
一文讀懂自動駕駛中基于特征點的視覺全局定位技術(shù)
來自于點擊下方卡片,關(guān)注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達


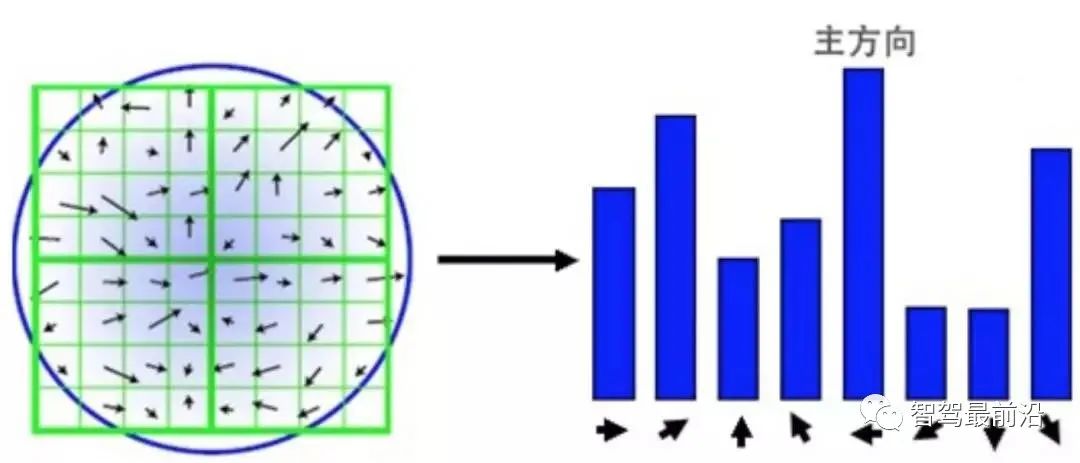
 ?維描述子?
?維描述子? ?通過?
?通過?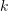 ?個碼詞的碼本進行編碼,可以形成一個?
?個碼詞的碼本進行編碼,可以形成一個? ?維的描述向量,向量中的值是描述子與第??個碼詞在第??維的差。之后進行?
?維的描述向量,向量中的值是描述子與第??個碼詞在第??維的差。之后進行? ?歸一化,形成最后的 VLAD 向量。
?歸一化,形成最后的 VLAD 向量。
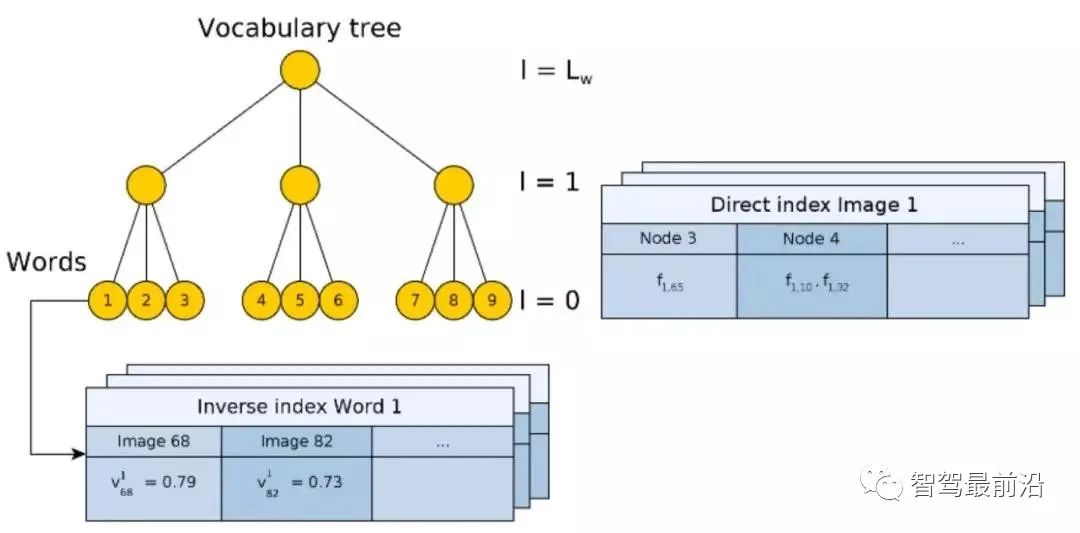 ?對于數(shù)據(jù)庫中第?
