
女媧算法,殺瘋了!
大家好,我是周末加班寫技術(shù)文的 Jack。
今天分享一個「多模態(tài)」算法 NüWA(女媧)。
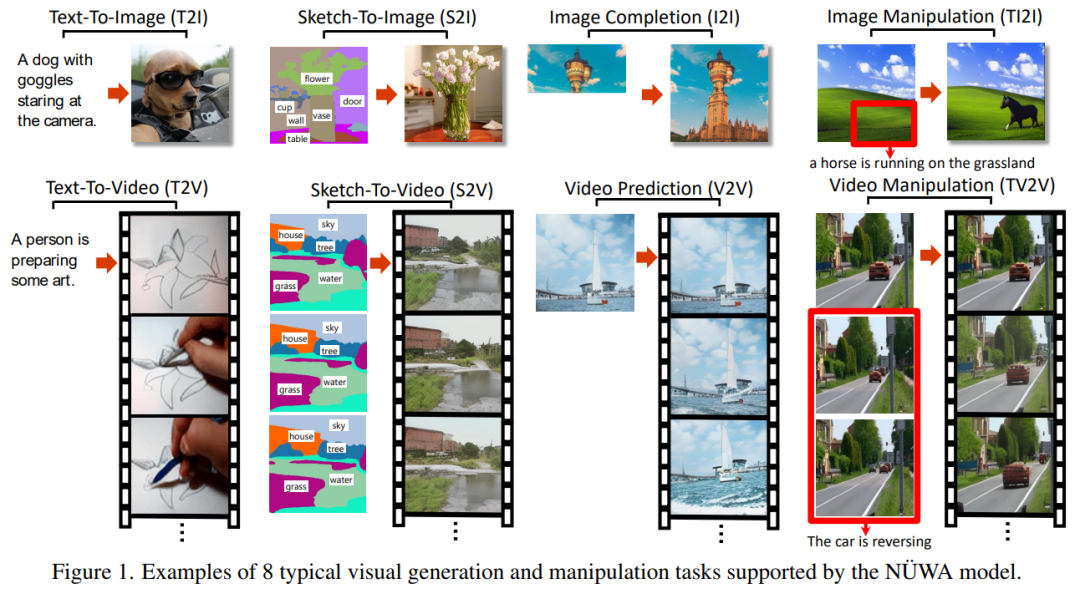
論文的開頭,就放出了效果,NüWA 包攬了 8 項(xiàng)經(jīng)典的視覺生成任務(wù)的 SOTA。
論文表示,NüWA 更是在文本到圖像生成中“完虐” OpenAI DALL-E。
碾壓各種對比的算法效果,殺瘋了!
NüWA 效果
我們先看下 NüWA 這算法在 8 項(xiàng)經(jīng)典的視覺生成任務(wù)中的表現(xiàn)。
Text-To-Image(T2I)
文字轉(zhuǎn)圖片任務(wù),其實(shí)就是根據(jù)一段文字描述,生成對應(yīng)描述的圖片。
比如:
A dog with gogglesstaring at the camera.
一只戴著護(hù)目鏡,盯著攝像機(jī)的狗。

還有更多效果:

NüWA 生成的效果看起來就沒那么違和,從論文的效果看,很真實(shí)!

