
如何更好的向量化召回
前言
常讀我的文章的同學(xué)會注意到,我一直強(qiáng)調(diào)、推崇,不要孤立地學(xué)習(xí)算法,而是要梳理算法的脈絡(luò)+框架,唯有如此,才能真正融會貫通,變紙面上的算法為你的算法,而不是狗熊掰棒子,被層出不窮的新文章、新算法搞得疲于奔命。
之前,我在《推薦算法的"五環(huán)之歌"》梳理了主流排序算法常見套路:
特征都ID化。類別特征天然是ID型,而實(shí)數(shù)特征需要經(jīng)過分桶轉(zhuǎn)化。 每個ID特征經(jīng)過Embedding變成一個向量,以擴(kuò)展其內(nèi)涵。 屬于一個Field的各Feature Embedding通過Pooling壓縮成一個向量,以減少DNN的規(guī)模 多個Field Embedding拼接在一起,喂入DNN DNN通過多層Fully Connection Layer (FC)完成特征之間的高階交叉,增強(qiáng)模型的擴(kuò)展能力。 最后一層FC的輸出,就是最終的logit,與label(e.g., 是否點(diǎn)擊?是否轉(zhuǎn)化)計(jì)算binary cross-entropy loss。
相比于排序那直白的套路,召回算法,品類眾多而形態(tài)迥異,看似很難找出共通點(diǎn)。如今比較流行的召回算法,比如:item2vec、DeepWalk、Youtube的召回算法、Airbnb的召回算法、FM召回、DSSM、雙塔模型、百度的孿生網(wǎng)絡(luò)、阿里的EGES、Pinterest的PinSAGE、騰訊的RALM和GraphTR、......
從召回方式上分,有的直接給user找他可能喜歡的item(user-to-item,簡稱u2i);有的是拿用戶喜歡的item找相似item(item-to-item,簡稱i2i);有的是給user查找相似user,再把相似user喜歡的item推出去(user-to-user-to-item,簡稱u2u2i) 從算法實(shí)現(xiàn)上分,有的來自“前深度學(xué)習(xí)”時代,老當(dāng)益壯;有的基于深度學(xué)習(xí),正當(dāng)紅;有的基于圖算法,未來可期(其實(shí)基于圖的,又可細(xì)分為游走類和卷積類)。 從優(yōu)化目標(biāo)上分,有的屬于一個越大規(guī)模的多分類問題,優(yōu)化softmax loss;有的基于Learning-To-Rank(LTR),優(yōu)化的是hinge loss或BPR loss
但是,如果我告訴你,以上這些召回算法,其實(shí)都可以被一個統(tǒng)一的算法框架所囊括,驚不驚奇、意不意外?本文就介紹我歸納總結(jié)的NFEP(Near, Far, Embedding, Pairwie-loss)框架,系統(tǒng)化地理解向量化召回算法。在詳細(xì)介紹之前,我首先需要強(qiáng)調(diào),這么做的目的,并非要將本來不相干的算法“削足適履”硬塞進(jìn)一個框架里,嘩眾取寵,而是有著兩方面的重要意義:
一是為了開篇所說的“融會貫通”。借助NFEP,你學(xué)習(xí)的不再是若干孤立的算法,而是一個算法體系,不僅能加深對現(xiàn)有算法的理解,還能輕松應(yīng)對未來出現(xiàn)的新算法; 二是為了“取長補(bǔ)短”。大多數(shù)召回算法,只是在NFEP的某個維度上進(jìn)行了創(chuàng)新,而在其他維度上的做法未必是最優(yōu)的。我們在技術(shù)選型時,沒必要照搬某個算法的全部,而是借助NFEP梳理的脈絡(luò),博采多家算法之所長,取長補(bǔ)短,組成最適合你的業(yè)務(wù)場景、數(shù)據(jù)環(huán)境的算法。
接下來,我首先介紹NFEP框架,然后逐一介紹如何從NFEP的框架視角來理解Airbnb召回、Youtube召回、Facebook EBR、Pinterest的PinSAGE、微信GraphTR、FM召回這幾種典型的召回算法。
NFEP:理解向量化召回的統(tǒng)一框架
向量化召回簡介
NFEP框架關(guān)注的是“向量化召回”算法,也就是將召回建模成在向量空間內(nèi)的近鄰搜索問題。傳統(tǒng)的ItemCF/UserCF那種基于統(tǒng)計(jì)的召回方式,和阿里TDM那種基于樹模型層次化劃分搜索空間的召回算法,不在討論范圍之內(nèi)。
假設(shè)向量化召回,是拿X概念下的某個x,在向量空間中搜索Y概念下與之最近的y。其serving的套路就是
離線時,將幾百萬、上千萬的y,通過模型獲得它們的embedding,將這些y embedding灌入FAISS并建立索引 在線時,拿請求中的x,或提取、或生成x embedding,在FAISS中查找最近的y embedding,將對應(yīng)的y作為召回結(jié)果返回
為了達(dá)成以上目標(biāo),我們在訓(xùn)練的時候,需要考慮四個問題:(1)如何定義X/Y兩概念之間的“距離近”?(2)如何舉反例,即如何定義X/Y之間的“距離遠(yuǎn)”?(3)如何獲取embedding?(4)如何定義loss來優(yōu)化?
