
MySQL:互聯(lián)網(wǎng)公司常用分庫分表方案匯總

本文目錄
IO瓶頸
CPU瓶頸
水平分庫
水平分表
垂直分庫
垂直分表
非partition key的查詢問題
非partition key跨庫跨表分頁查詢問題
擴容問題
一、數(shù)據(jù)庫瓶頸
1、IO瓶頸
2、CPU瓶頸
二、分庫分表
1、水平分庫
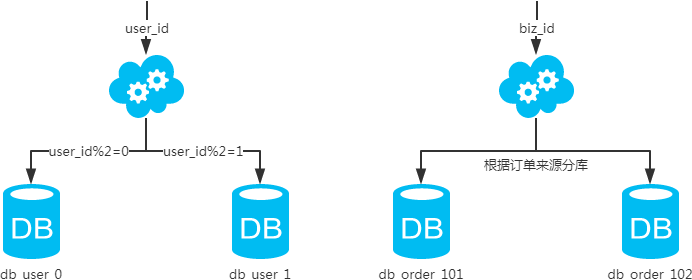
每個庫的結(jié)構都一樣;
每個庫的數(shù)據(jù)都不一樣,沒有交集;
所有庫的并集是全量數(shù)據(jù);
2、水平分表
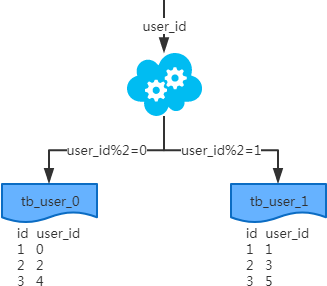
每個表的結(jié)構都一樣;
每個表的數(shù)據(jù)都不一樣,沒有交集;
所有表的并集是全量數(shù)據(jù);
3、垂直分庫
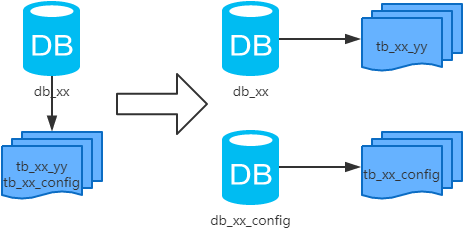
每個庫的結(jié)構都不一樣;
每個庫的數(shù)據(jù)也不一樣,沒有交集;
所有庫的并集是全量數(shù)據(jù);
4、垂直分表
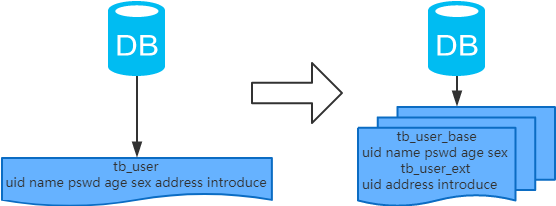
每個表的結(jié)構都不一樣;
每個表的數(shù)據(jù)也不一樣,一般來說,每個表的字段至少有一列交集,一般是主鍵,用于關聯(lián)數(shù)據(jù);
所有表的并集是全量數(shù)據(jù);
三、分庫分表工具
sharding-sphere:jar,前身是sharding-jdbc;
TDDL:jar,Taobao Distribute Data Layer;
Mycat:中間件。
注:工具的利弊,請自行調(diào)研,官網(wǎng)和社區(qū)優(yōu)先。
四、分庫分表步驟
五、分庫分表問題
