
Flink 執(zhí)行引擎:流批一體的融合之路
背景 流批一體的分層架構(gòu) 流批一體DataStream 流批一體DAG Scheduler 流批一體的Shuffle架構(gòu) 流批一體的容錯(cuò)策略 未來展望
一、背景


人力成本比較高。由于流和批是兩套系統(tǒng),相同的邏輯需要兩個(gè)團(tuán)隊(duì)開發(fā)兩遍。 數(shù)據(jù)鏈路冗余。在很多的場景下,流和批計(jì)算內(nèi)容其實(shí)是一致,但是由于是兩套系統(tǒng),所以相同邏輯還是需要運(yùn)行兩遍,產(chǎn)生一定的資源浪費(fèi)。 數(shù)據(jù)口徑不一致。這個(gè)是用戶遇到的最重要的問題。兩套系統(tǒng)、兩套算子,兩套 UDF,一定會(huì)產(chǎn)生不同程度的誤差,這些誤差給業(yè)務(wù)方帶來了非常大的困擾。這些誤差不是簡單依靠人力或者資源的投入就可以解決的。
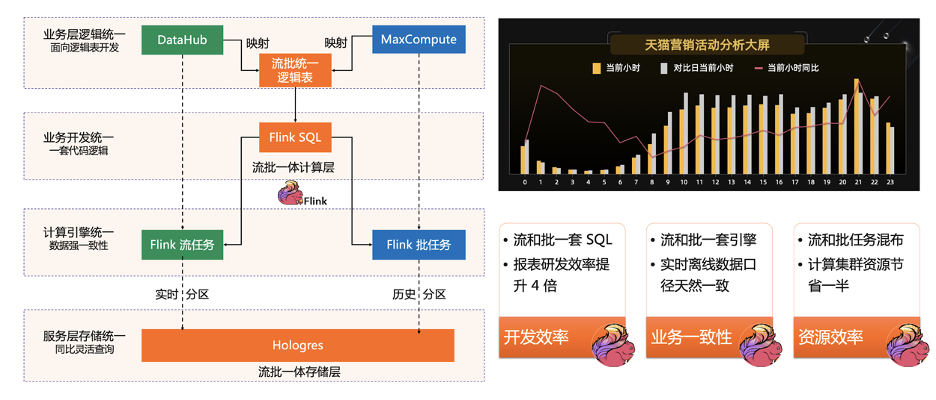
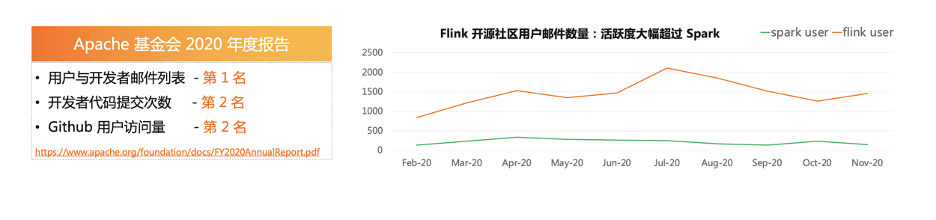
二、流批一體的分層架構(gòu)
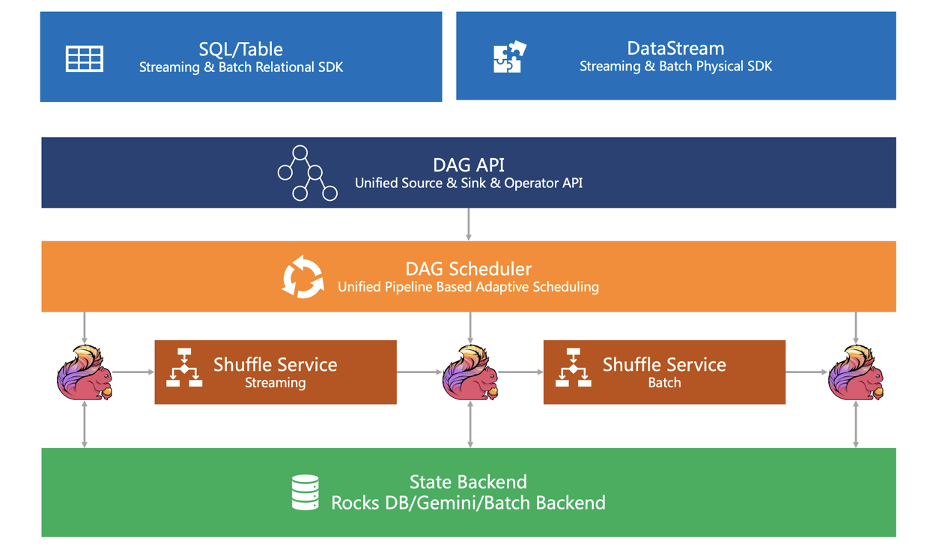
SDK 層。Flink 的 SDK 主要有兩類,第一類是關(guān)系型 Relational SDK 也就是 SQL/Table,第二類是物理型 Physical SDK 也就是 DataStream。這兩類 SDK 都是流批統(tǒng)一,即不管是 SQL 還是 DataStream,用戶的業(yè)務(wù)邏輯只要開發(fā)一遍,就可以同時(shí)在流和批的兩種場景下使用; 執(zhí)行引擎層。執(zhí)行引擎提供了統(tǒng)一的 DAG,用來描述數(shù)據(jù)處理流程 Data Processing Pipeline(Logical Plan)。不管是流任務(wù)還是批任務(wù),用戶的業(yè)務(wù)邏輯在執(zhí)行前,都會(huì)先轉(zhuǎn)化為此 DAG 圖。執(zhí)行引擎通過 Unified DAG Scheduler 把這個(gè)邏輯 DAG 轉(zhuǎn)化成在分布式環(huán)境下執(zhí)行的Task。Task 之間通過 Shuffle 傳輸數(shù)據(jù),我們通過 Pluggable Unified Shuffle 架構(gòu),同時(shí)支持流批兩種 Shuffle 方式; 狀態(tài)存儲(chǔ)。狀態(tài)存儲(chǔ)層負(fù)責(zé)存儲(chǔ)算子的狀態(tài)執(zhí)行狀態(tài)。針對(duì)流作業(yè)有開源 RocksdbStatebackend、MemoryStatebackend,也有商業(yè)化的版本的GemniStateBackend;針對(duì)批作業(yè)我們?cè)谏鐓^(qū)版本引入了 BatchStateBackend。
