
詳細解讀 Transformer的即插即用模塊 | MoE插件讓ViT模型更寬、更快、精度更高


本文提出Transformer更寬而不是更深,以實現(xiàn)更高效的參數(shù)部署,并將此框架實現(xiàn)為WideNet。首先通過在Transformer塊之間共享參數(shù)來壓縮可訓(xùn)練參數(shù)和深度,并用MoE層替換了FFN層。實驗表明,WideNet通過較少的可訓(xùn)練參數(shù)實現(xiàn)了最佳性能,優(yōu)于ViT等網(wǎng)絡(luò)。
作者單位:新加坡國立大學(xué)
1簡介
Transformer最近在各種任務(wù)上取得了令人矚目的成果。為了進一步提高Transformer的有效性和效率,現(xiàn)有工作中有2種思路:
-
通過擴展到更多可訓(xùn)練的參數(shù)來擴大范圍; -
通過參數(shù)共享或模型壓縮隨深度變淺。
然而,當(dāng)可供訓(xùn)練的Token較少時,較大的模型通常無法很好地擴展,而當(dāng)模型非常大時,則需要更高的并行性。由于表征能力的損失,與原始Transformer模型相比,較小的模型通常會獲得較差的性能。
在本文中,為了用更少的可訓(xùn)練參數(shù)獲得更好的性能,作者提出了一個通過更寬的模型框架來有效地部署可訓(xùn)練參數(shù)。特別地,作者通過用MoE替換前饋網(wǎng)絡(luò)(FFN)來沿模型寬度進行縮放。然后,使用單個層歸一化跨Transformer Block共享MoE層。這種部署起到了轉(zhuǎn)換各種語義表征的作用,這使得模型參數(shù)更加高效和有效。
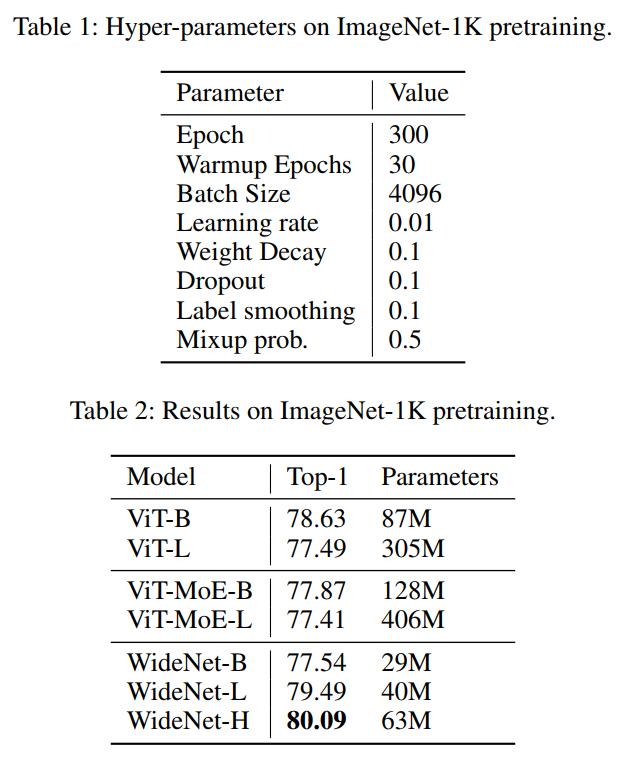
為了評估所提的框架,作者設(shè)計了WideNet并在ImageNet-1K上對其進行評估。最好的模型在0.72倍可訓(xùn)練參數(shù)下的性能比ViT高1.46%。使用0.46×和0.13×參數(shù)的WideNet仍然可以分別超過ViT和ViT-MoE0.83%和2.08%。
本文主要貢獻
-
為了提高參數(shù)效率,提出了跨Transformer Block的共享MoE層。MoE層可以在不同的Transformer Block中接收到不同的Token表示,這使得每個MoE都能得到充分的訓(xùn)練;
-
在Transformer Block之間保持單獨的標(biāo)準化層。單獨的層具有少量額外的可訓(xùn)練參數(shù)可以將輸入隱藏向量轉(zhuǎn)換為其他語義。然后,將不同的輸入輸入到同一Attention層或更強的MoE層,以建模不同的語義信息。
-
結(jié)合以上2種思路,作者提出了更廣、更少參數(shù)、更有效的框架。然后將用這個框架構(gòu)建了WideNet,并在ImageNet上對其進行評估。WideNet在可訓(xùn)練參數(shù)少得多的情況下,性能大大優(yōu)于Baseline。
2Methodology