1、非partition key的查詢問題
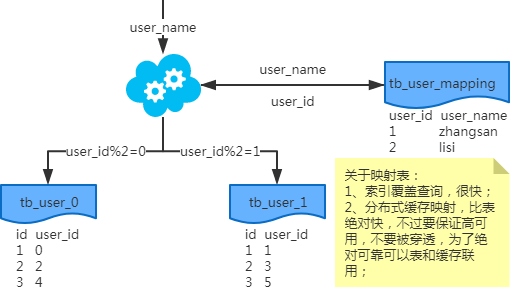
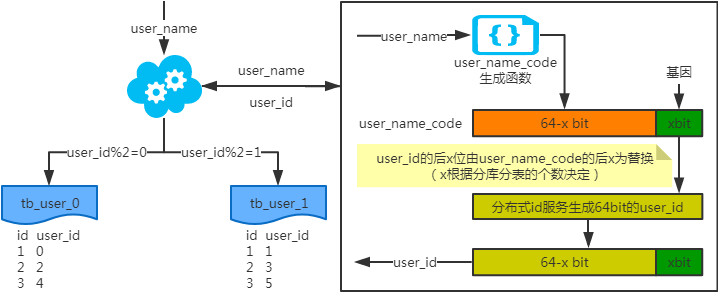
注:寫入時,基因法生成user_id,如圖。關于xbit基因,例如要分8張表,23=8,故x取3,即3bit基因。根據(jù)user_id查詢時可直接取模路由到對應的分庫或分表。 根據(jù)user_name查詢時,先通過user_name_code生成函數(shù)生成user_name_code再對其取模路由到對應的分庫或分表。id生成常用snowflake算法。
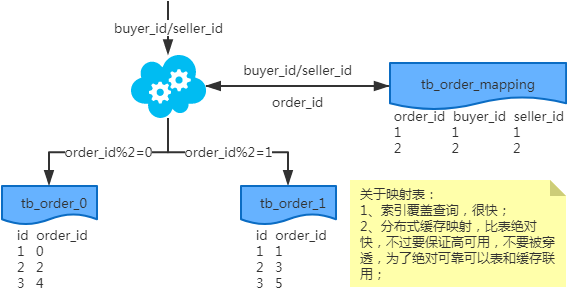
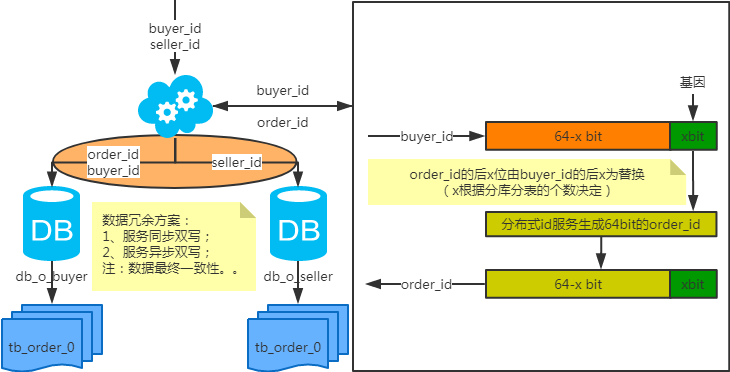
注:按照order_id或buyer_id查詢時路由到db_o_buyer庫中,按照seller_id查詢時路由到db_o_seller庫中。感覺有點本末倒置!有其他好的辦法嗎?改變技術棧呢?
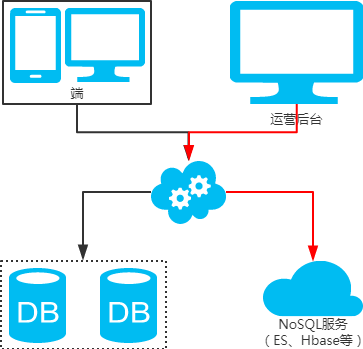
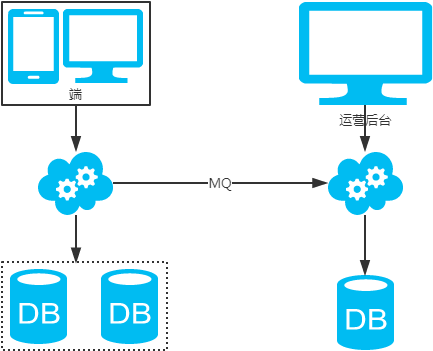
2、非partition key跨庫跨表分頁查詢問題
注:用NoSQL法解決(ES等)。
3、擴容問題
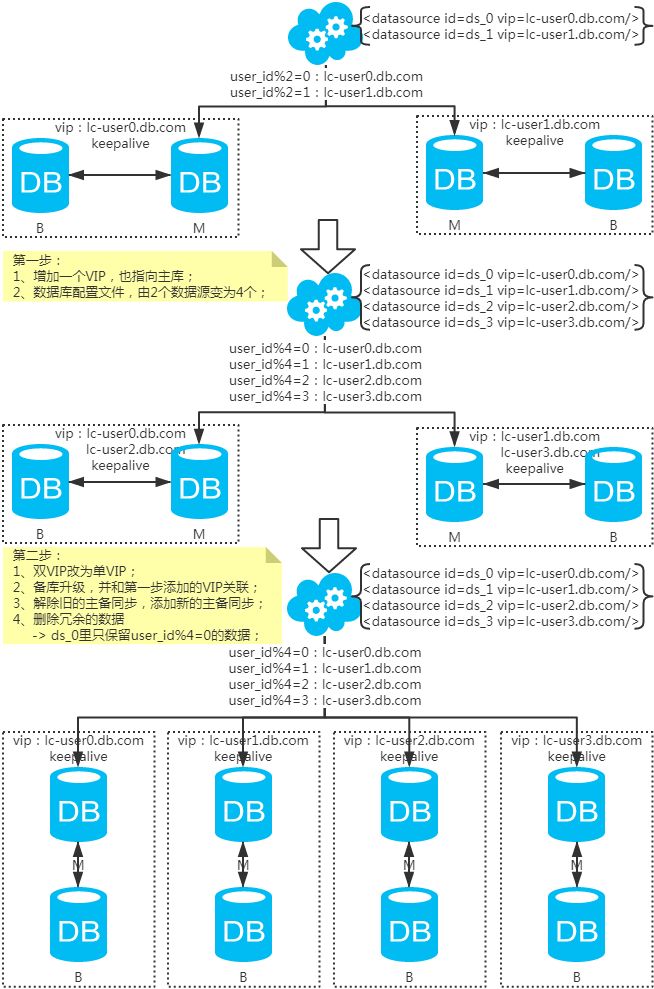
注:擴容是成倍的。
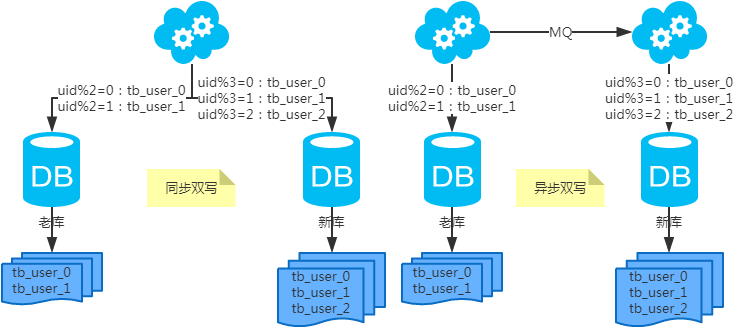
第一步:(同步雙寫)修改應用配置和代碼,加上雙寫,部署;
第二步:(同步雙寫)將老庫中的老數(shù)據(jù)復制到新庫中;
第三步:(同步雙寫)以老庫為準校對新庫中的老數(shù)據(jù);
第四步:(同步雙寫)修改應用配置和代碼,去掉雙寫,部署;