流批一體的 DataStream 介紹了如何通過流批一體的 DataStream 來解決 Flink SDK 當(dāng)前面臨的挑戰(zhàn); 流批一體的 DAG Scheduler 介紹了如何通過統(tǒng)一的 Pipeline Region 機(jī)制充分挖掘流式引擎的性能優(yōu)勢(shì);如何通過動(dòng)態(tài)調(diào)整執(zhí)行計(jì)劃的方式來改善引擎的易用性,提高系統(tǒng)的資源利用率; 流批一體的 Shuffle 架構(gòu)介紹如何通過一套統(tǒng)一的 Shuffle 架構(gòu)既可以滿足不同 Shuffle 在策略上的定制化需求,同時(shí)還能避免在共性需求上的重復(fù)開發(fā); 流批一體的容錯(cuò)策略介紹了如何通過統(tǒng)一的容錯(cuò)策略既滿足批場景下容錯(cuò)又可以提升流場景下的容錯(cuò)效果。
三、流批一體 DataStream
SDK 分析以及面臨的挑戰(zhàn)

Table/SQL 是一種 Relational 的高級(jí) SDK,主要用在一些數(shù)據(jù)分析的場景中,既可以支持 Bounded 也可以支持 Unbounded 的輸入。由于 Table/SQL 是 Declarative 的,所以系統(tǒng)可以幫助用戶進(jìn)行很多優(yōu)化,例如根據(jù)用戶提供的Schema,可以進(jìn)行 Filter Push Down 謂詞下推、按需反序列二進(jìn)制數(shù)據(jù)等優(yōu)化。目前 Table/SQL 可以支持 Batch 和 Streaming 兩種執(zhí)行模式。[1] DataStream 屬于一種 Physical SDK。Relatinal SDK 功能雖然強(qiáng)大,但也存在一些局限:不支持對(duì) State、Timer 的操作;由于 Optimizer 的升級(jí),可能導(dǎo)致用相同的 SQL 在兩個(gè)版本中出現(xiàn)物理執(zhí)行計(jì)劃不兼容的情況。而 DataStream SDK,既可以支持 State、Timer 維度 Low Level 的操作,同時(shí)由于 DataStream 是一種 Imperative SDK,所以對(duì)物理執(zhí)行計(jì)劃有很好的“掌控力”,從而也不存在版本升級(jí)導(dǎo)致的不兼容。DataStream 目前在社區(qū)仍有很大用戶群,例如目前未 Closed 的 DataStream issue 依然有近 500 個(gè)左右。雖然 DataStream 即可以支持 Bounded 又可以支持 Unbounded Input 用 DataStream 寫的 Application,但是在 Flink-1.12 之前只支持 Streaming 的執(zhí)行模式。 DataSet 是一種僅支持 Bounded 輸入的 Physical SDK,會(huì)根據(jù) Bounded 的特性對(duì)某些算子進(jìn)行做一定的優(yōu)化,但是不支持 EventTime 和 State 等操作。雖然 DataSet 是 Flink 提供最早的一種 SDK,但是隨著實(shí)時(shí)化和數(shù)據(jù)分析場景的不斷發(fā)展,相比于 DataStream 和 SQL,DataSet 在社區(qū)的影響力在逐步下降。
