
面試 | 校招社招中常見的算法套路
咱們在面試程序員崗位時(shí)往往需要經(jīng)歷一個(gè)編程面試過程,雇主會(huì)借此考驗(yàn)面試者的技術(shù)實(shí)力。
然而,這些技術(shù)問題有時(shí)候卻和我們的實(shí)際工作并無太大關(guān)系,也由此可能給我們的編程面試準(zhǔn)備階段帶來很大的壓力。
曾在 Facebook 和微軟工作過的 Educative.io 創(chuàng)始人 Fahim ul Haq 近日發(fā)文總結(jié)了編程面試所遇到的問題的 14 種最常見的模式,也許能幫你看清各種編程面試問題「背后的真相」。

對很多開發(fā)者來說,編程工作的面試準(zhǔn)備很容易讓人焦慮。面試要涉及的東西實(shí)在太多,其中很多還往往與開發(fā)者的日常工作無關(guān),只會(huì)額外增添壓力。
這種現(xiàn)狀導(dǎo)致了一個(gè)后果:現(xiàn)在的開發(fā)者往往需要花費(fèi)數(shù)周時(shí)間在 LeetCode 等網(wǎng)站上了解綜合數(shù)百個(gè)問題。
與我談過的開發(fā)者在面試前的一個(gè)常見焦慮問題是:我是否已經(jīng)解決過足夠多的實(shí)際問題?我本可以做到更多嗎?
這就是我想要幫助開發(fā)者了解每個(gè)問題背后的底層模式的原因——這樣他們就不必?fù)?dān)憂解決數(shù)百個(gè)問題以及被 LeetCode 整得疲憊不堪了。
如果你理解面試的通用模式,你就可以將其用作模板,從而解決各種層級的稍有不同的問題。
這里我將列出最常見的 14 種模式,它們可被用于解決任何編程面試問題。
另外我還會(huì)說明如何識(shí)別每種模式,并會(huì)為每種模式提供一些問題示例。
這些內(nèi)容都只是蜻蜓點(diǎn)水——我強(qiáng)烈建議你看看課程《Grokking the Coding Interview: Patterns for Coding Questions》,里面提供了全面的解釋、示例和編程實(shí)踐。
