
女媧算法,殺瘋了!

源?/?? ? ? ??文/?
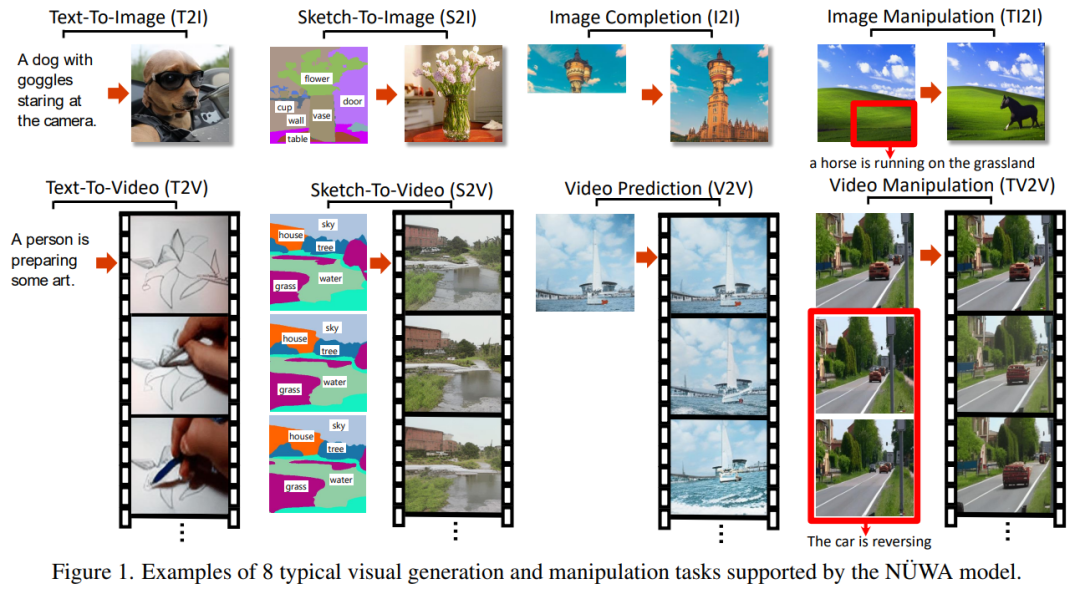
NüWA 效果
Text-To-Image(T2I)
A dog with gogglesstaring at the camera.


Sketch-To-Image (S2I)
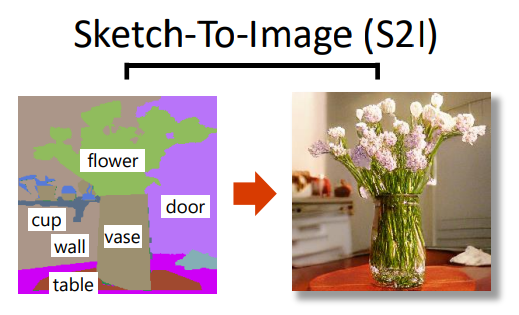
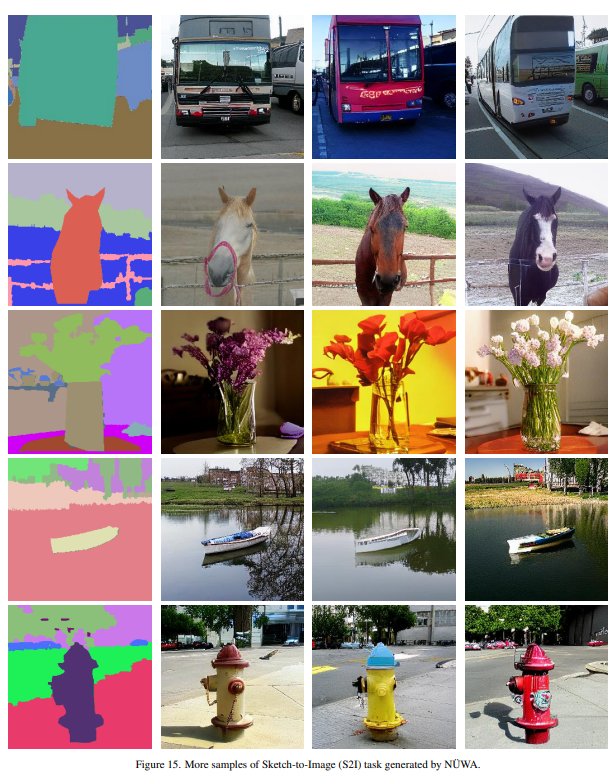

