
[ACM MM 2023] 基于殘差擴(kuò)散模型的文檔增強(qiáng)

本文簡要介紹被ACM MM 2023錄用的論文《DocDiff: Document Enhancement via Residual Diffusion Models》。本文注意到基于回歸的文檔圖像增強(qiáng)方法易受“回歸至均值”問題影響[1],導(dǎo)致生成的文本邊緣模糊。同時(shí),直接應(yīng)用面向自然圖像的擴(kuò)散模型進(jìn)行文檔增強(qiáng)也面臨訓(xùn)練代價(jià)高、采樣步數(shù)長等困難。基于這些觀察,本文重點(diǎn)關(guān)注文檔圖像增強(qiáng)的三大任務(wù):文檔去模糊、文檔去噪與二值化以及水印與印章的去除,并提出DocDiff,首個(gè)應(yīng)用擴(kuò)散模型進(jìn)行文檔增強(qiáng)的模型,并引入高頻殘差精煉模塊(High-Frequency Residual Refinement module,HRR)以及頻率分離訓(xùn)練機(jī)制,在保持字符一致性的同時(shí)提升文檔圖像的可讀性與OCR識(shí)別性能。實(shí)驗(yàn)表明:本文方法可以在不同文檔增強(qiáng)任務(wù)上取得競(jìng)爭(zhēng)性甚至SOTA的性能,同時(shí)也展現(xiàn)出了較強(qiáng)的推廣性和魯棒性。在模型參數(shù)上,基礎(chǔ)版本的DocDiff僅有8M,在128*128分辨率上以Batchsize=64訓(xùn)練只需要12GB顯存。如圖1所示,提出的HRR模塊是可插拔的,并且可以在不與Baseline模型進(jìn)行任何聯(lián)合訓(xùn)練的基礎(chǔ)上,直接串聯(lián)推理來大幅銳化Baseline生成的文本邊緣。并且,DocDiff僅需要采樣5步就可以得到較好的效果。總體而言,本文設(shè)計(jì)了一個(gè)基于擴(kuò)散模型的小巧高效的框架用于文檔增強(qiáng),平衡了創(chuàng)新性和實(shí)用性。代碼及數(shù)據(jù)集已開源:https://github.com/Royalvice/DocDiff
 圖1 DocDiff效果圖。與DE-GAN [1]和HINet [2]相比,DocDiff生成更清晰的文本邊緣。我們提出的HRR模塊能夠有效緩解基于回歸的方法生成的失真和模糊字符的問題,無論這些方法是設(shè)計(jì)用于自然場(chǎng)景還是文檔場(chǎng)景。需要注意的是,HRR模塊不需要與DE-GAN 和HINet進(jìn)行額外的聯(lián)合訓(xùn)練,其權(quán)重是從預(yù)訓(xùn)練的DocDiff中得出的。DocDiff-n代表推理時(shí)進(jìn)行n次采樣。
圖1 DocDiff效果圖。與DE-GAN [1]和HINet [2]相比,DocDiff生成更清晰的文本邊緣。我們提出的HRR模塊能夠有效緩解基于回歸的方法生成的失真和模糊字符的問題,無論這些方法是設(shè)計(jì)用于自然場(chǎng)景還是文檔場(chǎng)景。需要注意的是,HRR模塊不需要與DE-GAN 和HINet進(jìn)行額外的聯(lián)合訓(xùn)練,其權(quán)重是從預(yù)訓(xùn)練的DocDiff中得出的。DocDiff-n代表推理時(shí)進(jìn)行n次采樣。
一.研究背景

-
文檔圖像中存在的多種噪聲類型,包括整體的模糊以及局部的墨跡、透印等,以及它們的各種組合,對(duì)去噪提出了挑戰(zhàn)。 -
文本像素生成是一個(gè)困難的任務(wù)。與自然場(chǎng)景圖像不同,文本圖像的高頻信息主要集中在文字邊緣。對(duì)文本邊緣像素的輕微錯(cuò)誤修改都可能改變字符的語義含義,使其對(duì)OCR系統(tǒng)不可讀或不可識(shí)別。 -