下面的模式說明假設(shè)你已經(jīng)知悉了數(shù)據(jù)結(jié)構(gòu)。如果你還不了解,那需要補(bǔ)充一下知識(shí)點(diǎn)哦。
我們今天將說明以下 14 種模式:
1.滑動(dòng)窗口 2.二指針或迭代器 3.快速和慢速指針或迭代器 4.合并區(qū)間 5.循環(huán)排序 6.原地反轉(zhuǎn)鏈表 7.樹的寬度優(yōu)先搜索(Tree BFS) 8.樹的深度優(yōu)先搜索(Tree DFS) 9.Two Heaps 10.子集 11.經(jīng)過修改的二叉搜索 12.前 K 個(gè)元素 13.K 路合并 14.拓?fù)渑判?/section>
我們開始吧!
1.滑動(dòng)窗口
滑動(dòng)窗口模式是用于在給定數(shù)組或鏈表的特定窗口大小上執(zhí)行所需的操作,比如尋找包含所有 1 的最長子數(shù)組。
從第一個(gè)元素開始滑動(dòng)窗口并逐個(gè)元素地向右滑,并根據(jù)你所求解的問題調(diào)整窗口的長度。
在某些情況下窗口大小會(huì)保持恒定,在其它情況下窗口大小會(huì)增大或減小。
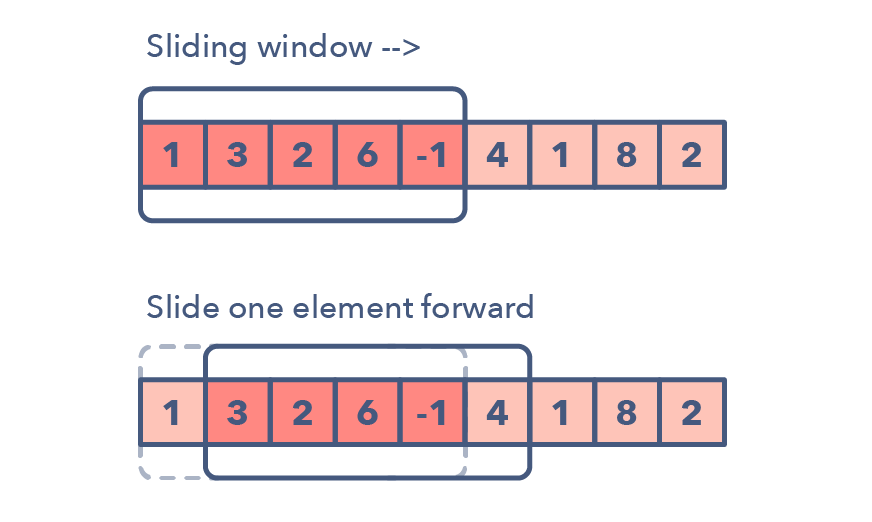
下面是一些你可以用來確定給定問題可能需要滑動(dòng)窗口的方法:
問題的輸入是一種線性數(shù)據(jù)結(jié)構(gòu),比如鏈表、數(shù)組或字符串 你被要求查找最長/最短的子字符串、子數(shù)組或所需的值
你可以使用滑動(dòng)窗口模式處理的常見問題:
大小為 K 的子數(shù)組的最大和(簡單) 帶有 K 個(gè)不同字符的最長子字符串(中等) 尋找字符相同但排序不一樣的字符串(困難)
2.二指針或迭代器
二指針(Two Pointers)是這樣一種模式:
兩個(gè)指針以一前一后的模式在數(shù)據(jù)結(jié)構(gòu)中迭代,直到一個(gè)或兩個(gè)指針達(dá)到某種特定條件。
