
自動化機器學習(AutoML)入門簡介
導讀
近期在學習研究一些關于自動化機器學習方面的論文,本文作為該系列的第一篇文章,就AutoML的一些基本概念和現(xiàn)狀進行簡單分享,權當抱磚引玉。
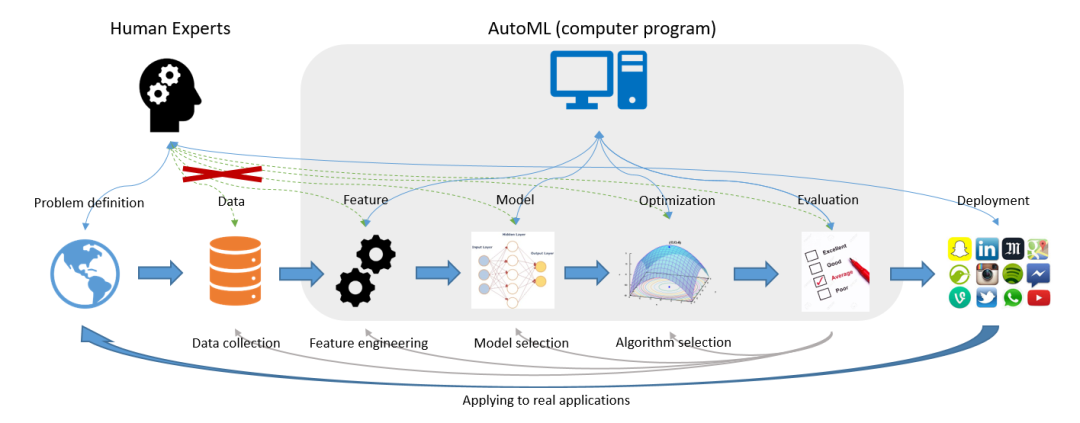
圖片源自《Taking Human out of Learning Applications: A Survey on Automated Machine Learning》2018
在算法行業(yè)有這樣一句話,大意是說80%的時間用在做數(shù)據(jù)清洗和特征工程,僅有20%的時間用來做算法建模,其核心是在說明數(shù)據(jù)和特征所占比重之大。與此同時,越來越多的數(shù)據(jù)從業(yè)者們也希望能夠降低機器學習的入門門檻,尤其是降低對特定領域的業(yè)務經驗要求、算法調參經驗等。基于這一背景,AutoML應運而生。
如何理解AutoML呢?從字面意思來看,AutoML即為Auto+ML,是自動化+機器學習兩個學科的結合體;從技術角度來說,則是泛指在機器學習各階段流程中有一個或多個階段采取自動化而無需人工參與的實現(xiàn)方案。例如在本文開篇引用的AutoML經典圖例中:其覆蓋了特征工程(Feature Engineering)、模型選擇(Model Selection)、算法選擇(Algorithm Selection)以及模型評估(Model Evaluation)4個典型階段,而僅有問題定義、數(shù)據(jù)準備和模型部署這三部分工作交由人工來實現(xiàn)。
數(shù)據(jù)從業(yè)者的懶惰。俗話說,懶惰是人類進步的源動力,這一點在AutoML這件事上體現(xiàn)的淋漓盡致。因為數(shù)據(jù)從業(yè)者們渴望從繁雜冗長的數(shù)據(jù)清洗、特征工程以及調參煉丹的無趣過程中解脫出來,自然而然的想法就是希望這一過程能夠Auto起來!當然,這一過程也可正面解讀為對技術精進的不懈追求…… 對降低ML入門門檻的期盼。毫無疑問,以機器學習為代表的AI行業(yè)是當下最熱門技術之一,也著實在很多場景解決了不少工程化的問題,所以越來越多的數(shù)據(jù)從業(yè)者投身其中。但并不是每名算法工程師或者數(shù)據(jù)科學家都有充分的業(yè)務經驗和煉丹技巧,所以更多人是希望能夠降低這一入門門檻,簡化機器學習建模流程。 足夠的數(shù)據(jù)體量和日益提升的算法算力。客觀來講,沒有足夠的數(shù)據(jù)量談Auto是不切實際的,因為不足以學到足夠的知識以實現(xiàn)Auto;而另一方面,AutoML的實現(xiàn)過程其實充滿了大量的迭代運算,所以完成單次的AutoML意味著約等于成百上千次的單次ML,其時間成本不得不成為AutoML領域的一個不容忽視的約束條件,而解決這一問題則一般需依賴優(yōu)秀的算法和充足的算力。
模型選擇(Model Selection)以及超參優(yōu)化(HPO)。這兩個階段可能是AutoML里最早涉及和最為關鍵的技術,早期的AutoML產品/工具其實也是主攻這兩個方向,例如Auto-WEKA和Auto-Sklearn就都是以這兩方面的實現(xiàn)為主。其中模型選擇其實主要還是枚舉為主,即將常用的模型逐一嘗試而后選出最好的模型或其組合。而HPO則相當于是加強版的GridSearch,都是解決最優(yōu)超參數(shù)的問題,只是解決的算法不同罷了,其中基于貝葉斯的超參優(yōu)化是主流。 自動化特征工程(AutoFE)。AutoFE是解決原始特征表達信息不充分或者存在冗余的問題,相應的解決方案就是特征衍生+特征選擇,而AutoFE一般是考慮這兩個過程的聯(lián)合實現(xiàn)抑或加一些創(chuàng)新的優(yōu)化設計。 元學習(Meta Learning)和遷移學習(Transfer Learning)。前面提到的模型選擇,雖然多數(shù)產品都是對候選模型進行枚舉嘗試,但也有更為優(yōu)秀的實現(xiàn)方案,那就是元學習。例如Auto-Sklearn中其實是集成了元學習的功能,在處理新的數(shù)據(jù)集學習任務時可以借鑒歷史任務而會自動選擇更為可能得到較好性能的模型,這個過程也稱之為warn-start。如果說元學習適用于經典機器學習算法,那么遷移學習其實則主要適用于深度學習技術:通過對歷史任務的學習經驗對后續(xù)類似場景的神經網絡架構設計提供一定的先驗信息。 神經網絡架構搜索(NAS)。同樣是針對深度學習的神經網絡架構,當沒有任何經驗可供遷移時,那么如何設計和構建神經網絡架構就是一個需要慎重考慮的問題。對此的解決方案即為NAS——neural architecture search!
相關閱讀:
評論
圖片
表情