效果非常 Amazing。
Sketch-To-Image (S2I)
草圖轉(zhuǎn)圖片任務(wù),就是根據(jù)草圖的布局,生成對應(yīng)的圖片。
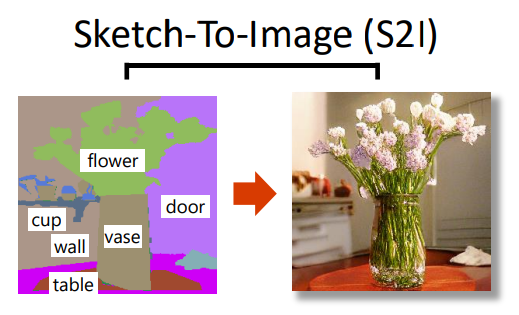
比如:
在一張圖片上,畫個大致輪廓,就可以自動“腦補(bǔ)”圖片。
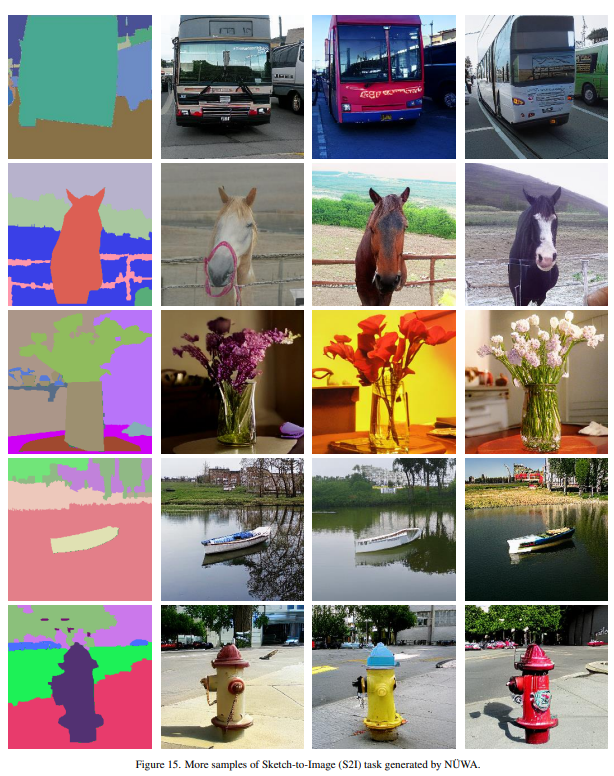
這效果真是開了眼了,真實(shí)效果真如論文這般的話,那確實(shí)很強(qiáng)。

這個算法,可以用在很多有意思的場景。
Image Completion (I2I)
圖像補(bǔ)全,如果一副圖片殘缺了,算法可以自動“腦補(bǔ)”出殘缺的部分。

好家伙,是不是又有一些大膽的想法了?
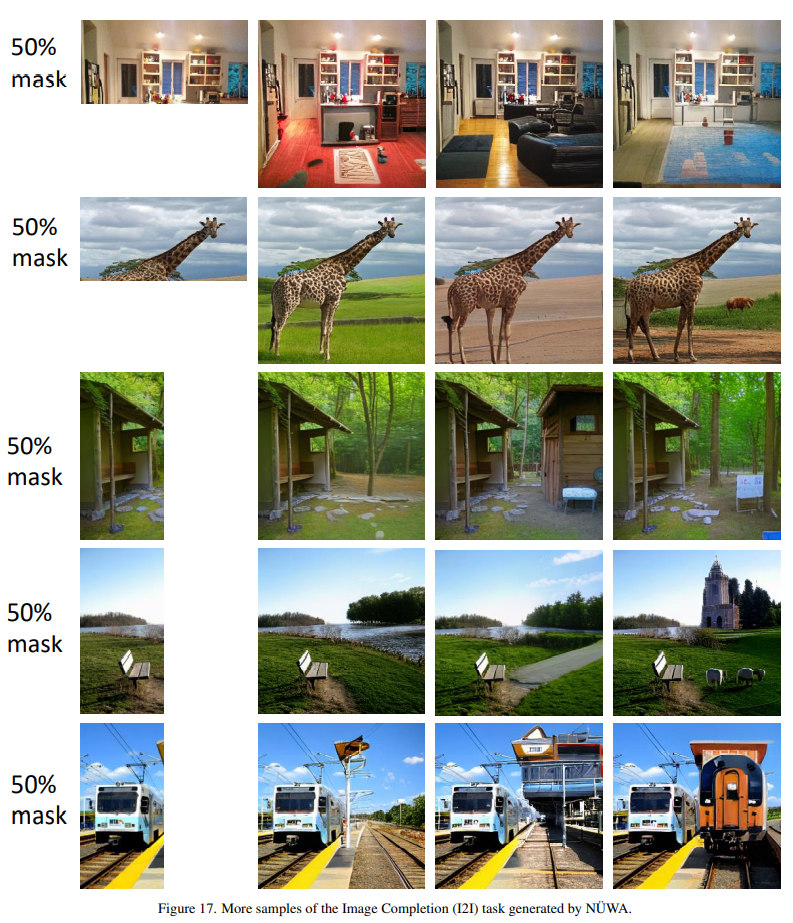