這4個問題,對應(yīng)著NFEP框架的4個維度,接下來將會逐一詳細(xì)分析。
Near:如何定義“近”?
這取決于不同的召回方式
i2i召回:x,y都是item,我們認(rèn)為同一個用戶在同一個session交互過的兩個item在向量空間是相近的,體現(xiàn)兩個item之間的“相似性”。 u2i召回:x是user,y是item。一個用戶與其交互(e.g., 點(diǎn)擊、觀看、購買)過的item應(yīng)該是相近的,體現(xiàn)user與item之間的“匹配性”。 u2u召回:x,y都是user。比如使用孿生網(wǎng)絡(luò),則x是user一半的交互歷史,y是同一用戶另一半交互歷史,二者在向量空間應(yīng)該是相近的,體現(xiàn)“同一性”。
無論哪種召回方式,為了能夠與FAISS兼容,我們都拿x embedding和y embedding之間的“點(diǎn)積”或"cosine"來衡量距離。顯然,點(diǎn)積或cosine越大,代表x與y在向量空間越接近。
Far:如何定義“遠(yuǎn)”?
其實(shí)就是舉反例。舉出的<>反例,要能夠讓模型見識到形形色色、五花八門、不同角度的“之間差異性”,達(dá)到讓模型“開眼界,見世面”的目的。特別是在訓(xùn)練u2i召回模型時,一個非常重要的原則就是,千萬不能(只)拿“曝光未點(diǎn)擊”做負(fù)樣本。否則,正負(fù)樣本都來自“曝光”樣本,都是與user比較匹配的item,而在上百萬的候選item中,絕大部分item都是與user興趣“八桿子打不著”的。這種訓(xùn)練數(shù)據(jù)與預(yù)測數(shù)據(jù)之間的bias,將導(dǎo)致召回模型上線后“水土不服”。具體原理解釋,請參考我的另一篇文章《負(fù)樣本為王》。
為了達(dá)到以上目標(biāo),獲得最重要的方式就是在整個y的候選集中隨機(jī)采樣:
有同學(xué)擔(dān)心,隨機(jī)采樣得到的有可能與x是相近的。不排除這種可能性,但是在一個實(shí)際的推薦系統(tǒng)中,候選的y一般是成百上千萬,而每次隨機(jī)采樣的不會超過100,這種false negative的概率極低。 隨機(jī)采樣并非uniform sampling,那樣會導(dǎo)致熱門item霸占召回結(jié)果,從而失去個性化。因此在采樣時,需要打壓熱門item。比較有效的一種方式就是學(xué)習(xí)word2vec中打壓高頻詞的方法,降低熱門item成為正樣本的概率,提升熱門item成為負(fù)樣本的概率。具體公式細(xì)節(jié),見的我的知乎回答《推薦系統(tǒng)傳統(tǒng)召回是怎么實(shí)現(xiàn)熱門item的打壓?》。
但是,只通過隨機(jī)采樣獲得也有問題,就是會導(dǎo)致模型的精度不足。假如,你要訓(xùn)練一個“相似圖片召回”算法。
當(dāng)x是一只狗時,是另外一只狗。在所有動物圖片中隨機(jī)采樣得到,大概率是到貓、大象、烏鴉、海豚、...。這些隨機(jī)負(fù)樣本,對于讓模型“開眼界,見世面”十分重要,能夠讓模型快速“去偽存真”。 但是貓、大象、烏鴉、海豚、...這樣隨機(jī)的負(fù)樣本,與正樣本相比相差太大,使得模型只觀察到粗粒度就足夠了,沒有動力去注意細(xì)節(jié),所以這些負(fù)樣本被稱為easy negative。 為了能給模型增加維度,迫使其關(guān)注細(xì)節(jié),我們需要讓其見識一些hard negative,比如狼、狐貍、...這種與還有幾分相似的負(fù)樣本
不同的算法,采取不同的方式獲得hard negative,在下文中將會詳細(xì)分析。
Embedding:如何生成向量?
