
深度學(xué)習(xí)相關(guān)面試題

向AI轉(zhuǎn)型的程序員都關(guān)注了這個(gè)號(hào)???
人工智能大數(shù)據(jù)與深度學(xué)習(xí) ?公眾號(hào):datayx
1.CNN的特點(diǎn)以及優(yōu)勢(shì)
改變?nèi)B接為局部連接,這是由于圖片的特殊性造成的(圖像的一部分的統(tǒng)計(jì)特性與其他部分是一樣的),通過(guò)局部連接和參數(shù)共享大范圍的減少參數(shù)值。可以通過(guò)使用多個(gè)filter來(lái)提取圖片的不同特征(多卷積核)。
CNN使用范圍是具有局部空間相關(guān)性的數(shù)據(jù),比如圖像,自然語(yǔ)言,語(yǔ)音
1.局部連接:可以提取局部特征。
2.權(quán)值共享:減少參數(shù)數(shù)量,因此降低訓(xùn)練難度(空間、時(shí)間消耗都少了)。
3.可以完全共享,也可以局部共享(比如對(duì)人臉,眼睛鼻子嘴由于位置和樣式相對(duì)固定,可以用和臉部不一樣的卷積核)
4.降維:通過(guò)池化或卷積stride實(shí)現(xiàn)。
5.多層次結(jié)構(gòu):將低層次的局部特征組合成為較高層次的特征。不同層級(jí)的特征可以對(duì)應(yīng)不同任務(wù)。
2.deconv的作用
1.unsupervised learning:重構(gòu)圖像
2.CNN可視化:將conv中得到的feature map還原到像素空間,來(lái)觀察特定的feature map對(duì)哪些pattern的圖片敏感
3.Upsampling:上采樣。
3.dropout作用以及實(shí)現(xiàn)機(jī)制 (參考:https://blog.csdn.net/nini_coded/article/details/79302800)
1.dropout是指在深度學(xué)習(xí)網(wǎng)絡(luò)的訓(xùn)練過(guò)程中,對(duì)于神經(jīng)網(wǎng)絡(luò)單元,按照一定的概率將其暫時(shí)從網(wǎng)絡(luò)中丟棄。注意是暫時(shí),
對(duì)于隨機(jī)梯度下降來(lái)說(shuō),由于是隨機(jī)丟棄,故而每一個(gè)mini-batch都在訓(xùn)練不同的網(wǎng)絡(luò)。
2.dropout是一種CNN訓(xùn)練過(guò)程中防止過(guò)擬合提高效果的方法
3.dropout帶來(lái)的缺點(diǎn)是可能減慢收斂速度:由于每次迭代只有一部分參數(shù)更新,可能導(dǎo)致梯度下降變慢
4.測(cè)試時(shí),需要每個(gè)權(quán)值乘以P
4.深度學(xué)習(xí)中有什么加快收斂/降低訓(xùn)練難度的方法:
1.瓶頸結(jié)構(gòu)
2.殘差
3.學(xué)習(xí)率、步長(zhǎng)、動(dòng)量
4.優(yōu)化方法
5.預(yù)訓(xùn)練
5.什么造成過(guò)擬合,如何防止過(guò)擬合
1.data agumentation
2.early stop
3.參數(shù)規(guī)則化
4.用更簡(jiǎn)單模型
5.dropout
6.加噪聲
7.預(yù)訓(xùn)練網(wǎng)絡(luò)freeze某幾層
6.LSTM防止梯度彌散和爆炸
LSTM用加和的方式取代了乘積,使得很難出現(xiàn)梯度彌散。但是相應(yīng)的更大的幾率會(huì)出現(xiàn)梯度爆炸,但是可以通過(guò)給梯度加門(mén)限解決這一問(wèn)題
7.為什么很多做人臉的Paper會(huì)最后加入一個(gè)Local Connected Conv?
在一些研究成果中,作者通過(guò)實(shí)驗(yàn)表明:人臉在不同的區(qū)域存在不同的特征(眼睛/鼻子/嘴的分布位置相對(duì)固定),當(dāng)不存在全局的局部特征分布時(shí),Local-Conv更適合特征的提取。
8.神經(jīng)網(wǎng)絡(luò)權(quán)值初始化方式以及不同方式的區(qū)別?
