
什么是時(shí)序數(shù)據(jù)?有哪些應(yīng)用場景?終于有人講明白了

導(dǎo)讀:本文主要講解時(shí)序數(shù)據(jù)的定義、典型特點(diǎn)、時(shí)序數(shù)據(jù)的應(yīng)用場景、數(shù)采難點(diǎn)及時(shí)序數(shù)據(jù)工具等內(nèi)容。

分析故障,看主要的設(shè)備故障是什么; 分析產(chǎn)能,看如何優(yōu)化配置來提升生產(chǎn)效率; 分析能耗,看如何降低生產(chǎn)成本; 分析潛在的安全隱患,以降低故障時(shí)長。

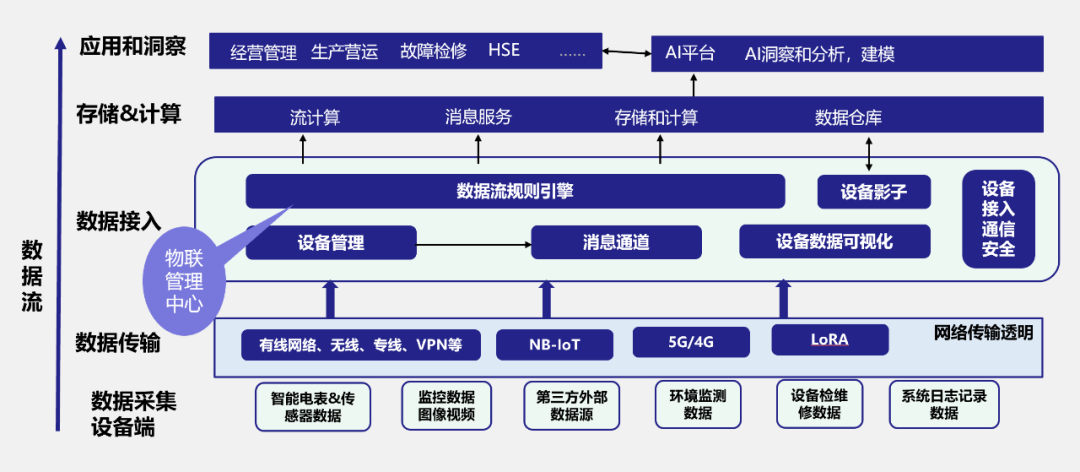
數(shù)據(jù)是時(shí)序的,一定帶有時(shí)間戳:聯(lián)網(wǎng)的設(shè)備按照設(shè)定的周期,或受外部事件的觸發(fā),源源不斷地產(chǎn)生數(shù)據(jù),每個(gè)數(shù)據(jù)點(diǎn)是在哪個(gè)時(shí)間點(diǎn)產(chǎn)生的,這個(gè)時(shí)間對(duì)于數(shù)據(jù)的計(jì)算和分析十分重要,必須要記錄。 數(shù)據(jù)是結(jié)構(gòu)化的:網(wǎng)絡(luò)爬蟲的數(shù)據(jù)、微博、微信的海量數(shù)據(jù)都是非結(jié)構(gòu)化的,可以是文字、圖片、視頻等。但物聯(lián)網(wǎng)設(shè)備產(chǎn)生的數(shù)據(jù)往往是結(jié)構(gòu)化的,而且是數(shù)值型的,比如智能電表采集的電流、電壓就可以用4字節(jié)的標(biāo)準(zhǔn)的浮點(diǎn)數(shù)來表示。 數(shù)據(jù)極少有更新操作:聯(lián)網(wǎng)設(shè)備產(chǎn)生的數(shù)據(jù)是機(jī)器日志數(shù)據(jù),一般不容許而且也沒有修改的必要。很少有場景,需要對(duì)采集的原始數(shù)據(jù)進(jìn)行修改。但對(duì)于一個(gè)典型的信息化或互聯(lián)網(wǎng)應(yīng)用,記錄是一定可以修改或刪除的。 數(shù)據(jù)源是唯一的:一個(gè)物聯(lián)網(wǎng)設(shè)備采集的數(shù)據(jù)與另外一個(gè)設(shè)備采集的數(shù)據(jù)是完全獨(dú)立的。