
Transformer為何能闖入CV界秒殺CNN?
轉(zhuǎn)載自 | AI科技評論
文章主要介紹Transformers背后的技術(shù)思想,Transformers在計算機視覺領(lǐng)域的應(yīng)用情況、最新動態(tài)以及該架構(gòu)相對于CNN的優(yōu)勢。
為什么Transformers模型在NLP自然語言處理任務(wù)中能夠力壓群雄,變成SOTA模型的必備組件之一。 Transformers模型的計算原理。 為什么說Transformers是對CNN的當頭棒喝,Transformers是怎么針對CNN的各種局限性進行補全的。 計算機視覺領(lǐng)域的最新模型是如何應(yīng)用Transformers提升自己的。
長期依賴和計算效率之間的權(quán)衡取舍
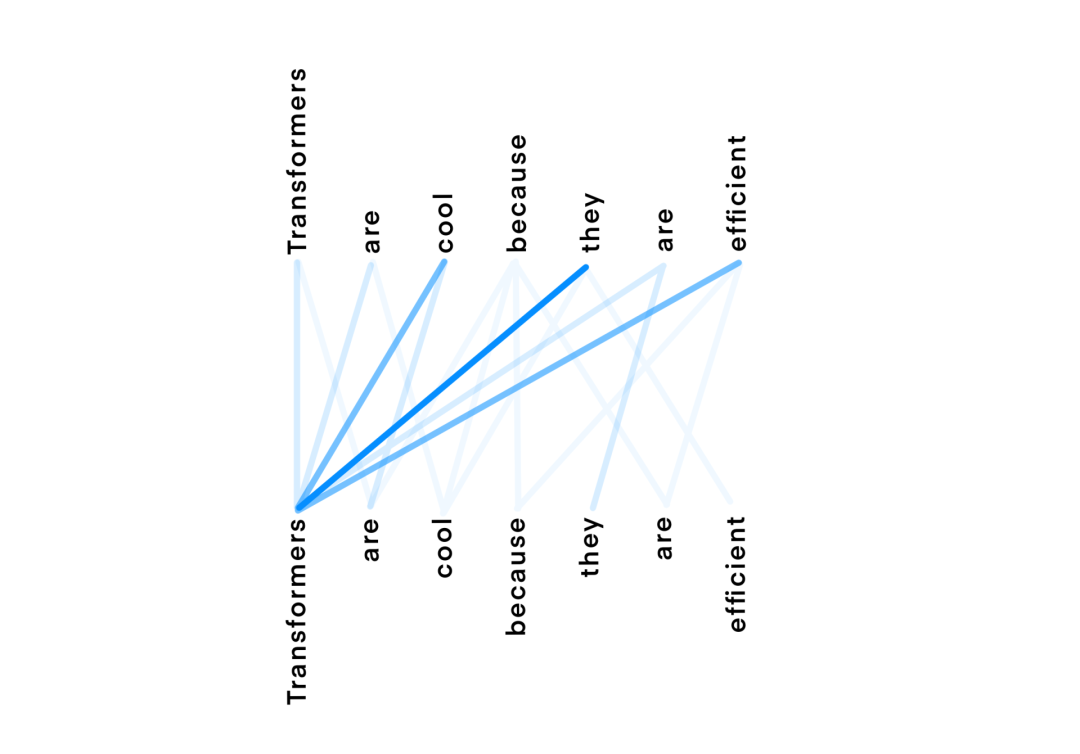
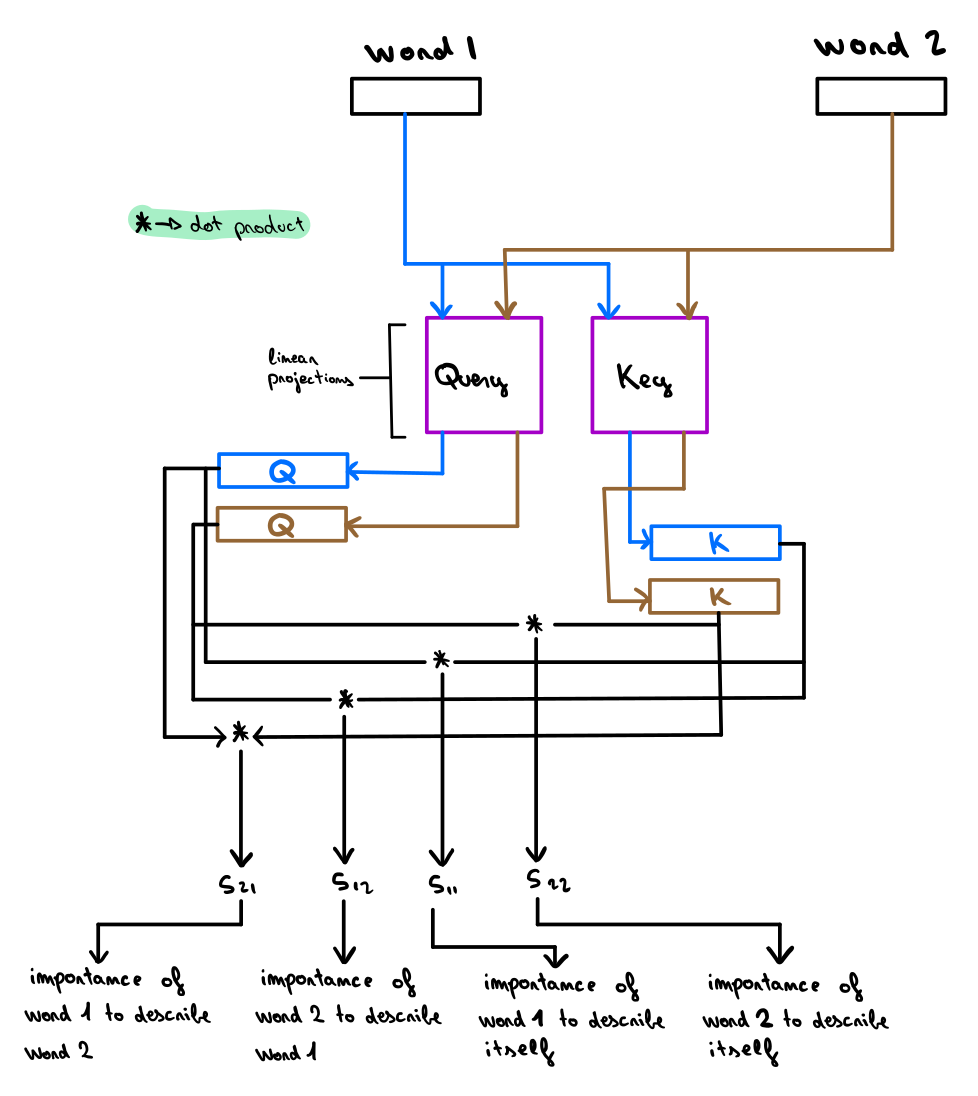
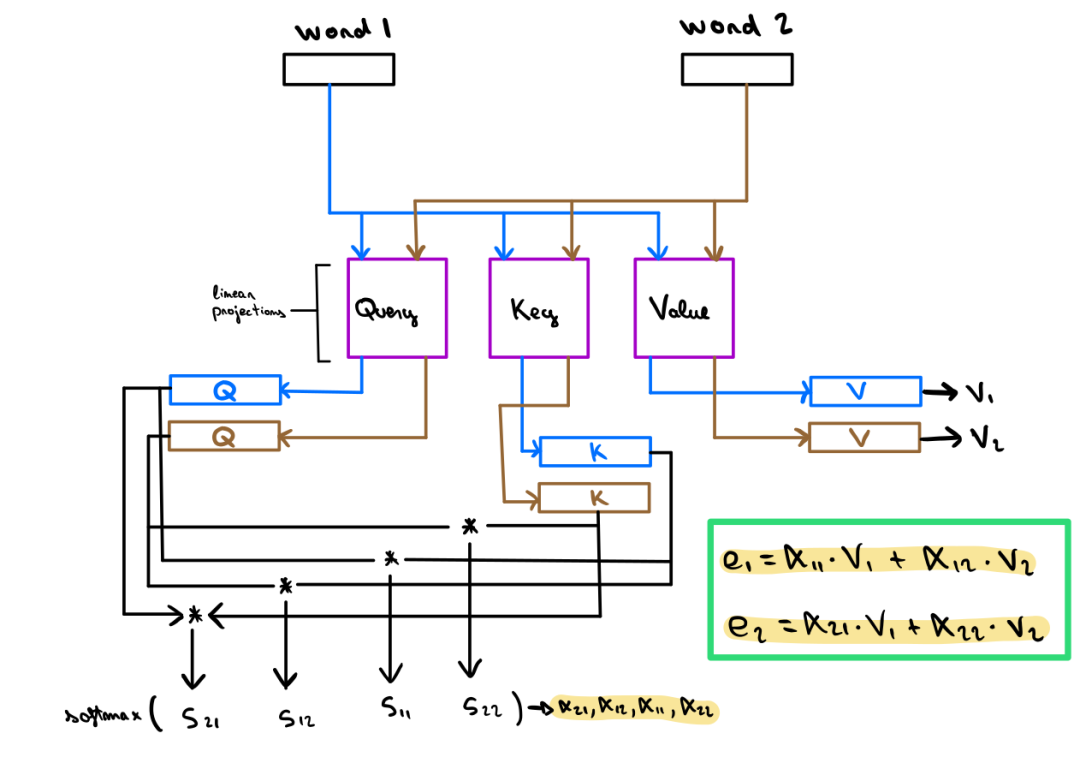
Transformers橫空出世
卷積歸納偏差
由于 CNN 權(quán)重共享機制,卷積層所提取的特征便具有平移不變性,它們對特征的全局位置不感冒,而只在乎這些決定性的特征是否存在。 