利用已有 Physical SDK 無法寫出一個(gè)真正生產(chǎn)可以用的流批一體的 Application。例如用戶寫一個(gè)程序用來處理 Kafka 中的實(shí)時(shí)數(shù)據(jù),那么利用相同的程序來處理存儲(chǔ)在 OSS/S3/HDFS 上的歷史數(shù)據(jù)也是非常自然的事情。但是目前不管是 DataSet 還是 DataStream 都無法滿足用戶這個(gè)“簡單”的訴求。大家可能覺得奇怪,DataStream 不是既支持 Bounded 的 Input 又支持 Unbounded 的 Input,為什么還會(huì)有問題呢?其實(shí)“魔鬼藏在細(xì)節(jié)中”,我會(huì)在 Unified DataStream 這一節(jié)中會(huì)做進(jìn)一的闡述。 學(xué)習(xí)和理解的成本比較高。隨著 Flink 不斷壯大,越來越多的新用戶加入 Flink 社區(qū),但是對(duì)于這些新用戶來說就要學(xué)習(xí)兩種 Physical SDK。和其他引擎相比,用戶入門的學(xué)習(xí)成本是相對(duì)比較高的;兩種 SDK 在語義上有不同的地方,例如 DataStream 上有 Watermark、EventTime,而 DataSet 卻沒有,對(duì)于用戶來說,理解兩套機(jī)制的門檻也不小;由于這兩 SDK 還不兼容,一個(gè)新用戶一旦選擇錯(cuò)誤,將會(huì)面臨很大的切換成本。
Unified Physical SDK

為什么選擇 DataStream 作為 Unified Physical SDK?
Unified DataStream 比“老”的 DataStream 提供了哪些能力讓用戶可以寫出一個(gè)真正生產(chǎn)可以用的流批一體 Application?
為什么不是 Unified DataSet
用戶收益。在前邊已經(jīng)分析過,隨著 Flink 社區(qū)的發(fā)展,目前 DataSet 在社區(qū)的影響力逐漸下降。如果選擇使用 DataSet 作為 Unified Physical SDK,那么用戶之前在 DataStream 大量“投資”就會(huì)作廢。而選擇 DataStream,可以讓許多用戶的已有 DataStream “投資”得到額外的回報(bào); 開發(fā)成本。DataSet 過于古老,缺乏大量對(duì)于現(xiàn)代實(shí)時(shí)計(jì)算引擎基本概念的支持,例如 EventTime、Watermark、State、Unbounded Source 等。另外一個(gè)更深層的原因是現(xiàn)有 DataSet 算子的實(shí)現(xiàn),在流的場景完全無法復(fù)用,例如 Join 等。而對(duì)于 DataStream 則不然,可以進(jìn)行大量的復(fù)用。那么如何在流批兩種場景下復(fù)用 DataStream 的算子呢?
