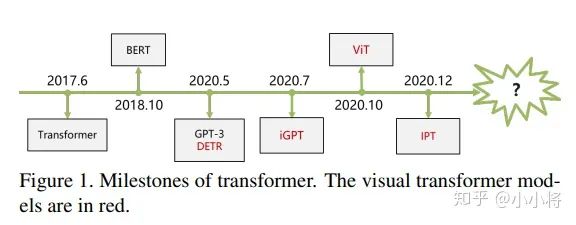
【新智元導(dǎo)讀】 Transformer有可能替換CNN嗎?本文總結(jié)了來(lái)自于知乎問(wèn)題:“如何看待Transformer在CV上的應(yīng)用前景,未來(lái)有可能替代CNN嗎?”下的3個(gè)精華回答,對(duì)Transformer在CV領(lǐng)域的未來(lái)發(fā)展提出了有價(jià)值的觀點(diǎn)。 目前已經(jīng)有基于Transformer在三大圖像問(wèn)題上的應(yīng)用:分類(lèi)(ViT),檢測(cè)(DETR)和分割(SETR),并且都取得了不錯(cuò)的效果。那么未來(lái),Transformer有可能替換CNN嗎,Transformer會(huì)不會(huì)如同在NLP領(lǐng)域的應(yīng)用一樣革新CV領(lǐng)域?后面的研究思路可能會(huì)有哪些?
湃森:要從方法提出的動(dòng)機(jī)來(lái)剖析
回答這個(gè)問(wèn)題,筆者認(rèn)為可以從方法提出的動(dòng)機(jī)來(lái)剖析比較合適,即為什么我們需要它;而不是簡(jiǎn)單的“存在即合理”,大家皆用我也用的風(fēng)向標(biāo)。 首先我們應(yīng)該了解為什么CNN會(huì)在圖像領(lǐng)域被大規(guī)模應(yīng)用,我們可以從三個(gè)主要點(diǎn)說(shuō)起, 比如基于傳統(tǒng)的方法,基于模式識(shí)別的方法,基于深度學(xué)習(xí)的方法 。
1. 傳統(tǒng)方法在視覺(jué)任務(wù)上的應(yīng)用絕大多數(shù)都依賴(lài)于在某個(gè)領(lǐng)域具有豐富經(jīng)驗(yàn)的專(zhuān)家,去針對(duì)具體的任務(wù)設(shè)計(jì)出一組最具有代表性的數(shù)據(jù)表示來(lái)作為輸入特征進(jìn)行處理,使得特征之間具備可區(qū)分性,典型的有SIFT。 其次,一些特征提取的方法也需要人為的參與,手工設(shè)計(jì)出一些特征提取算子,比如一些經(jīng)典的邊緣檢測(cè)算子,水平檢測(cè),垂直檢測(cè)等。 然而, 一方面需要依賴(lài)專(zhuān)家手動(dòng)設(shè)計(jì)特征的方式所需要的先驗(yàn)知識(shí)多,模型的的性能也極其依賴(lài)于其所設(shè)計(jì)出來(lái)的數(shù)據(jù)表示 ,這樣一來(lái)不僅費(fèi)時(shí)費(fèi)力,而且也很難針對(duì)實(shí)際場(chǎng)景中復(fù)雜多變的任務(wù)去設(shè)計(jì)出一種合適的算子,不具備泛化性。 另一方面,受制于數(shù)據(jù)采集的環(huán)境,設(shè)備等影響,比如光照,拍攝視角,遮擋,陰影,背景等等,這些因素會(huì)嚴(yán)重制約模型的性能,即手工設(shè)計(jì)的特征并不具備魯棒性。
