
復(fù)習(xí)社招面試整體思路
今天也像往常一樣,早早起床來到公司,瀏覽了一下西安和太原的房價(jià)之后,心理不由自主地躁動(dòng)了起來,躺平是不可能躺平的,這輩子都不可能躺平。創(chuàng)業(yè)又不會(huì)創(chuàng),也就是卷這種東西,才能維持得了生活這樣。進(jìn)入程序員行業(yè)感覺就像回家一樣,這里個(gè)個(gè)都是人才,說話又都好聽,我超喜歡這里!
如何準(zhǔn)備社招。參考了幾個(gè)大佬的文章和視頻之后,今天圍繞這個(gè)問題來捋一捋思路,同時(shí)讓自己也順這個(gè)方向繼續(xù)學(xué)下去。爭取未來獲得更多的加速度來盡可能地削弱前段時(shí)間的謎之操作對我自己后續(xù)人生產(chǎn)生的負(fù)面影響。整體的思路圖如下所示,后續(xù)文章都圍繞這張圖展開。
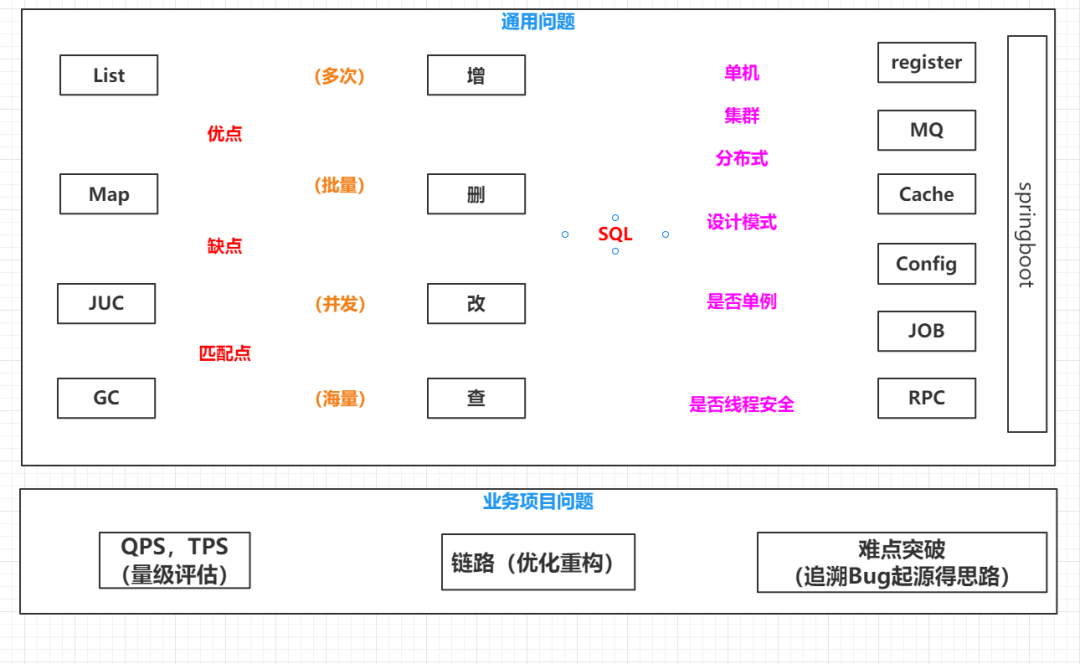
通用技術(shù)問題
每個(gè)技術(shù)點(diǎn)都有優(yōu)點(diǎn),缺點(diǎn),匹配點(diǎn)。任何一個(gè)技術(shù)點(diǎn),我們遇到之后都必須從這三個(gè)點(diǎn)進(jìn)行分析整理。
Java是面向?qū)ο螅嫦蚪涌诰幊痰摹R粋€(gè)接口有多個(gè)實(shí)現(xiàn)類,每一個(gè)實(shí)現(xiàn)類他的功能不一樣,特性不一樣。例如List,有ArrayList和LinkedList,所以很多面試問題都會(huì)有,ArrayList有什么優(yōu)點(diǎn),有什么缺點(diǎn),你的項(xiàng)目中為什么使用ArrayList,而不用LinkedList。同樣對于Map來說,有HashMap,LinkedHashMap,
TreeMap,ConCurrentHashMap。他們各自有什么優(yōu)點(diǎn),有什么缺點(diǎn),你的項(xiàng)目中為什么要用HashMap,為什么要使用ConcurrentHashMap。所以每一個(gè)技術(shù)點(diǎn)都可以從這三個(gè)點(diǎn)去想。
除了Java基礎(chǔ)之外,我們還會(huì)被問到很多框架,中間件之類的問題,而且占比一般都會(huì)超過Java基礎(chǔ)。這里通過抽象,一般我們都要了解這幾個(gè)東西,Cache緩存,MQ消息隊(duì)列,RPC框架,JOB定時(shí)任務(wù),Register組件,Config配置文件。
例如MQ來說,我們一般了解有三種實(shí)現(xiàn),RabbitMQ,RocketMQ,Kafka。他們各自有什么優(yōu)缺點(diǎn),你為什么要在你的項(xiàng)目中用到它。你的項(xiàng)目為什么要用到RabbitMQ,為什么不用Kafka。這個(gè)問題確實(shí)也被問到過,而且我們大部分人回答的都是,因?yàn)榧軜?gòu)師選擇的是這個(gè),然而這個(gè)回答肯定是不行的,明顯是個(gè)敷衍的回答。
然后是SQL語句的面試,一般我們擰螺絲肯定就是增刪改查了,大部分人的工作都是CRUD。但是造航母的話,就要在擰螺絲的任務(wù)上加上前綴。多次新增,批量修改,不批量刪除,并發(fā)修改,海量查詢。然后他們各自對應(yīng)的什么場景。
批量新增的時(shí)候,你怎么能夠保證新增是唯一的,如果說來了個(gè)業(yè)務(wù)數(shù)據(jù)他調(diào)用兩次新增,你給他生成兩條數(shù)據(jù),那肯定是有問題的,如何去保證冪等,如何保證唯一。
批量刪除的時(shí)候,怎么保證這個(gè)時(shí)候你的表可能有100萬條數(shù)據(jù),1千萬條數(shù)據(jù)或者1億條數(shù)據(jù),這個(gè)時(shí)候你要怎么刪除,直接delete一把刪掉嗎。如果要求你跑個(gè)一萬條然后停頓個(gè)0.5秒之類的。
