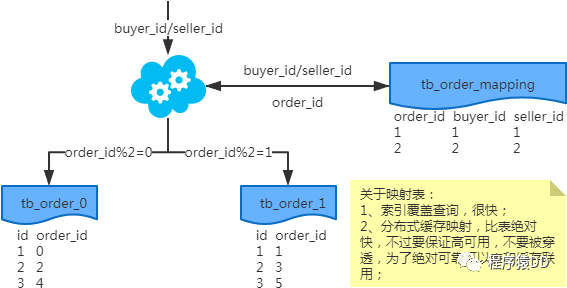
冗余法
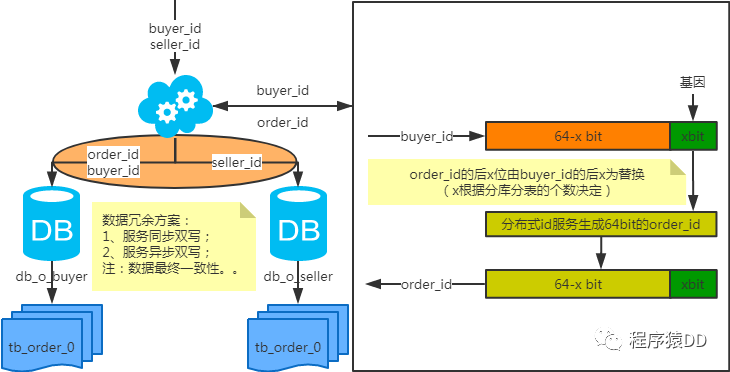
后臺(tái)除了partition key還有各種非partition key組合條件查詢
NoSQL法 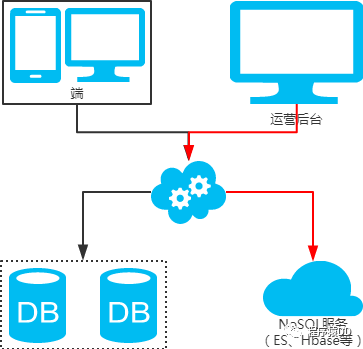
冗余法 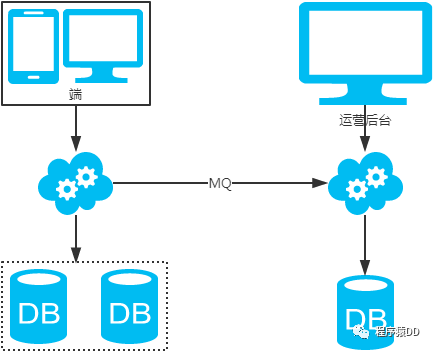
注:按照order_id或buyer_id查詢時(shí)路由到db_o_buyer庫(kù)中,按照seller_id查詢時(shí)路由到db_o_seller庫(kù)中。感覺有點(diǎn)本末倒置!有其他好的辦法嗎?改變技術(shù)棧呢?