實(shí)際文檔圖像分辨率往往超過1k,為保證整個(gè)文檔分析系統(tǒng)的效率,圖像增強(qiáng)預(yù)處理的速度至關(guān)重要,這要求模型盡可能輕量化。
當(dāng)前,文檔增強(qiáng)方法主要基于深度學(xué)習(xí)中的回歸框架[2,4,5],直接優(yōu)化像素級(jí)別的損失函數(shù)。由于“回歸至均值”的問題,這些方法生成的圖像文字邊緣存在模糊失真的問題,如圖1所示。此外,由于高分辨率文檔圖像中存在大量非文本區(qū)域,基于GAN的方法容易在局部Patch上出現(xiàn)模式坍塌[2]。近年來,許多基于擴(kuò)散模型的方法試圖為自然圖像恢復(fù)更豐富的細(xì)節(jié)。但是,直接將這些方法應(yīng)用于文檔圖像存在一定困難:訓(xùn)練成本過高,采樣步數(shù)過長使其難以在文檔分析系統(tǒng)中實(shí)際應(yīng)用;生成多樣性可能導(dǎo)致條件圖像與采樣圖像之間的字符不一致。文檔增強(qiáng)任務(wù)不追求生成多樣性,基于此我們可以對(duì)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行壓縮,對(duì)優(yōu)化目標(biāo)進(jìn)行改進(jìn)。
二、方法概述
 圖3 DocDiff結(jié)構(gòu)圖
圖3 DocDiff結(jié)構(gòu)圖
如圖3所示,DocDiff由兩個(gè)模塊組成:粗預(yù)測(cè)器(Coarse Predictor, CP)和高頻殘差精煉(High-Frequency Residual Refinement, HRR)模塊。
粗預(yù)測(cè)器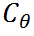 的目標(biāo)是在像素級(jí)別粗略恢復(fù)退化文檔圖像y為其干凈版本
的目標(biāo)是在像素級(jí)別粗略恢復(fù)退化文檔圖像y為其干凈版本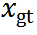 。其優(yōu)化目標(biāo)為最小化預(yù)測(cè)
。其優(yōu)化目標(biāo)為最小化預(yù)測(cè)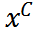 與GT 的均方誤差:
與GT 的均方誤差:

在文本像素生成中,粗預(yù)測(cè)器可以有效恢復(fù)文本的主要內(nèi)容,但可能無法準(zhǔn)確捕捉文字邊緣的高頻信息,導(dǎo)致文本邊緣明顯模糊。這是基于CNN的回歸方法由于“回歸至均值”問題的普遍局限,僅疊加更多卷積層難以解決此問題。
為解決上述問題,我們引入了高頻殘差精煉(HRR)模塊,它能從可學(xué)習(xí)的后驗(yàn)分布中生成樣本。HRR模塊的核心是一個(gè)Denoiser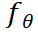 ,利用擴(kuò)散概率模型(DPM)[6,7]來估計(jì)Ground-truth圖像與CP生成圖像之間的殘差分布。與之前的工作[8-10]不同,我們?cè)O(shè)計(jì)HRR模塊不僅可以彌補(bǔ)單個(gè)回歸模型(此處為CP)的“回歸至均值”缺陷,還可以普適地增強(qiáng)各類基于回歸的方法的生成效果,不需要聯(lián)合訓(xùn)練。為此,我們對(duì)CP與HRR模塊進(jìn)行端到端聯(lián)合訓(xùn)練,而不是分別訓(xùn)練。通過這種方式,HRR模塊可以動(dòng)態(tài)調(diào)整并捕捉更多模式。大量實(shí)驗(yàn)表明,這種訓(xùn)練策略可以在不存在任何額外聯(lián)合訓(xùn)練的情況下,直接且顯著增強(qiáng)不同回歸去模糊方法生成的文字邊緣清晰度。
