
基于 Flink SQL 構(gòu)建流批一體的 ETL 數(shù)據(jù)集成
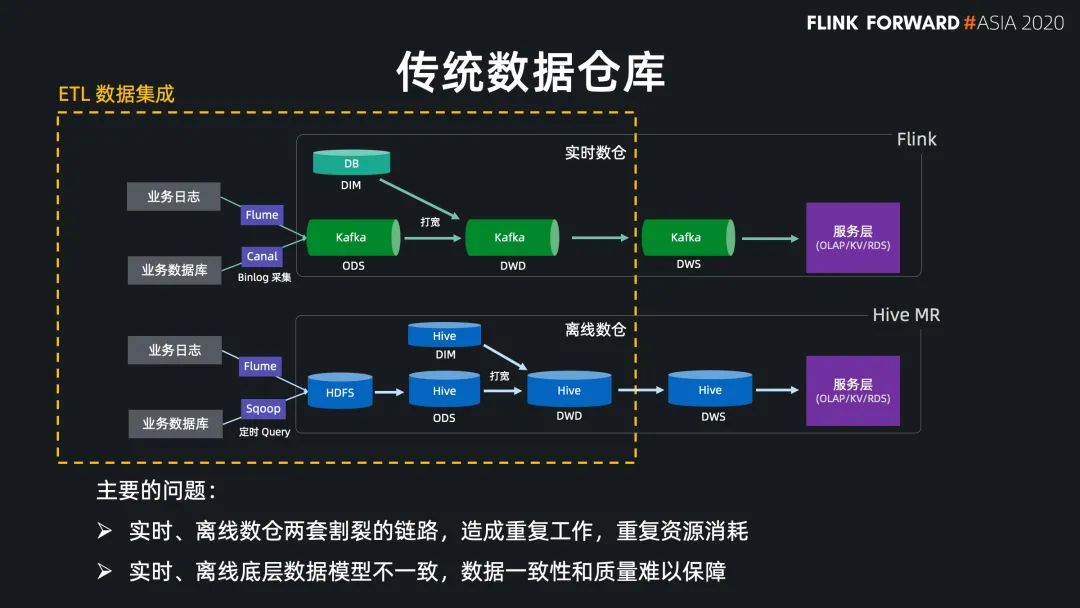
數(shù)據(jù)倉庫與數(shù)據(jù)集成
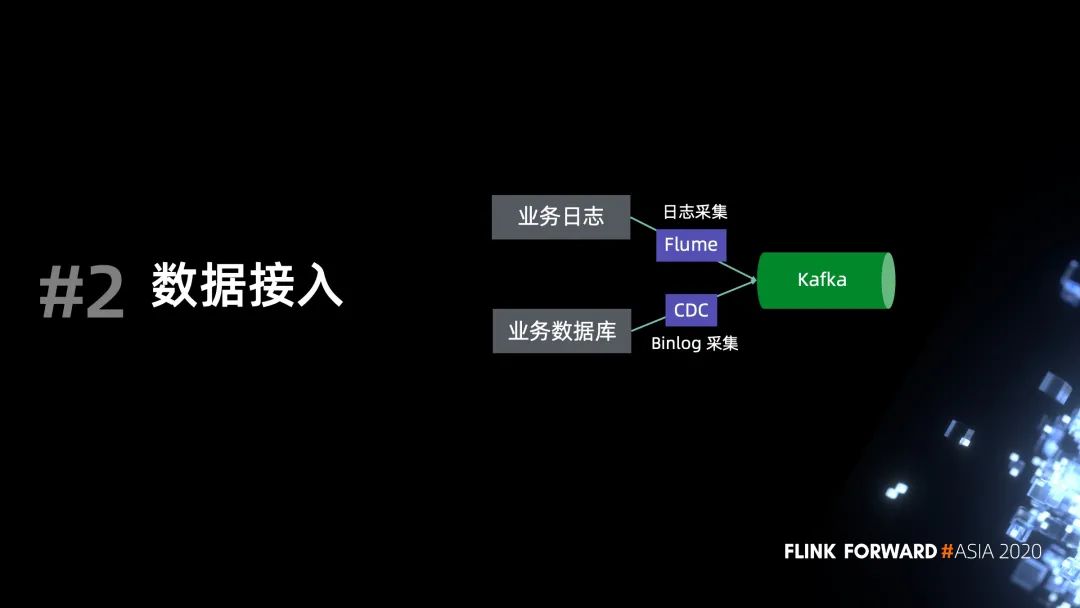
數(shù)據(jù)接入(E)
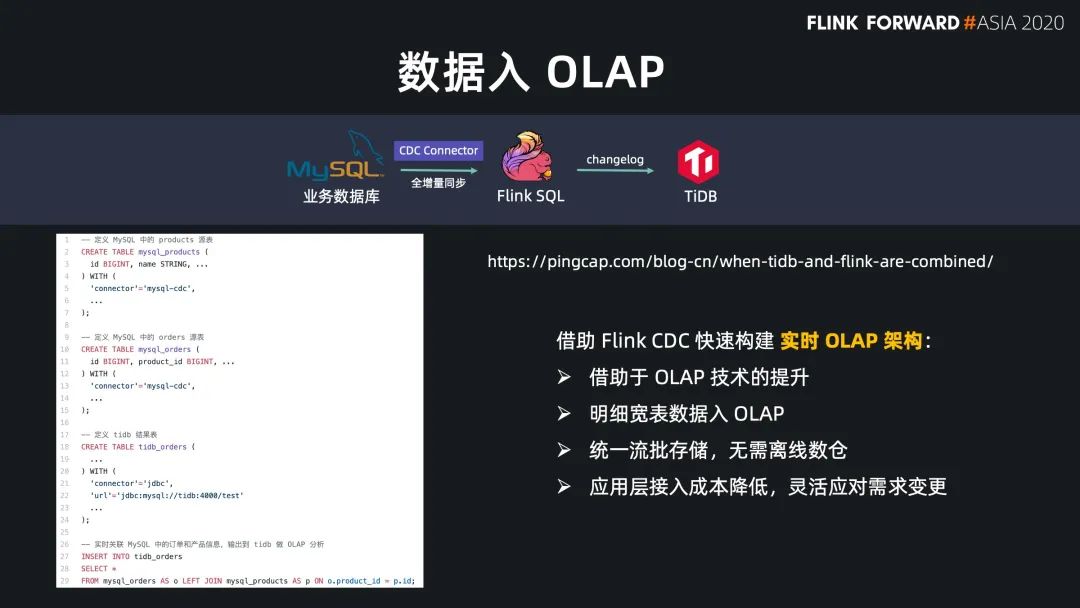
數(shù)據(jù)入倉/湖(L)