二指針通常在排序數(shù)組或鏈表中搜索配對時(shí)很有用:比如當(dāng)你必須將一個(gè)數(shù)組的每個(gè)元素與其它元素做比較時(shí)。
二指針是很有用的,因?yàn)槿绻挥幸粋€(gè)指針,你必須繼續(xù)在數(shù)組中循環(huán)回來才能找到答案。
這種使用單個(gè)迭代器進(jìn)行來回在時(shí)間和空間復(fù)雜度上都很低效——這個(gè)概念被稱為「漸進(jìn)分析(asymptotic analysis)」。
盡管使用 1 個(gè)指針進(jìn)行暴力搜索或簡單普通的解決方案也有效果,但這會(huì)沿 O(n2) 線得到一些東西。在很多情況中,二指針有助于你尋找有更好空間或運(yùn)行時(shí)間復(fù)雜度的解決方案。
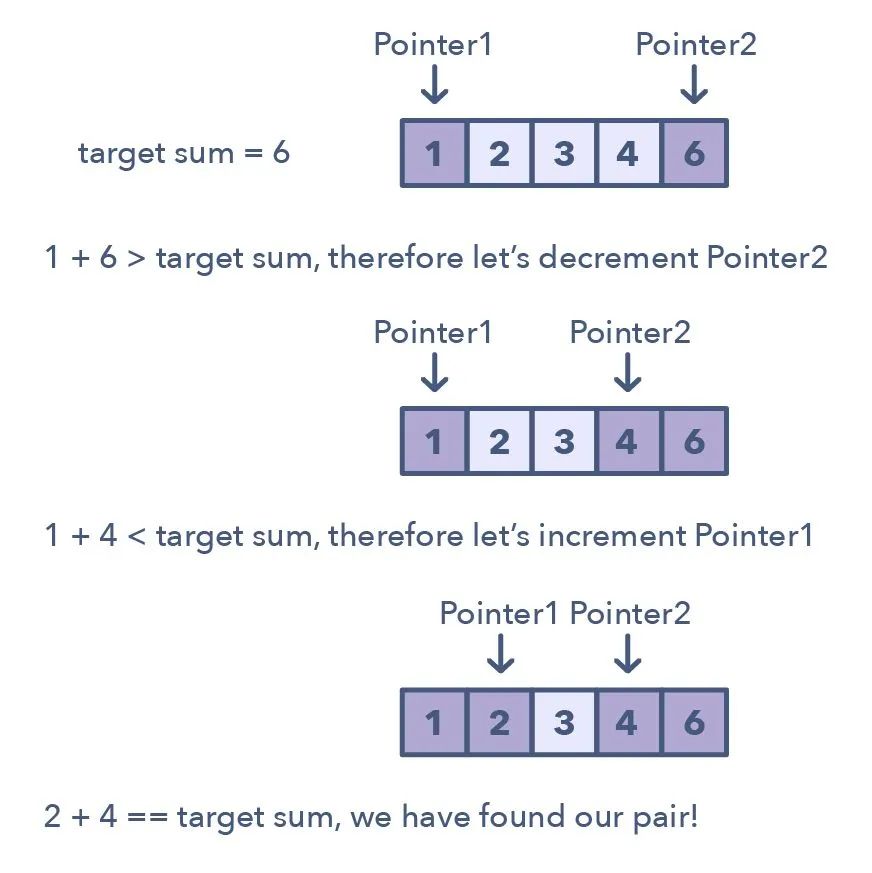
用于識(shí)別使用二指針的時(shí)機(jī)的方法:
可用于你要處理排序數(shù)組(或鏈接列表)并需要查找滿足某些約束的一組元素的問題 數(shù)組中的元素集是配對、三元組甚至子數(shù)組
下面是一些滿足二指針模式的問題:
求一個(gè)排序數(shù)組的平方(簡單) 求總和為零的三元組(中等) 比較包含回退(backspace)的字符串(中等)
3.快速和慢速指針
快速和慢速指針方法也被稱為 Hare & Tortoise 算法,該算法會(huì)使用兩個(gè)在數(shù)組(或序列/鏈表)中以不同速度移動(dòng)的指針。該方法在處理循環(huán)鏈表或數(shù)組時(shí)非常有用。
通過以不同的速度進(jìn)行移動(dòng)(比如在一個(gè)循環(huán)鏈表中),該算法證明這兩個(gè)指針注定會(huì)相遇。只要這兩個(gè)指針在同一個(gè)循環(huán)中,快速指針就會(huì)追趕上慢速指針。
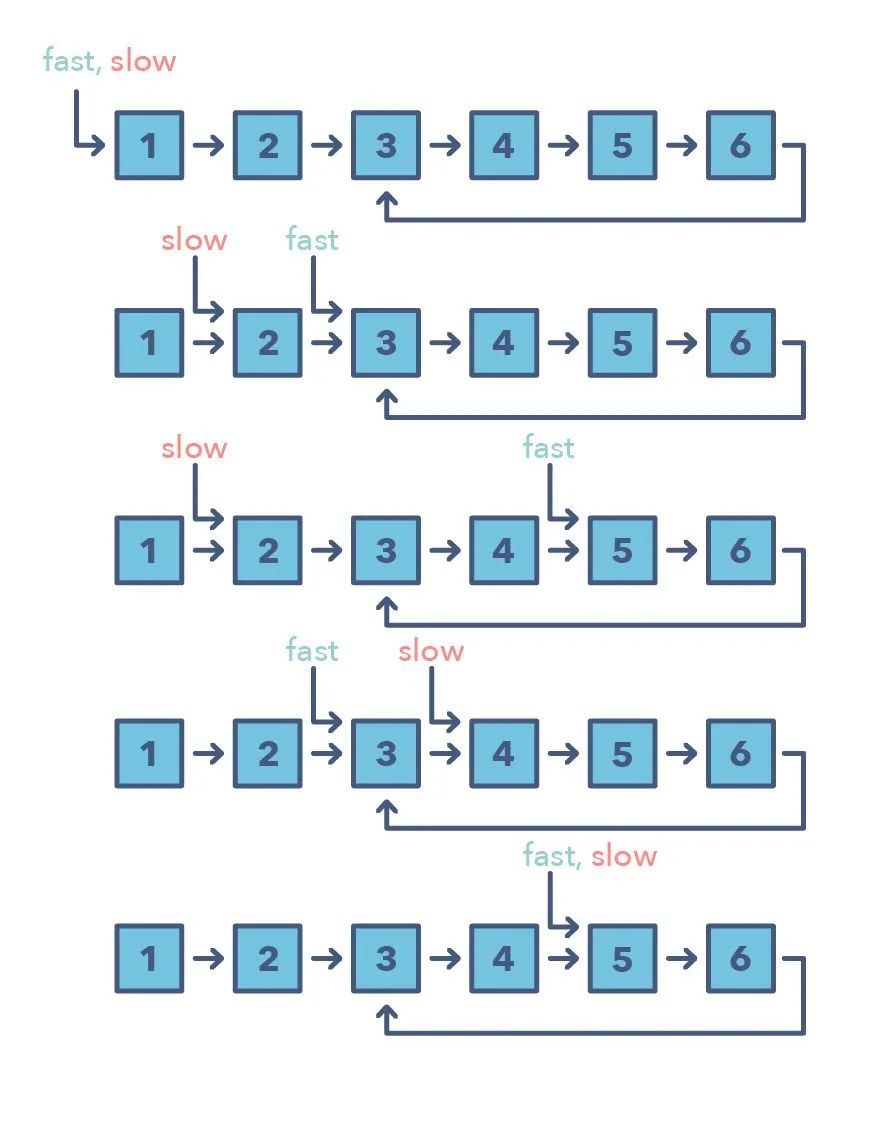
如何判別使用快速和慢速模式的時(shí)機(jī)?