,利用擴(kuò)散概率模型(DPM)[6,7]來估計(jì)Ground-truth圖像與CP生成圖像之間的殘差分布。與之前的工作[8-10]不同,我們?cè)O(shè)計(jì)HRR模塊不僅可以彌補(bǔ)單個(gè)回歸模型(此處為CP)的“回歸至均值”缺陷,還可以普適地增強(qiáng)各類基于回歸的方法的生成效果,不需要聯(lián)合訓(xùn)練。為此,我們對(duì)CP與HRR模塊進(jìn)行端到端聯(lián)合訓(xùn)練,而不是分別訓(xùn)練。通過這種方式,HRR模塊可以動(dòng)態(tài)調(diào)整并捕捉更多模式。大量實(shí)驗(yàn)表明,這種訓(xùn)練策略可以在不存在任何額外聯(lián)合訓(xùn)練的情況下,直接且顯著增強(qiáng)不同回歸去模糊方法生成的文字邊緣清晰度。
HRR模塊執(zhí)行正向加噪過程和反向去噪過程來建模殘差分布,參考[6,7]。
正向加噪過程:給定干凈文檔圖像和其粗略估計(jì),計(jì)算它們的殘差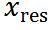 。將
。將 設(shè)為
設(shè)為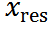 ,然后依次引入基于時(shí)間步長t的高斯噪聲,如下:
,然后依次引入基于時(shí)間步長t的高斯噪聲,如下:
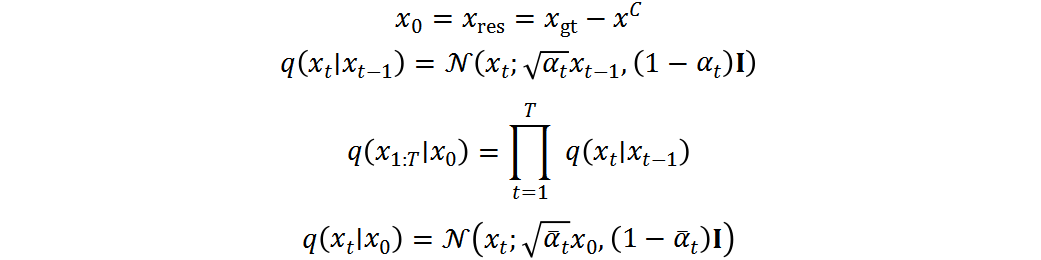
其中,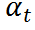 是控制每步添加高斯噪聲方差的超參數(shù)。正向過程中沒有可學(xué)習(xí)的參數(shù),生成的
是控制每步添加高斯噪聲方差的超參數(shù)。正向過程中沒有可學(xué)習(xí)的參數(shù),生成的 與大小相同。通過重參數(shù)技巧,可以將
與大小相同。通過重參數(shù)技巧,可以將 寫為:
寫為:
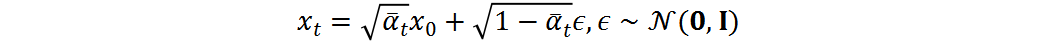
反向去噪過程:反向過程將高斯噪聲轉(zhuǎn)化回殘差分布,在給定條件下進(jìn)行。反向擴(kuò)散步驟可以寫為:
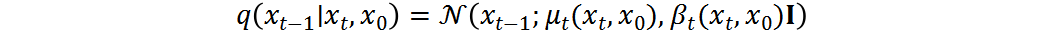
其中, 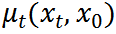 和
和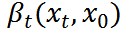 分別是均值和方差。參考[7],我們執(zhí)行確定性反向過程
分別是均值和方差。參考[7],我們執(zhí)行確定性反向過程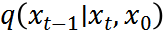 ,方差為零,均值可計(jì)算為:
,方差為零,均值可計(jì)算為:

給定Denoiser ,可參數(shù)化后驗(yàn)分布 :
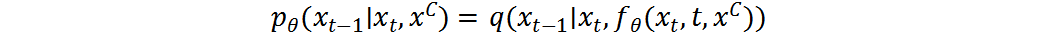
條件在條件分布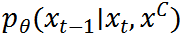 中非常重要。在每個(gè)時(shí)間步,需要采樣與在像素級(jí)字符上高度相關(guān)的殘差。
中非常重要。在每個(gè)時(shí)間步,需要采樣與在像素級(jí)字符上高度相關(guān)的殘差。
可以訓(xùn)練Denoiser 來預(yù)測(cè)原數(shù)據(jù)或者添加的噪聲 。為增加生成圖像的多樣性,現(xiàn)有方法[6,11-13]通常預(yù)測(cè)添加的噪聲。與的預(yù)測(cè)在無條件生成中是等價(jià)的,可以通過等式相互轉(zhuǎn)化。但是,在條件生成中,在采用Concat的條件輸入方式[11-13]的前提下,預(yù)測(cè)與預(yù)測(cè)是不等價(jià)的。預(yù)測(cè)時(shí),Denoiser只能從噪聲數(shù)據(jù)中學(xué)習(xí);而預(yù)測(cè)時(shí),還可以利用條件進(jìn)行監(jiān)督,這犧牲了多樣性但可以顯著提升反向過程前幾步的生成質(zhì)量。為此,我們訓(xùn)練Denoiser 直接預(yù)測(cè),這更符合文檔增強(qiáng)的目標(biāo)。訓(xùn)練目標(biāo)是最小化與真實(shí)后驗(yàn)分布之間的距離:
。為增加生成圖像的多樣性,現(xiàn)有方法[6,11-13]通常預(yù)測(cè)添加的噪聲。與的預(yù)測(cè)在無條件生成中是等價(jià)的,可以通過等式相互轉(zhuǎn)化。但是,在條件生成中,在采用Concat的條件輸入方式[11-13]的前提下,預(yù)測(cè)與預(yù)測(cè)是不等價(jià)的。預(yù)測(cè)時(shí),Denoiser只能從噪聲數(shù)據(jù)中學(xué)習(xí);而預(yù)測(cè)時(shí),還可以利用條件進(jìn)行監(jiān)督,這犧牲了多樣性但可以顯著提升反向過程前幾步的生成質(zhì)量。為此,我們訓(xùn)練Denoiser 直接預(yù)測(cè),這更符合文檔增強(qiáng)的目標(biāo)。訓(xùn)練目標(biāo)是最小化與真實(shí)后驗(yàn)分布之間的距離:

其中,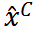 是在內(nèi)存中的克隆,不參與梯度計(jì)算。損失僅從通過反向傳播至
是在內(nèi)存中的克隆,不參與梯度計(jì)算。損失僅從通過反向傳播至 。
。
給定訓(xùn)練好的和,整合上式可得到確定性反向過程:
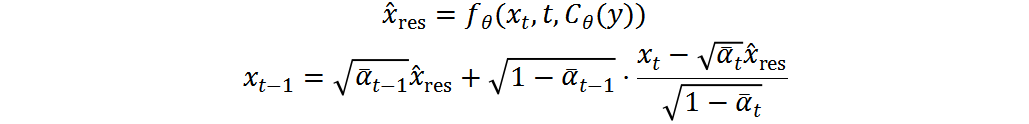
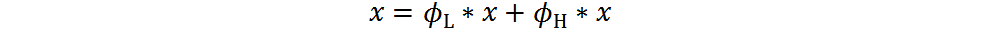
其中, 是低通濾波器,
是低通濾波器,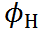 是高通濾波器。通常,為提取文字邊緣的殘差,我們將設(shè)置為拉普拉斯核。根據(jù)上式可得到低頻信息。與[10,14]不同,我們的方法不需要執(zhí)行FFT,也不需要在頻域參數(shù)化頻率分離,直接使用拉普拉斯核作為高通濾波器不僅簡化了訓(xùn)練時(shí)間,也證明了非常有效。
是高通濾波器。通常,為提取文字邊緣的殘差,我們將設(shè)置為拉普拉斯核。根據(jù)上式可得到低頻信息。與[10,14]不同,我們的方法不需要執(zhí)行FFT,也不需要在頻域參數(shù)化頻率分離,直接使用拉普拉斯核作為高通濾波器不僅簡化了訓(xùn)練時(shí)間,也證明了非常有效。
我們的目標(biāo)是最大化Denoiser 恢復(fù)CP預(yù)測(cè)中缺失的高頻信息的能力,同時(shí)通過的支持最小化的任務(wù)負(fù)擔(dān)。從這個(gè)角度看,和都需要恢復(fù)不同的高低頻信息,但它們展現(xiàn)了不同的專長。具體來說,主要重建低頻信息,而專門恢復(fù)高頻細(xì)節(jié):
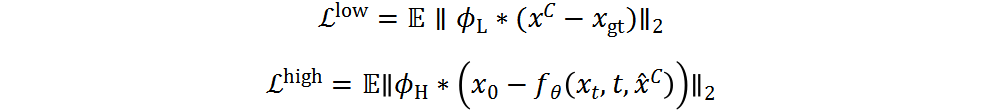
因此,和的綜合損失,以及DocDiff的總體損失為:

算法流程如下圖4

三、實(shí)驗(yàn)結(jié)果
論文在多個(gè)文檔增強(qiáng)數(shù)據(jù)集上進(jìn)行了全面評(píng)估。
在文檔去模糊任務(wù)上,論文在文檔去模糊數(shù)據(jù)集上報(bào)告定量和定性結(jié)果。定量結(jié)果顯示,DocDiff取得了最佳的感知指標(biāo)和優(yōu)秀的的失真指標(biāo),明顯優(yōu)于當(dāng)前最先進(jìn)的面向自然場(chǎng)景和文檔場(chǎng)景的基于回歸方法。即使在非原始分辨率下,DocDiff只需要5步采樣也能達(dá)到競(jìng)爭(zhēng)性的性能。定性結(jié)果也證明相比其他方法,DocDiff能夠更清晰準(zhǔn)確地恢復(fù)文字邊緣。