本文研究了一種新的可訓(xùn)練參數(shù)部署框架,并在Transformer上實現(xiàn)了該框架。總體結(jié)構(gòu)如圖所示。在這個例子中使用Vision Transformer作為Backbone,這意味著在Attention或FFN層之前進行規(guī)范化。
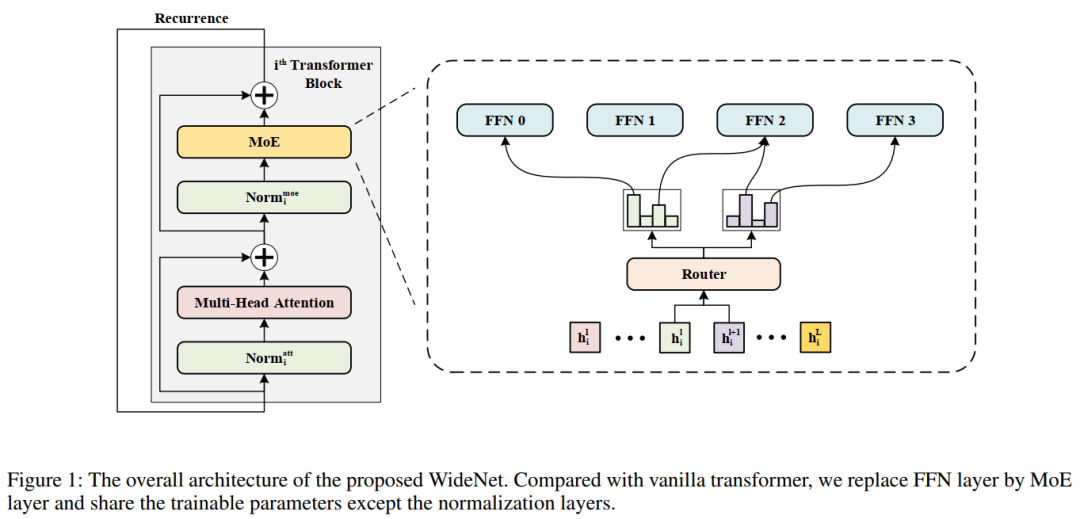
WideNet可以很容易地擴展到其他Transformer模型。在WideNet中用MoE層代替FFN層。采用跨Transformer Block的參數(shù)共享,以實現(xiàn)更有效的參數(shù)部署。在每個MoE層中有一個路由器來選擇K個專家來學(xué)習(xí)更復(fù)雜的表示。請注意,為了更多樣化的語義表示,層標(biāo)準化中的可訓(xùn)練參數(shù)不是共享的。
2.1 MoE條件計算
核心理念是沿著寬度部署更多的可訓(xùn)練參數(shù),沿著深度部署更少的可訓(xùn)練參數(shù)。為此,作者使用MoE將Transformer縮放到大量的可訓(xùn)練參數(shù)。MoE作為一種典型的條件計算模型,只激活少數(shù)專家,即網(wǎng)絡(luò)的子集。對于每個輸入只將需要處理的隱藏表示的一部分提供給選定的專家。
根據(jù)Shazeer,給定E個可訓(xùn)練專家,輸入表示 , MoE模型的輸出可以表示為:
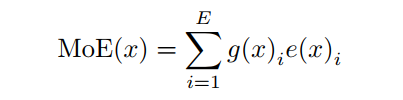
其中 為非線性變換, 為可訓(xùn)練路由器 輸出的第 個元素,通常 和 都是由神經(jīng)網(wǎng)絡(luò)參數(shù)化的。
由上式可知,當(dāng) 為稀疏向量時,在訓(xùn)練過程中,只有部分專家會被反向傳播激活和更新。在本文中,對于普通的MoE和WideNet,每個專家都是一個FFN層。
2.2 Routing
為了保證稀疏Routing ,使用TopK()來選擇排名最高的專家。根據(jù)Riquelme論文 可表示為:
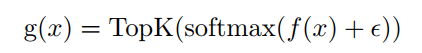
式中 為路由線性變換, 為專家路由的高斯噪聲。在 之后使用softmax,以獲得更好的性能和更稀疏的專家。當(dāng)K<<E時, 的大部分元素為零,從而實現(xiàn)稀疏條件計算。
2.3 Balanced Loading
在基于MoE的Transformer中將每個Token分派給K個專家。在訓(xùn)練期間,如果MoE模型沒有規(guī)則,大多數(shù)Token可能會被分派給一小部分專家。這種不平衡的分配會降低MoE模型的吞吐量。
此外,更重要的是,大多數(shù)附加的可訓(xùn)練參數(shù)沒有得到充分的訓(xùn)練,使得稀疏條件模型在縮放時無法超越相應(yīng)的稠密模型。因此,為了平衡加載需要避免2件事:
-
分配給單個專家的Token太多, -
單個專家收到的Token太少。
