
【NLP】如何在文本分類任務(wù)中Fine-Tune BERT
 問 題
問 題 ?目?標(biāo)
?目?標(biāo)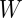 是task specific層的參數(shù),最后通過最大化log-probability of correct label優(yōu)化模型參數(shù)。
是task specific層的參數(shù),最后通過最大化log-probability of correct label優(yōu)化模型參數(shù)。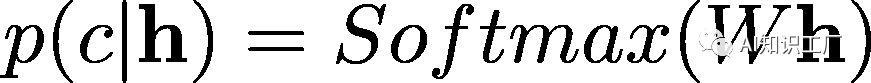
 方?法
方?法How to Fine-Tune BERT for Text Classification?[1]這篇論文從四個(gè)方面對BERT(BERT base)進(jìn)行不同形式的pretrain和fine-tune,并通過實(shí)驗(yàn)展示不同形式的pretrain和fine-tune之間的效果對比。
當(dāng)我們在特定任務(wù)上fine-tune BERT的時(shí)候,往往會(huì)有多種方法利用Bert,舉個(gè)例子:BERT的不同層往往代表著對不同語義或者語法特征的提取,并且對于不同的任務(wù),不同層表現(xiàn)出來的重要性和效果往往不太一樣。因此如何利用類似于這些信息,以及如何選擇一個(gè)最優(yōu)的優(yōu)化策略和學(xué)習(xí)率將會(huì)影響最終fine-tune 的效果。
