
即插即用模塊:CompConv卷積讓模型不丟精度還可以提速

極市導讀
為了降低CNN的計算成本,本文提出了一種新的卷積設計:CompConv。它利用分治法策略來簡化特征圖的轉換。即插即用!可直接替換普通卷積,幾乎不犧牲性能,極致壓縮CNN結構! >>加入極市CV技術交流群,走在計算機視覺的最前沿

簡介
本文主要貢獻
-
提出了一種緊湊的卷積模塊CompConv,它利用了分治法策略和精心設計的相同映射大大降低了CNN的計算代價。 -
通過研究遞歸計算對學習能力的影響,對所提出的CompConv進行了詳盡的分析。進一步提出了一個切實可行的壓縮率控制方案。 -
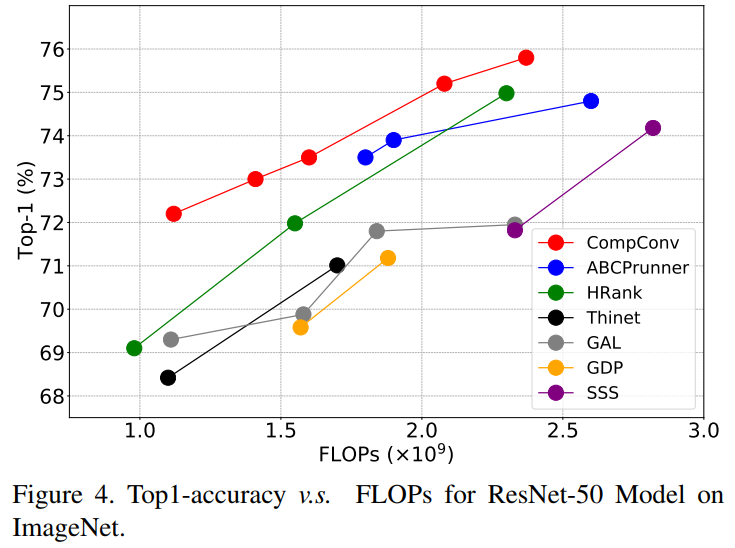
作為傳統(tǒng)卷積層的方便替代作者將CompConv應用于各種benchmark。結果表明,CompConv可以大幅節(jié)省計算負載,但幾乎不犧牲模型在分類和檢測任務上的性能的情況下,CompConv方法優(yōu)于現(xiàn)有的方法。
2 本文方法
2.1 動機何在?
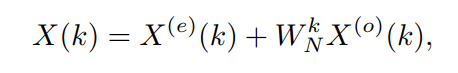
2.2 CompConv核心單元
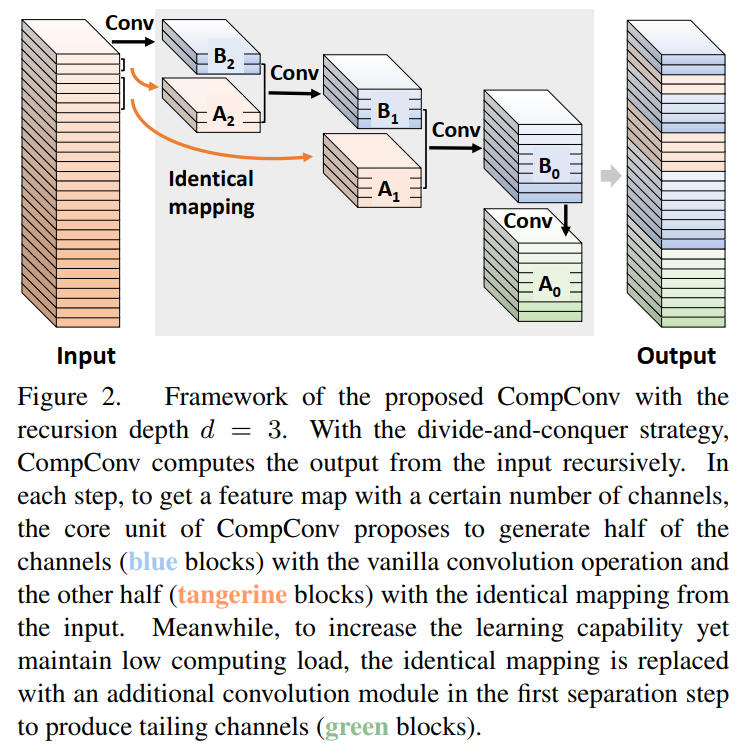
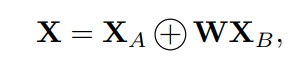
2.3 遞歸計算
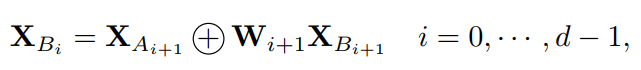
Tailing Channels
-
一方面,在所有相同的部件 中, 的通道最多。如果直接將一些輸入通道復制為 ,那么輸入特征映射和輸出特征映射之間會有過多的冗余,嚴重限制了該模塊的學習能力。
-
另一方面,除了從 轉換之外,還有一些其他方法可以獲得 ,例如從整個輸入特征映射或構建另一個遞歸。其中,從 開發(fā) 是計算成本最低的一種方法。同時, 的推導已經(jīng)從輸入特征中收集了足夠的信息,因此學習能力也可以保證。
整合遞歸結果
2.4 Adaptive Separation策略
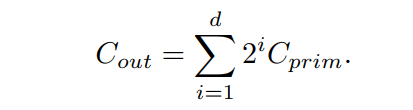