并發(fā)修改,如何去保證數(shù)據(jù)的準(zhǔn)確,就是你改的確實(shí)是你想改的,或者你現(xiàn)在改的,就是你想改的那個(gè)數(shù)據(jù)。如果有兩個(gè)的話,第一個(gè)過來先把它改成1,第二個(gè)想把它改成3,你怎么保證你改的是正確的,不會(huì)造成數(shù)據(jù)的一個(gè)缺失,對賬錯(cuò)誤之類的。
海量查詢,當(dāng)數(shù)據(jù)級達(dá)到一定量度的時(shí)候,最開始,假如數(shù)據(jù)庫就那么10條數(shù)據(jù),你隨便select *也好,想怎么玩,就怎么玩。當(dāng)數(shù)據(jù)量大的時(shí)候,就要考慮怎么去建立索引,你的Sql怎么寫是滿足索引的。
然后再往后面一塊是各個(gè)中間件,我們學(xué)習(xí)得時(shí)候,可能都用的單機(jī)模式,就我們在自己的電腦上,去啟動(dòng)一個(gè)單機(jī)的redis,然后往里面去插數(shù)據(jù),取數(shù)據(jù),我們起一個(gè)單機(jī)的apollo,去往里面寫配置,取配置。
但是實(shí)際上,基本上現(xiàn)在我們用的中間件,他們都是支持集群和分布式的,這個(gè)時(shí)候,它就有集群的特性,也有分布式的特性。分布式有什么特性,經(jīng)典的CAP理論,你要知道哪個(gè)中間件它是符合CAP中的什么的,然后他是有什么特性。最后是這個(gè)中間件是怎么能夠在我們的項(xiàng)目中用出來。
我們現(xiàn)在大部分項(xiàng)目都是Springboot,那么Springboot怎么跟他們?nèi)ハ嘟Y(jié)合呢,然后能夠?yàn)槟愕捻?xiàng)目進(jìn)行助力,然后對Spring,還有本身的以及每個(gè)中間件,除了單機(jī)集群分布式,這些運(yùn)行模式之外,還會(huì)有些知識(shí)點(diǎn),就是他們這邊用的什么設(shè)計(jì)模式,設(shè)計(jì)模式這一塊,基本上社招的時(shí)候都會(huì)問到,像Spring中的一些設(shè)計(jì)模式啊,單例工廠組合模板,這個(gè)是必須要非常熟練的背下來的。
然后是否是單例,當(dāng)你在看源碼的時(shí)候,就是面試官喜歡考察你什么呢,就是非常典型的題目,就是一些非常典型的類,他會(huì)問你這個(gè)類,在這個(gè)中間件加載的時(shí)候,他是否是單例的,一般來說只要是配置類的話,基本上都是單例的,那么其他的典型類呢,這個(gè)就要具體問題具體分析了,去看源碼。
然后第三個(gè)問題是是否是線程安全的,就比如Spring中,他哪些關(guān)鍵的方法是加了鎖的,他為什么在這里加鎖。如果這些隨便一個(gè)問題,我們對這個(gè)沒有概念的話,就會(huì)感覺到面試官又在瞎問了。
業(yè)務(wù)項(xiàng)目問題
程序員這行跳槽,其實(shí)并沒有太受行業(yè)的限制,你可能上一家是在一個(gè)房地產(chǎn)公司做開發(fā),那么下一次呢可能是在一個(gè)金融公司做開發(fā),在下一次呢,很可能在一個(gè)醫(yī)療領(lǐng)域開發(fā),在哪兒不都是寫代碼,在哪兒都是增刪改查。你很有可能和你的面試官不是一個(gè)行業(yè)的。所以這個(gè)時(shí)候業(yè)務(wù)上問題,就根據(jù)你簡歷上寫的項(xiàng)目,也會(huì)去問一些項(xiàng)目相關(guān)的問題。
第一個(gè)問題必問的是你現(xiàn)在做的一個(gè)業(yè)務(wù)是多大的一個(gè)量級。他的qps,或者tps是多少。這個(gè)時(shí)候你就要估計(jì)一下了。我們舉個(gè)例子,比如說一個(gè)電商網(wǎng)站,一天又100萬的UV,那么我們除以,比如他平均分布在10個(gè)小時(shí)上,我們除以10,那就是每個(gè)小時(shí)大概會(huì)有10萬的UV,就是網(wǎng)站訪問量。然后我們假設(shè)某個(gè)特定的時(shí)間段,比如說下午中午那一塊,還有是訪問量比較多的乘以2,那就等于一個(gè)小時(shí)有20萬的UV。然后再除以3600s。最后得到的這個(gè)數(shù)字就是你的qps。所以在估計(jì)的時(shí)候,一定要根據(jù)自己的業(yè)務(wù)量估,不要瞎估就隨口就報(bào)。一個(gè)qps 10000,我們qps20000,面試官都直接驚掉了下巴。