處理鏈表或數(shù)組中的循環(huán)的問題 當(dāng)你需要知道特定元素的位置或鏈表的總長度時(shí)
何時(shí)應(yīng)該優(yōu)先選擇這種方法,而不是上面提到的二指針方法?
有些情況不適合使用二指針方法,比如在不能反向移動(dòng)的單鏈接鏈表中。使用快速和慢速模式的一個(gè)案例是當(dāng)你想要確定一個(gè)鏈表是否為回文(palindrome)時(shí)。
下面是一些滿足快速和慢速指針模式的問題:
鏈表循環(huán)(簡單) 回文鏈表(中等) 環(huán)形數(shù)組中的循環(huán)(困難)
4.合并區(qū)間
合并區(qū)間模式是一種處理重疊區(qū)間的有效技術(shù)。
在很多涉及區(qū)間的問題中,你既需要找到重疊的區(qū)間,也需要在這些區(qū)間重疊時(shí)合并它們。該模式的工作方式為:
給定兩個(gè)區(qū)間(a 和 b),這兩個(gè)區(qū)間有 6 種不同的互相關(guān)聯(lián)的方式:
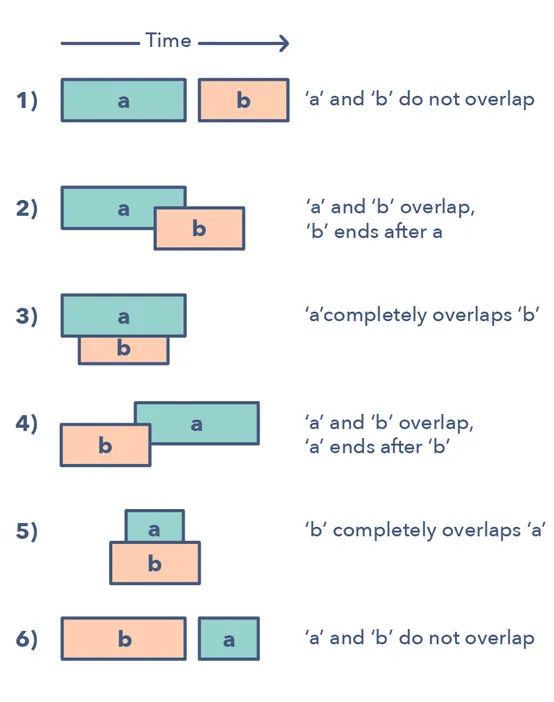
理解并識(shí)別這六種情況有助于你求解范圍廣泛的問題,從插入?yún)^(qū)間到優(yōu)化區(qū)間合并等。
那么如何確定何時(shí)該使用合并區(qū)間模式呢?
如果你被要求得到一個(gè)僅含互斥區(qū)間的列表 如果你聽到了術(shù)語「重疊區(qū)間(overlapping intervals)」
合并區(qū)間模式的問題:
區(qū)間交叉(中等) 最大 CPU 負(fù)載(困難)
5. 循環(huán)排序
這一模式描述了一種有趣的方法,處理的是涉及包含給定范圍內(nèi)數(shù)值的數(shù)組的問題。
循環(huán)排序模式一次會(huì)在數(shù)組上迭代一個(gè)數(shù)值,如果所迭代的當(dāng)前數(shù)值不在正確的索引處,就將其與其正確索引處的數(shù)值交換。
你可以嘗試替換其正確索引處的數(shù)值,但這會(huì)帶來 O(n^2) 的復(fù)雜度,這不是最優(yōu)的,因此要用循環(huán)排序模式。
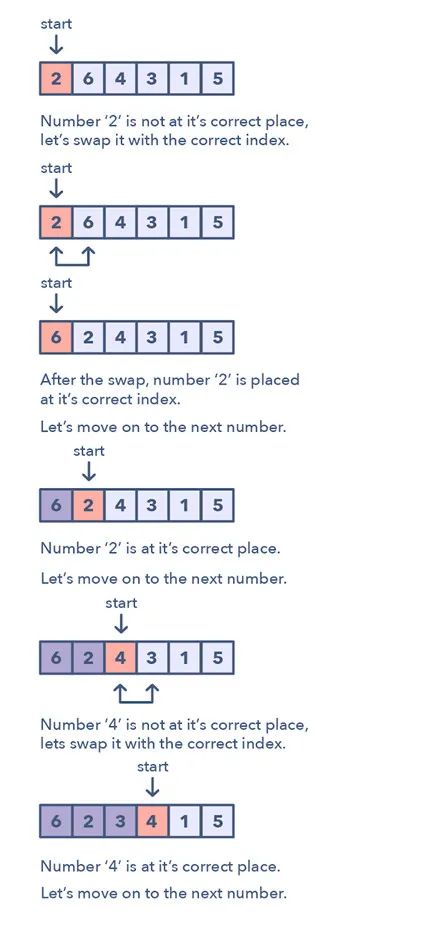
如何識(shí)別這種模式?