Unified DataStream
效率
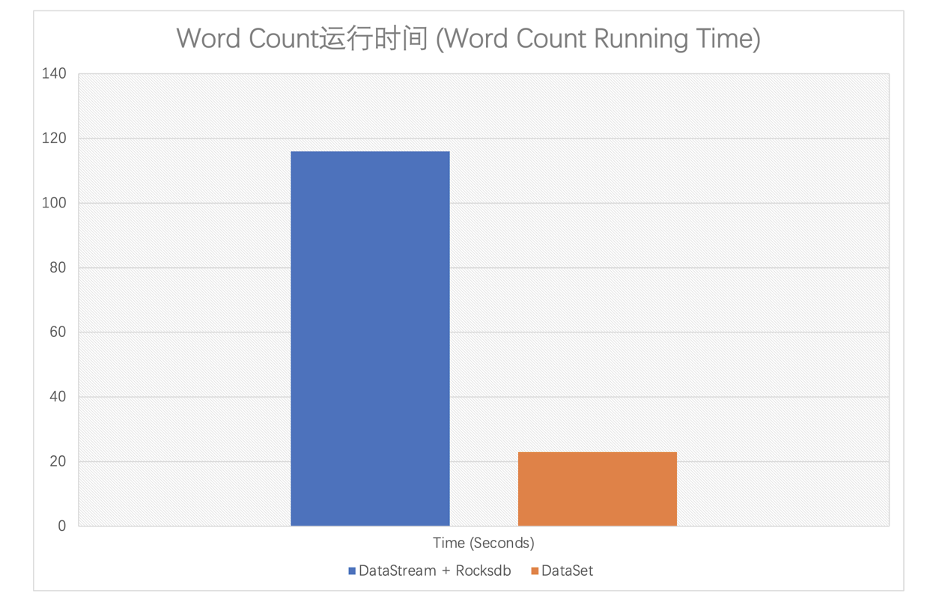
一致性
資源消耗大: 使用 Streaming 方式,需要同時(shí)拿到所有的資源。在某些情況下,用戶可能沒有這么多資源; 容錯(cuò)成本高: 在 Bounded 場景下,為了效率一些算子可能無法支持 Snapshot 操作,一旦出錯(cuò)可能需要重新執(zhí)行整個(gè)作業(yè)。
What to commit? How to commit? Where to commit? When to commit?
四、流批一體 DAG Scheduler
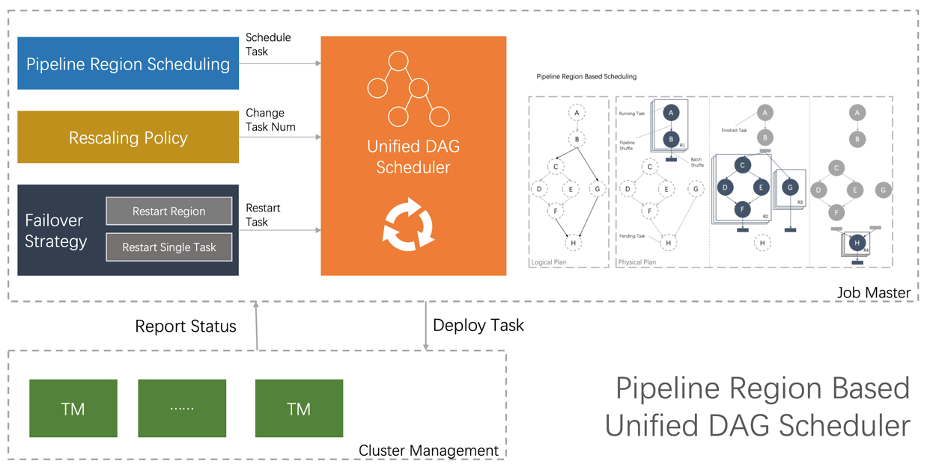
Unified DAG Scheduler 要解決什么問題
一種是流的調(diào)度模式,在這種模式下,Scheduler 會(huì)申請(qǐng)到一個(gè)作業(yè)所需要的全部資源,然后同時(shí)調(diào)度這個(gè)作業(yè)的全部 Task,所有的 Task 之間采取 Pipeline 的方式進(jìn)行通信。批作業(yè)也可以采取這種方式,并且在性能上也會(huì)有很大的提升。但是對(duì)于運(yùn)行比較長的 Batch 作業(yè)來說來說,這種模式還是存在一定的問題:規(guī)模比較大的情況下,同時(shí)消耗的資源比較多,對(duì)于某些用戶來說,他可能沒有這么多的資源;容錯(cuò)代價(jià)比較高,例如一旦發(fā)生錯(cuò)誤,整個(gè)作業(yè)都需要重新運(yùn)行。 一種是批的調(diào)度模式。這種模式和傳統(tǒng)的批引擎類似,所有 Task 都是可以獨(dú)立申請(qǐng)資源,Task 之間都是通過 Batch Shuffle 進(jìn)行通訊。這種方式的好處是容錯(cuò)代價(jià)比較小。但是這種運(yùn)行方式也存在一些短板。例如,Task 之間的數(shù)據(jù)都是通過磁盤來進(jìn)行交互,引發(fā)了大量的磁盤 IO。