2. 基于模式識(shí)別的方法大多數(shù)是一些與機(jī)器學(xué)習(xí)相關(guān)的技術(shù),比如隨機(jī)森林,支持向量機(jī),感知機(jī)等。 機(jī)器學(xué)習(xí)較傳統(tǒng)方法的一個(gè)顯著優(yōu)勢(shì)就是,可以避免人為進(jìn)行純手動(dòng)設(shè)計(jì)特征 ,它能夠?qū)W習(xí)出一組從輸入的數(shù)據(jù)表示到輸出的映射這一套規(guī)則。 比如AutoEncoder便能夠從一組輸入中學(xué)習(xí)出另一組數(shù)據(jù)的表示,雖然生成的結(jié)果基本是模糊的。盡管這些方法具有以上的優(yōu)勢(shì),但是如何學(xué)習(xí)高效的學(xué)習(xí)出一組更合適的映射規(guī)則是關(guān)鍵。 對(duì)于高效性來(lái)說(shuō),以感知機(jī)為例, 它利用多個(gè)MLP來(lái)進(jìn)行特征的學(xué)習(xí)從而來(lái)表征輸入數(shù)據(jù) 。但是這樣有很明顯的缺陷,一方面計(jì)算量是非常龐大的,另一方面直接將輸入flatten為一個(gè)列向量,會(huì)破壞圖像中目標(biāo)原有的結(jié)構(gòu)和上下文聯(lián)系。 在此基礎(chǔ)上,我們可以繼續(xù)優(yōu)化它,把它推廣到更一般的表示——CNN,MLP其實(shí)是CNN的一種特例。
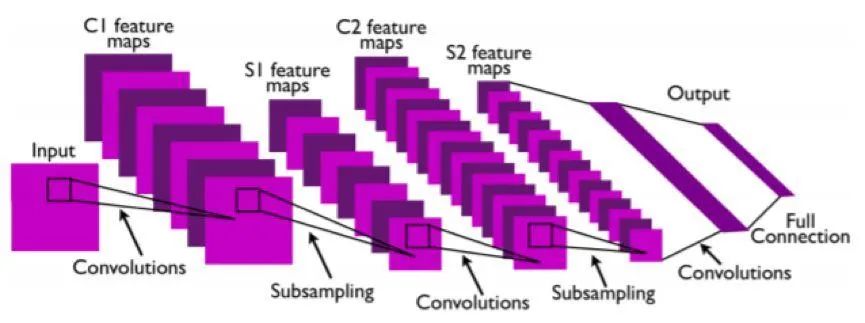
3. 基于深度學(xué)習(xí)的方法在圖像識(shí)別領(lǐng)域最典型的應(yīng)用便是CNN 。CNN是一種分層(hierarchical)的數(shù)據(jù)表示方式,高層的特征表示依賴(lài)于底層的特征表示,由淺入深逐步抽象地提取更具備高級(jí)語(yǔ)義信息的特征。 比如第一層更傾向于提取邊緣,角點(diǎn),線(xiàn)條等low-level的特征,第二層提取顏色,紋理等mid-level的特征,第三層提取更具抽象語(yǔ)義的high-level的特征。網(wǎng)絡(luò)的深度有助于模型提取更抽象地高級(jí)特征,網(wǎng)絡(luò)的寬度有利于模型提取更豐富的特征表示。 這種連接主義 (connectionism)本質(zhì)上是一種解決問(wèn)題很好的思路, 每一層都學(xué)習(xí)各自簡(jiǎn)單的表示 ,但最后通過(guò)連接起來(lái),卻形成了強(qiáng)大的(powerful)的特征表征能力!