遞歸計算深度的選擇
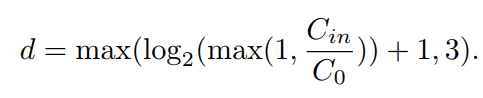
推薦配置
2.5 復雜度分析
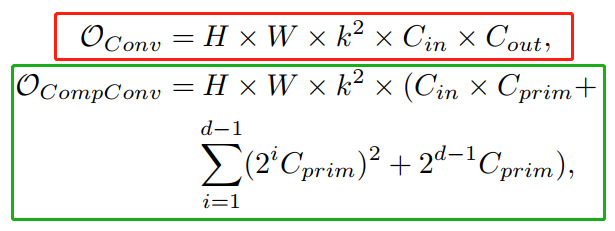
3 實驗
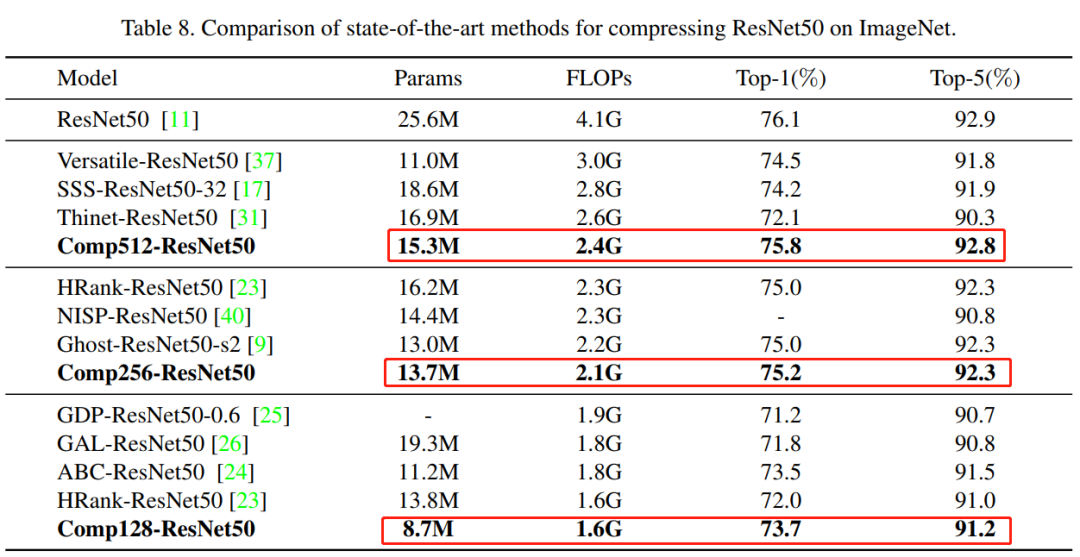
3.1 ImageNet分類

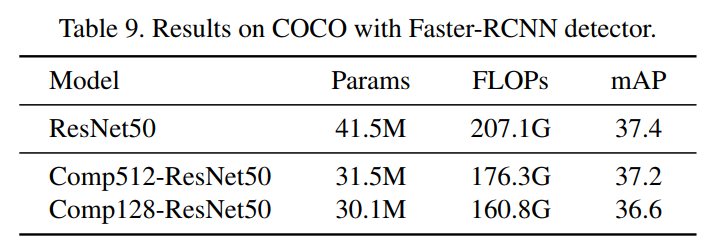
3.2 COCO目標檢測
4 論文傳遞門:
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復“79”獲取CVPR 2021:TransT 直播鏈接~

# CV技術社群邀請函 #
備注:姓名-學校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~

評論
圖片
表情