架構(gòu)不一致、維護(hù)成本高。調(diào)度的本質(zhì)就是進(jìn)行資源的分配,換句話說就是要解決 When to deploy which tasks to where 的問題。原有兩種調(diào)度模式,在資源分配的時(shí)機(jī)和粒度上都有一定的差異,最終導(dǎo)致了調(diào)度架構(gòu)上無法完全統(tǒng)一,需要開發(fā)人員維護(hù)兩套邏輯。例如,流的調(diào)度模式,資源分配的粒度是整個(gè)物理執(zhí)行計(jì)劃的全部 Task;批的調(diào)度模式,資源分配的粒度是單個(gè)任務(wù),當(dāng) Scheduler 拿到一個(gè)資源的時(shí)候,就需要根據(jù)作業(yè)類型走兩套不同的處理邏輯; 性能。傳統(tǒng)的批調(diào)度方式,雖然容錯(cuò)代價(jià)比較小,但是引入大量的磁盤 I/O,并且性能也不是最佳,無法發(fā)揮出 Flink 流式引擎的優(yōu)勢(shì)。實(shí)際上在資源相對(duì)充足的場景下,可以采取“流”的調(diào)度方式來運(yùn)行 Batch 作業(yè),從而避免額外的磁盤 I/O,提高作業(yè)的執(zhí)行效率。尤其是在夜間,流作業(yè)可以釋放出一定資源,這就為批作業(yè)按照“Streaming”的方式運(yùn)行提供了可能。 自適應(yīng)。目前兩種調(diào)度方式的物理執(zhí)行計(jì)劃是靜態(tài)的,靜態(tài)生成物理執(zhí)行計(jì)劃存在調(diào)優(yōu)人力成本高、資源利用率低等問題。
基于 Pipeline Region 的統(tǒng)一調(diào)度