一臺(tái)設(shè)備的數(shù)據(jù)一定是這臺(tái)設(shè)備產(chǎn)生的,不可能是人工或其他設(shè)備產(chǎn)生的,也就是說一臺(tái)設(shè)備的數(shù)據(jù)只有一個(gè)生產(chǎn)者,數(shù)據(jù)源是唯一的。 相對(duì)互聯(lián)網(wǎng)應(yīng)用,寫多讀少:對(duì)于互聯(lián)網(wǎng)應(yīng)用,一條數(shù)據(jù)記錄,往往是一次寫,很多次讀。比如一條微博或一篇微信公眾號(hào)文章,一次寫,但有可能會(huì)有上百萬人讀。但物聯(lián)網(wǎng)設(shè)備產(chǎn)生的數(shù)據(jù)不一樣,對(duì)于產(chǎn)生的數(shù)據(jù),一般是計(jì)算、分析程序自動(dòng)讀,而且計(jì)算、分析次數(shù)不多,只有分析事故等場景,人才會(huì)主動(dòng)看原始數(shù)據(jù)。 用戶關(guān)注的是一段時(shí)間的趨勢:對(duì)于一條銀行記錄,或者一條微博、微信,對(duì)于它的用戶而言,每一條都很重要。但對(duì)于物聯(lián)網(wǎng)數(shù)據(jù),每個(gè)數(shù)據(jù)點(diǎn)與數(shù)據(jù)點(diǎn)的變化并不大,一般是漸變的,大家關(guān)心的更多是一段時(shí)間,比如過去5分鐘,過去1小時(shí)數(shù)據(jù)變化的趨勢,一般對(duì)某一特定時(shí)間點(diǎn)的數(shù)據(jù)值并不關(guān)注。 數(shù)據(jù)是有保留期限的:采集的數(shù)據(jù)一般都有基于時(shí)長的保留策略,比如僅僅保留一天、一周、一個(gè)月、一年甚至更長時(shí)間,為節(jié)省存儲(chǔ)空間,系統(tǒng)最好能自動(dòng)刪除。 數(shù)據(jù)的查詢分析往往是基于時(shí)間段和某一組設(shè)備的:對(duì)于物聯(lián)網(wǎng)數(shù)據(jù),在做計(jì)算和分析時(shí),一定是指定時(shí)間范圍的,不會(huì)只針對(duì)一個(gè)時(shí)間點(diǎn)或者整個(gè)歷史進(jìn)行。