在文檔去噪與二值化任務(wù)上,論文在H-DIBCO'18和DIBCO'19兩個(gè)數(shù)據(jù)集上進(jìn)行評(píng)估。盡管在H-DIBCO'18上沒有取得最佳,但F-Measure比SOTA方法DE-GAN提升了10.52%。而在DIBCO'19上,DocDiff的F-Measure比當(dāng)前最好的方法提升了5.75%,參數(shù)量只有對(duì)方的1/23。定性結(jié)果也證明DocDiff能更準(zhǔn)確地分類文本像素。
在水印與印章去除任務(wù)上,由于缺乏公開數(shù)據(jù)集,論文合成了含水印和印章的文檔圖像進(jìn)行訓(xùn)練和測(cè)試。結(jié)果表明DocDiff可以高效去除水印與印章,同時(shí)保留覆蓋的字符內(nèi)容。尤其是在真實(shí)發(fā)票場(chǎng)景中,僅在合成印章數(shù)據(jù)上訓(xùn)練的DocDiff模型也展現(xiàn)出很強(qiáng)的泛化能力。
論文還使用Tesseract OCR對(duì)增強(qiáng)前后的文檔圖像進(jìn)行了識(shí)別評(píng)估。結(jié)果證明文檔增強(qiáng)可以顯著降低OCR的字符錯(cuò)誤率。
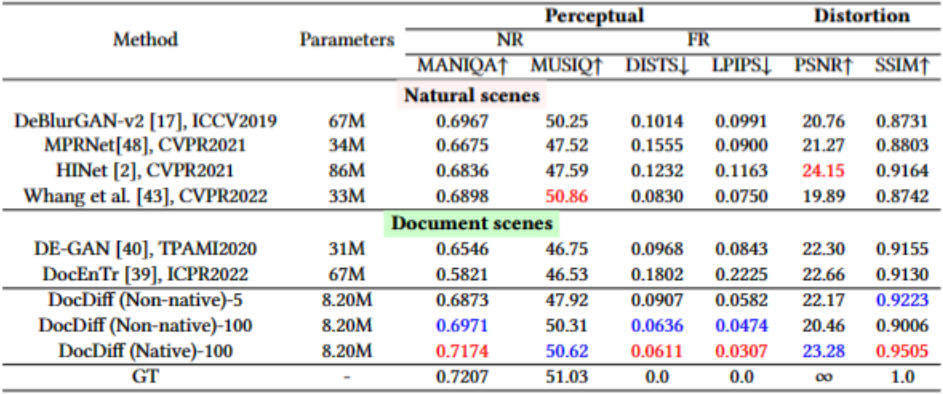
 圖5 文檔去模糊結(jié)果
圖5 文檔去模糊結(jié)果
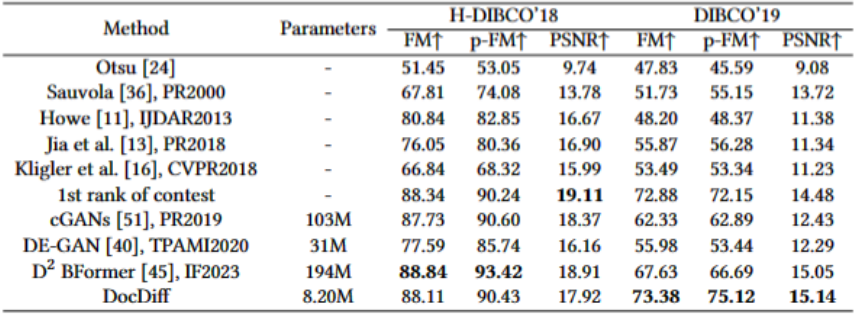


 圖8 OCR識(shí)別結(jié)果
圖8 OCR識(shí)別結(jié)果
四、總結(jié)
本文針對(duì)當(dāng)前基于回歸的文檔圖像增強(qiáng)方法易造成文本邊緣模糊,以及直接應(yīng)用面向自然圖像的擴(kuò)散模型存在困難的問題,提出了名為DocDiff的新穎高效框架。主要結(jié)論和貢獻(xiàn)總結(jié)如下:
DocDiff是第一個(gè)專門設(shè)計(jì)用于各種文檔圖像增強(qiáng)任務(wù)的基于殘差擴(kuò)散模型的框架。
插即用的高頻殘差精煉模塊可以直接增強(qiáng)各類基于回歸方法重建的文字邊緣質(zhì)量,無需額外的聯(lián)合訓(xùn)練。這具有很好的普適性。
DocDiff是一個(gè)小巧、靈活、高效且訓(xùn)練穩(wěn)定的生成模型。實(shí)驗(yàn)驗(yàn)證其只需要5步采樣就能達(dá)到競(jìng)爭(zhēng)性的性能。
-
實(shí)驗(yàn)結(jié)果全面證明了DocDiff在文檔去模糊、去噪與二值化以及水印和印章去除任務(wù)上的有效性和泛化性。
五、相關(guān)資源
https://zhuanlan.zhihu.com/p/654282220?utm_psn=1702345120874299392
參考文獻(xiàn)
[1]Anvari Z, Athitsos V. A survey on deep learning based document image enhancement[J]. arXiv preprint arXiv:2112.02719, 2021.
[2]Souibgui M A, Kessentini Y. De-gan: A conditional generative adversarial network for document enhancement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(3): 1180-1191.
[3]Chen L, Lu X, Zhang J, et al. Hinet: Half instance normalization network for image restoration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 182-192.