Image Completion (I2I)

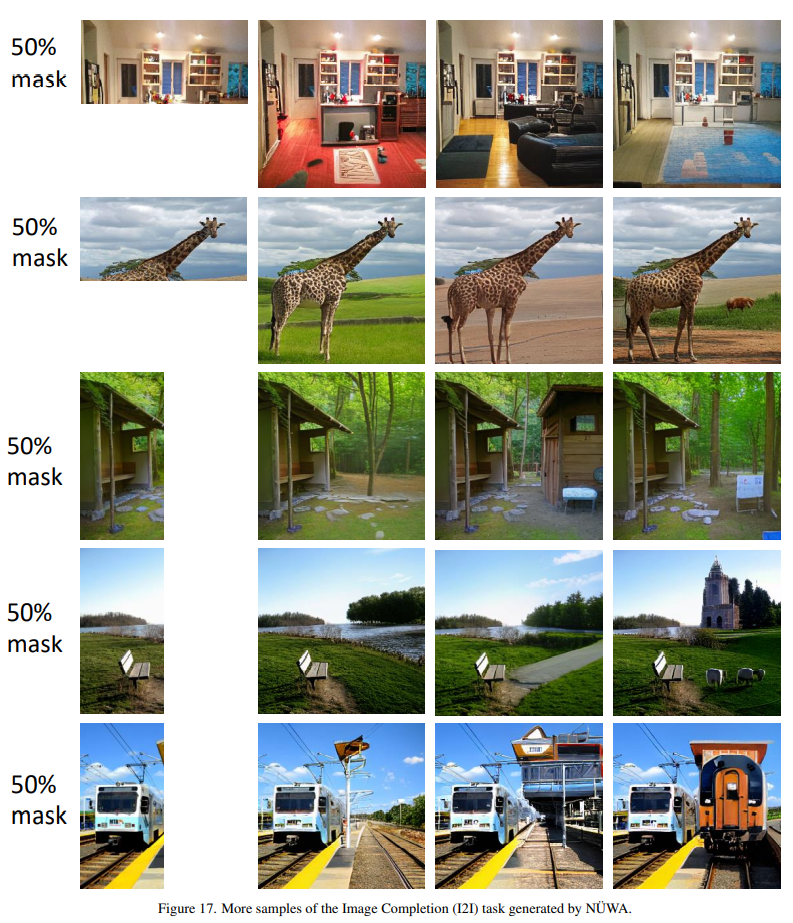
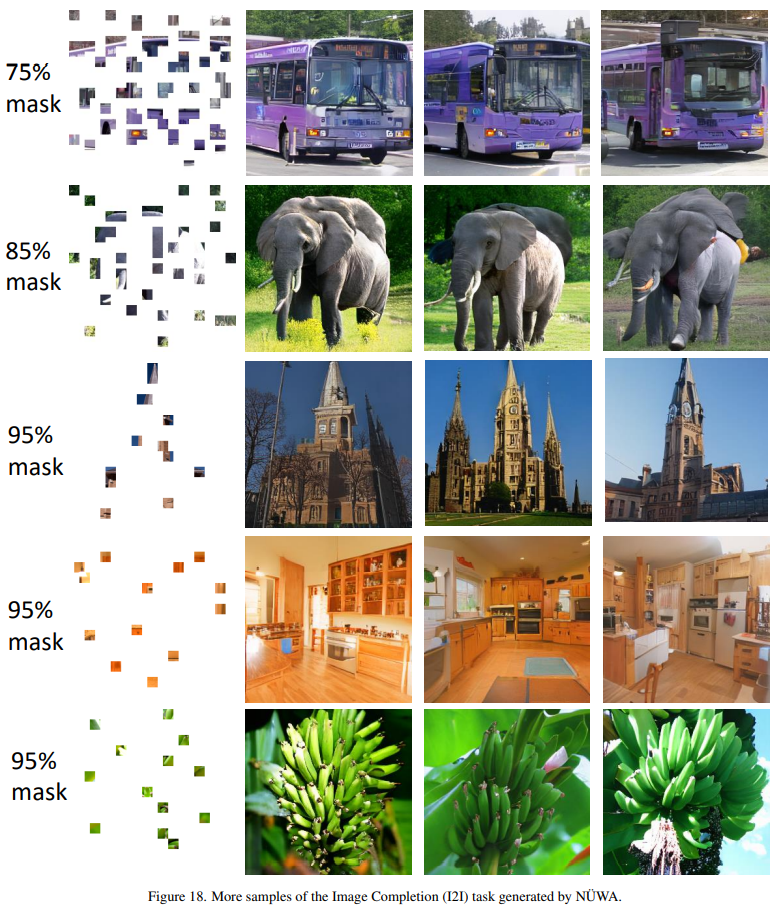
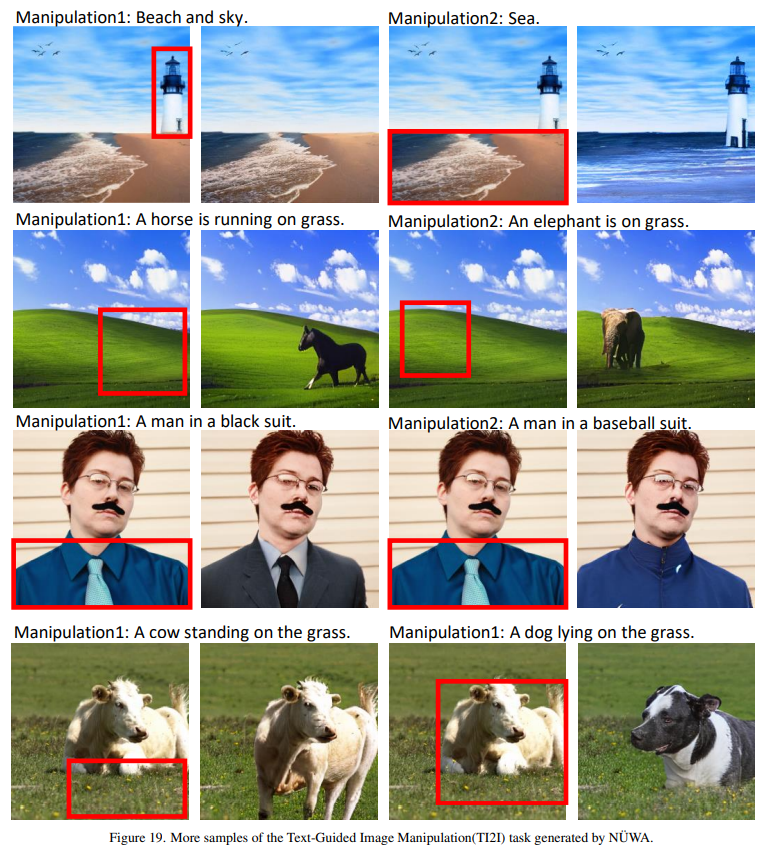
Image Manipulation (TI2I)
a horse is running on the grassland
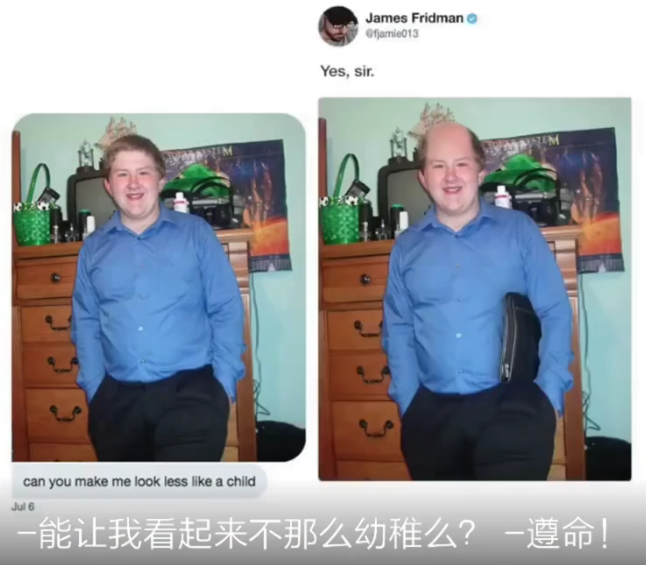