此外,CNN還具有一個(gè)非常重要的特性,它是通過(guò)共享卷積核來(lái)提取特征,這樣一方面可以極大的降低參數(shù)量來(lái)避免更多冗余的計(jì)算從而提高網(wǎng)絡(luò)模型計(jì)算的效率,另一方面又結(jié)合結(jié)合卷積和池化使網(wǎng)絡(luò)具備一定的平移不變性(shift-invariant)和平移等變性(equivariance)。 當(dāng)然,對(duì)于分類(lèi)任務(wù)來(lái)說(shuō),我們是希望網(wǎng)絡(luò)具備平移不變性的特點(diǎn),而 對(duì)于分割任務(wù)來(lái)說(shuō)我們則更希望其具備平移等變性 ,不過(guò)這些都是后話(huà),在這里不展開(kāi)闡述。因此,這便是CNN如何學(xué)習(xí)高效的學(xué)習(xí)出一組更合適的映射規(guī)則的關(guān)鍵。
雖然CNN具備如此多的優(yōu)點(diǎn),但不是一開(kāi)始就一蹴而就,也并不是完美無(wú)瑕的。 以圖像分割為例,在全卷積神經(jīng)網(wǎng)絡(luò)FCN提出以前,大多數(shù)基于CNN的方法都是基于Patch-wise即將圖像塊作為輸入輸入到CNN中去進(jìn)行相應(yīng)類(lèi)別預(yù)測(cè),這種方式一來(lái)計(jì)算非常冗余,二來(lái)也缺乏充足的上下文信息。
所以為什么FCN會(huì)這么有影響力,甚至可以稱(chēng)為是一個(gè)mile-stone的網(wǎng)絡(luò),就在于 它真正意義上將patch-wise做到了pixel-wise ,這對(duì)于語(yǔ)義分割這種密集型任務(wù)來(lái)說(shuō)是至關(guān)重要的。
當(dāng)然,F(xiàn)CN也存在許多的缺點(diǎn),諸如分割結(jié)果粗糙等,當(dāng)這并不妨礙我們基于它的思想去進(jìn)行很多的拓展。 比如最近幾年提出的很多分割論文都是針對(duì)它去進(jìn)行改進(jìn),有人提倡改善編碼器利用更強(qiáng)大的卷積模塊去提取更具備代表性的特征。 有人熱衷于改善解碼器,比如引入跳躍連接操作來(lái)彌補(bǔ)編碼器下采樣過(guò)程中空間細(xì)節(jié)信息的丟失從而來(lái)實(shí)現(xiàn)更精準(zhǔn)的定位,關(guān)于如何跳躍又是一個(gè)問(wèn)題,有直接連線(xiàn)的Unet。 