用哪些特征學(xué)出embedding?
有的算法只使用UserId/DocId 有的算法除此之外,還使用了畫像、交互歷史等side information 圖卷積算法還使用了user節(jié)點(diǎn)、item節(jié)點(diǎn)在圖上的連接關(guān)系
通過什么樣的模型學(xué)習(xí)出embedding?
只使用ID特征的算法,模型就只有一個embedding矩陣,通過id去矩陣相應(yīng)行提取embedding 有的模型,將特征(id+side information)喂入DNN,逐層讓特征充分交互,DNN最后一層的輸出就是我們需要的embedding 基于圖卷積的模型中,目標(biāo)節(jié)點(diǎn)(user或item)的embedding,是由其鄰居節(jié)點(diǎn)的embedding,加上節(jié)點(diǎn)本身信息,聚合而成。一來,圖上的節(jié)點(diǎn)不僅有user/item,還可以包括性別、年齡、職業(yè)等屬性節(jié)點(diǎn);二來,鄰居節(jié)點(diǎn)也有自己的鄰居。圖的這種性質(zhì),使得節(jié)點(diǎn)embedding能夠利用的信息更加廣泛,并且兼具本地與全局視角。
召回模型的特點(diǎn):解耦
u2i召回,與排序,雖然都是建模user與item的匹配(match)關(guān)系,但是在樣本、特征、模型上都有顯著不同。在之前的文章中,我詳細(xì)論述了二者在樣本選擇上的區(qū)別,這一節(jié)將論述二者在特征、模型上的區(qū)別。簡言之,就是:排序鼓勵交叉,召回要求解耦。
排序鼓勵交叉
特征上,排序除了利用user feature(包括context)、item feature,最重要還使用了大量的交叉統(tǒng)計(jì)特征,比如“user tag與item tag的重合度”。這類交叉統(tǒng)計(jì)特征是衡量“user與item匹配性”的最強(qiáng)信號,但是也將user feature與item feature緊密耦合在一起。 模型上,排序一般將user feature、item feature、交叉統(tǒng)計(jì)特征拼接成一個大向量,喂入DNN,讓三類特征通過多層全連接層(Fully Connection, FC)進(jìn)行充分交叉。從第一層FC之后,你就已經(jīng)無法分辨,F(xiàn)C的輸出中哪些屬于user信息?哪些屬于item信息?
召回要求解耦
排序之所以允許、鼓勵交叉,還是因?yàn)樗暮蜻x集比較小,最多不過幾千個。換成召回那樣,要面對百萬、千萬級別的海量候選item,如果讓每個user與每個候選item都計(jì)算交叉統(tǒng)計(jì)特征,都過一遍DNN那樣的復(fù)雜操作,是無論如何也無法滿足線上的實(shí)時性要求的。所以,召回要求解耦、隔離user與item特征。
特征上,盡管信號強(qiáng),但是召回不允許使用“交叉統(tǒng)計(jì)特征”。(放棄這么強(qiáng)的信號,的確可惜。如何在不使用交叉統(tǒng)計(jì)特征的情況下,仍然達(dá)到使用了它們的效果?有一種方法是使用蒸餾,詳情見《Privileged Features Distillation at Taobao Recommendations》) 模型上,禁止user feature與item feature出現(xiàn)DNN那樣的多層交叉,二者必須獨(dú)立發(fā)展,i.e., user子模型,利用user特征,生成user embedding;item子模型,利用item特征,生成item embedding。唯一一次user與item的交叉,只允許出現(xiàn)在最后拿user embedding與item embedding做點(diǎn)積計(jì)算匹配得分的時候。
只有這樣,才能允許我們
離線時,在user未知的情況下,獨(dú)立生成item embedding灌入faiss; 在線時,能獨(dú)立生成user embedding,避免與每個候選item進(jìn)行“計(jì)算交叉特征”和“通過DNN”這樣復(fù)雜耗時的操作
Pairwise-loss:如何成對優(yōu)化?