這個遮擋還算可以,還有更細(xì)碎的。
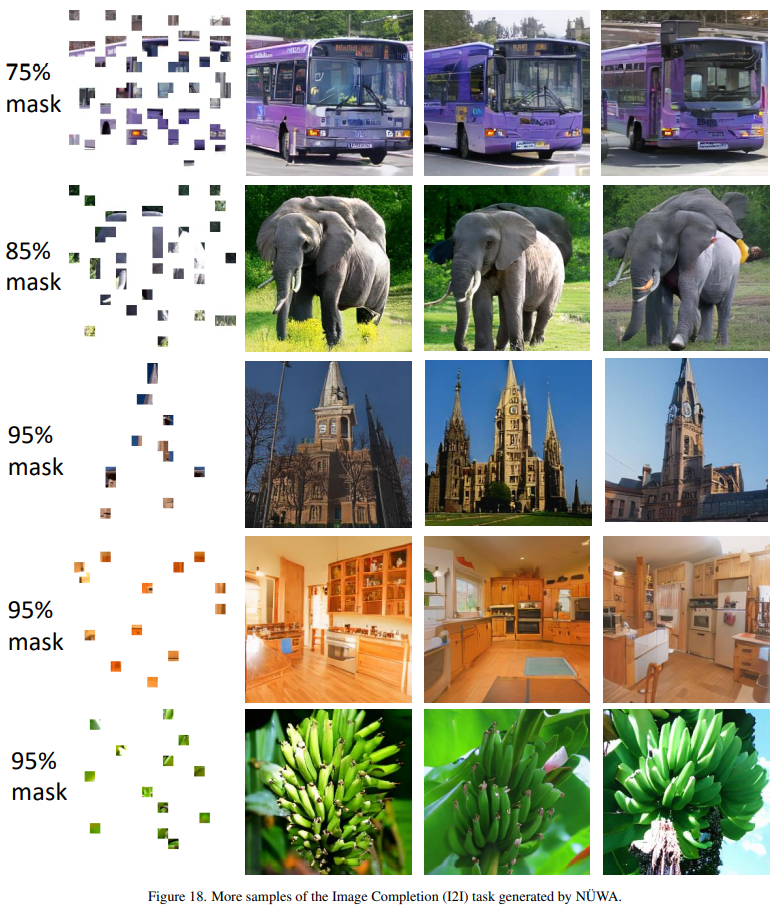
圖片碎成這樣,還能“腦補(bǔ)”出畫面,我很期待代碼。
Image Manipulation (TI2I)
圖片處理,根據(jù)文字描述,處理圖片。
比如:
有一副草原的圖片,然后增加一段描述:
a horse is running on the grassland
一匹馬奔跑在草原上,然后就可以生成對應(yīng)的圖片。

這驚人的理解力。
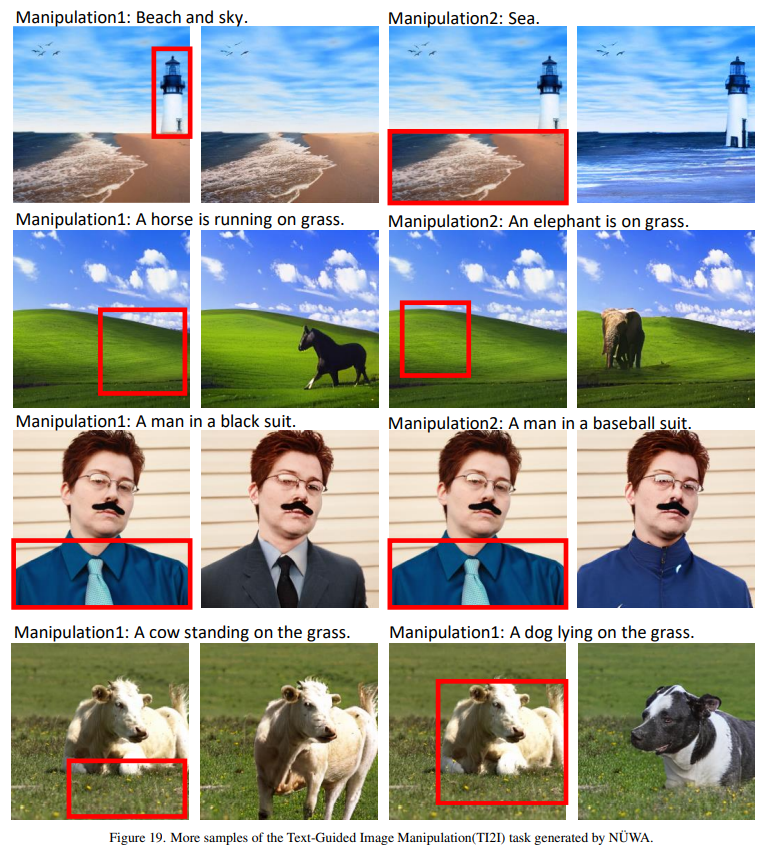
這讓我想起來了 P 圖吧大神,惡搞的作品。
有了這個算法,咱也可以試一試了,哈哈。
Video
這還不算完,除了上述的生成圖片的四種效果,NüWA 還可以生成視頻!