涉及數(shù)值在給定范圍內(nèi)的排序數(shù)組的問題 如果問題要求你在一個(gè)排序/旋轉(zhuǎn)的數(shù)組中找到缺失值/重復(fù)值/最小值
循環(huán)排序模式的問題:
找到缺失值(簡單) 找到最小的缺失的正數(shù)值(中等)
6. 原地反轉(zhuǎn)鏈表
在很多問題中,你可能會(huì)被要求反轉(zhuǎn)一個(gè)鏈表中一組節(jié)點(diǎn)之間的鏈接。
通常而言,你需要原地完成這一任務(wù),即使用已有的節(jié)點(diǎn)對象且不占用額外的內(nèi)存。這就是這個(gè)模式的用武之地。
該模式會(huì)從一個(gè)指向鏈表頭的變量(current)開始一次反轉(zhuǎn)一個(gè)節(jié)點(diǎn),然后一個(gè)變量(previous)將指向已經(jīng)處理過的前一個(gè)節(jié)點(diǎn)。
以鎖步的方式,在移動(dòng)到下一個(gè)節(jié)點(diǎn)之前將其指向前一個(gè)節(jié)點(diǎn),可實(shí)現(xiàn)對當(dāng)前節(jié)點(diǎn)的反轉(zhuǎn)。
另外,也將更新變量「previous」,使其總是指向已經(jīng)處理過的前一個(gè)節(jié)點(diǎn)。
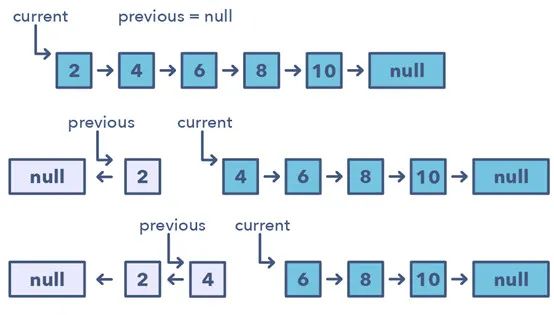
如何識(shí)別使用該模式的時(shí)機(jī):
如果你被要求在不使用額外內(nèi)存的前提下反轉(zhuǎn)一個(gè)鏈表
原地反轉(zhuǎn)鏈表模式的問題:
反轉(zhuǎn)一個(gè)子列表(中等) 反轉(zhuǎn)每個(gè) K 個(gè)元素的子列表(中等)
7.樹的寬度優(yōu)先搜索(Tree BFS)
該模式基于寬度優(yōu)先搜索(BFS)技術(shù),可遍歷一個(gè)樹并使用一個(gè)隊(duì)列來跟蹤一個(gè)層級的所有節(jié)點(diǎn),之后再跳轉(zhuǎn)到下一個(gè)層級。
任何涉及到以逐層級方式遍歷樹的問題都可以使用這種方法有效解決。
Tree BFS 模式的工作方式是:將根節(jié)點(diǎn)推至隊(duì)列,然后連續(xù)迭代知道隊(duì)列為空。在每次迭代中,我們移除隊(duì)列頭部的節(jié)點(diǎn)并「訪問」該節(jié)點(diǎn)。在移除了隊(duì)列中的每個(gè)節(jié)點(diǎn)之后,我們還將其所有子節(jié)點(diǎn)插入到隊(duì)列中。
如何識(shí)別 Tree BFS 模式:
如果你被要求以逐層級方式遍歷(或按層級順序遍歷)一個(gè)樹
Tree BFS 模式的問題:
二叉樹層級順序遍歷(簡單) 之字型遍歷(Zigzag Traversal)(中等)
8.樹的深度優(yōu)先搜索(Tree DFS)
Tree DFS 是基于深度優(yōu)先搜索(DFS)技術(shù)來遍歷樹。
你可以使用遞歸(或該迭代方法的技術(shù)棧)來在遍歷期間保持對所有之前的(父)節(jié)點(diǎn)的跟蹤。