2、非partition key跨庫(kù)跨表分頁(yè)查詢問題
3、擴(kuò)容問題
水平擴(kuò)容庫(kù)(升級(jí)從庫(kù)法)
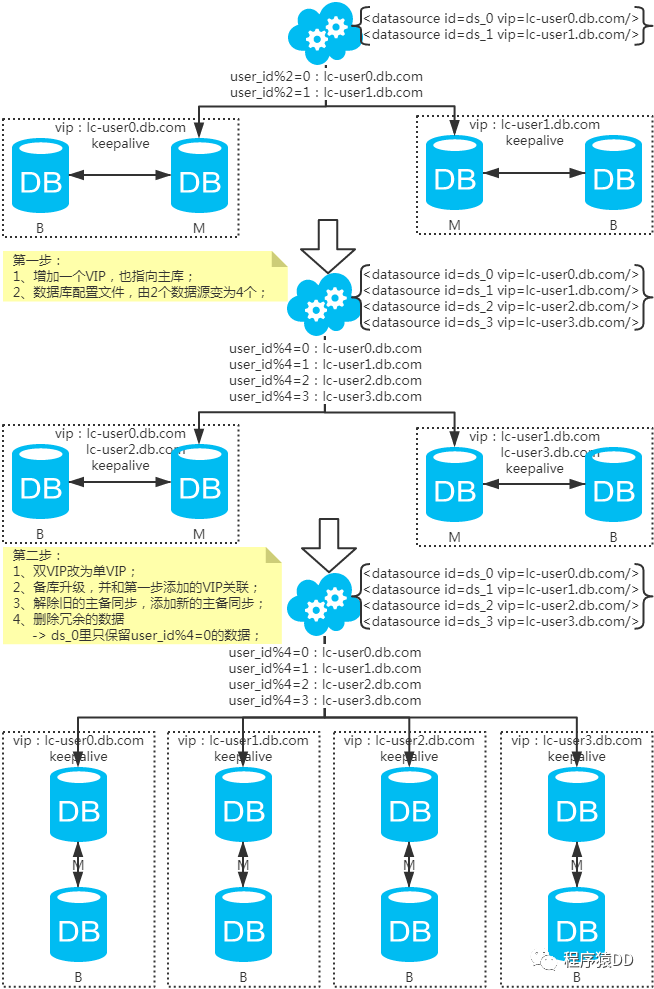
注:擴(kuò)容是成倍的。
水平擴(kuò)容表(雙寫遷移法)
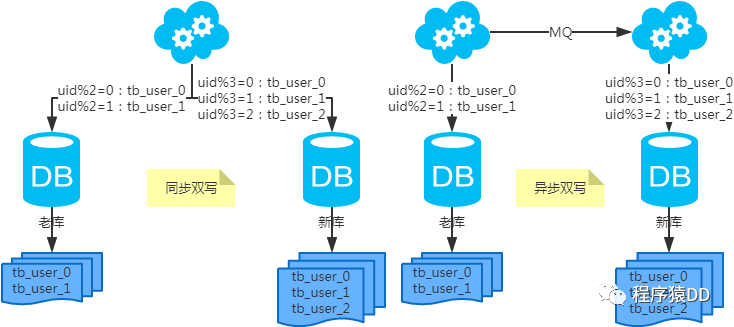 第一步:(同步雙寫)修改應(yīng)用配置和代碼,加上雙寫,部署;第二步:(同步雙寫)將老庫(kù)中的老數(shù)據(jù)復(fù)制到新庫(kù)中;第三步:(同步雙寫)以老庫(kù)為準(zhǔn)校對(duì)新庫(kù)中的老數(shù)據(jù);第四步:(同步雙寫)修改應(yīng)用配置和代碼,去掉雙寫,部署;
第一步:(同步雙寫)修改應(yīng)用配置和代碼,加上雙寫,部署;第二步:(同步雙寫)將老庫(kù)中的老數(shù)據(jù)復(fù)制到新庫(kù)中;第三步:(同步雙寫)以老庫(kù)為準(zhǔn)校對(duì)新庫(kù)中的老數(shù)據(jù);第四步:(同步雙寫)修改應(yīng)用配置和代碼,去掉雙寫,部署;
六、分庫(kù)分表總結(jié)
分庫(kù)分表,首先得知道瓶頸在哪里,然后才能合理地拆分(分庫(kù)還是分表?水平還是垂直?分幾個(gè)?)。且不可為了分庫(kù)分表而拆分。 選key很重要,既要考慮到拆分均勻,也要考慮到非partition key的查詢。 只要能滿足需求,拆分規(guī)則越簡(jiǎn)單越好。
七、分庫(kù)分表示例
推薦閱讀:
當(dāng)當(dāng)網(wǎng)的羊毛被網(wǎng)友薅慘了!9月這一次到底又被薅多少?
20個(gè)使用 Java CompletableFuture的例子
微信掃描二維碼,關(guān)注我的公眾號(hào)
朕已閱?
評(píng)論
圖片
表情