而且往往需要根據(jù)分析的維度,對(duì)物聯(lián)網(wǎng)設(shè)備的一個(gè)子集采集的數(shù)據(jù)進(jìn)行分析,比如某個(gè)地理區(qū)域的設(shè)備,某個(gè)型號(hào)、某個(gè)批次的設(shè)備,某個(gè)廠商的設(shè)備。等等。 除存儲(chǔ)查詢外,往往需要實(shí)時(shí)分析計(jì)算操作:對(duì)于大部分互聯(lián)網(wǎng)大數(shù)據(jù)應(yīng)用,更多的是離線分析,即使有實(shí)時(shí)分析,但實(shí)時(shí)分析的要求并不高。比如用戶畫像,可以在積累一定的用戶行為數(shù)據(jù)后進(jìn)行。但是對(duì)于物聯(lián)網(wǎng)應(yīng)用,對(duì)數(shù)據(jù)的實(shí)時(shí)計(jì)算要求往往很高,因?yàn)樾枰鶕?jù)計(jì)算結(jié)果進(jìn)行實(shí)時(shí)報(bào)警,以避免事故的發(fā)生。 流量平穩(wěn)、可預(yù)測:給定物聯(lián)網(wǎng)數(shù)量、數(shù)據(jù)采集頻次,就可以較為準(zhǔn)確地估算出所需要的帶寬和流量、每天新生成的數(shù)據(jù)大小。 數(shù)據(jù)處理的特殊性:與典型的互聯(lián)網(wǎng)相比,還有不一樣的數(shù)據(jù)處理需求。比如要檢查某個(gè)具體時(shí)間的設(shè)備采集的某個(gè)量,但傳感器實(shí)際采集的時(shí)間不是這個(gè)時(shí)間點(diǎn),這時(shí)往往需要做插值處理。還有很多場景需要基于采集量進(jìn)行復(fù)雜的數(shù)學(xué)函數(shù)計(jì)算。 數(shù)據(jù)量巨大:以智能電表為例,一臺(tái)智能電表每隔15分鐘采集一次數(shù)據(jù),每天自動(dòng)生成96條記錄,全國就有接近5億臺(tái)智能電表,每天生成近500億條記錄。一臺(tái)聯(lián)網(wǎng)的汽車每隔10到15秒就采集一次數(shù)據(jù)發(fā)送到云端,一臺(tái)汽車一天就很容易產(chǎn)生1000條記錄。如果中國2億輛車全部聯(lián)網(wǎng),那么每天將產(chǎn)生2000億條記錄。5年之內(nèi),物聯(lián)網(wǎng)設(shè)備產(chǎn)生的數(shù)據(jù)將占世界數(shù)據(jù)總量的90%以上。