數(shù)據(jù)打?qū)?T)
數(shù)據(jù)倉庫與數(shù)據(jù)集成


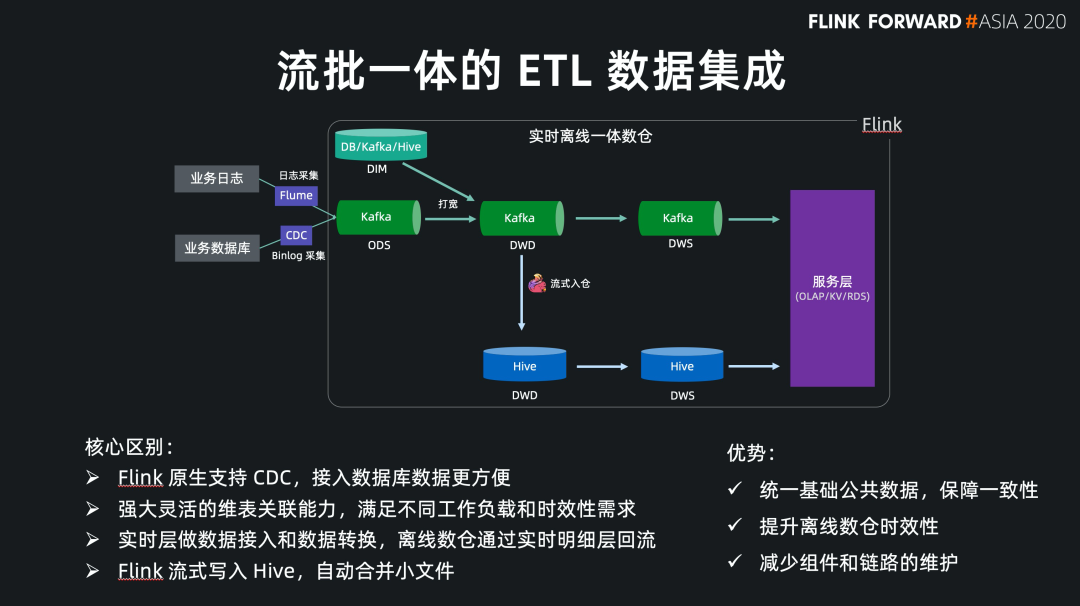
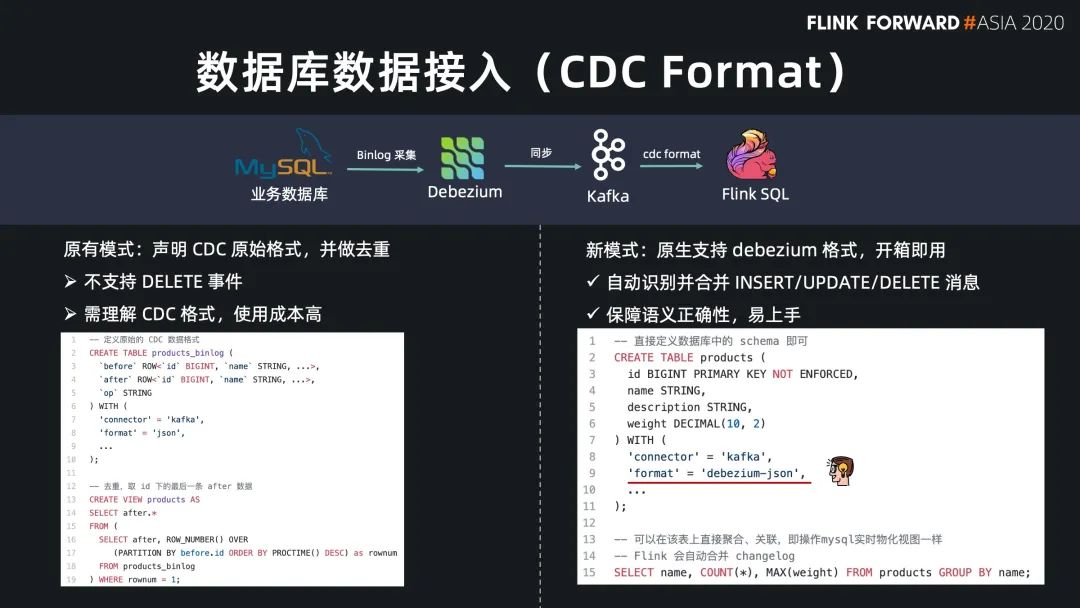
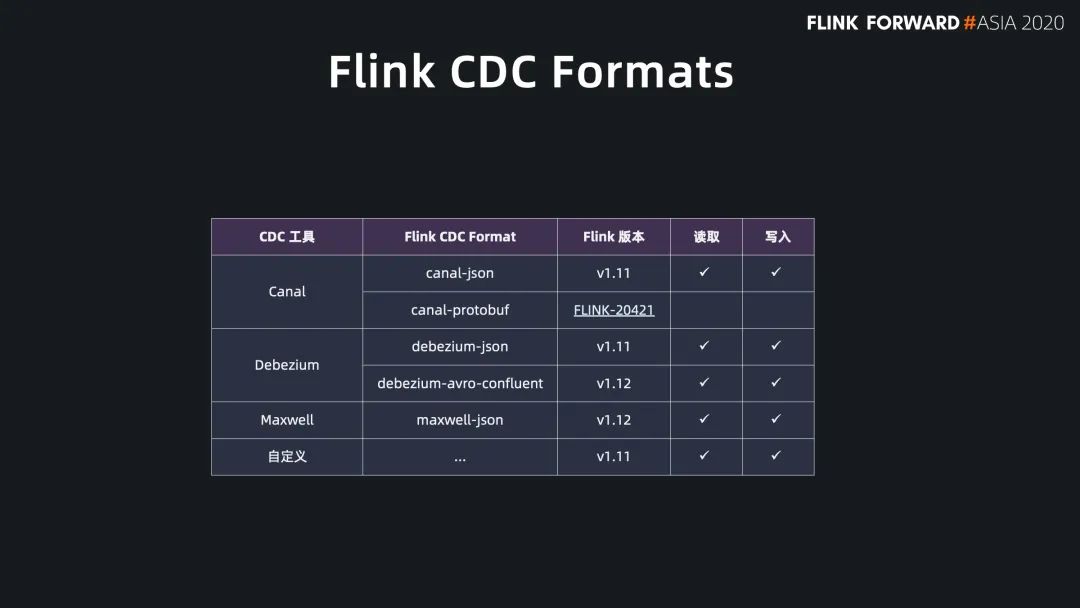
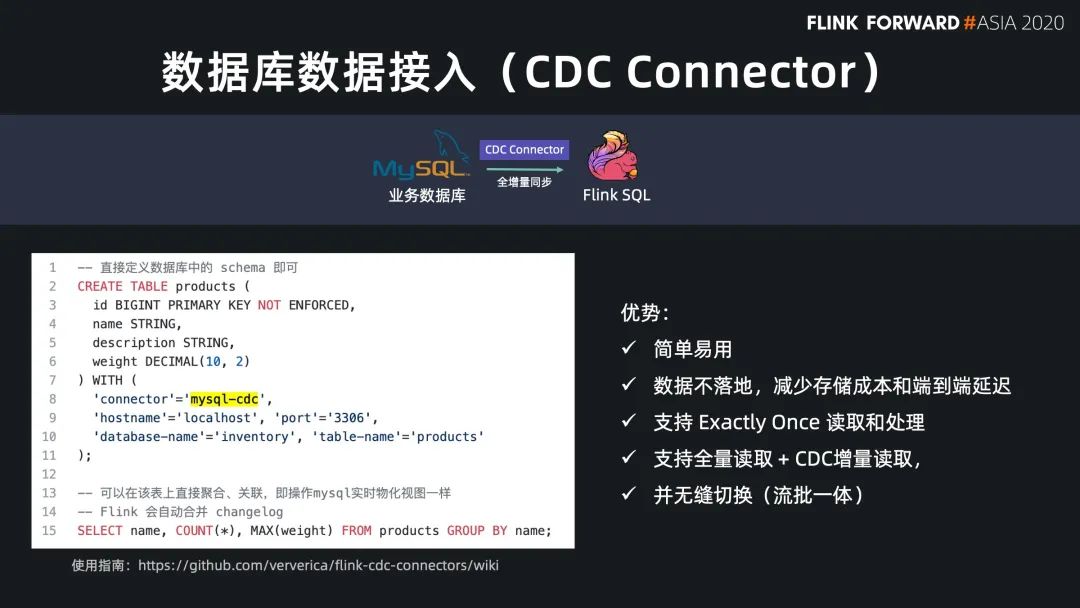
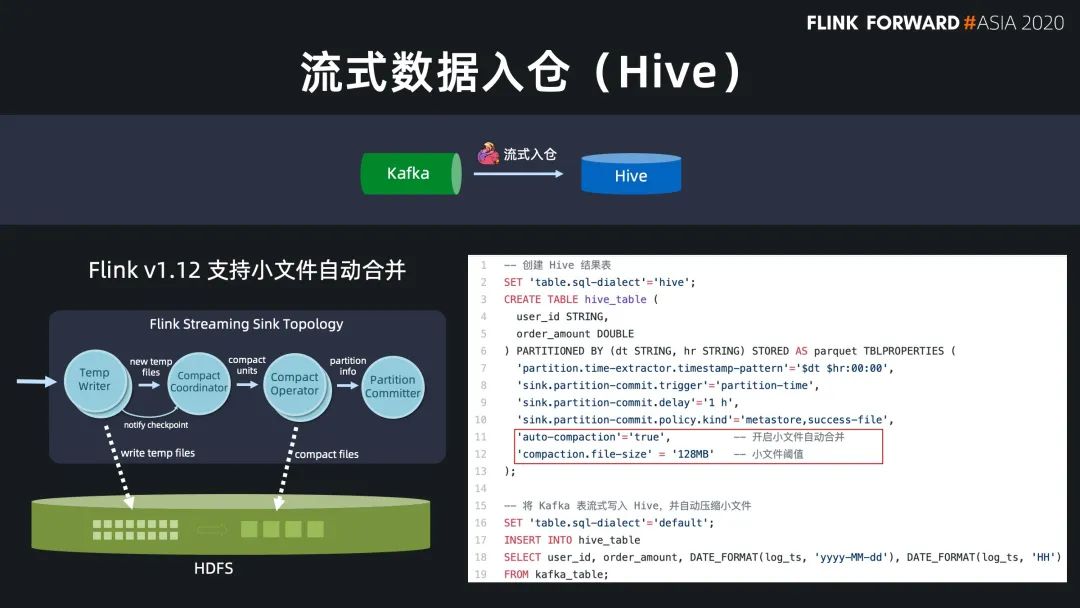