Tree DFS 模式的工作方式是從樹的根部開始,如果這個(gè)節(jié)點(diǎn)不是一個(gè)葉節(jié)點(diǎn),則需要做兩件事:
1.決定現(xiàn)在是處理當(dāng)前的節(jié)點(diǎn)(pre-order),或是在處理兩個(gè)子節(jié)點(diǎn)之間(in-order),還是在處理兩個(gè)子節(jié)點(diǎn)之后(post-order) 2.為當(dāng)前節(jié)點(diǎn)的兩個(gè)子節(jié)點(diǎn)執(zhí)行兩次遞歸調(diào)用以處理它們
如何識(shí)別 Tree DFS 模式:
如果你被要求用 in-order、pre-order 或 post-order DFS 來遍歷一個(gè)樹 如果問題需要搜索其中節(jié)點(diǎn)更接近葉節(jié)點(diǎn)的東西
Tree DFS 模式的問題:
路徑數(shù)量之和(中等) 一個(gè)和的所有路徑(中等)
9.Two Heaps
在很多問題中,我們要將給定的一組元素分為兩部分。
為了求解這個(gè)問題,我們感興趣的是了解一部分的最小元素以及另一部分的最大元素。這一模式是求解這類問題的一種有效方法。
該模式要使用兩個(gè)堆(heap):一個(gè)用于尋找最小元素的 Min Heap 和一個(gè)用于尋找最大元素的 Max Heap。
該模式的工作方式是:
先將前一半的數(shù)值存儲(chǔ)到 Max Heap,這是由于你要尋找前一半中的最大數(shù)值。然后再將另一半存儲(chǔ)到 Min Heap,因?yàn)槟阋獙ふ业诙氲淖钚?shù)值。在任何時(shí)候,當(dāng)前數(shù)值列表的中間值都可以根據(jù)這兩個(gè) heap 的頂部元素計(jì)算得到。
識(shí)別 Two Heaps 模式的方法:
在優(yōu)先級隊(duì)列、調(diào)度等場景中有用 如果問題說你需要找到一個(gè)集合的最小/最大/中間元素 有時(shí)候可用于具有二叉樹數(shù)據(jù)結(jié)構(gòu)的問題
Two Heaps 模式的問題:
查找一個(gè)數(shù)值流的中間值(中等)
10.子集
很多編程面試問題都涉及到處理給定元素集合的排列和組合。
子集(Subsets)模式描述了一種用于有效處理所有這些問題的寬度優(yōu)先搜索(BFS)方法。
該模式看起來是這樣:
給定一個(gè)集合 [1, 5, 3]
1. 從一個(gè)空集開始:[[]] 2.向所有已有子集添加第一個(gè)數(shù) (1),從而創(chuàng)造新的子集:[[], [1]] 3.向所有已有子集添加第二個(gè)數(shù) (5):[[], [1], [5], [1,5]] 4.向所有已有子集添加第三個(gè)數(shù) (3):[[], [1], [5], [1,5], [3], [1,3], [5,3], [1,5,3]]
下面是這種子集模式的一種視覺表示:
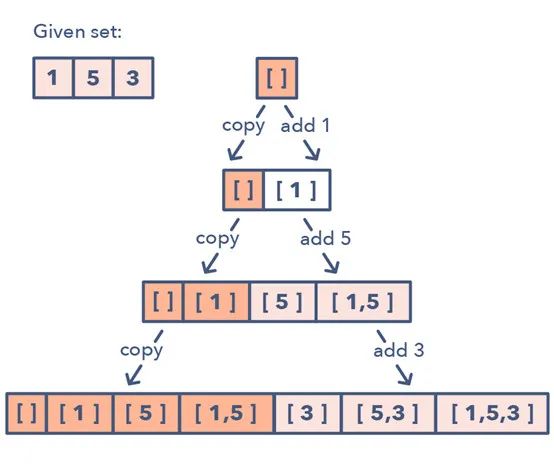