由于卷積算子的性質(zhì),所以卷積的特征圖具有局部敏感性,也就是每次卷積操作只會考慮原始數(shù)據(jù)的一小部分的局部信息。
計算機視覺領(lǐng)域中的Transformers
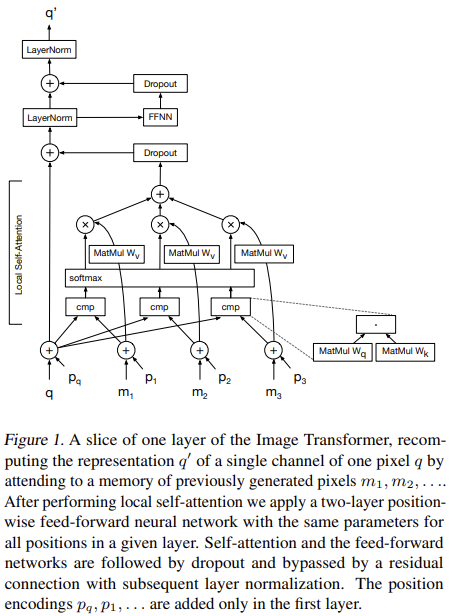
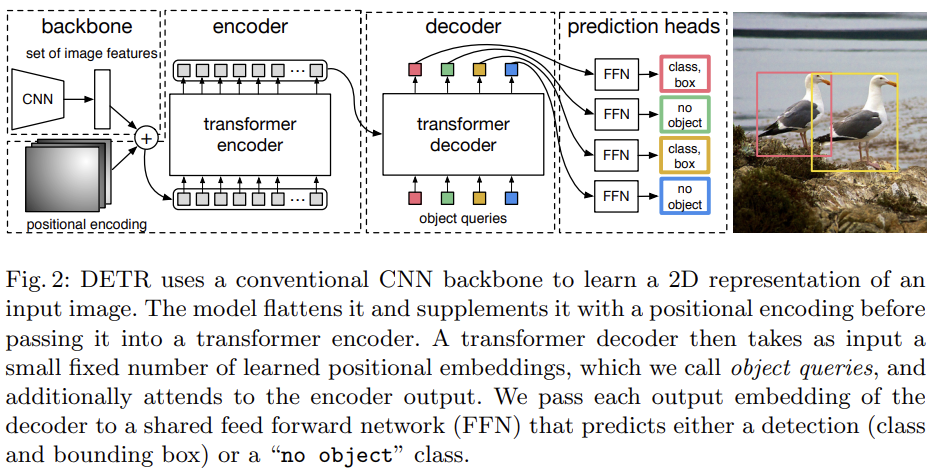
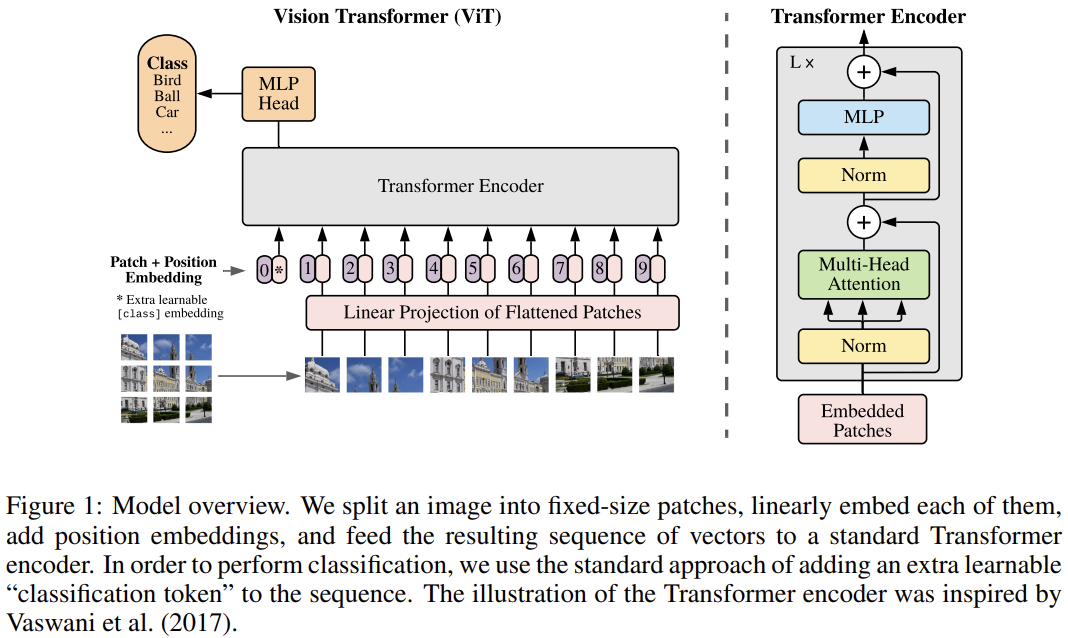
位置編碼
結(jié)論
雙一流高校研究生團隊創(chuàng)建 ↓
專注于計算機視覺原創(chuàng)并分享相關(guān)知識 ?
整理不易,點贊三連!
評論
圖片
表情