然后當(dāng)你報(bào)出了自己的qps之后,面試官往往都會(huì)問一句說,假如你現(xiàn)在業(yè)務(wù)量翻了10倍,以后就qps乘以10,或者說qps乘以100,這個(gè)時(shí)候你怎么辦。如何搭建一個(gè)高并發(fā)的系統(tǒng),你就順著你看的思路,如何去做頁面緩存,怎么去做nginx緩存,然后nginx如何轉(zhuǎn)發(fā),如何負(fù)載均衡。然后怎么到服務(wù)器上來,然后繼續(xù)做本地緩存,redis,然后數(shù)據(jù)庫這里做個(gè)讀寫分離。讀寫分庫,最后再搞個(gè)分庫分表這些玩意兒。你就一步分析他到什么量級的時(shí)候,他的瓶頸是哪里,然后有了這個(gè)瓶頸之后,我們怎么去解決這個(gè)問題。一步一步過來就可以了。
然后第二個(gè)問題,200%會(huì)問到,你的業(yè)務(wù)鏈路是什么。所謂的鏈路就是你負(fù)責(zé)的這個(gè)模塊,他的上游是什么,你的下游是什么。你的上游就是誰給你數(shù)據(jù),你的下游就是誰會(huì)消費(fèi)你的數(shù)據(jù)。然后你把這個(gè)鏈路描述清楚之后,后面就是問你怎么去優(yōu)化他,怎么去重構(gòu)他。所有的技術(shù)方案和業(yè)務(wù)背景是分不開的,當(dāng)你在談某個(gè)技術(shù)方案的時(shí)候,一定是跟他業(yè)務(wù)背景是強(qiáng)相關(guān)強(qiáng)綁定的,所以這個(gè)時(shí)候在說優(yōu)化或者重構(gòu)的時(shí)候,不要直接這樣泛泛而談。一定要先說,我們現(xiàn)在是在做一個(gè)什么業(yè)務(wù),然后這個(gè)業(yè)務(wù)有什么特點(diǎn),比如說這個(gè)業(yè)務(wù)還是讀多寫少,寫多讀少,比如說這個(gè)業(yè)務(wù)對實(shí)時(shí)性要求不高,那么在這個(gè)前提下,我們再去優(yōu)化我們的技術(shù)方案或者重構(gòu)方案。比如說如果是一個(gè)讀多寫少的一個(gè)業(yè)務(wù)場景的話,我們就把讀庫寫庫拆開,或者我們就多做緩存。如果說對實(shí)時(shí)性要求非常高的話,那用強(qiáng)一致性的數(shù)據(jù)是吧,一定是有業(yè)務(wù)場景的。
第三點(diǎn),這個(gè)是1000%會(huì)問的一個(gè)點(diǎn)。你在項(xiàng)目中遇到哪些難點(diǎn),或者你在做項(xiàng)目中最自豪的,最驕傲最有成就感的一點(diǎn)是哪里。這個(gè)呢,你可以說遇到一個(gè)源碼級別的bug,或者源碼級別的參數(shù),然后你通過百度谷歌博客各種方式,發(fā)現(xiàn)博客寫錯(cuò)了,然后自己跟著搞了半天,沒搞定,然后呢點(diǎn)進(jìn)了源碼,再debug,然后怎么配置參數(shù),傳遞參數(shù),模擬啊各種操作,最終找到了是某個(gè)參數(shù)錯(cuò)了,然后感覺好開心,好激動(dòng)。所以呢這個(gè)是純技術(shù)方面的,這個(gè)時(shí)候要注意你的思路。
然后我們還要注意一個(gè)詞叫影響力,比如在gitHub上擁有一個(gè)star很多的項(xiàng)目,在某個(gè)博客上有很多技術(shù)文章,記錄自己做開發(fā)以來遇到的bug以及解決方式,還有自己對很多新技術(shù)的分析與學(xué)習(xí)筆記等。這個(gè)算是一張個(gè)人名片了,有時(shí)候甚至要比學(xué)歷管用。