排序階段經(jīng)常遵循"CTR預(yù)估"的方式
樣本上,<>和<>是兩條樣本 loss上使用binary cross-entropy這樣的pointwise loss
能夠這么做的前提是,其中的<>是“曝光過但未點(diǎn)擊”的“真負(fù)”樣本,label的準(zhǔn)確性允許我們使用pointwise loss追求“絕對準(zhǔn)確性”。
但是在召回場景下,以上前提并不成立。以常見的u2i召回為例,絕大多數(shù)item從未給user曝光過,我們再從中隨機(jī)采樣一部分作為負(fù)樣本,這個negative label是存在噪聲的。在這種情況下,再照搬排序使用binary cross-entropy loss追求“預(yù)估值”與“l(fā)abel”之間的“絕對準(zhǔn)確性”,就有點(diǎn)強(qiáng)人所難了。所以,召回算法往往采用Pairwise LearningToRank(LTR),建模“排序的相對準(zhǔn)確性”:
樣本往往是<>的三元組形式 模型的優(yōu)化目標(biāo)是,針對同一個user,與他的匹配程度,要遠(yuǎn)遠(yuǎn)高于,與他的匹配程度。所以Loss中沒有l(wèi)abel,而存在“<>的匹配分”與“<>的匹配分”相互比較的形式。
為了實(shí)現(xiàn)Pairwise LTR,有幾種Loss可供選擇。
一種是sampled softmax loss。
這種loss將召回看成一個超大規(guī)模的多分類問題,優(yōu)化的目標(biāo)是使,user選中item+的概率最高。 user選中item+的概率=,其中是user embedding,代表item embedding,代表整個item候選集。 為使以上概率達(dá)到最大,要求分子,即user與item+的匹配度,盡可能大;而分母,即user與除item+之外的所有item的匹配度之和,盡可能小。體現(xiàn)出上文所說的“不與label比較,而是匹配得分相互比較”的特點(diǎn)。 但是,由于計(jì)算分配牽扯到整個候選item集合,計(jì)算量大到不現(xiàn)實(shí)。所以實(shí)際優(yōu)化的是sampled softmax loss,即從中隨機(jī)采樣若干,近似代替計(jì)算完整的分母。
另一種loss是margin hinge loss,
優(yōu)化目標(biāo)是:user與正樣本item的匹配程度,要比,user與負(fù)樣本item的匹配程度,高出一定的閾值。 即,=
因?yàn)閙argin hinge loss多出一個超參margin需要調(diào)節(jié),因此我主要使用如下的BPR Loss。
其思想是計(jì)算"給user召回時,將item+排在item-前面的概率", 因?yàn)?lt;user, item+, item->的ground-truth label永遠(yuǎn)是1,所以將喂入binary cross-entropy loss的公式,就有=
注意,為了方便行文,以上公式都是針對u2i召回的舉例,但是u2u, i2i召回也具備類似的公式。
用NFEP理解典型向量化召回算法
本節(jié)將從NFEP框架的視角,來理解幾種主流、經(jīng)典的召回算法,看看這些算法是在哪些維度上進(jìn)行了創(chuàng)新,存在哪些內(nèi)在聯(lián)系。
Airbnb召回算法
《Real-time Personalization using Embeddings for Search Ranking at Airbnb》是一篇經(jīng)典論文,其中介紹了listing embedding和user/listing-type embedding兩種召回算法。
listing embedding召回
listing就是Airbnb中的房源,所以基于listing embedding的召回,本質(zhì)就是一個i2i召回。
Near
本來是想照搬word2vec,將用戶的點(diǎn)擊序列看成一個句子,認(rèn)為一個滑窗內(nèi)的兩個相鄰listing是相似的,它們的embedding應(yīng)該接近。
但是仔細(xì)想想,以上想法存在嚴(yán)重問題
word2vec建模的是語言模型的“共現(xiàn)性”,即哪些詞語經(jīng)常一起出現(xiàn),因此需要一個滑動窗口限制距離 而這里,我們建模的是listing之間的相似性,難道只有相鄰listing之間存在相似性?一個點(diǎn)擊序列首尾的兩個listing就不相似了嗎?