權(quán)值初始化的方法主要有:常量初始化(constant)、高斯分布初始化(gaussian)、positive_unitball初始化、均勻分布初始化(uniform)、xavier初始化、msra初始化、雙線性初始化(bilinear)
9.Convolution、 pooling、 Normalization是卷積神經(jīng)網(wǎng)絡(luò)中十分重要的三個(gè)步驟,分別簡(jiǎn)述Convolution、 pooling和Normalization在卷積神經(jīng)網(wǎng)絡(luò)中的作用。
10.dilated conv(空洞卷積)優(yōu)缺點(diǎn)以及應(yīng)用場(chǎng)景
基于FCN的語(yǔ)義分割問(wèn)題中,需保持輸入圖像與輸出特征圖的size相同。
若使用池化層,則降低了特征圖size,需在高層階段使用上采樣,由于池化會(huì)損失信息,所以此方法會(huì)影響導(dǎo)致精度降低;
若使用較小的卷積核尺寸,雖可以實(shí)現(xiàn)輸入輸出特征圖的size相同,但輸出特征圖的各個(gè)節(jié)點(diǎn)感受野小;
若使用較大的卷積核尺寸,由于需增加特征圖通道數(shù),此方法會(huì)導(dǎo)致計(jì)算量較大;
所以,引入空洞卷積(dilatedconvolution),在卷積后的特征圖上進(jìn)行0填充擴(kuò)大特征圖size,這樣既因?yàn)橛芯矸e核增大感受野,也因?yàn)?填充保持計(jì)算點(diǎn)不變。
11.判別模型和生成模型解釋
監(jiān)督學(xué)習(xí)方法又分生成方法(Generative approach)和判別方法(Discriminative approach),所學(xué)到的模型分別稱(chēng)為生成模型(Generative Model)和判別模型(Discriminative Model)。
從概率分布的角度考慮,對(duì)于一堆樣本數(shù)據(jù),每個(gè)均有特征Xi對(duì)應(yīng)分類(lèi)標(biāo)記yi。
生成模型:學(xué)習(xí)得到聯(lián)合概率分布P(x,y),即特征x和標(biāo)記y共同出現(xiàn)的概率,然后求條件概率分布。能夠?qū)W習(xí)到數(shù)據(jù)生成的機(jī)制。
判別模型:學(xué)習(xí)得到條件概率分布P(y|x),即在特征x出現(xiàn)的情況下標(biāo)記y出現(xiàn)的概率。
數(shù)據(jù)要求:生成模型需要的數(shù)據(jù)量比較大,能夠較好地估計(jì)概率密度;而判別模型對(duì)數(shù)據(jù)樣本量的要求沒(méi)有那么多。
由生成模型可以得到判別模型,但由判別模型得不到生成模型。
12.如何判斷是否收斂
13.正則化方法以及特點(diǎn)
正則化方法包括:L1 regularization 、 L2 regularization 、 數(shù)據(jù)集擴(kuò)增 、 dropout 等
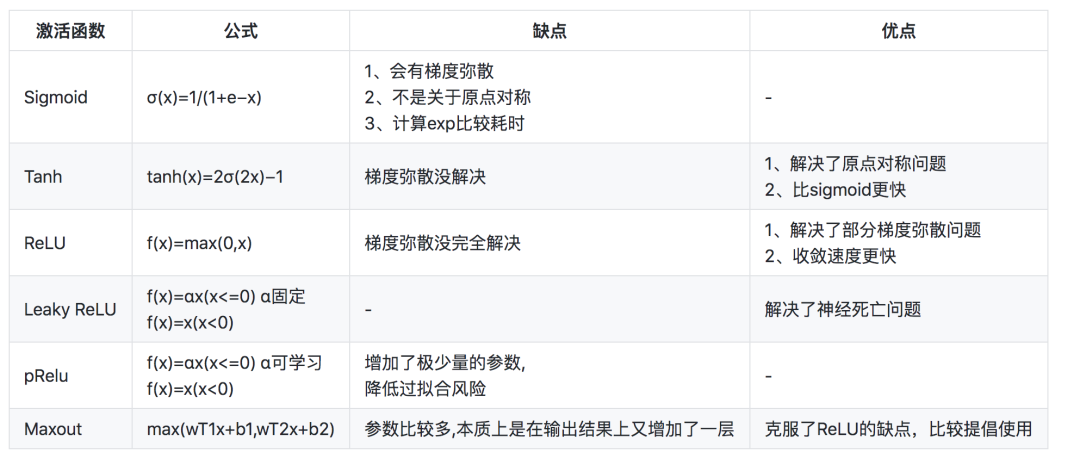
14.常用的激活函數(shù) (參考:https://blog.csdn.net/Yshihui/article/details/80540070)
15.1x1卷積的作用
1. 實(shí)現(xiàn)跨通道的信息交互和整合。1x1卷積核只有一個(gè)參數(shù),當(dāng)它作用在多通道的feature map上時(shí),相當(dāng)于不同通道上的一個(gè)線性組合,
實(shí)際上就是加起來(lái)再乘以一個(gè)系數(shù),但是這樣輸出的feature map就是多個(gè)通道的整合信息了,能夠使網(wǎng)絡(luò)提取的特征更加豐富。
2. feature map通道數(shù)上的降維。降維這個(gè)作用在GoogLeNet和ResNet能夠很好的體現(xiàn)。舉個(gè)例子:假設(shè)輸入的特征維度為100x100x128,
卷積核大小為5x5(stride=1,padding=2),通道數(shù)為256,則經(jīng)過(guò)卷積后輸出的特征維度為100x100x256,卷積參數(shù)量為