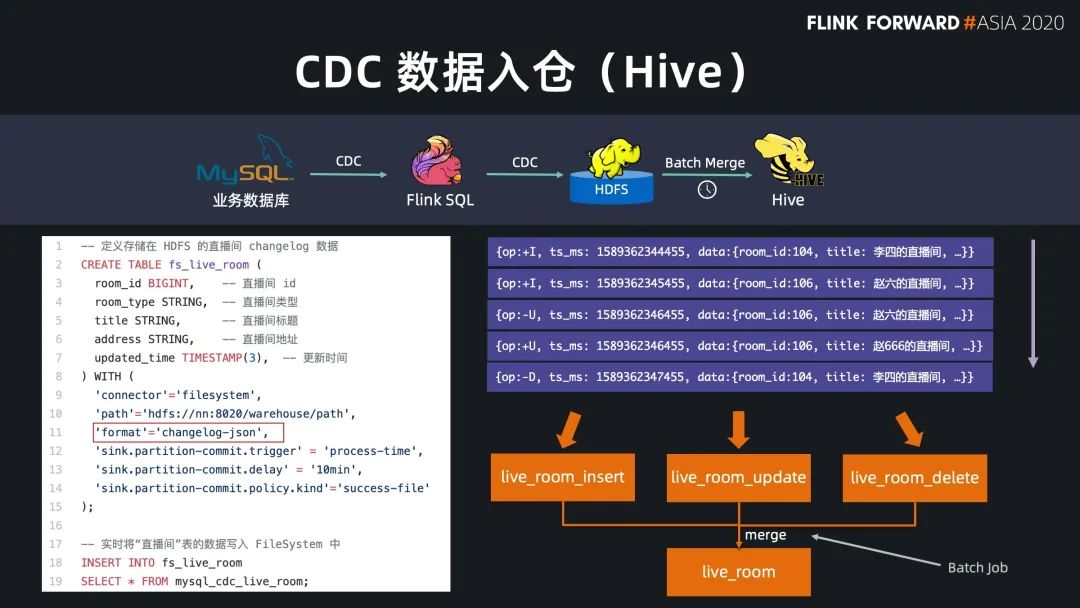
Flink SQL 原生支持了 CDC 所以現(xiàn)在可以方便地同步數(shù)據(jù)庫數(shù)據(jù),不管是直連數(shù)據(jù)庫,還是對接常見的 CDC工具。
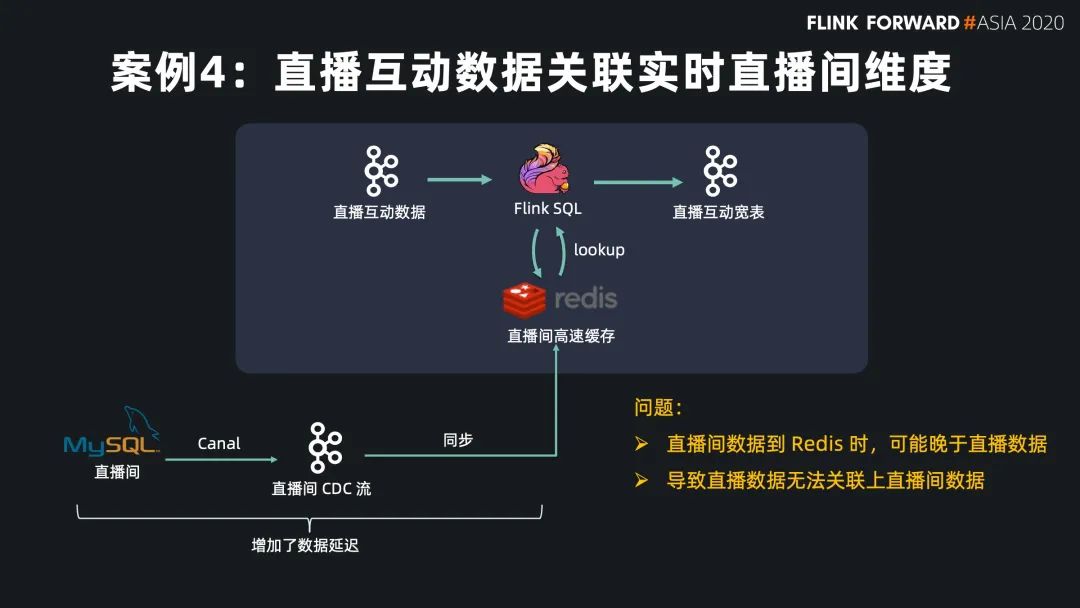
Flink SQL 在最近的版本中持續(xù)強化了維表 join 