
【深度學(xué)習(xí)】?jī)H用256KB就實(shí)現(xiàn)單片機(jī)上的神經(jīng)網(wǎng)絡(luò)訓(xùn)練

1
『背景』
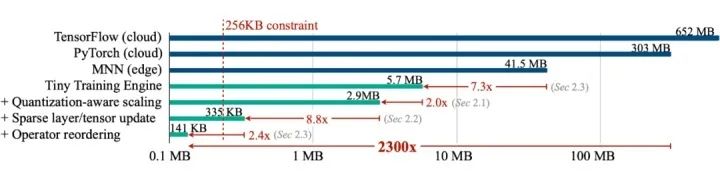
2
『方法』
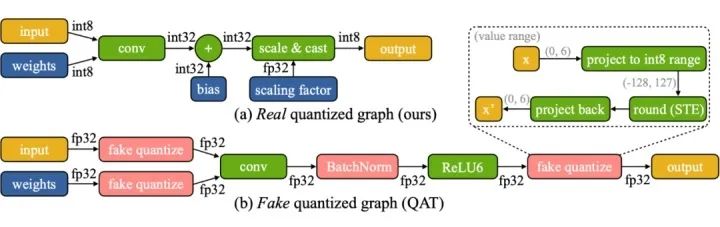

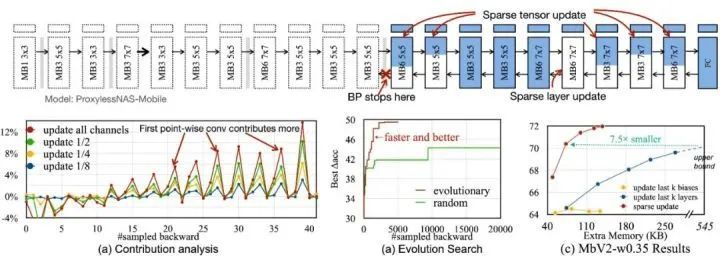

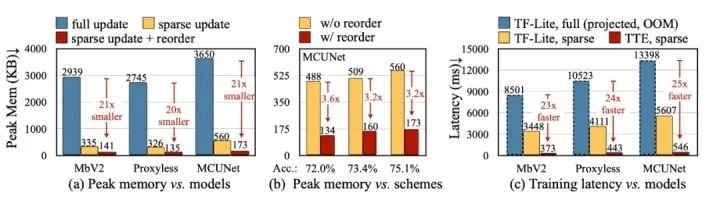
3
『結(jié)論』
往期精彩回顧
適合初學(xué)者入門(mén)人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門(mén)系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專(zhuān)輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請(qǐng)掃碼
評(píng)論
圖片
表情