128x5x5x256=819200。此時(shí)在5x5卷積前使用一個(gè)64通道的1x1卷積,最終的輸出特征維度依然是100x100x256,但是此時(shí)的卷積參數(shù)
量為128x1x1x64 + 64x5x5x256=417792,大約減少一半的參數(shù)量。
3. 增加非線性映射次數(shù)。1x1卷積后通常加一個(gè)非線性激活函數(shù),使網(wǎng)絡(luò)提取更加具有判別信息的特征,同時(shí)網(wǎng)絡(luò)也能做的越來(lái)越深。
16.無(wú)監(jiān)督學(xué)習(xí)方法有哪些
強(qiáng)化學(xué)習(xí)、K-means 聚類(lèi)、自編碼、受限波爾茲曼機(jī)
17.增大感受野的方法?
空洞卷積、池化操作、較大卷積核尺寸的卷積操作
18.目標(biāo)檢測(cè)領(lǐng)域的常見(jiàn)算法?
1.兩階段檢測(cè)器:R-CNN、Fast R-CNN、Faster R-CNN
2.單階段檢測(cè)器:YOLO、YOLO9000、SSD、DSSD、RetinaNet
19.回歸問(wèn)題的評(píng)價(jià)指標(biāo)
1.平均絕對(duì)值誤差(MAE)
2.均方差(MSE)
20.卷積層和全連接層的區(qū)別
1.卷積層是局部連接,所以提取的是局部信息;全連接層是全局連接,所以提取的是全局信息;
2.當(dāng)卷積層的局部連接是全局連接時(shí),全連接層是卷積層的特例;
21.反卷積的棋盤(pán)效應(yīng)及解決方案
圖像生成網(wǎng)絡(luò)的上采樣部分通常用反卷積網(wǎng)絡(luò),不合理的卷積核大小和步長(zhǎng)會(huì)使反卷積操作產(chǎn)生棋盤(pán)效應(yīng)
解決方案:
22.分類(lèi)的預(yù)訓(xùn)練模型如何應(yīng)用到語(yǔ)義分割上
1.參考論文: Fully Convolutional Networks for Semantic Segmentation
23.SSD和YOLO的區(qū)別
24.交叉熵和softmax,還有它的BP
實(shí)踐部分
1.python中range和xrange有什么不同
兩者的區(qū)別是xrange返回的是一個(gè)可迭代的對(duì)象;range返回的則是一個(gè)列表,同時(shí)效率更高,更快。
2.python中帶類(lèi)和main函數(shù)的程序執(zhí)行順序
1)對(duì)于? if __name__ == '__main__': 的解釋相關(guān)博客已經(jīng)給出了說(shuō)明,意思就是當(dāng)此文件當(dāng)做模塊被調(diào)用時(shí),不會(huì)從這里執(zhí)行,
因?yàn)榇藭r(shí)name屬性就成了模塊的名字,而不是main。當(dāng)此文件當(dāng)做單獨(dú)執(zhí)行的程序運(yùn)行時(shí),就會(huì)從main開(kāi)始執(zhí)行。
2)對(duì)于帶有類(lèi)的程序,會(huì)先執(zhí)行類(lèi)及類(lèi)內(nèi)函數(shù),或者其他類(lèi)外函數(shù)。這里可以總結(jié)為,對(duì)于沒(méi)有縮進(jìn)的程序段,按照順序執(zhí)行。然后,才
到main函數(shù)。然后才按照main內(nèi)函數(shù)的執(zhí)行順序執(zhí)行。如果main內(nèi)對(duì)類(lèi)進(jìn)行了實(shí)例化,那么執(zhí)行到此處時(shí),只會(huì)對(duì)類(lèi)內(nèi)成員進(jìn)行初始
化,然后再返回到main 函數(shù)中。執(zhí)行其他實(shí)例化之后對(duì)象的成員函數(shù)調(diào)用。
3.神經(jīng)網(wǎng)絡(luò)的參數(shù)量計(jì)算
4.計(jì)算空洞卷積的感受野
5.mAP的計(jì)算
6.Python tuple和list的區(qū)別
7.Python的多線程和多進(jìn)程,Python偽多線程,什么時(shí)候應(yīng)該用它
8.tensorflow while_loop和python for循環(huán)的區(qū)別,什么情況下for更優(yōu)?