?對于數(shù)據(jù)庫中第? ?張圖的權(quán)重?
?張圖的權(quán)重?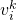 ?(Fig.10)。這里權(quán)重使用 TF-IDF(Term frequency–inverse document frequency) 計算。即如果一個詞??在某個圖像??中出現(xiàn)頻率高,在其它圖像出現(xiàn)頻率低,則這個詞對于圖像判別性較好,權(quán)重值??較高。最終通過投票 (Voting) 機制,選出匹配圖像。同樣需要注意的是,逆向索引不一定建立在樹形結(jié)構(gòu)的 BoW 上,它僅僅是提供一種快速查詢的方法。
?(Fig.10)。這里權(quán)重使用 TF-IDF(Term frequency–inverse document frequency) 計算。即如果一個詞??在某個圖像??中出現(xiàn)頻率高,在其它圖像出現(xiàn)頻率低,則這個詞對于圖像判別性較好,權(quán)重值??較高。最終通過投票 (Voting) 機制,選出匹配圖像。同樣需要注意的是,逆向索引不一定建立在樹形結(jié)構(gòu)的 BoW 上,它僅僅是提供一種快速查詢的方法。

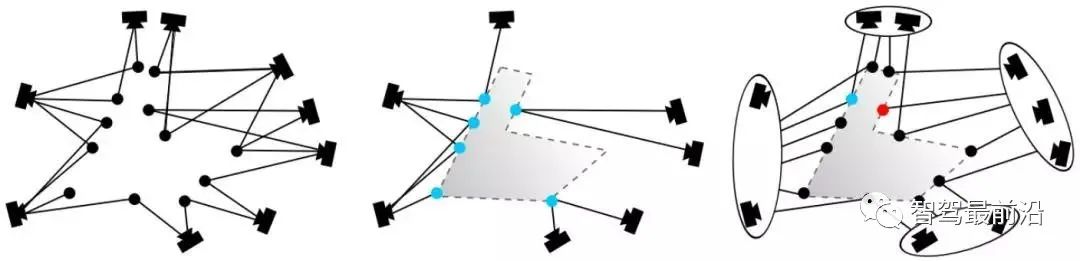
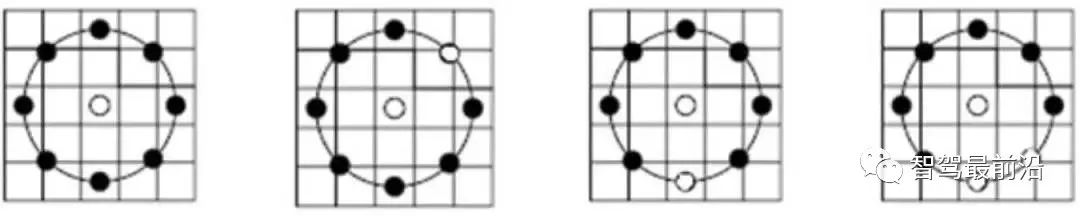
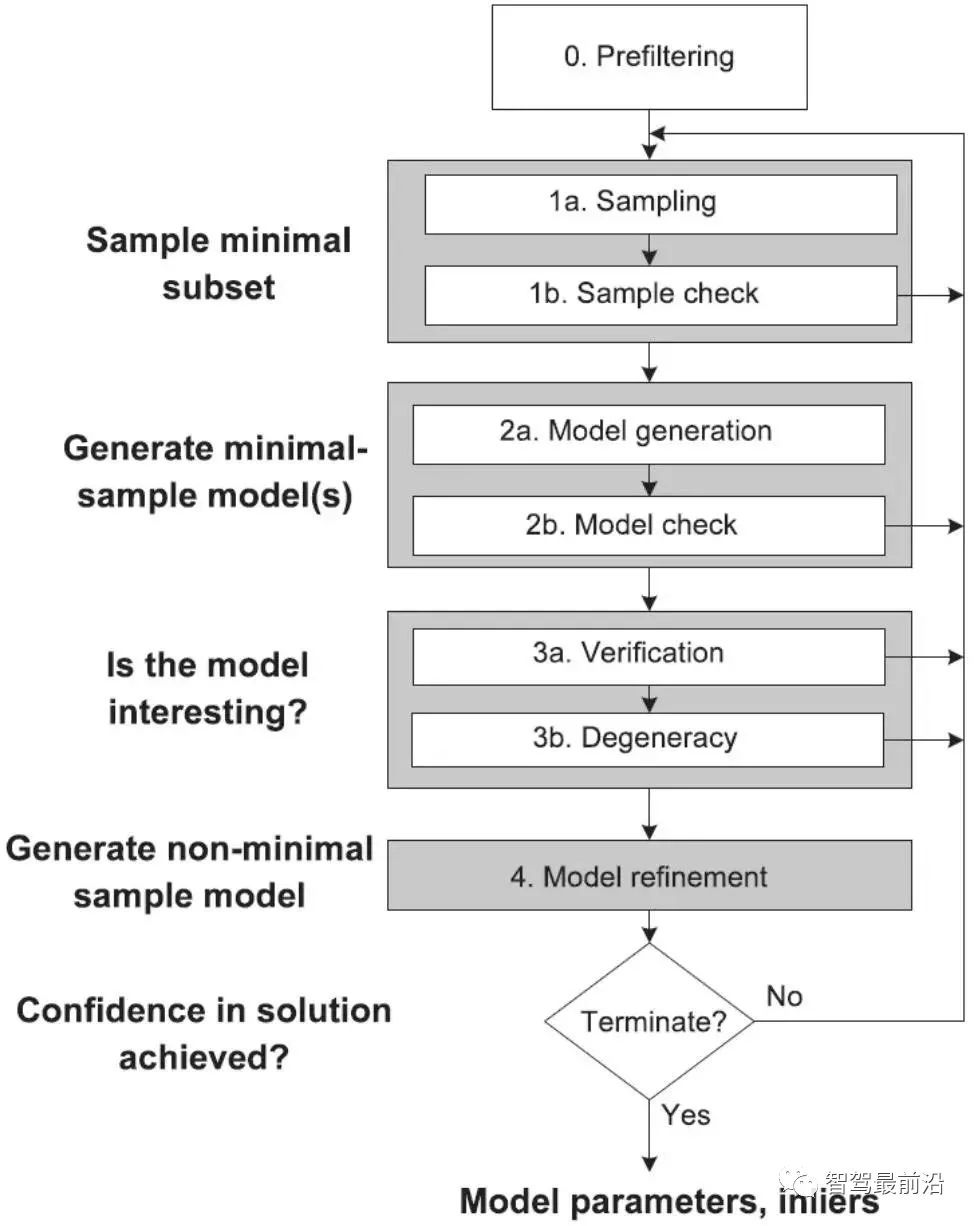
①采樣初始子集。 ②計算變換矩陣。 ③ 根據(jù)變換矩陣計算匹配點的重投影誤差。 ④ 去除誤差較大的點 ⑤ 循環(huán)①-④,保留最滿足指標的匹配方案。

 ?,變換矩?
?,變換矩? ?的齊次形式為:
?的齊次形式為: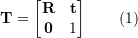
 ?為旋轉(zhuǎn)矩陣,?
?為旋轉(zhuǎn)矩陣,?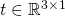 ??為平移矩陣。
??為平移矩陣。
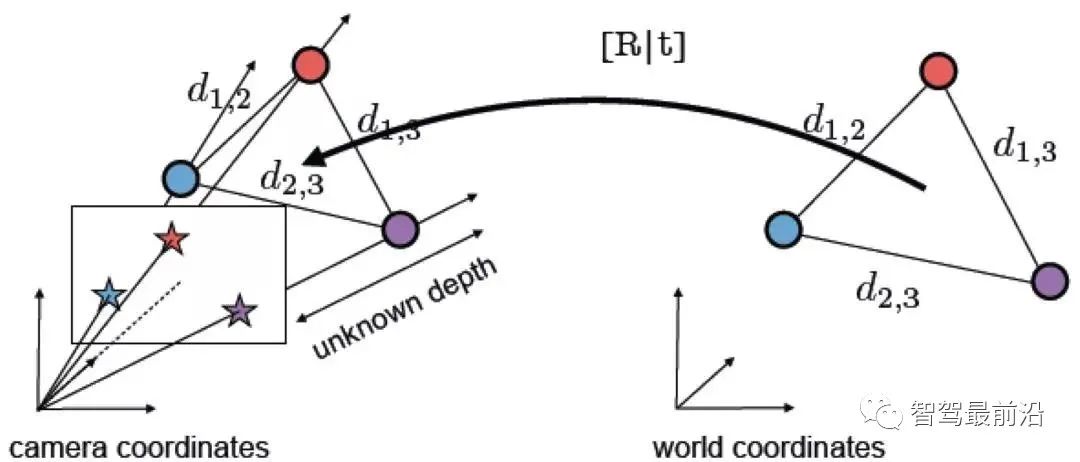
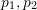 )?,它們在歸一化平面上的坐標為 (
)?,它們在歸一化平面上的坐標為 ( ),需要通過對極約束計算出相應的變換矩陣。如 Fig. 17所示,其幾何意義是?