對于長文本的處理
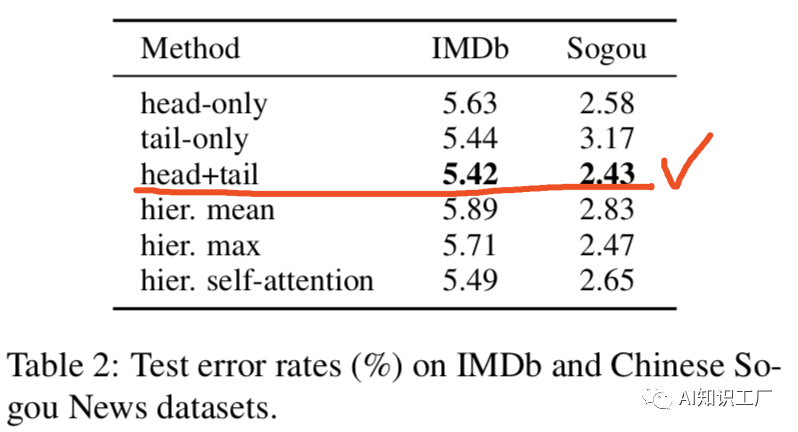
Fine-tune層的選擇
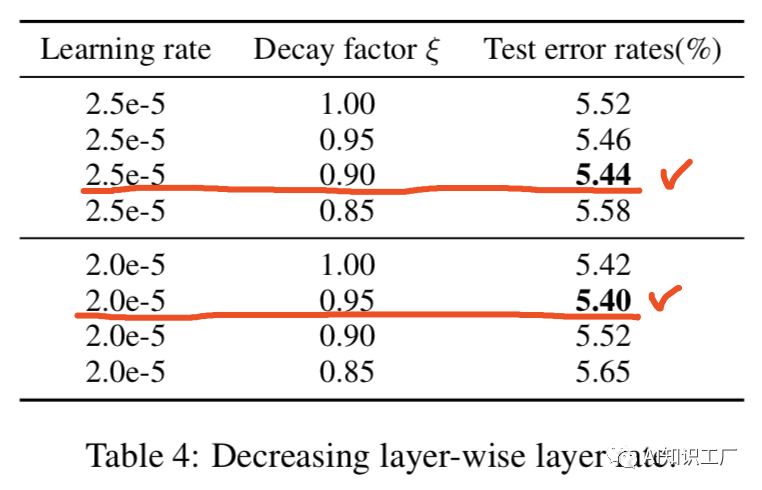
學(xué)習(xí)率優(yōu)化策略
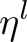 代表第l層的學(xué)習(xí)率,我們設(shè)定base learning rate為
代表第l層的學(xué)習(xí)率,我們設(shè)定base learning rate為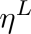 ,代表頂層的學(xué)習(xí)率,其他層的策略如公式(2)所示,其中
,代表頂層的學(xué)習(xí)率,其他層的策略如公式(2)所示,其中 是衰減系數(shù),如果
是衰減系數(shù),如果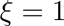 ,那么每層的學(xué)習(xí)率是一樣的,如果
,那么每層的學(xué)習(xí)率是一樣的,如果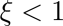 ,那么越往下的層學(xué)習(xí)率就越低。