高并發(fā)、高吞吐量的寫入能力:如何支持每秒鐘上千萬數(shù)據(jù)點(diǎn)的寫入,這是最關(guān)鍵的技術(shù)能力。 數(shù)據(jù)高速聚合:如何支持以秒級(jí)的速度對(duì)上億數(shù)據(jù)進(jìn)行分組聚合運(yùn)算,如何能高效地在大數(shù)據(jù)量的基礎(chǔ)上將滿足條件的原始數(shù)據(jù)查詢出來并聚合,要知道統(tǒng)計(jì)的原始值可能因?yàn)闀r(shí)間比較久遠(yuǎn)而不在內(nèi)存中,因此這可能是一個(gè)非常耗時(shí)的操作。 降低存儲(chǔ)成本:如何降低海量數(shù)據(jù)存儲(chǔ)的成本,這需要時(shí)序數(shù)據(jù)庫提供高壓縮率。 多維度的查詢能力:時(shí)序數(shù)據(jù)通常會(huì)有多個(gè)維度的標(biāo)簽來刻畫一條數(shù)據(jù),如何根據(jù)幾個(gè)維度進(jìn)行高效查詢就是必須要解決的一個(gè)問題。
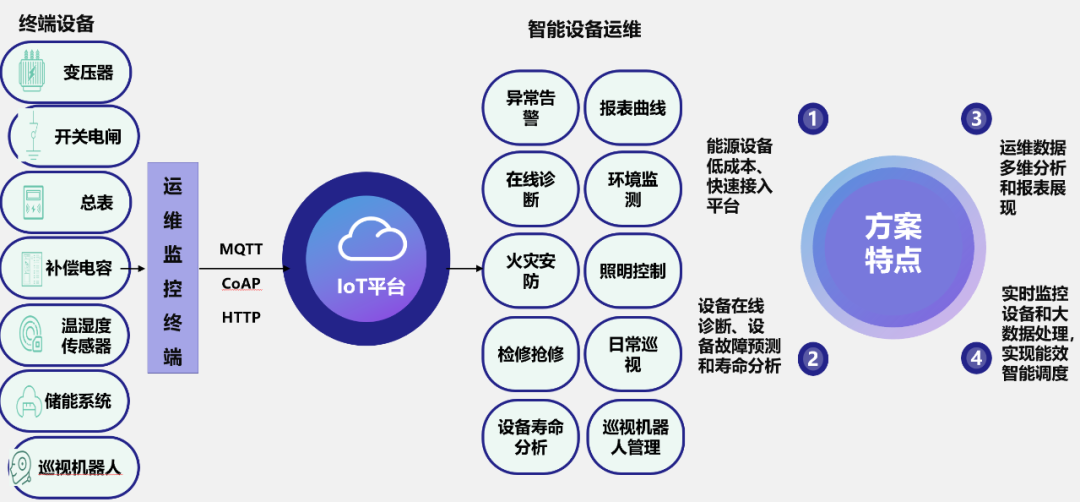
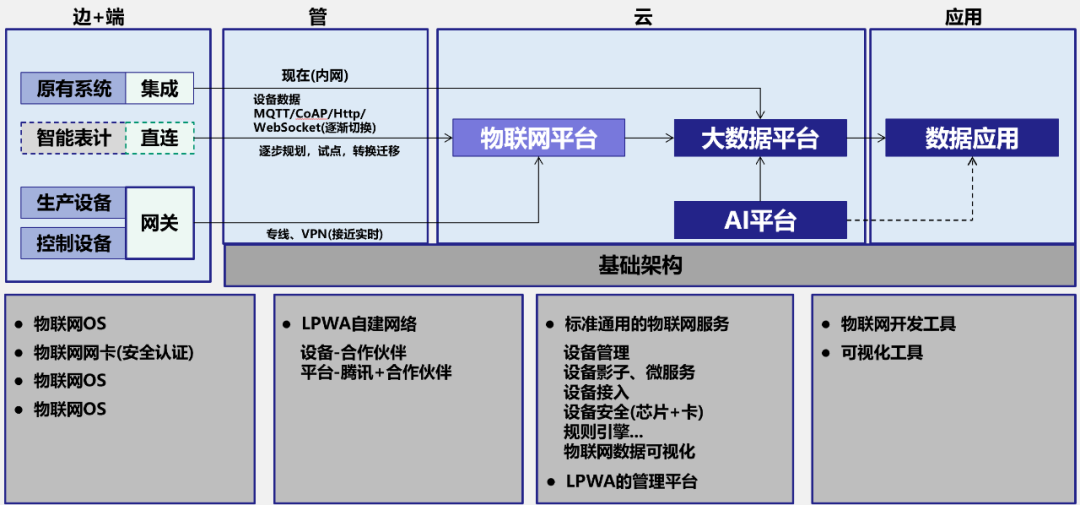
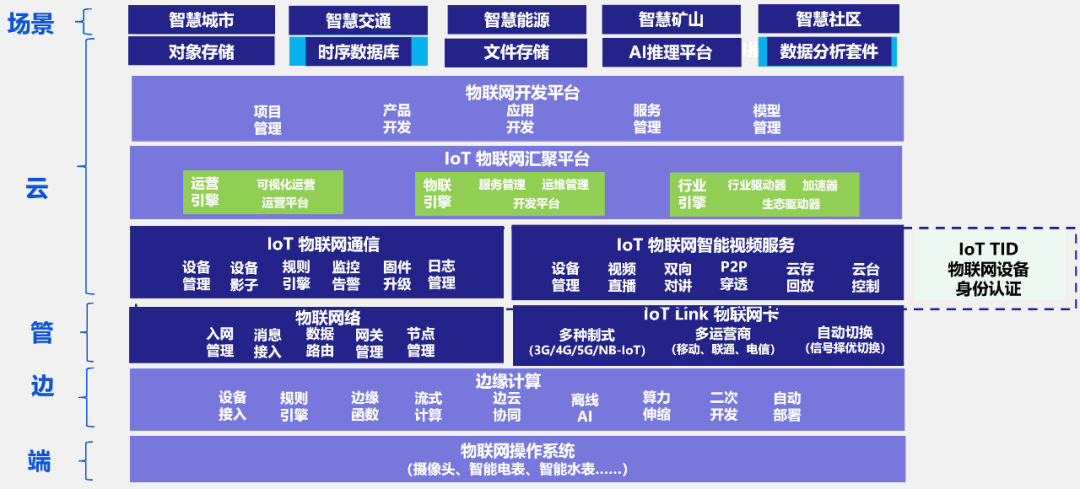
時(shí)序數(shù)據(jù)在各行各業(yè)有著廣泛應(yīng)用的,例如在電力行業(yè)智能電表、電網(wǎng)發(fā)電設(shè)備集中監(jiān)測; 在石油化工行業(yè)油井、運(yùn)輸管線運(yùn)輸車隊(duì)的實(shí)時(shí)監(jiān)測; 在園區(qū),在智慧城市實(shí)時(shí)路況、卡口數(shù)據(jù)路口流量監(jiān)測,在金融行業(yè)交易記錄、存取記錄ATM、POS機(jī)監(jiān)測,智能安防(樓宇門禁、車輛管理、井蓋、電子圍欄)、應(yīng)急響應(yīng)(消防、人群聚集、危化品、結(jié)構(gòu)健康、電梯)等。


以PI為代表的實(shí)時(shí)數(shù)據(jù)庫