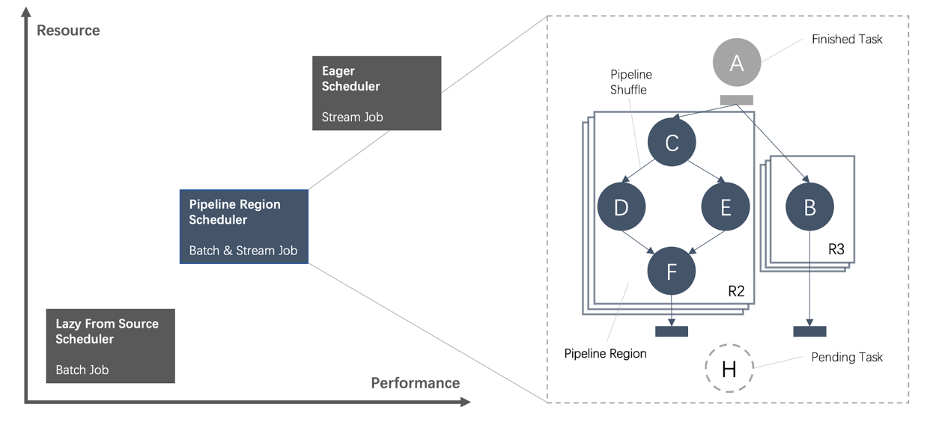

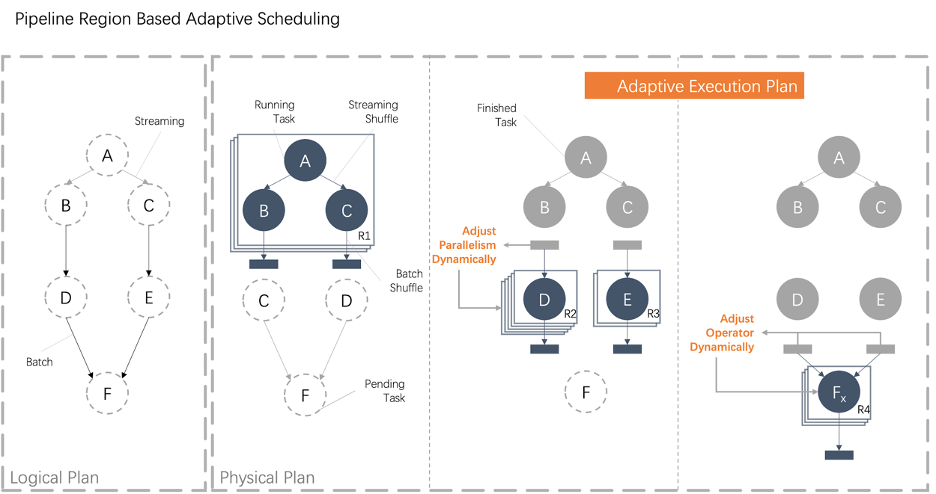
自適應(yīng)調(diào)度
配置人力成本高。對(duì)于批作業(yè)來說,雖然理論上可以根據(jù)統(tǒng)計(jì)信息推斷出物理執(zhí)行計(jì)劃中每個(gè)階段的并發(fā)度,但是由于存在大量的 UDF 或者統(tǒng)計(jì)信息的缺失等問題,導(dǎo)致靜態(tài)決策結(jié)果可能會(huì)出現(xiàn)嚴(yán)重不準(zhǔn)確的情況;為了保障業(yè)務(wù)作業(yè)的 SLA,在大促期間,業(yè)務(wù)的同學(xué)需要根據(jù)大促的流量估計(jì),手動(dòng)調(diào)整高優(yōu)批作業(yè)的并發(fā)度,由于業(yè)務(wù)變化快,一旦業(yè)務(wù)邏輯發(fā)生變化,又要不斷的重復(fù)這個(gè)過程。整個(gè)調(diào)優(yōu)過程都需要業(yè)務(wù)的同學(xué)手動(dòng)操作,人力成本比較高,即便這樣也可能會(huì)出現(xiàn)誤判的情況導(dǎo)致無法滿足用戶 SLA; 資源利用率低。由于人工配置并發(fā)度成本比較高,所以不可能對(duì)所有的作業(yè)都手動(dòng)配置并發(fā)度。對(duì)于中低優(yōu)先級(jí)的作業(yè),業(yè)務(wù)同學(xué)會(huì)選取一些默認(rèn)值作為并發(fā)度,但是在大多數(shù)情況下這些默認(rèn)值都偏大,造成資源的浪費(fèi);而且雖然高優(yōu)先級(jí)的作業(yè)可以進(jìn)行手工并發(fā)配置,由于配置方式比較繁瑣,所以大促過后,雖然流量已經(jīng)下降但是業(yè)務(wù)方仍然會(huì)使用大促期間的配置,也造成大量的資源浪費(fèi)現(xiàn)象; 穩(wěn)定性差。