所以,理想情況下,一個序列中任意兩個listing,它們的embedding都應(yīng)該是相近的。但是在實(shí)踐中發(fā)現(xiàn),這樣的組合太多,所以Airbnb還是退回到word2vec的老路,即還是只拿一個滑窗內(nèi)的中心listing與鄰居listing組成正樣本對。但是由于“最終成功預(yù)訂”的那個listing有最強(qiáng)的業(yè)務(wù)信號,所以我們拿它與點(diǎn)擊序列中的每個listing組成正樣本對。這也就是Airbnb論文中“增加final booked listing作為global context加入每個滑窗”的原因。
Far
絕大部分負(fù)樣本還是隨機(jī)采樣生成的。但是,Airbnb發(fā)現(xiàn),用戶點(diǎn)擊序列中的listing多是同城的,導(dǎo)致正樣本多是同城listing組成,而隨機(jī)采樣的負(fù)樣本多是異地的,這其中存在的bias容易讓模型只關(guān)注“地域”這個粗粒度特征。
為此,Airbnb在全局隨機(jī)采樣生成的負(fù)樣本之外,還在與中心listing同城的listing中隨機(jī)采樣一部分listing作為hard negative,以促使模型能夠關(guān)注除“地域”外的更多其他細(xì)節(jié)。
Embedding
特征只用了listing ID,模型也只不過是一個大的embedding矩陣而已。缺點(diǎn)是對于新listing,其id不在embedding矩陣中,無法獲得embedding。
Pairwise-loss
使用sampled softmax loss。
user/listing-type embedding召回
Near
這個所謂的用user-type去召回listing-type,實(shí)際上就是u2i召回,只不過Airbnb覺得預(yù)訂行為太稀疏,所以將相似的user聚類成user-type,把相似的listing聚類成listing-type。
既然如此,"Near"步驟與一般的u2i召回,別無二致。即,如果某user預(yù)訂過某listing,那么該user所屬的user-type,與該listing所屬的listing-type就應(yīng)該是相近的。
Far
絕大部分負(fù)樣本還是隨機(jī)采樣生成的。除此之外,增加“被owner拒絕”作為hard negative,表達(dá)一種非常強(qiáng)烈的“user~item不匹配”。
Embedding
特征只有user-type ID和listing-type ID,模型也只不過拿ID當(dāng)行號去embedding矩陣中抽取embedding。
Pairwise-loss
使用sampled softmax loss。
點(diǎn)評
Airbnb的兩個算法,在Embedding和Pairwise-loss兩個步驟上,都是標(biāo)準(zhǔn)操作,平淡無奇。
由于Airbnb論文的話術(shù)向word2vec“生搬硬套”,給人一種感覺,在學(xué)習(xí)listing embedding時增加final booked listing作為global context加入每個滑窗,在學(xué)習(xí)user/listing-type embedding時將user-type和listing-type組成異構(gòu)序列,都是腦洞大開的創(chuàng)新。但從Near的角度來看
word2vec建模的是詞語間的“共現(xiàn)性”,listing embedding建模的是一個session中任意兩個listing之間的“相似性”,而user/listing-type embedding建模的是user和listing之間的“匹配性”,三者的目標(biāo)截然不同。 序列、滑窗只是word2vec刻畫“共現(xiàn)性”所獨(dú)有的概念,完全沒必要出現(xiàn)在學(xué)習(xí)listing embedding和user/listing-type embedding的過程中。 學(xué)習(xí)listing embedding時增加final booked listing作為global context,與其說是創(chuàng)新,不如說是考慮計(jì)算量之后的一種折中方案。 讓user type和其預(yù)訂過的listing type組成正樣本對,從“匹配性”的角度來看,天經(jīng)地義,完全沒必要像論文中那樣組成user+listing異構(gòu)序列,從“共現(xiàn)性”的角度來解釋。
在Far這個維度,Airbnb增加“同城負(fù)樣本”和“owner拒絕負(fù)樣本”,是根據(jù)業(yè)務(wù)邏輯增加hard negative的典型代表。