沒有水平擴(kuò)展能力,數(shù)據(jù)量增加,只能依靠硬件的縱向擴(kuò)展解決。 技術(shù)架構(gòu)老舊,很多還是運(yùn)行于Windows系統(tǒng)中的。 數(shù)據(jù)分析能力偏弱,不支持現(xiàn)在流行的各種數(shù)據(jù)分析接口。 不支持云端部署,更不支持SaaS。 在傳統(tǒng)的實(shí)時(shí)監(jiān)控場景,由于對(duì)各種工業(yè)協(xié)議的支持比較完善,實(shí)時(shí)數(shù)據(jù)庫還占有較牢固的市場地位,但是在工業(yè)大數(shù)據(jù)處理上,因?yàn)樯鲜鰩讉€(gè)原因,幾乎沒有任何大數(shù)據(jù)平臺(tái)采用它們。
schemaless(無結(jié)構(gòu)),可以是任意數(shù)量的列 可擴(kuò)展(集群) 方便、強(qiáng)大的查詢語言 Native HTTP API 集成了數(shù)據(jù)采集、存儲(chǔ)、可視化功能 實(shí)時(shí)數(shù)據(jù)Downsampling 高效存儲(chǔ),使用高壓縮比算法,支持retention polices 數(shù)據(jù)采集支持多種協(xié)議和插件:行文本、UDP、Graphite、CollectD、OpenTSDB
存儲(chǔ)數(shù)值型時(shí)序列數(shù)據(jù) 根據(jù)請(qǐng)求對(duì)數(shù)據(jù)進(jìn)行可視化(畫圖)
高并發(fā)寫入:數(shù)據(jù)先寫入內(nèi)存,再周期性的 Dump 為不可變的文件存儲(chǔ)。且可以通過批量寫入數(shù)據(jù),降低網(wǎng)絡(luò)開銷 低成本存儲(chǔ):通過數(shù)據(jù)上卷(Rollup),對(duì)歷史數(shù)據(jù)做聚合,節(jié)省存儲(chǔ)空間。同時(shí)利用合理的編碼壓縮算法,提高數(shù)據(jù)壓縮比


無論是插入,還是查詢,性能都高出許多。 因?yàn)樾阅艹瑥?qiáng),其所需要的計(jì)算資源不及其他軟件的1/5。 采用列式存儲(chǔ),對(duì)不同數(shù)據(jù)類型采取不同的壓縮算法,所需要的存儲(chǔ)資源不到其他軟件的1/10。 無須分庫、分表,無實(shí)時(shí)數(shù)據(jù)與歷史數(shù)據(jù)之分,管理成本為零。 采用標(biāo)準(zhǔn)SQL語法,應(yīng)用可以通過標(biāo)準(zhǔn)的JDBC、ODBC接口插入或查詢數(shù)據(jù),學(xué)習(xí)成本幾乎為零。

評(píng)論
圖片
表情