注:雙寫是通用方案。
六、分庫分表總結(jié)
分庫分表,首先得知道瓶頸在哪里,然后才能合理地拆分(分庫還是分表?水平還是垂直?分幾個?)。且不可為了分庫分表而拆分。
選key很重要,既要考慮到拆分均勻,也要考慮到非partition key的查詢。
只要能滿足需求,拆分規(guī)則越簡單越好。
七、分庫分表示例
示例GitHub地址:https://github.com/littlecharacter4s/study-sharding
---END--- 重磅!碼農(nóng)突圍-技術交流群已成立 掃碼可添加碼農(nóng)突圍助手,可申請加入碼農(nóng)突圍大群和細分方向群,細分方向已涵蓋:Java、Python、機器學習、大數(shù)據(jù)、人工智能等群。 一定要備注:開發(fā)方向+地點+學校/公司+昵稱(如Java開發(fā)+上海+拼夕夕+猴子),根據(jù)格式備注,可更快被通過且邀請進群 ▲長按加群 推薦閱讀
? ?微軟蘇州集體抵制來自阿里、華為的跳槽者:請停止你的“奮斗逼”行為!網(wǎng)友:看到 955 不加班的公司名單,我酸了 ???面試:如何決定使用 HashMap 還是 TreeMap? ???一千個不用 Null 的理由! ???干掉 "try catch " ?? 那些還在外包公司干的程序員們,快醒醒吧! ?? 面試官:為什么 HashMap 的加載因子是0.75? 最近面試BAT,整理一份面試資料《Java面試BAT通關手冊》,覆蓋了Java核心技術、JVM、Java并發(fā)、SSM、微服務、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構等等。 獲取方式:點“在看”,關注公眾號并回復?BAT?領取,更多內(nèi)容陸續(xù)奉上。 如有收獲,點個在看,誠摯感謝 明天見(??ω??)??
評論
圖片
表情