Youtube召回算法
Youtube在《Deep Neural Networks for YouTube Recommendations》一文中介紹的基于DNN的召回算法,非常經(jīng)典,開DNN在召回中應(yīng)用之先河,被業(yè)界模仿。
Near
u2i召回的典型思路:user與其觀看過的視頻,在向量空間中是相近的。
Far
論文中只提到了隨機(jī)負(fù)采樣,沒有提到如何打壓熱門視頻,也沒有提到如何增加hard negative。
Embedding
user embedding 用戶看過的視頻的embedding,pooling成一個向量 用戶搜索的關(guān)鍵詞的embedding,pooling成一個向量 以上兩個向量,加上一些用戶的基本屬性,拼接成一個大向量,喂入多層全連接(FC)進(jìn)行充分交叉 最后一層FC的輸出就是user embedding video embedding 特征只用了video id,模型也只不過是一個大的embedding矩陣 整個模型在兩個地方要用到video embedding,一個自然是最后計(jì)算user embedding與video embedding點(diǎn)積作為匹配分的時候要用到,另一處是用戶看過的視頻的embedding要參與生成user embedding 這兩處video embedding是否需要共享?原文中沒有詳細(xì)說明。我是偏向于共享的,一來降低模型規(guī)模,二來增加一些冷門video得到訓(xùn)練的機(jī)會。
Pairwise-loss
使用sampled softmax loss。
Facebook的EBR算法
Facebook在《Embedding-based Retrieval in Facebook Search》一文中介紹的算法。如果想了解更多的技術(shù)細(xì)節(jié),請參考我的另一篇文章《負(fù)樣本為王:評Facebook的向量化召回算法》
Near
u2i召回的典型思路:user與其觀看過的視頻,在向量空間中是相近的。
Far
絕大部分負(fù)樣本依然是通過隨機(jī)采樣得到的。論文明確提出了,召回算法不應(yīng)該拿“曝光未點(diǎn)擊”做負(fù)樣本。
另外,本文最大的貢獻(xiàn)是提供了兩種挑選hard negative的方案。Facebook的EBR與百度Mobius的作法非常相似,都是用上一版本的召回模型篩選出"沒那么相似"的<user,item>對,作為額外負(fù)樣本,來增強(qiáng)訓(xùn)練下一版本召回模型。具體做法上,又分online和offline兩個版本
在線篩選 假如一個batch有n個正樣本對,<>,那么的hard negative是利用上一輪迭代得到的召回模型,評估與同一個batch的除之外的所有的匹配度,再選擇一個與最相似的作為hard negative。 文章還提到,一個正樣本最多配置2個這樣的hard negative,配置多了反而會有負(fù)向效果。 缺點(diǎn)是僅僅采用一個batch中的item作為hard negative的候選集,規(guī)模太小,可能還不足夠hard。 離線篩選 拿當(dāng)前的召回模型,為每個候選item生成item embedding,灌入FAISS 拿當(dāng)前的召回模型,為每個user生成user embedding,在FAISS中檢索出top K條近鄰item 這top K條近鄰item中,排名靠前的是positive,排名靠后的是easy negative,只有中間區(qū)域(Facebook的經(jīng)驗(yàn)是101-500)的item可以作為hard negative。 將hard negative與隨機(jī)采樣得到的easy negative混合。畢竟線上召回時,候選庫里還是以easy negative為主,所以作者將比例維持在easy:hard=100:1 拿增強(qiáng)后的負(fù)樣本,訓(xùn)練下一版召回模型。
Embedding
模型采用經(jīng)典的雙塔模型。雙塔模型鮮明體現(xiàn)了前文所述的“召回要求解耦”的特點(diǎn):
模型不會將user feature與item feature接入一個DNN,防止它們在底層就出現(xiàn)交叉 user特征,通過user tower獨(dú)立演進(jìn),生成user embedding item特征,通過item tower獨(dú)立演進(jìn),生成item embedding 唯一一次user與item的交叉,只允許出現(xiàn)在最后拿user embedding與item embedding做點(diǎn)積計(jì)算匹配得分的時候
只有這樣,才能允許我們