while loop的循環(huán)次數(shù)不確定的情況下效率低,因?yàn)橐粩嘀匦陆▓D
參考文獻(xiàn)
[1]?https://blog.csdn.net/u014722627/article/details/77938703
[2]?https://www.cnblogs.com/houjun/p/8535471.html
閱讀過(guò)本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實(shí)戰(zhàn)
基于40萬(wàn)表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測(cè)
《基于深度學(xué)習(xí)的自然語(yǔ)言處理》中/英PDF
Deep Learning 中文版初版-周志華團(tuán)隊(duì)
【全套視頻課】最全的目標(biāo)檢測(cè)算法系列講解,通俗易懂!
《美團(tuán)機(jī)器學(xué)習(xí)實(shí)踐》_美團(tuán)算法團(tuán)隊(duì).pdf
《深度學(xué)習(xí)入門(mén):基于Python的理論與實(shí)現(xiàn)》高清中文PDF+源碼
python就業(yè)班學(xué)習(xí)視頻,從入門(mén)到實(shí)戰(zhàn)項(xiàng)目
2019最新《PyTorch自然語(yǔ)言處理》英、中文版PDF+源碼
《21個(gè)項(xiàng)目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實(shí)踐詳解》完整版PDF+附書(shū)代碼
《深度學(xué)習(xí)之pytorch》pdf+附書(shū)源碼
PyTorch深度學(xué)習(xí)快速實(shí)戰(zhàn)入門(mén)《pytorch-handbook》
【下載】豆瓣評(píng)分8.1,《機(jī)器學(xué)習(xí)實(shí)戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車(chē)行業(yè)完整知識(shí)圖譜項(xiàng)目實(shí)戰(zhàn)視頻(全23課)
李沐大神開(kāi)源《動(dòng)手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計(jì)學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
將機(jī)器學(xué)習(xí)模型部署為REST API
FashionAI服裝屬性標(biāo)簽圖像識(shí)別Top1-5方案分享
重要開(kāi)源!CNN-RNN-CTC 實(shí)現(xiàn)手寫(xiě)漢字識(shí)別
同樣是機(jī)器學(xué)習(xí)算法工程師,你的面試為什么過(guò)不了?
前海征信大數(shù)據(jù)算法:風(fēng)險(xiǎn)概率預(yù)測(cè)
【Keras】完整實(shí)現(xiàn)‘交通標(biāo)志’分類(lèi)、‘票據(jù)’分類(lèi)兩個(gè)項(xiàng)目,讓你掌握深度學(xué)習(xí)圖像分類(lèi)
VGG16遷移學(xué)習(xí),實(shí)現(xiàn)醫(yī)學(xué)圖像識(shí)別分類(lèi)工程項(xiàng)目
特征工程(二) :文本數(shù)據(jù)的展開(kāi)、過(guò)濾和分塊
如何利用全新的決策樹(shù)集成級(jí)聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
全球AI挑戰(zhàn)-場(chǎng)景分類(lèi)的比賽源碼(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識(shí)別手寫(xiě)中文網(wǎng)站
中科院Kaggle全球文本匹配競(jìng)賽華人第1名團(tuán)隊(duì)-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號(hào)添加:?datayx??
機(jī)大數(shù)據(jù)技術(shù)與機(jī)器學(xué)習(xí)工程
?搜索公眾號(hào)添加:?datanlp
長(zhǎng)按圖片,識(shí)別二維碼