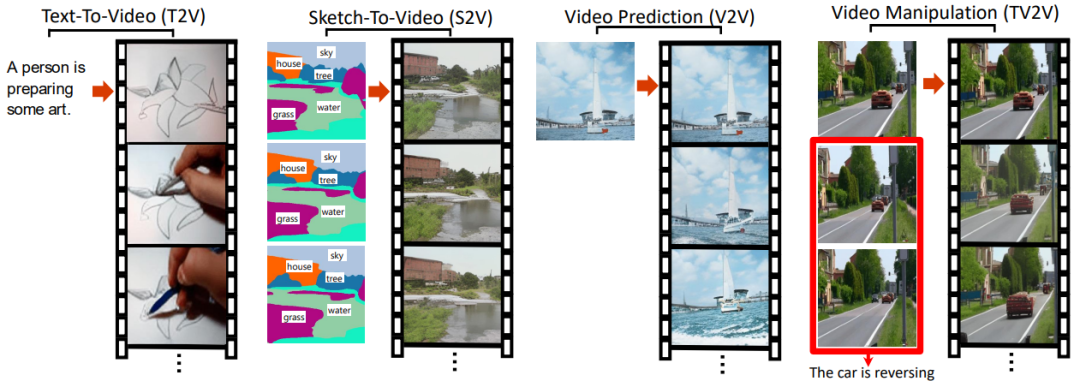
對應(yīng)的四種視頻生成任務(wù):
Text-To-Video (T2V) Sketch-To-Video (S2V) Sketch-To-Video (S2V) Video Manipulation (TV2V)
既可以玩圖片又可以玩視頻。

NüWA 原理
NüWA模型的整體架構(gòu)包含一個支持多種條件的 adaptive 編碼器和一個預(yù)訓(xùn)練的解碼器,能夠同時使圖像和視頻的信息。
對于圖像補(bǔ)全、視頻預(yù)測、圖像處理和視頻處理任務(wù),將輸入的部分圖像或視頻直接送入解碼器即可。
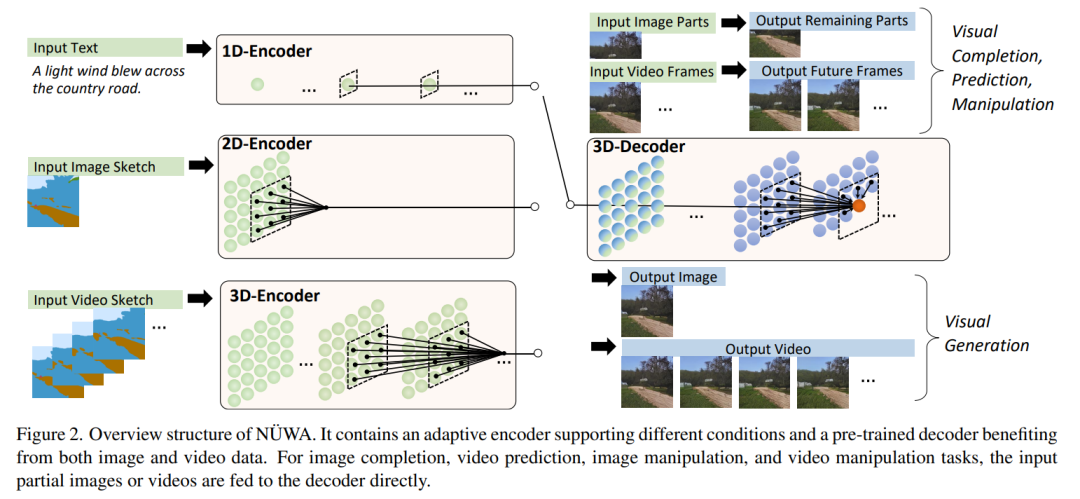
而編碼解碼器都是基于一個3D Nearby的自注意力機(jī)制(3DNA)建立的,該機(jī)制可以同時考慮空間和時間軸的上局部特性,定義如下:
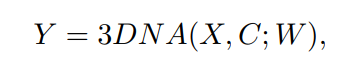
W 表示可學(xué)習(xí)的權(quán)重,X 和 C 分別代表文本、圖像、視頻數(shù)據(jù)的 3D 表示。
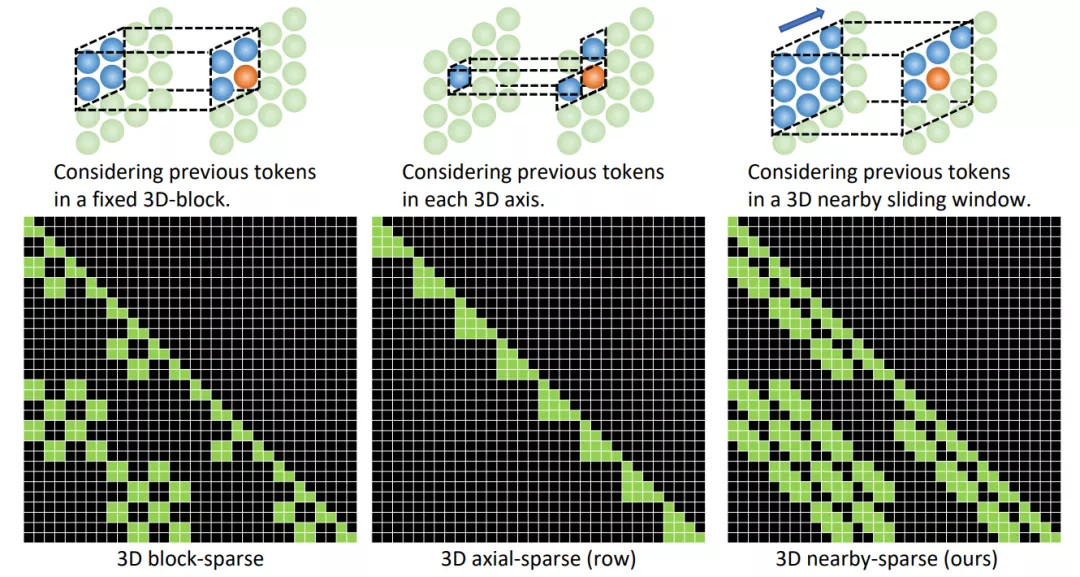