離線時,在user未知的情況下,只使用item tower,獨(dú)立生成item embedding灌入faiss; 在線時,只使用user tower獨(dú)立生成user embedding,避免與每個候選item進(jìn)行“計(jì)算交叉特征”和“通過DNN”這樣復(fù)雜耗時的操作

Pairwise-loss
使用margin hinge loss
Pinterest的PinSAGE
Pinterest 推出的基于 GCN 的召回算法 PinSAGE,被譽(yù)為"GCN 在工業(yè)級推薦系統(tǒng)上的首次成功運(yùn)用"。對技術(shù)細(xì)節(jié)感興趣的同學(xué),推薦讀我的另一篇文章《PinSAGE 召回模型及源碼分析》。
Near
和Airbnb一樣,我們可以認(rèn)為被同一個user消費(fèi)過的兩個item是相似的,但是這樣的排列組合太多了。
為此,PinSAGE采用隨機(jī)游走的方式進(jìn)行采樣:在原始的user-item二部圖上,以某個item作為起點(diǎn),進(jìn)行一次二步游走(item→user→item),首尾兩端的item構(gòu)成一條邊。將以上二步游走反復(fù)進(jìn)行多次,就構(gòu)成了item-item同構(gòu)圖。
在這個新構(gòu)建出來的item-item同構(gòu)圖上,每條邊連接的兩個item,因?yàn)楸煌粋€user消費(fèi)過,所以是相似的,構(gòu)成了訓(xùn)練中的正樣本。
Far
PinSAGE提供了一種基于隨機(jī)游走篩選hard negative的方法。
在訓(xùn)練開始前, 從item-item圖上的某個節(jié)點(diǎn)u,隨機(jī)游走若干次。 游走過程中遍歷到的每個節(jié)點(diǎn)v,都被賦予一個分?jǐn)?shù)L1-normalized visit count=該節(jié)點(diǎn)被訪問到的次數(shù) / 隨機(jī)游走的總步數(shù)。 這個分?jǐn)?shù),被視為節(jié)點(diǎn)v針對節(jié)點(diǎn)u的重要性,即所謂的Personal PageRank(PPR)。 訓(xùn)練過程中 針對item-item同構(gòu)圖上的某一條邊u→v,u和v就構(gòu)成了一條正樣本,它們的embedding應(yīng)該相近 在圖上所有節(jié)點(diǎn)中隨機(jī)采樣一部分ne,u和每個ne就構(gòu)成了一條負(fù)樣本,它們的embedding應(yīng)該比較遠(yuǎn)。因?yàn)槭请S機(jī)采樣得到的,所以ne是easy negative。 除此之外,還將u所有的鄰居,按照它們對u的重要性(PPR)從大到小排序,篩選出排名居中(e.g.論文中是2000~5000名)的那些item。這些item與u有幾分相似,但是相似性又沒那么強(qiáng),從中再抽樣一批item,作為"u"的hard negative。
Embedding
每個item embedding通過圖卷積的方式生成。圖卷積的核心思想就是:利用邊的信息對節(jié)點(diǎn)信息進(jìn)行聚合從而生成新的節(jié)點(diǎn)表示。多層圖卷積的公式如下所示。
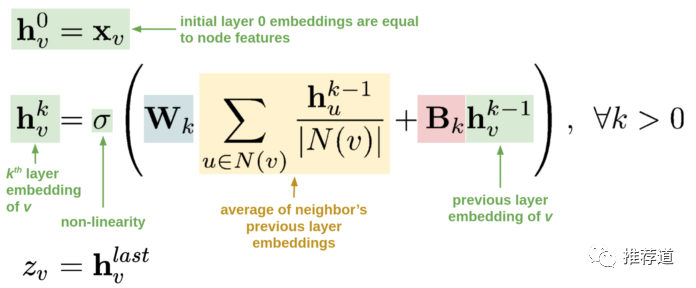
第一行,說明各節(jié)點(diǎn)的初始表示,就等同于各節(jié)點(diǎn)自身的特征。這時還沒有用上任何圖的信息。 第二行,第 k 層卷積后,各節(jié)點(diǎn)的表示, 和兩部分有關(guān) 第一部分,括號中藍(lán)色+黃色部分,即先聚合當(dāng)前節(jié)點(diǎn)的鄰居的第 k-1 層卷積結(jié)果(),再做線性變換。這時就利用上了圖的信息,即某節(jié)點(diǎn)的鄰居節(jié)點(diǎn)上的信息沿邊傳遞到該節(jié)點(diǎn)并聚合(也就是卷積) 第二部分,括號中紅色+綠色部分,即拿當(dāng)前節(jié)點(diǎn)的第 k-1 層卷積結(jié)果(),做線性變換 可以看到,如果不考慮括號中的第一部分,這個公式簡化為,是不是很眼熟?這不就是傳統(tǒng)的 MLP 公式嗎?所以,圖卷積的思想很簡單,就是每層在做非線性變換之前,每個節(jié)點(diǎn)先聚合一次鄰居的信息。 第三行,最后一層卷積后的結(jié)果,成為各節(jié)點(diǎn)最終向量表示,用于計(jì)算兩節(jié)點(diǎn)存在邊的可能性。
Parwise-loss
使用margin hinge loss。
微信的GraphTR
這是我見過的最復(fù)雜的生成embedding的算法,沒有之一。
Near