為了解決第1個問題,需要緩沖容量B。也就是說,對于每個專家,最多只保留B個Token,不管分派給該專家多少Token。如果分配了超過B個Token,那么左邊的Token將被丟棄:
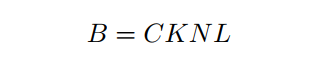
其中C是容量比,這是一個預(yù)定義的超參數(shù),用于控制為每個專家保留的Token的比例。通常, ,在沒有特別說明的情況下,設(shè)C為1.2。K是每個token選擇的專家數(shù)量。N為每個設(shè)備上的batch-size。L是序列的長度。對于計算機視覺任務(wù),L表示每幅圖像中patch Token的數(shù)量。
緩沖區(qū)容量B幫助每個專家去除冗余token以最大化吞吐量,但它不能確保所有專家都能收到足夠的token進行訓(xùn)練。換句話說,直到現(xiàn)在,路由仍然是不平衡的。因此,使用可微分的負載均衡損失,而不是在路由器中均衡負載時單獨的負載均衡和重要性權(quán)重損失。對于每個路由操作,給定E專家和N批帶有NL token,在訓(xùn)練時模型總損失中加入以下輔助損失:
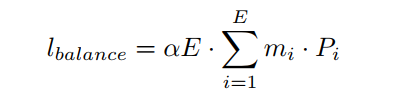
其中 是向量。第 i$的token的比例:
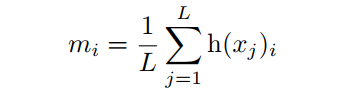
式中 為Eq.2中TopK選取的指標(biāo)向量。 是 的第 個元素。值得注意的是,與Eq.2中的 不同, 和 是不可微的。然而,需要一個可微分的損失函數(shù)來優(yōu)化端到端的MoE。因此,將式4中的 定義為:
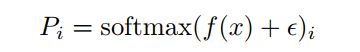
可以看出 是softmax激活函數(shù)后路由線性變換的第 個元素,并且 是可微的。
負載均衡損失的目的是實現(xiàn)均衡分配。當(dāng)最小化 時,可以看到m和P都接近均勻分布。
2.4 Cross Transformer blocks共享MoE
如圖1所示,WideNet采用跨Transformer blocks參數(shù)共享的方式。使用參數(shù)共享有2個原因。首先,在本文中目標(biāo)是一個更參數(shù)有效的框架。其次,由于使用MoE層來獲得更強的建模能力,為了克服稀疏條件計算帶來的過擬合問題,需要給每個專家提供足夠的token。為此,WideNet使用相同的路由器和專家在不同的Transformer blocks。
形式上,給定隱藏表示 作為第1個Transformer blocks的輸入,可以將參數(shù)共享定義為 ,這與現(xiàn)有的基于MoE的模型 不同。
請注意,雖然在包括路由器在內(nèi)的MoE層共享可訓(xùn)練參數(shù),但對應(yīng)于同一Token的Token表示在每個Transformer blocks中是不同的。也就是說, 和 可以派給不同的專家。因此,每個專家將接受更多不同的Token的訓(xùn)練,以獲得更好的性能。
2.5 Individual Layer Normalization