如何識(shí)別子集模式:
你需要找到給定集合的組合或排列的問題
子集模式的問題:
帶有重復(fù)項(xiàng)的子集(簡單) 通過改變大小寫的字符串排列(中等)
11.經(jīng)過修改的二叉搜索
只要給定了排序數(shù)組、鏈表或矩陣,并要求尋找一個(gè)特定元素,你可以使用的最佳算法就是二叉搜索。
這一模式描述了一種用于處理所有涉及二叉搜索的問題的有效方法。
對于一個(gè)升序的集合,該模式看起來是這樣的:
1.首先,找到起點(diǎn)和終點(diǎn)的中間位置。
尋找中間位置的一種簡單方法是:middle = (start + end) / 2。
但這很有可能造成整數(shù)溢出,所以推薦你這樣表示中間位置:middle = start + (end—start) / 2。2.如果鍵值(key)等于中間索引處的值,那么返回這個(gè)中間位置。 3.如果鍵值不等于中間索引處的值: 4.檢查 key < arr[middle] 是否成立。如果成立,將搜索約簡到 end = middle—1【換行】5.檢查 key > arr[middle] 是否成立。如果成立,將搜索約簡到 end = middle + 1
下面給出了這種經(jīng)過修改的二叉搜索模式的視覺表示:
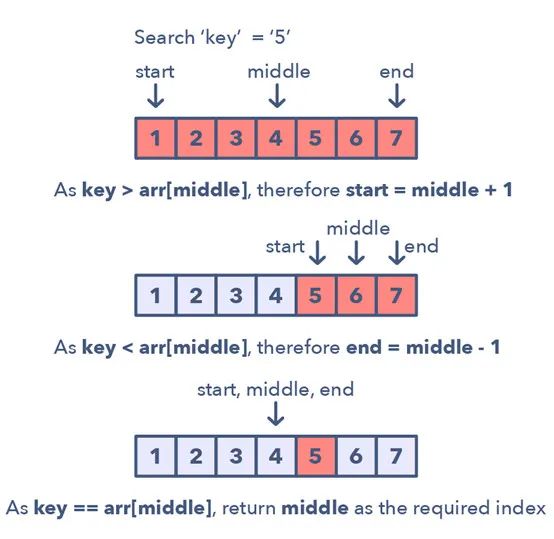
經(jīng)過修改的二叉搜索模式的問題:
與順序無關(guān)的二叉搜索(簡單) 在經(jīng)過排序的無限數(shù)組中搜索(中等)
12. 前 K 個(gè)元素
任何要求我們找到一個(gè)給定集合中前面的/最小的/最常出現(xiàn)的 K 的元素的問題都在這一模式的范圍內(nèi)。
跟蹤 K 個(gè)元素的最佳的數(shù)據(jù)結(jié)構(gòu)是 Heap。
這一模式會(huì)使用 Heap 來求解多個(gè)一次性處理一個(gè)給定元素集中 K 個(gè)元素的問題。
該模式是這樣工作的:
1.根據(jù)問題的不同,將 K 個(gè)元素插入到 min-heap 或 max-heap 中 2.迭代處理剩余的數(shù),如果你找到一個(gè)比 heap 中數(shù)更大的數(shù),那么就移除那個(gè)數(shù)并插入這個(gè)更大的數(shù)

這里無需排序算法,因?yàn)?heap 將為你跟蹤這些元素。
如何識(shí)別前 K 個(gè)元素模式:
如果你被要求尋找一個(gè)給定集合中前面的/最小的/最常出現(xiàn)的 K 的元素 如果你被要求對一個(gè)數(shù)值進(jìn)行排序以找到一個(gè)確定元素
前 K 個(gè)元素模式的問題:
前面的 K 個(gè)數(shù)(簡單) 最常出現(xiàn)的 K 個(gè)數(shù)(中等)
13. K 路合并
K 路合并能幫助你求解涉及一組經(jīng)過排序的數(shù)組的問題。