[4]Souibgui M A, Biswas S, Jemni S K, et al. DocEnTr: An end-to-end document image enhancement transformer[C]//2022 26th International Conference on Pattern Recognition (ICPR). IEEE, 2022: 1699-1705.
[5]Jemni S K, Souibgui M A, Kessentini Y, et al. Enhance to read better: a multi-task adversarial network for handwritten document image enhancement[J]. Pattern Recognition, 2022, 123: 108370.
[6]Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851.
[7]Song J, Meng C, Ermon S. Denoising diffusion implicit models[J]. arXiv preprint arXiv:2010.02502, 2020.
[8]Li H, Yang Y, Chang M, et al. Srdiff: Single image super-resolution with diffusion probabilistic models[J]. Neurocomputing, 2022, 479: 47-59.
[9]Niu A, Zhang K, Pham T X, et al. CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution[J]. arXiv preprint arXiv:2302.12831, 2023.
[10]Shang S, Shan Z, Liu G, et al. Resdiff: Combining cnn and diffusion model for image super-resolution[J]. arXiv preprint arXiv:2303.08714, 2023.
[11]Whang J, Delbracio M, Talebi H, et al. Deblurring via stochastic refinement[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16293-16303.
[12]Saharia C, Chan W, Chang H, et al. Palette: Image-to-image diffusion models[C]//ACM SIGGRAPH 2022 Conference Proceedings. 2022: 1-10.
[13]Saharia C, Ho J, Chan W, et al. Image super-resolution via iterative refinement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(4): 4713-4726.
[14]Wu J, Fang H, Zhang Y, et al. Medsegdiff: Medical image segmentation with diffusion probabilistic model[J]. arXiv preprint arXiv:2211.00611, 2022.
原文作者: Zongyuan Yang, Baolin Liu, Yongping Xiong, Lan Yi, Guibin Wu, Xiaojun Tang, Ziqi Liu, Junjie Zhou, Xing Zhang
免責(zé)聲明:(1)本文僅代表撰稿者觀點(diǎn),撰稿者不一定是原文作者,其個(gè)人理解及總結(jié)不一定準(zhǔn)確及全面,論文完整思想及論點(diǎn)應(yīng)以原論文為準(zhǔn)。(2)本文觀點(diǎn)不代表本公眾號(hào)立場(chǎng)。