Video
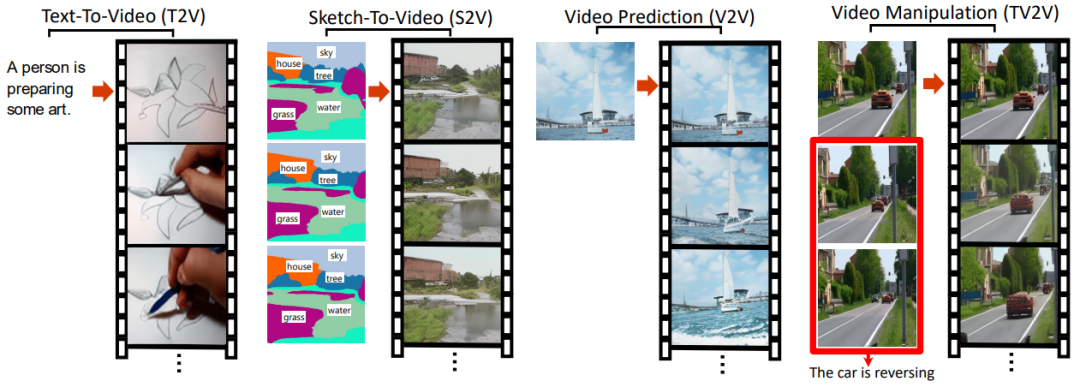
Text-To-Video (T2V) Sketch-To-Video (S2V) Sketch-To-Video (S2V) Video Manipulation (TV2V)

NüWA 原理
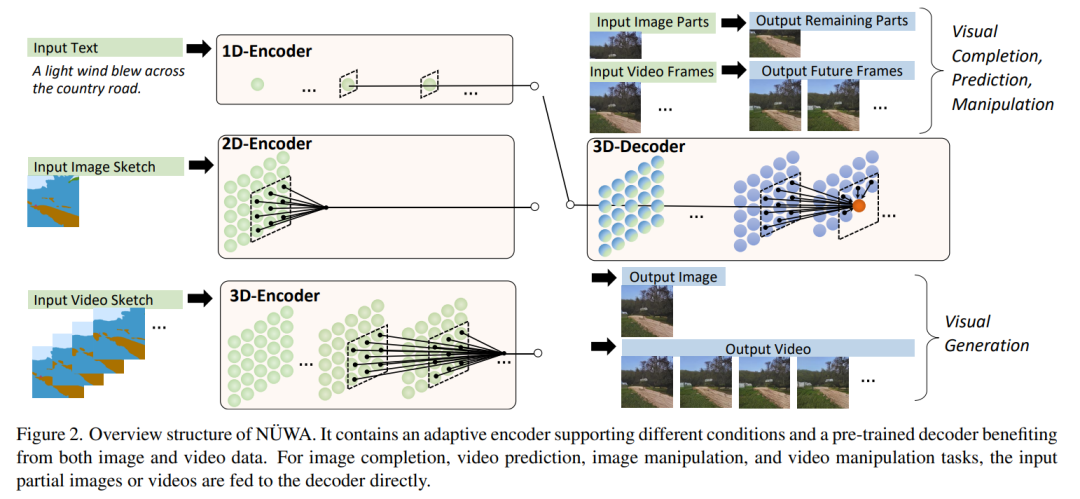
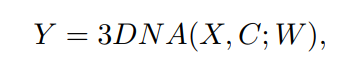