當(dāng)你被給出了 K 個(gè)經(jīng)過排序的數(shù)組時(shí),你可以使用 Heap 來有效地執(zhí)行所有數(shù)組的所有元素的排序遍歷。你可以將每個(gè)數(shù)組的最小元素推送至 Min Heap 以獲得整體最小值。
在獲得了整體最小值后,將來自同一個(gè)數(shù)組的下一個(gè)元素推送至 heap。
然后,重復(fù)這一過程以得到所有元素的排序遍歷結(jié)果。
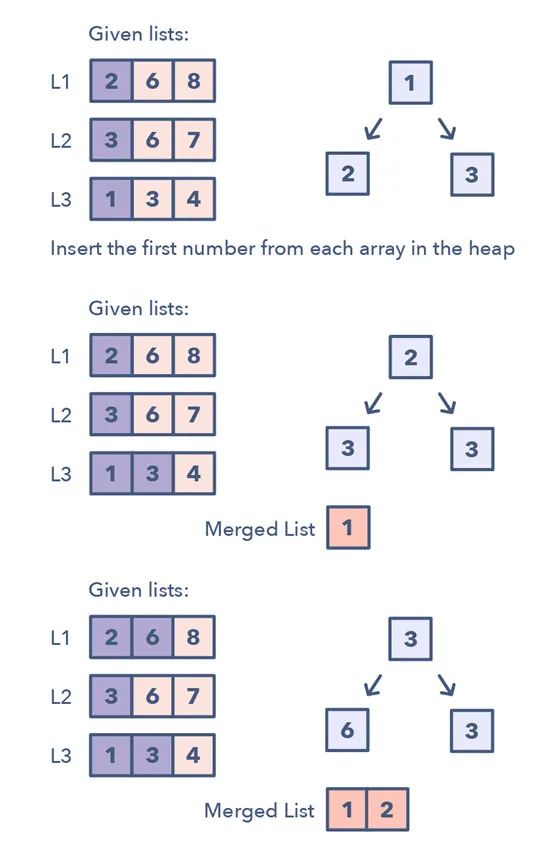
該模式看起來像這樣:
1.將每個(gè)數(shù)組的第一個(gè)元素插入 Min Heap 2.之后,從該 Heap 取出最小(頂部的)元素,將其加入到合并的列表。 3.在從 Heap 移除了最小的元素之后,將同一列表的下一個(gè)元素插入該 Heap 4.重復(fù)步驟 2 和 3,以排序的順序填充合并的列表
如何識(shí)別 K 路合并模式:
具有排序數(shù)組、列表或矩陣的問題 如果問題要求你合并排序的列表,找到一個(gè)排序列表中的最小元素
K 路合并模式的問題:
合并 K 個(gè)排序的列表(中等) 找到和最大的 K 個(gè)配對(困難)
14. 拓?fù)渑判?/h1>
拓?fù)渑判蚩捎糜趯ふ一ハ嘁蕾嚨脑氐木€性順序。
比如,如果事件 B 依賴于事件 A,那么 A 在拓?fù)渑判驎r(shí)位于 B 之前。
這個(gè)模式定義了一種簡單方法來理解執(zhí)行一組元素的拓?fù)渑判虻募夹g(shù)。
該模式看起來是這樣的:
1.初始化。
a)使用 HashMap 將圖(graph)存儲(chǔ)到鄰接的列表中;
b)為了查找所有源,使用 HashMap 記錄 in-degree 的數(shù)量2.構(gòu)建圖并找到所有頂點(diǎn)的 in-degree。
a)根據(jù)輸入構(gòu)建圖并填充 in-degree HashMap3.尋找所有的源。
a)所有 in-degree 為 0 的頂點(diǎn)都是源,并會(huì)被存入一個(gè)隊(duì)列4.排序。
a)對于每個(gè)源,執(zhí)行以下操作:
i)將其加入到排序的列表;
ii)根據(jù)圖獲取其所有子節(jié)點(diǎn);
iii)將每個(gè)子節(jié)點(diǎn)的 in-degree 減少 1;
iv)如果一個(gè)子節(jié)點(diǎn)的 in-degree 變?yōu)?0,將其加入到源隊(duì)列。
b)重復(fù) (a),直到源隊(duì)列為空。

如何識(shí)別拓?fù)渑判蚰J剑?/p>
處理無向有環(huán)圖的問題 如果你被要求以排序順序更新所有對象 如果你有一類遵循特定順序的對象
---END---
雙一流大學(xué)研究生團(tuán)隊(duì)創(chuàng)建,一個(gè)專注于目標(biāo)檢測與深度學(xué)習(xí)的組織,希望可以將分享變成一種習(xí)慣。
將「目標(biāo)檢測與深度學(xué)習(xí)」設(shè)為星標(biāo)★,并點(diǎn)擊右下角“在看“,解鎖推送限制,第一時(shí)間收到我們的分享。
整理不易,點(diǎn)贊三連↓