資源浪費(fèi)的情況最終導(dǎo)致資源的超額申請(qǐng)現(xiàn)象。目前大多數(shù)批作業(yè)都是采取和流作業(yè)集群混跑的方式,具體來說申請(qǐng)的資源都是非保障資源,一旦資源緊張或者出現(xiàn)機(jī)器熱點(diǎn),這些非保障資源都是優(yōu)先被調(diào)整的對(duì)象。
五、流批一體的 Shuffle 架構(gòu)

流批 Shuffle 之間的差異
Shuffle 數(shù)據(jù)的生命周期。流作業(yè)的 Shuffle 數(shù)據(jù)和 Task 的生命周期基本是一致的;而批作業(yè)的 Shuffle 數(shù)據(jù)和 Task 生命周期是解耦的; Shuffle 數(shù)據(jù)的存儲(chǔ)介質(zhì)。因?yàn)榱髯鳂I(yè)的 Shuffle 數(shù)據(jù)生命周期比較短,所以可以把流作業(yè)的 Shuffle 數(shù)據(jù)存儲(chǔ)在內(nèi)存中;而批作業(yè)的 Shuffle 數(shù)據(jù)生命周期有一定的不確定性,所以需要把批作業(yè)的 Shuffle 數(shù)據(jù)存儲(chǔ)在磁盤中; Shuffle 部署方式[7]。把 Shuffle 服務(wù)和計(jì)算節(jié)點(diǎn)部署在一起,對(duì)流作業(yè)來說這種部署方式是有優(yōu)勢(shì)的,因?yàn)檫@樣會(huì)減少不必要網(wǎng)絡(luò)開銷,從而減少 Latency。但對(duì)于批作業(yè)來說,這種部署方式在資源利用率、性能、穩(wěn)定性上都存在一定的問題。[8]
流批 Shuffle 之間的共性