的能力,不僅可以實時關(guān)聯(lián)數(shù)據(jù)庫中的維表數(shù)據(jù),現(xiàn)在還能關(guān)聯(lián) Hive 和 Kafka 中的維表數(shù)據(jù),能靈活滿足不同工作負載和時效性的需求。
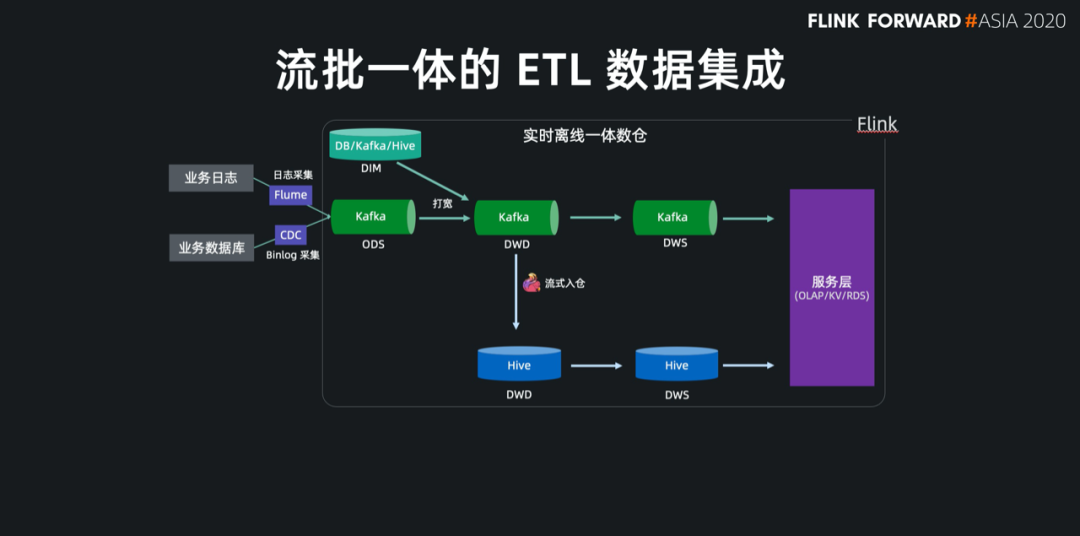
基于 Flink 強大的流式 ETL 的能力,我們可以統(tǒng)一在實時層做數(shù)據(jù)接入和數(shù)據(jù)轉(zhuǎn)換,然后將明細層的數(shù)據(jù)回流到離線數(shù)倉中。