繼而 有人又借助語(yǔ)義鴻溝(semantic gap)或者背景噪聲干擾這些口去突破 ,利用多個(gè)卷積去消除,結(jié)合高級(jí)特征的強(qiáng)語(yǔ)義和低級(jí)特征豐富的細(xì)節(jié)信息去指導(dǎo)融合的也有,另外還有借助注意力方式去消除歧義和抑制背景噪聲的也大有人在。 除了編解碼器之外,我們借用特征金字塔的思想還可以結(jié)合多層的結(jié)果去融合輸出,得到一個(gè)更加細(xì)化的特征表示。在拋掉模型本身,也可以從任務(wù)本身下手,從全監(jiān)督到半監(jiān)督,自監(jiān)督,few-shot learning,ome-shot learning,甚至是無(wú)監(jiān)督域等等也有很多方向可以突破。
其他視覺(jué)任務(wù)如分類(lèi),檢測(cè)或者low-level的任務(wù)如超分,去噪等也可以此類(lèi)比,很多人寫(xiě)不來(lái)論文或者解決不了問(wèn)題的關(guān)鍵點(diǎn)在于根本沒(méi)發(fā)現(xiàn)問(wèn)題在哪里,又何談解決問(wèn)題。
目前為止,我們已經(jīng)簡(jiǎn)要的總結(jié)了CNN為什么會(huì)被提出以及它的優(yōu)勢(shì)在哪。 盡管CNN存在以上優(yōu)勢(shì),比如它利用卷積核或?yàn)V波器不斷地提取抽象地高級(jí)特征,理論上來(lái)說(shuō)其感受野應(yīng)該能覆蓋到全圖, 但許多研究表明其實(shí)際感受野遠(yuǎn)小于理論感受野,這不利于我們充分的利用上下文信息進(jìn)行特征的捕獲 ,雖然我們可以通過(guò)不斷的堆疊更深的卷積層,但這顯然會(huì)造成模型過(guò)于臃腫計(jì)算量急劇增加,違背了初衷。 而transformer的優(yōu)勢(shì)就在于利用注意力的方式來(lái)捕獲全局的上下文信息從而對(duì)目標(biāo)建立起遠(yuǎn)距離的依賴(lài),從而提取出更強(qiáng)有力的特征。
因此,我們并不需要說(shuō)一味的拋棄CNN,或許可以轉(zhuǎn)換下思路把兩者結(jié)合起來(lái),將transformer當(dāng)做是一種特征提取器利用起來(lái),再結(jié)合CNN的一些優(yōu)勢(shì)去解決現(xiàn)有的問(wèn)題。 對(duì)于接下來(lái)這個(gè)方向的思考,筆者推測(cè)當(dāng)過(guò)了這把trasformer的新鮮勁,即在各個(gè)任務(wù)上都利用transformer替代一遍后, 未來(lái)的工作更多的是結(jié)合這兩者 ,來(lái)實(shí)現(xiàn)一個(gè)更優(yōu)或者說(shuō)是一個(gè)更reasonable的結(jié)果,讓我們拭目以待。