),需要通過對極約束計算出相應的變換矩陣。如 Fig. 17所示,其幾何意義是? ?三者共面,這個面也被稱為極平面,
?三者共面,這個面也被稱為極平面, ?稱為基線,
?稱為基線, ? 稱為極線。對極約束中同時包含了平移和旋轉(zhuǎn),定義為:
? 稱為極線。對極約束中同時包含了平移和旋轉(zhuǎn),定義為: ?是??在歸一化平面上的坐標,∧ 是外積運算符。將公式中間部分計為基礎矩陣?
?是??在歸一化平面上的坐標,∧ 是外積運算符。將公式中間部分計為基礎矩陣?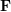 ?和本質(zhì)矩陣?
?和本質(zhì)矩陣? ?,則有:
?,則有: ?不具有尺度信息,所以 E 乘以任意非零常數(shù)后對極約束依然成立。?可以通過經(jīng)典的 8 點法求解(Eight-point-algorithm),然后分解得到?
?不具有尺度信息,所以 E 乘以任意非零常數(shù)后對極約束依然成立。?可以通過經(jīng)典的 8 點法求解(Eight-point-algorithm),然后分解得到? ,?
,?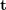 。因此可以看出 2D-2D 的變換矩陣求解方式有兩個缺點,首先單目視覺具有尺度不確定性,尺度信息需要在初始化中由??提供。相應地,單目初始化不能只有純旋轉(zhuǎn),必須要有足夠程度的平移,否則會導致??為零。
。因此可以看出 2D-2D 的變換矩陣求解方式有兩個缺點,首先單目視覺具有尺度不確定性,尺度信息需要在初始化中由??提供。相應地,單目初始化不能只有純旋轉(zhuǎn),必須要有足夠程度的平移,否則會導致??為零。 ?對 2D-3D 匹配點,求解變換矩陣,以獲得相機位姿。我們將 3D 點 P(X, Y, Z) 投影到相機成像平面 (
?對 2D-3D 匹配點,求解變換矩陣,以獲得相機位姿。我們將 3D 點 P(X, Y, Z) 投影到相機成像平面 ( ) 上:
) 上: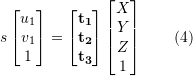
 ?為尺度,
?為尺度, ?。這個等式的求解可以化為一個線性方程問題,每個特征可以提供兩個線性約束:
?。這個等式的求解可以化為一個線性方程問題,每個特征可以提供兩個線性約束:
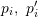 ) 結(jié)果正確,則求得的轉(zhuǎn)換矩陣應當盡量減少重投影誤差?
) 結(jié)果正確,則求得的轉(zhuǎn)換矩陣應當盡量減少重投影誤差?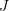 。可以使用 SVD 求解最小二乘問題:
。可以使用 SVD 求解最小二乘問題:
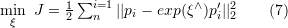
 ?表示相機位姿。這里的優(yōu)化目標與 2D-3D 匹配中的 Bundle Adjustment 的類似,但是不需要考慮相機內(nèi)參?
?表示相機位姿。這里的優(yōu)化目標與 2D-3D 匹配中的 Bundle Adjustment 的類似,但是不需要考慮相機內(nèi)參?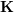 ?,因為通過雙目相機或者 RGB-D 深度相機,已經(jīng)把原本圖像上的 2D 點從相機成像平面投影到 3D 世界中。
?,因為通過雙目相機或者 RGB-D 深度相機,已經(jīng)把原本圖像上的 2D 點從相機成像平面投影到 3D 世界中。本文僅做學術(shù)分享,如有侵權(quán),請聯(lián)系刪文。
評論
圖片
表情