數(shù)據(jù)的 Meta 管理。所謂 Shuffle Meta 是指邏輯數(shù)據(jù)劃分到數(shù)據(jù)物理位置的映射。不管是流還是批的場景,在正常情況下都需要從 Meta 中找出自己的讀取或者寫入數(shù)據(jù)的物理位置;在異常情況下,為了減少容錯(cuò)代價(jià),通常也會(huì)對(duì) Shuffle Meta 數(shù)據(jù)進(jìn)行持久化; 數(shù)據(jù)傳輸。從邏輯上講,流作業(yè)和批作業(yè)的 Shuffle 都是為了對(duì)數(shù)據(jù)進(jìn)行重新劃分(re-partition/re-distribution)。在分布式系統(tǒng)中,對(duì)數(shù)據(jù)的重新劃分都涉及到跨線程、進(jìn)程、機(jī)器的數(shù)據(jù)傳輸。
流批一體的 Shuffle 架構(gòu)
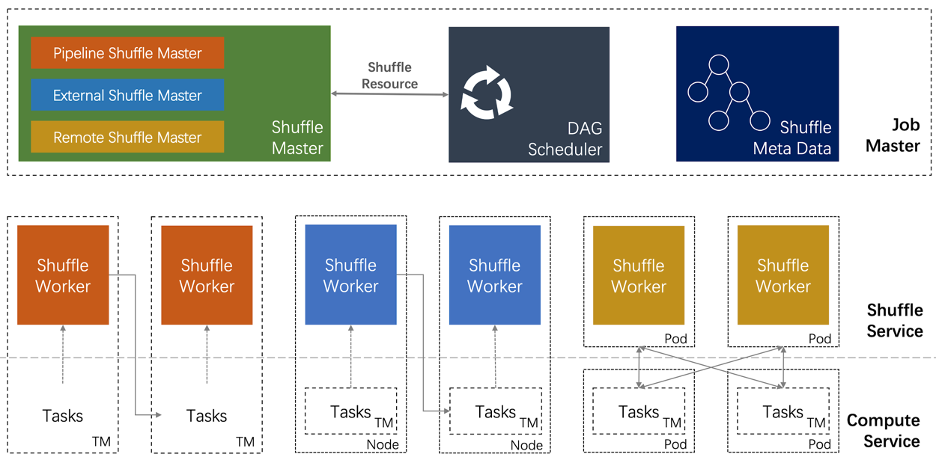
Shuffle Master 資源申請(qǐng)和資源釋放。也就是說插件需要通知框架 How to request/release resource。而由 Flink 來決定 When to call it; Shuffle Writer 上游的算子利用 Writer 把數(shù)據(jù)寫入 Shuffle Service——Streaming Shuffle 會(huì)把數(shù)據(jù)寫入內(nèi)存;External/Remote Batch Shuffle 可以把數(shù)據(jù)寫入到外部存儲(chǔ)中; Shuffle Reader 下游的算子可以通過 Reader 讀取 Shuffle 數(shù)據(jù);
六、流批一體的容錯(cuò)策略
Pipeline Region Failover
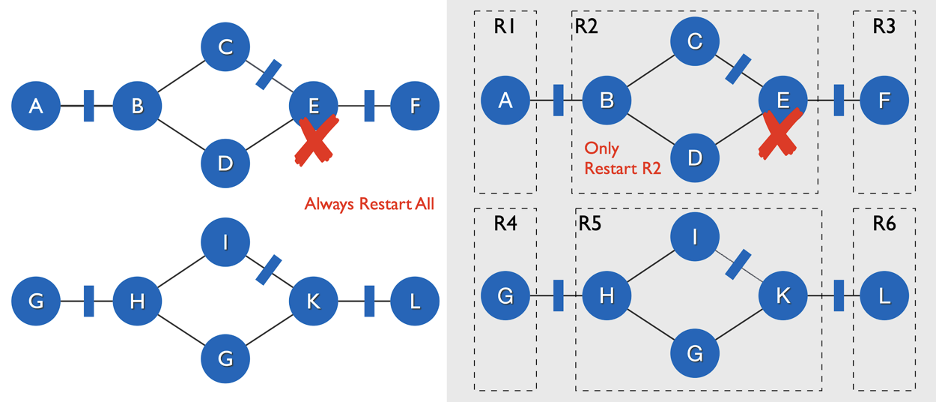
JM Failover
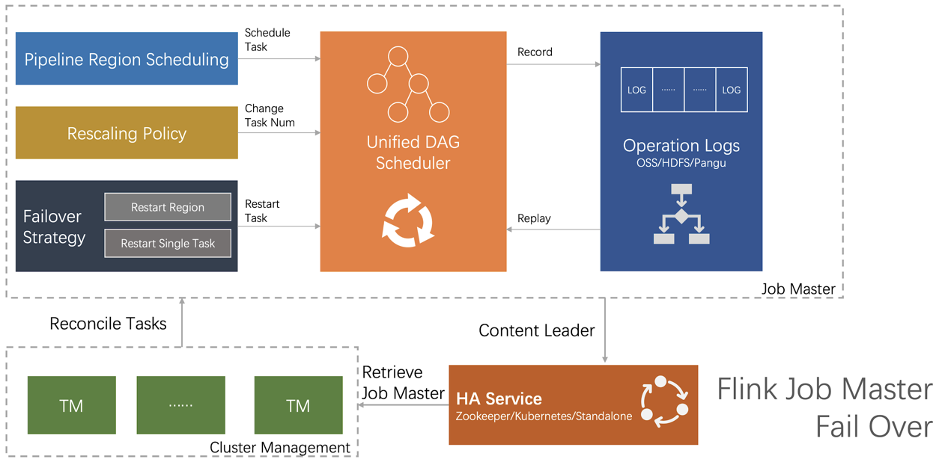
七、未來展望
評(píng)論
圖片
表情