現(xiàn)在 Flink 流式寫入 Hive,已經(jīng)支持了自動合并小文件的功能,解決了小文件的痛苦。
統(tǒng)一了基礎(chǔ)公共數(shù)據(jù) 保障了流批結(jié)果的一致性 提升了離線數(shù)倉的時效性 減少了組件和鏈路的維護成本
數(shù)據(jù)接入


數(shù)據(jù)入倉湖


數(shù)據(jù)打?qū)?/strong>


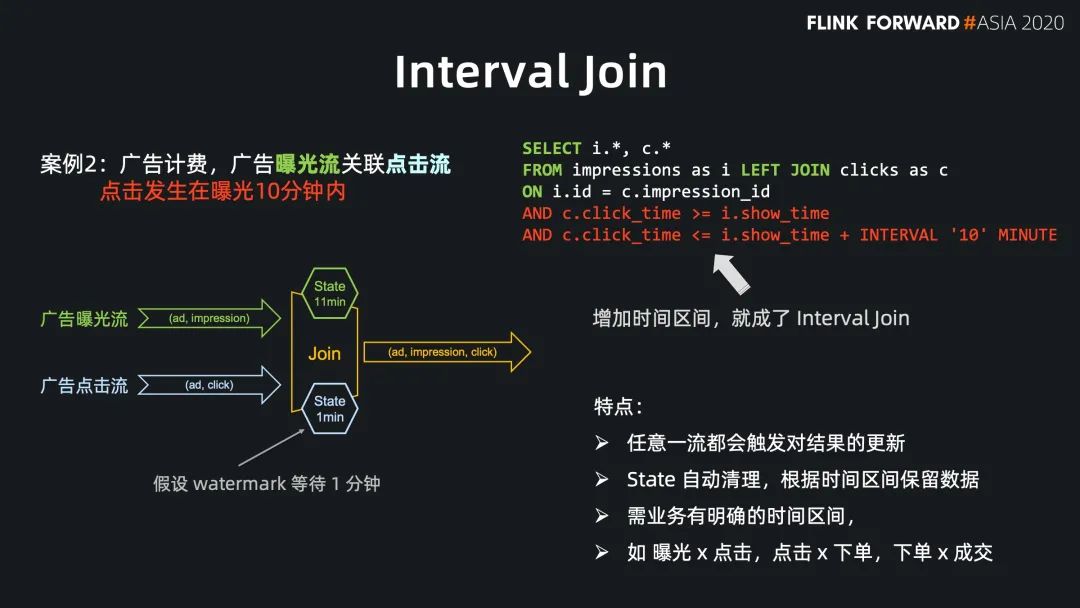



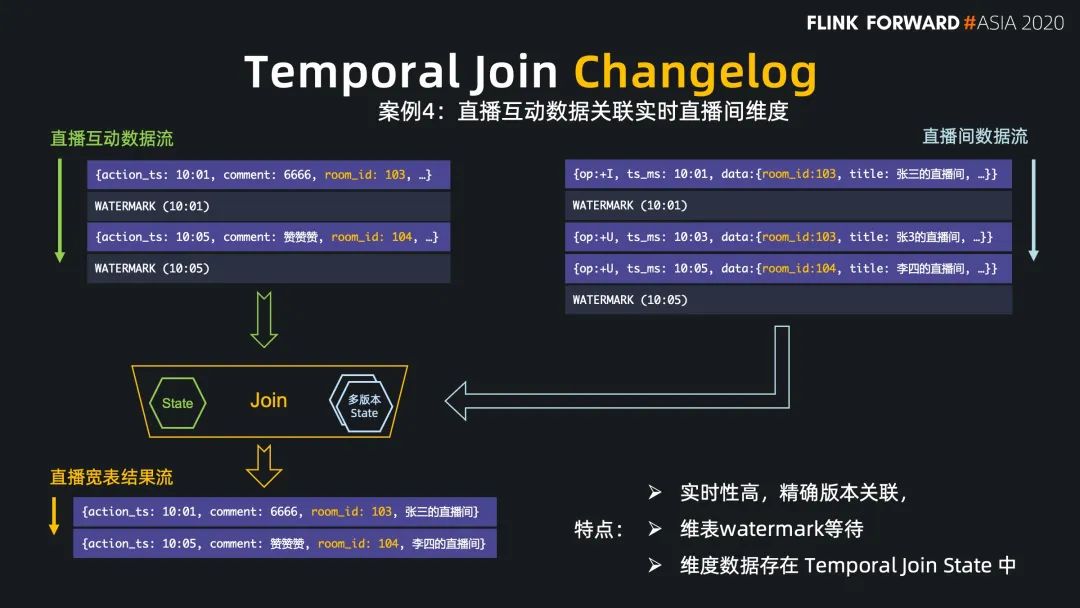
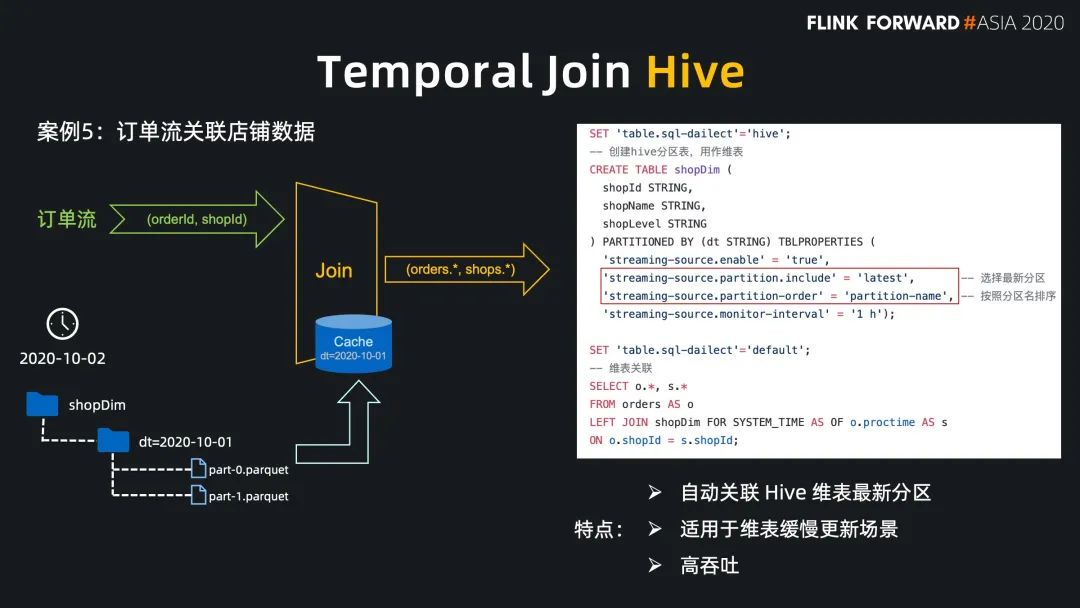
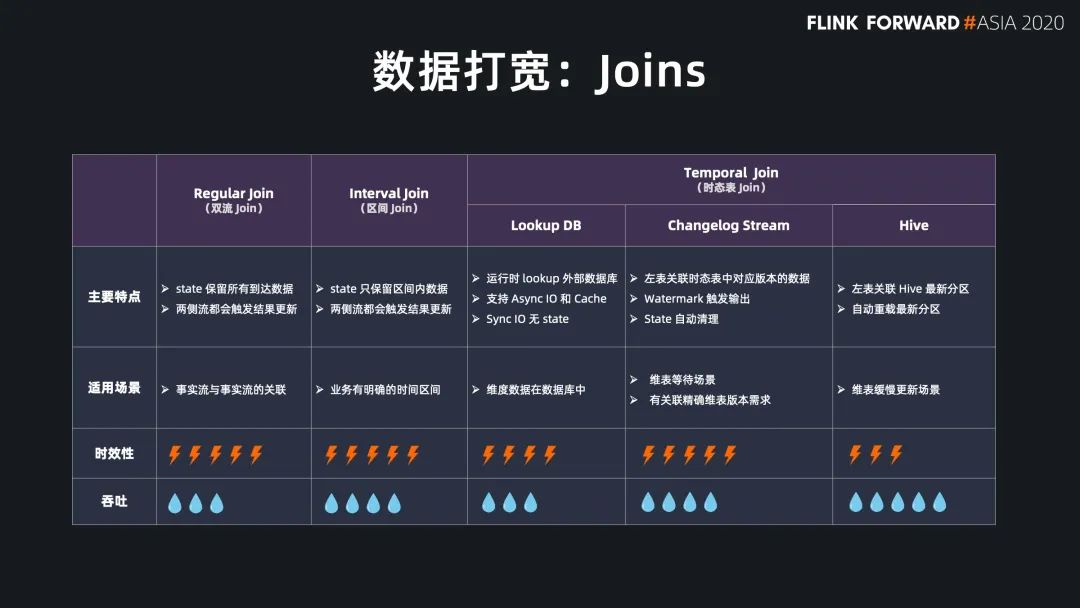
Regular Join 的實效性非常高,吞吐一般,因為 state 會保留所有到達的數(shù)據(jù),適用于雙流關(guān)聯(lián)場景; Interval