就是傳統(tǒng)i2i召回的思路,在一個session內(nèi)被觀看的多個video之間是相似的,它們的embedding接近。
Far
就是隨機(jī)負(fù)采樣那一套,文中沒有涉及打壓熱門視頻,也沒有涉及篩選hard negative。
Embedding
與上邊介紹過的PinSAGE建立在item-item的同構(gòu)圖上有所不同,GraphTR建立在包括了user, video, tag, media (視頻來源)這4類節(jié)點(diǎn)(每類稱作一個域)的異構(gòu)圖上。每個節(jié)點(diǎn)要聚合來自多個領(lǐng)域的異構(gòu)消息。
為了防止異構(gòu)消息相互抵銷而引入信息損失,GraphTR利用了三種聚合方式,從三種不同粒度對于不同類型的鄰居節(jié)點(diǎn)上的信息進(jìn)行聚合
將各域鄰居節(jié)點(diǎn)的embedding拼接成一個大向量,按照傳統(tǒng)的GraphSAGE方式聚合。這種聚合方式,不區(qū)分域,粒度最粗。 接下來的FM聚合,細(xì)致了一些,讓不同域的鄰居信息之間的兩兩交叉。 最后的Transformer聚合方式,粒度最細(xì),不僅考慮了不同域之間的交叉,還考慮了一個域內(nèi)部多個鄰居節(jié)點(diǎn)之間的交叉。
為了生成item embedding,使用了GraphSAGE+FM+Transformer三種大殺器,是我見過的最復(fù)雜的向量化召回算法。對技術(shù)細(xì)節(jié)感興趣的同學(xué),可以參考我的另一篇文章《GraphSAGE+FM+Transformer強(qiáng)強(qiáng)聯(lián)手:評微信的GraphTR模型》。
Pairwise-loss
sampled softmax loss
FM召回
與風(fēng)頭正勁的眾多基于DNN/GNN的召回算法相比,F(xiàn)M召回算法,如今不太引人注目。但是,FM召回性能優(yōu)異,便于上線和解釋,而且對冷啟動新用戶或新物料都非常友好,仍然不失為召回算法中的一把利器。
Near
u2i召回的典型思路:user與其消費(fèi)過的item,在向量空間中是相近的。
Far
絕大部分負(fù)樣本還是隨機(jī)采樣生成的。同時在隨機(jī)采樣的過程中,要注意打壓熱門item,具體細(xì)節(jié),見的我的知乎回答《推薦系統(tǒng)傳統(tǒng)召回是怎么實(shí)現(xiàn)熱門item的打壓?》
至于如何增加hard negative來提高模型的精度,可以參考Facebook EBR中在線與離線篩選hard negative的做法。
Embedding
以上介紹的所有u2i召回(e.g, Youtube召回、Facebook EBR),召回的依據(jù)都只是user embedding與item embedding的點(diǎn)積,即只考慮了user與item的匹配程度。但是,在一個實(shí)際的推薦系統(tǒng)中,用戶喜歡的未必一定是與自身最匹配的,也包括一些自身性質(zhì)極佳的item(e.g.,熱門視頻、知名品牌的商品、著名作者的文章)。所以,我們在給某對兒<user,item>打分時,除了user/item的匹配度,還需要考慮item本身的受歡迎程度。
在FM召回中增加item自身得分非常簡單,只需要將user embedding和item embedding都增廣一維,如下圖所示。其中是某user包含的所有特征embedding之和,是某Item包含的所有特征embedding之和。

具體公式細(xì)節(jié),請參考我的文章《FM:推薦算法中的瑞士軍刀》中的FM召回一節(jié)。需要特別指出的是,這種通過向量增廣考慮“item本身的受歡迎程度”的做法,同樣適用于其他u2i召回算法(e.g.,e.g, Youtube召回、Facebook EBR),有助于提高它們的精度。
Pairwise-loss
在我的實(shí)現(xiàn)中,我使用了BRP loss。
總結(jié)
從NFEP框架視角來理解向量化召回算法,各算法的特點(diǎn)梳理如下表所示。
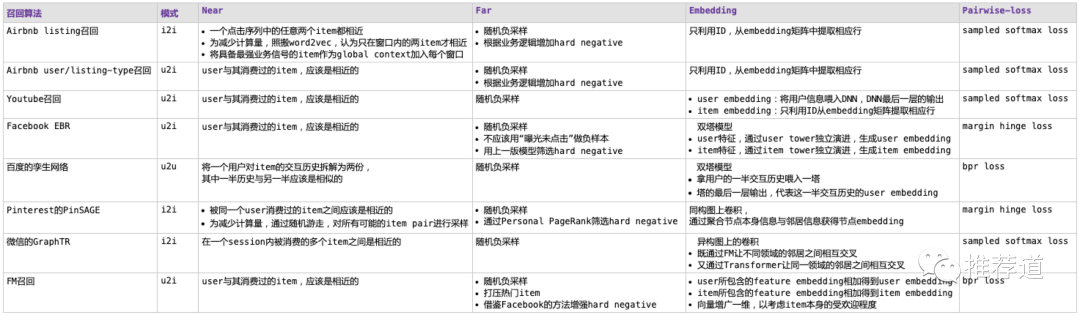
可以看到,通過NFEP框架的梳理,各召回算法間的異同變得清晰,便于我們加深理解,融會貫通。
而當(dāng)你為自己的召回項(xiàng)目選型的時候,你可能希望實(shí)現(xiàn)雙塔模型,還希望模仿Facebook的做法來增強(qiáng)hard negative,同時還要像FM召回一樣將“item本身受歡迎程度”考慮在內(nèi)。借助NFEP框架的梳理,我們可以更好地取長補(bǔ)短,設(shè)計(jì)出最適合你的業(yè)務(wù)場景、數(shù)據(jù)環(huán)境的召回算法。
- END -