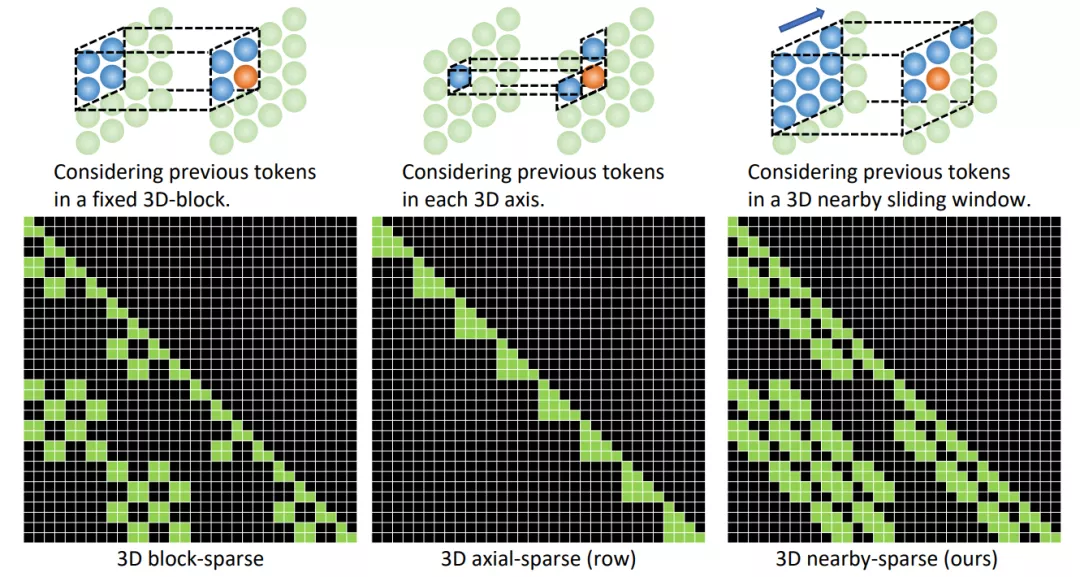
論文地址: https://arxiv.org/abs/2111.12417
NüWA 代碼
Github: https://github.com/microsoft/NUWA
總結(jié)
END


頂級(jí)程序員:topcoding
做最好的程序員社區(qū):Java后端開發(fā)、Python、大數(shù)據(jù)、AI
一鍵三連「分享」、「點(diǎn)贊」和「在看」
評(píng)論
圖片
表情