Jon 的時效性非常好,吞吐較好,因為 state 只保留時間區(qū)間內(nèi)的數(shù)據(jù),適用于有業(yè)務(wù)時間區(qū)間的雙流關(guān)聯(lián)場景; Temporal Join Lookup DB 的時效性比較好,吞吐較差,因為每條數(shù)據(jù)都需要查詢外部系統(tǒng),會有 IO 開銷,適用于維表在數(shù)據(jù)庫中的場景; Temporal Join Changelog 的時效性很好,吞吐也比較好,因為它沒有 IO 開銷,適用于需要維表等待,或者關(guān)聯(lián)準確版本的場景; Temporal Join Hive 的時效性一般,但吞吐非常好,因為維表的數(shù)據(jù)存放在cache 中,適用于維表緩慢更新的場景,高吞吐的場景。
總結(jié)
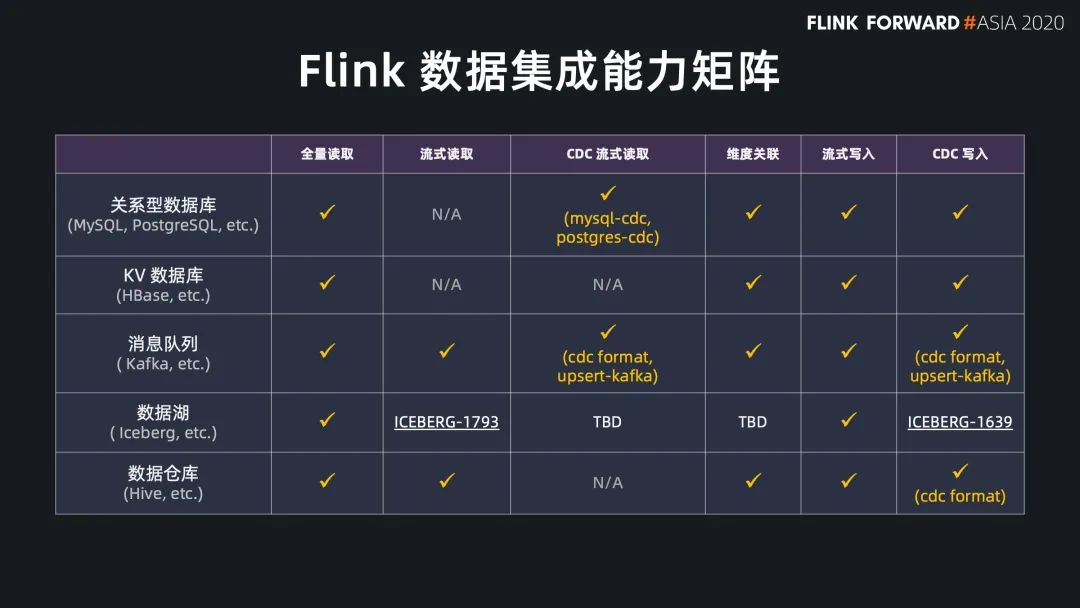
全量讀取 流式讀取 CDC 流式讀取
維度關(guān)聯(lián);
流式寫入 CDC 寫入
評論
圖片
表情