總的來(lái)說(shuō),每一種技術(shù)的提出,都會(huì)受到當(dāng)時(shí)所處環(huán)境或多或少的影響,然后通過(guò)不斷地發(fā)現(xiàn)問(wèn)題,提出問(wèn)題,再到解決問(wèn)題這樣一步步不停地迭代。 從宏觀角度上來(lái)看, 一個(gè)學(xué)科技術(shù)要發(fā)展的更快更好,其中的一個(gè)很重要原因便是具備普適性。 個(gè)人認(rèn)為這一點(diǎn)非常重要,普適性意味著入門(mén)門(mén)檻低,這樣涌入這個(gè)圈子的人就多,形成的“泡沫”就大,資本才會(huì)為其買(mǎi)單,真正意義上潛心研究的專(zhuān)家才能更被凸顯出來(lái),才能有更充足的經(jīng)費(fèi)和動(dòng)力去研究,去突破現(xiàn)有的技術(shù)將知識(shí)的邊界不斷的拓寬,利用科技造福人類(lèi)。 當(dāng)然,這里面必定夾雜著許多魚(yú)龍混雜的人或物,但是只要宏觀方向把握得當(dāng),制度制定得比較完善,就能夠避免“泡沫”的幻滅,整體維持一個(gè)健康向上的發(fā)展。畢竟,任何事物都具備兩面性,發(fā)展是一把雙刃劍。 唯有寄希望于巨頭公司和機(jī)構(gòu)有更大的擔(dān)當(dāng),當(dāng)好這個(gè)時(shí)代的領(lǐng)頭羊和風(fēng)向標(biāo),在制度的籠子下引領(lǐng)著這個(gè)時(shí)代朝著健康向上的道路去發(fā)展,而不是諸如一窩蜂的跑到菜市場(chǎng)去搞“社區(qū)團(tuán)購(gòu)”之類(lèi)的割韭菜活動(dòng),而是應(yīng)該做到真正意義上的“科技向善”。 齊國(guó)君:CNN和Transformer在處理視覺(jué)信息上各有優(yōu)缺點(diǎn)
CNN網(wǎng)絡(luò)在提取底層特征和視覺(jué)結(jié)構(gòu)方面有比較大的優(yōu)勢(shì)。這些 底層特征構(gòu)成了在patch level 上的關(guān)鍵點(diǎn)、線(xiàn)和一些基本的圖像結(jié)構(gòu) 。這些底層特征具有明顯的幾何特性,往往關(guān)注諸如平移、旋轉(zhuǎn)等變換下的一致性或者說(shuō)是共變性。 比如,一個(gè)CNN卷積濾波器檢測(cè)得到的關(guān)鍵點(diǎn)、物體的邊界等構(gòu)成視覺(jué)要素的基本單元在平移等空間變換下應(yīng)該是同時(shí)變換(共變性)的。