,那么越往下的層學(xué)習(xí)率就越低。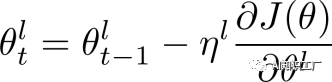 ?????(1)
?????(1)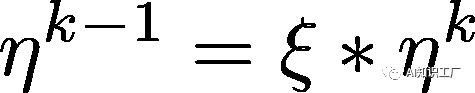 (2)
(2)
災(zāi)難性遺忘問題
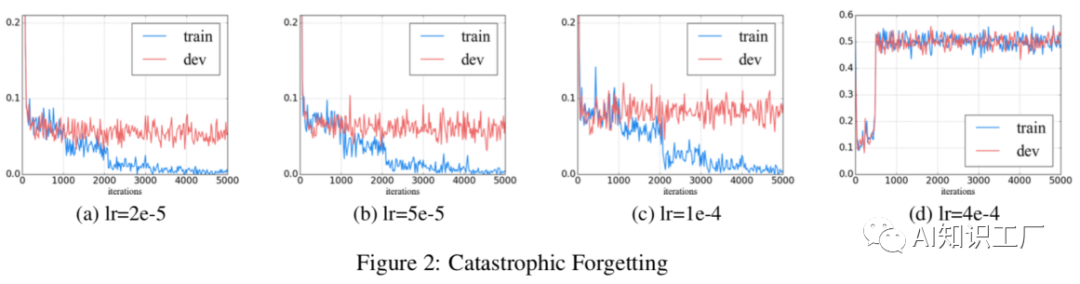
任務(wù)內(nèi)進(jìn)一步預(yù)訓(xùn)練:
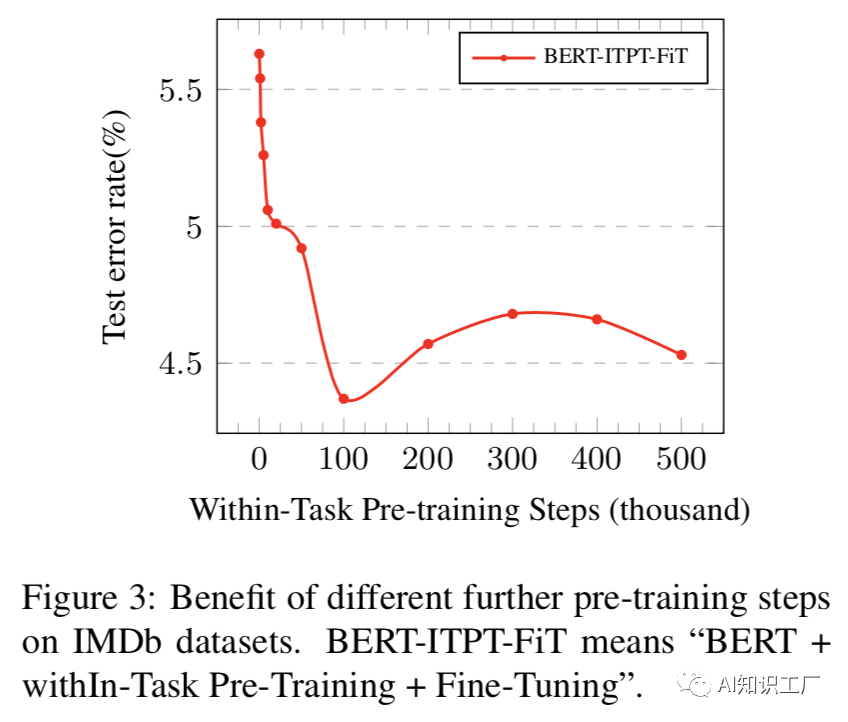
領(lǐng)域內(nèi)和交叉域內(nèi)的進(jìn)一步預(yù)訓(xùn)練:
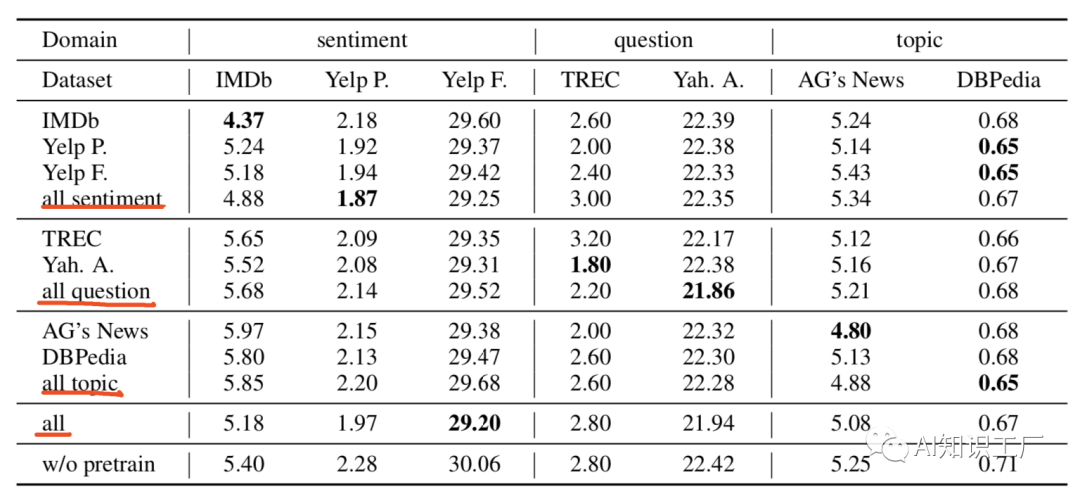
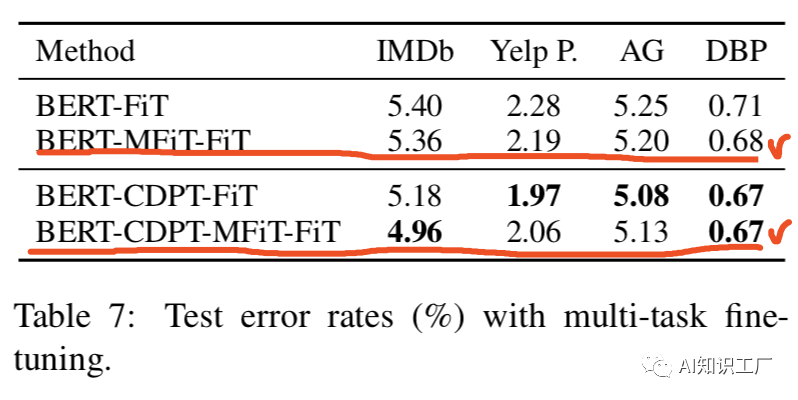
BERT-FiT? =? “BERT + Fine-Tuning”.
BERT-CDPT-MFiT-FiT = “BERT + Cross-Domain Pre-Training+Multi-Task Pre-Training+ Fine-Tuning”.(先在交叉域上做pretrain,然后在多任務(wù)域上做pretrain,最后在target-domian上做fine-tune)

往期精彩回顧
獲取本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群請掃碼:
評(píng)論
圖片
表情