3DNA 考慮了完整的鄰近信息,并為每個 token 動態(tài)生成三維鄰近注意塊。注意力矩陣還顯示出 3DNA 的關(guān)注部分(藍(lán)色)比三維塊稀疏注意力和三維軸稀疏注意力更平滑。
更多細(xì)節(jié),可以直接看論文:
論文地址:
https://arxiv.org/abs/2111.12417
NüWA 代碼
NüWA 的代碼還沒有開源,不過 Github 已經(jīng)建立。
Github:
https://github.com/microsoft/NUWA
作者表示,很快就會開源:
公司有開源審批流程,代碼也得梳理下,所以可以先 Star 上標(biāo)記下,耐心等等。
微軟亞研院和北大聯(lián)合打造的一個多模態(tài)預(yù)訓(xùn)練模型 NüWA,在首屆微軟峰會上亮相過。
這種應(yīng)該不會鴿的~
總結(jié)
今年算是多模態(tài) Transformer 大力發(fā)展的一年,從各種頂會的論文就能看出,各種多模態(tài)。
就聊這么多吧,今天寫完技術(shù)文,我繼續(xù)做視頻了。
我是 Jack,我們下期見~

推薦閱讀
?? ?這個項(xiàng)目,我能玩一年?? ?這兩個練手項(xiàng)目,我王多魚投了????從高考到程序員的成長之路