CNN網(wǎng)絡(luò)在處理這類(lèi)共變性時(shí)是很自然的選擇。 但當(dāng)我們檢測(cè)得到這些基本視覺(jué)要素后, 高層的視覺(jué)語(yǔ)義信息往往更關(guān)注這些要素之間如何關(guān)聯(lián)在一起進(jìn)而構(gòu)成一個(gè)物體,以及物體與物體之間的空間位置關(guān)系如何構(gòu)成一個(gè)場(chǎng)景 ,這些是我們更加關(guān)心的。目前來(lái)看,transformer在處理這些要素之間的關(guān)系上更自然也更有效。 從這兩方面的角度來(lái)看,將CNN在處理底層視覺(jué)上的優(yōu)勢(shì)和transformer在處理視覺(jué)要素和物體之間關(guān)系上的優(yōu)勢(shì)相結(jié)合,應(yīng)該是一個(gè)非常有希望的方向。
小小將:足夠大的參數(shù)+好的訓(xùn)練方法,三層神經(jīng)網(wǎng)絡(luò)可以逼近任何一個(gè)非線(xiàn)性函數(shù)
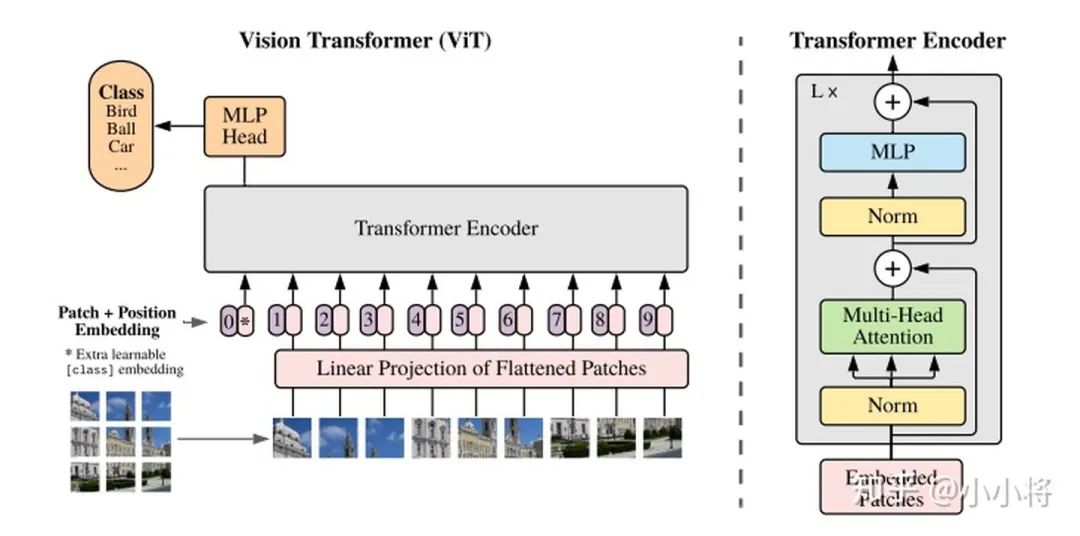
先簡(jiǎn)單來(lái)看一下transformer在分類(lèi),檢測(cè)和分割上的應(yīng)用: (1) 分類(lèi) ViT :?An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 把圖像分成固定大小的patchs,把patchs看成words送入transformer的encoder,中間沒(méi)有任何卷積操作,增加一個(gè)class token來(lái)預(yù)測(cè)分類(lèi)類(lèi)別。 (2) 檢測(cè) DETR :End-to-End Object Detection with Transformers
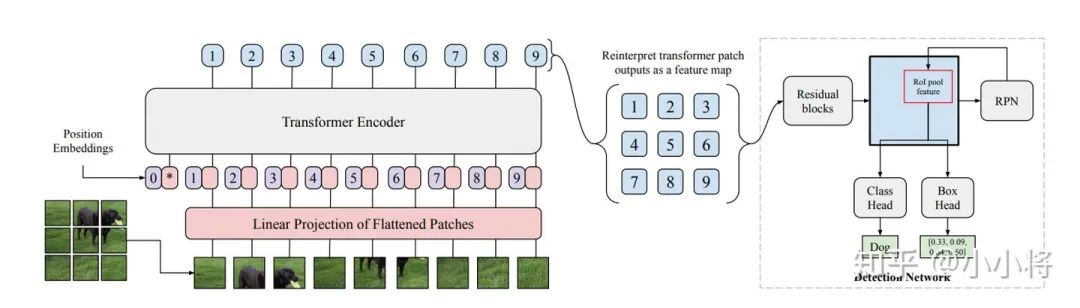
先用CNN提取特征,然后把最后特征圖的每個(gè)點(diǎn)看成word,這樣特征圖就變成了a sequence words,而檢測(cè)的輸出恰好是a set objects,所以transformer正好適合這個(gè)任務(wù)。 (3) 分割 SETR :Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers 用ViT作為的圖像的encoder,然后加一個(gè)CNN的decoder來(lái)完成語(yǔ)義圖的預(yù)測(cè)。 