雖然現(xiàn)有的工作表明不同Transformer blocks的激活是相似的,但余弦距離仍然遠遠大于零。因此,不同于現(xiàn)有的作品在Transformer blocks之間共享所有權(quán)重,為了鼓勵不同塊更多樣化的輸入表示,這里只共享multi-head attention layer和FFN(或MoE)層,這意味著層標(biāo)準化的可訓(xùn)練參數(shù)在塊之間是不同的。
綜上所述,框架中的第 個Transformer blocks可以寫成:
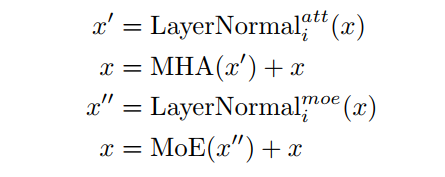
標(biāo)準化層LayerNormal(·)為:
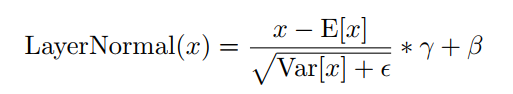
其中 和 是2個可訓(xùn)練的參數(shù)。
層歸一化只需要這2個小向量,所以單獨的歸一化只會在框架中添加一些可訓(xùn)練的參數(shù)。可以發(fā)現(xiàn)共享層標(biāo)準化和單個標(biāo)準化之間的差異是輸出的平均值和大小。對于共享層歸一化,MHA和MoE層的輸入在不同的Transformer blocks中更相似。由于共享了可訓(xùn)練矩陣,鼓勵更多樣化的輸入以在不同的Transformer blocks中表示不同的語義。
3Optimization
雖然在每個Transformer block中重用了路由器的可訓(xùn)練參數(shù),但由于輸入表示的不同,分配也會不同。因此,給定T次具有相同可訓(xùn)練參數(shù)的路由操作,需要優(yōu)化的損失如下:
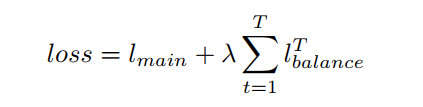
其中λ是一個超參數(shù),以確保平衡分配,將其設(shè)置為一個相對較大的數(shù),即在本工作中為0.01。與現(xiàn)有的基于MoE的模型相似,作者發(fā)現(xiàn)該模型的性能對λ不敏感。 是Transformer的主要目標(biāo)。例如,在有監(jiān)督圖像分類中, 是交叉熵損失。
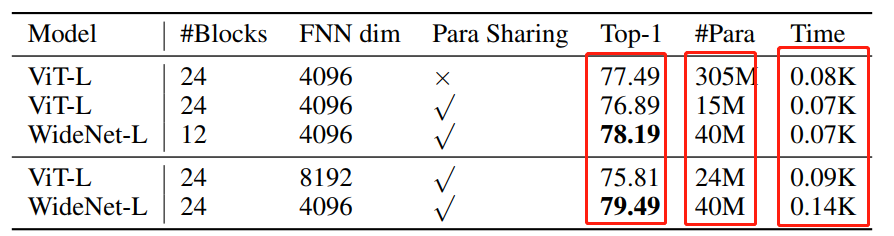
4實驗
5參考
[1].Go Wider Instead of Deeper
6推薦閱讀

超越MobileNet V3 | 詳解SkipNet+Bias Loss=輕量化模型新的里程碑
CSL-YOLO | 超越Tiny-YOLO V4,全新設(shè)計輕量化YOLO模型實現(xiàn)邊緣實時檢測!!!
DA-YOLO |多域自適應(yīng)DA-YOLO解讀,惡劣天氣也看得見(附論文)
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉(zhuǎn)載請說明出處
掃描下方二維碼關(guān)注【集智書童】公眾號,獲取更多實踐項目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