當(dāng)然,目前基于transformer的模型在分類(lèi),檢測(cè)和分割上的應(yīng)用絕不止上面這些,但基本都是差不多的思路。 比如ViT-FRCNN:Toward Transformer-Based Object Detection這個(gè)工作是把ViT和RCNN模型結(jié)合在一起來(lái)實(shí)現(xiàn)檢測(cè)的。 關(guān)于transformer更多在CV上的工作,可以看最新的一篇綜述文章:A Survey on Visual Transformer
這里來(lái)談一下自己幾點(diǎn)粗鄙的認(rèn)識(shí):
(1) CNN是通過(guò)不斷地堆積卷積層來(lái)完成對(duì)圖像從局部信息到全局信息的提取 ,不斷堆積的卷積層慢慢地?cái)U(kuò)大了感受野直至覆蓋整個(gè)圖像;但是transformer并不假定從局部信息開(kāi)始,而且一開(kāi)始就可以拿到全局信息,學(xué)習(xí)難度更大一些,但transformer學(xué)習(xí)長(zhǎng)依賴(lài)的能力更強(qiáng)。
另外從ViT的分析來(lái)看,前面的layers的“感受野”(論文里是mean attention distance)雖然迥異但總體較小,后面的layers的“感受野“越來(lái)越大,這說(shuō)明ViT也是學(xué)習(xí)到了和CNN相同的范式。
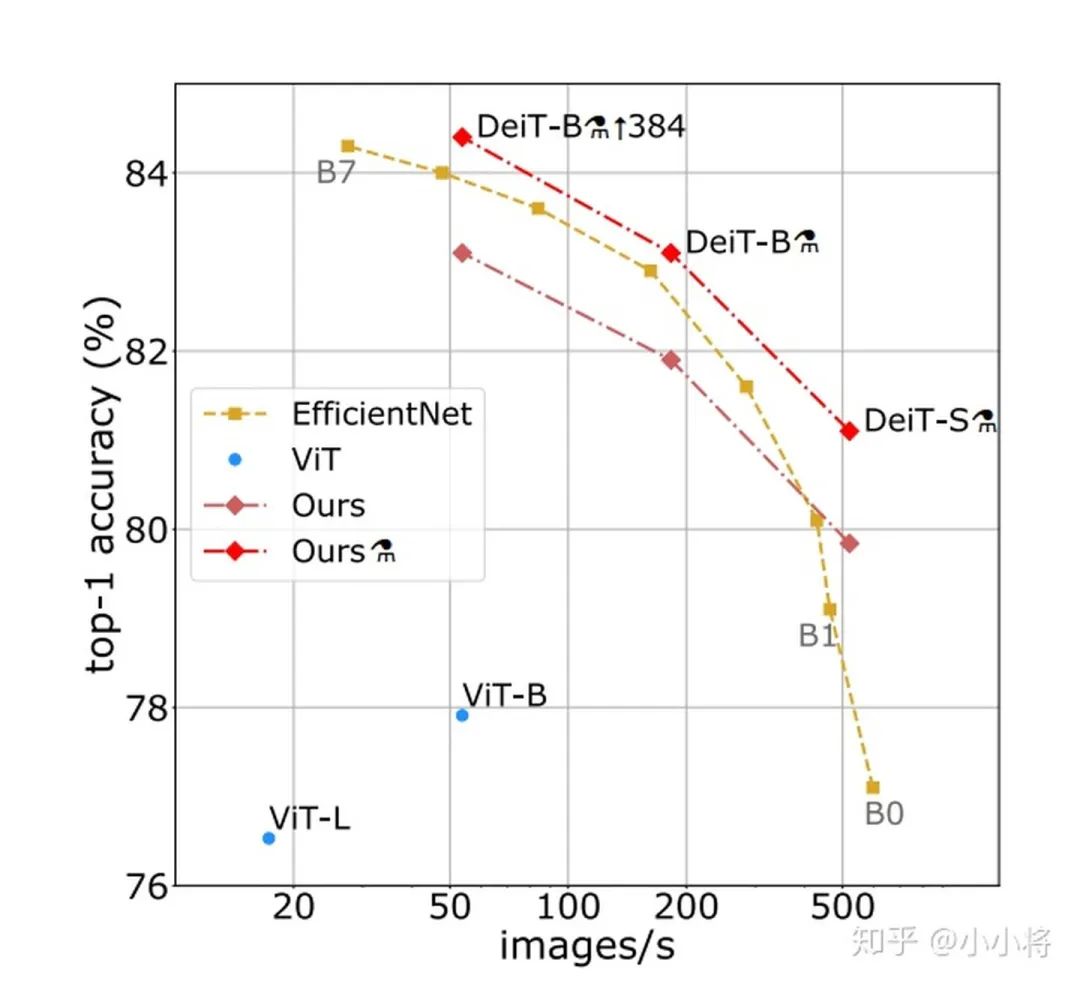
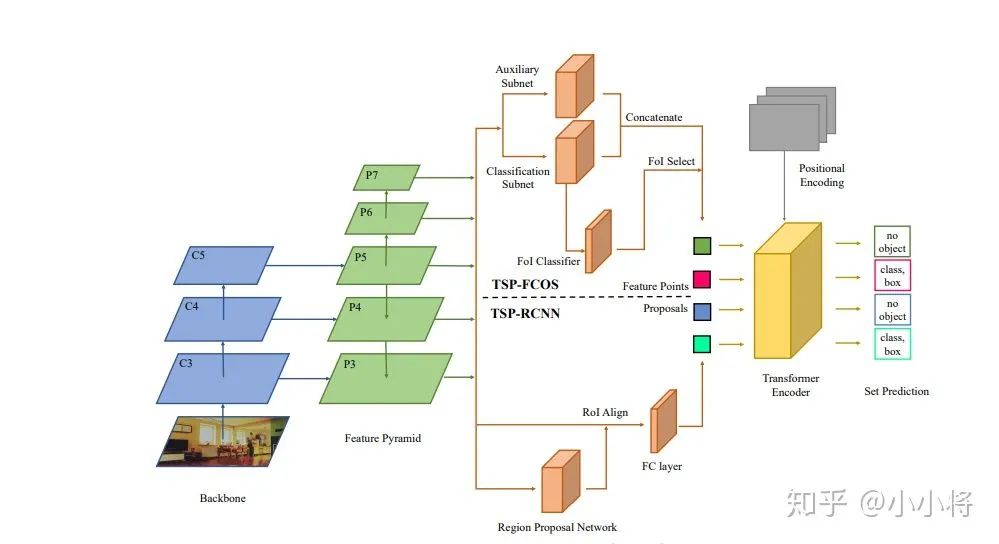
(2) CNN對(duì)圖像問(wèn)題有天然的inductive bias ,如平移不變性等等,以及CNN的仿生學(xué)特性,這讓CNN在圖像問(wèn)題上更容易;相比之下,transformer沒(méi)有這個(gè)優(yōu)勢(shì),那么學(xué)習(xí)的難度很大,往往需要更大的數(shù)據(jù)集(ViT)或者更強(qiáng)的數(shù)據(jù)增強(qiáng)(DeiT)來(lái)達(dá)到較好的訓(xùn)練效果。 好在transformer的遷移效果更好,大的數(shù)據(jù)集上的pretrain模型可以很好地遷移到小數(shù)據(jù)集上。還有一個(gè)就是ViT所說(shuō)的, transformer的scaling能力很強(qiáng),那么進(jìn)一步提升參數(shù)量或許會(huì)帶來(lái)更好的效果 (就像驚艷的GPT模型)。 (3)目前我們還看到很大一部分工作還是把transformer和現(xiàn)有的CNN工作結(jié)合在一起,如ViT其實(shí)也是有Hybrid Architecture(將ResNet提出的特征圖送入ViT)。 而對(duì)于檢測(cè)和分割這類(lèi)問(wèn)題,CNN方法已經(jīng)很成熟,難以一下子用transformer替換掉, 目前的工作都是CNN和transformer的混合體,這其中有速度和效果的雙重考慮 。 另外也要考慮到如果輸入較大分辨率的圖像,transformer的計(jì)算量會(huì)很大,所以ViT的輸入并不是pixel,而是小patch,對(duì)于DETR它的transformer encoder的輸入是1/32特征這都有計(jì)算量的考慮,不過(guò)這肯定有效果的影響,所以才有后面改進(jìn)工作deform DETR。 短期來(lái)看,CNN和transformer應(yīng)該還會(huì)攜手同行 。最新的論文Rethinking Transformer-based Set Prediction for Object Detection,還是把現(xiàn)有的CNN檢測(cè)模型和transformer思想結(jié)合在一起實(shí)現(xiàn)了比DETR更好的效果(訓(xùn)練收斂速度也更快): (4)這我想到了 神經(jīng)網(wǎng)絡(luò)的本質(zhì):一個(gè)復(fù)雜的非線(xiàn)性系統(tǒng)來(lái)擬合你的問(wèn)題 。無(wú)論是CNN,RNN或者transformer都是對(duì)問(wèn)題一種擬合罷了,也沒(méi)有孰優(yōu)孰劣。
就一個(gè)受限的問(wèn)題來(lái)看,可能有個(gè)高低之分,但我相信隨著數(shù)據(jù)量的增加,問(wèn)題的效果可能最終取決于模型的計(jì)算量和參數(shù),而不是模型是哪個(gè),因?yàn)橹暗墓ぷ饕呀?jīng)證明: 一個(gè)三層神經(jīng)網(wǎng)絡(luò)可以逼近任何一個(gè)非線(xiàn)性函數(shù),前提是參數(shù)足夠大,而且更重要的是你找到一個(gè)好的訓(xùn)練方法 。
未來(lái)雖然很難說(shuō),但依然可期!
原文鏈接:
【1】https://www.zhihu.com/question/437495132/answer/1656908750
【2】https://www.zhihu.com/question/437495132/answer/1658559732
【3】https://www.zhihu.com/question/437495132/answer/1656610825