
Python實(shí)現(xiàn) ! 千萬級別數(shù)據(jù)處理
今天分享一個數(shù)據(jù)清洗小技巧,可以讓你在遇到 百萬、千萬級別數(shù)據(jù) 的時候游刃有余。
先來說說問題的背景
現(xiàn)在有一個 csv 格式的數(shù)據(jù)集,大概 2千萬條 左右的樣子,存儲的是用戶的網(wǎng)絡(luò)交互數(shù)據(jù),其中電話號碼作為用戶的唯一標(biāo)識。
再來看看我們要做啥
首先我們需要針對這批用戶確定所屬運(yùn)營商,其次根據(jù)交互數(shù)據(jù)對各運(yùn)營商的用戶感知情況進(jìn)行分析,最后給出各運(yùn)營商的相應(yīng)優(yōu)化解決措施。
這個目標(biāo)的第一部分:確定用戶歸屬運(yùn)營商,正好可以用今天這個小技巧去解決。
判斷兩千萬個號碼中每個號碼歸屬的運(yùn)營商,你應(yīng)該首先會想到循環(huán)遍歷。
但是你如果真的挨個號碼去遍歷一次,你會發(fā)現(xiàn)讀一遍數(shù)據(jù)都需要好久,甚至可能會需要幾分鐘、十幾分鐘。
所以今天會用到 Pandas 中的矢量化操作,通過 isin 函數(shù)進(jìn)行篩選過濾,完成上面這個任務(wù) 只需要一兩秒
矢量化操作
矢量化,有別于對每一個單獨(dú)的值(標(biāo)量)進(jìn)行操作,是 Pandas 底層支持的對于整個 Array 進(jìn)行的操作,也是Pandas 中執(zhí)行的最快的方法。
這種操作適用于對某一列的全體數(shù)據(jù)進(jìn)行普適的操作,即矢量化是對整個數(shù)組執(zhí)行操作的過程。
矢量化操作適用于 Pandas 的 Dataframe,Series 對象
Pandas 對于常用的函數(shù),例如求和、平均值等常用統(tǒng)計(jì)函數(shù)做了非常好的矢量化支持。
在大多數(shù)場景下,我們需要做的只是 把一整列的元素,當(dāng)成一個元素去處理,Pandas 會自動把函數(shù)應(yīng)用到每一個單元格上。例如
df_data['age']?=?df_data['age']?+?5
這就是最簡單的矢量化操作,就算你的數(shù)據(jù)集是 2 千萬條,執(zhí)行一次簡單矢量化操作最多幾秒也就可以搞定。
isin 方法可以通過矢量化操作,完成簡單的數(shù)據(jù)篩選
isin函數(shù)
常用的是 DataFrame 的 isin 函數(shù),它的官方定義是這樣的:
def?isin(self,?values):
????"""
????Whether?each?element?in?the?DataFrame?is?contained?in?values.
?Parameters
????----------
????values?:?iterable,?Series,?DataFrame?or?dict
????The?result?will?only?be?true?at?a?location?if?all?the
????labels?match.?If?`values`?is?a?Series,?that's?the?index.?If
????`values`?is?a?dict,?the?keys?must?be?the?column?names,
????which?must?match.?If?`values`?is?a?DataFrame,
????then?both?the?index?and?column?labels?must?match.
?Returns
????-------
????DataFrame
????DataFrame?of?booleans?showing?whether?each?element?in?the?DataFrame
????is?contained?in?values.
????"""
可以看到需要傳入一個參數(shù) values,函數(shù)會返回一個 DataFrame。
其中參數(shù) values 大致解釋如下:
values :iterable, Series, DataFrame 或 dict
如果所有標(biāo)簽都匹配,則結(jié)果僅在某個位置為 true。 如果 values 是 Series,那就是索引。 如果 values 是一個 dict,則鍵必須是必須匹配的列名。 如果值是 DataFrame,則索引標(biāo)簽和列標(biāo)簽都必須匹配。
返回值是一個布爾的 DataFrame,顯示 DataFrame 中的每個元素是否包含在值 values 中。
大致解釋一下:
當(dāng) values 是列表時,將會檢查列表中是否存在 DataFrame 中的每個值
當(dāng) values 是 dict 時,可以通過傳遞值以分別檢查每一列
當(dāng) values 是 Series 或 DataFrame 時,索引和列必須匹配
"""創(chuàng)建?DataFrame"""
df?=?pd.DataFrame({'num_legs':?[2,?4],?'num_wings':?[2,?0]},?index=['falcon',?'dog'])
df
???????????num_legs??num_wings
falcon?????????2??????????2
dog????????????4??????????0
#?values?是列表
df.isin([0,?2])
??????????num_legs??num_wings
falcon??????True???????True
dog????????False???????True
#?values?是?dict
df.isin({'num_wings':?[0,?3]})
??????????num_legs??num_wings
falcon?????False??????False
dog????????False???????True
#?values?是?DataFrame
other?=?pd.DataFrame({'num_legs':?[8,?2],?'num_wings':?[0,?2]},?index=['spider','falcon'])
df.isin(other)
??????????num_legs??num_wings
falcon??????True???????True
dog????????False??????False
isin 函數(shù)的用法就這些,很簡單,下面針對我們遇到的問題試試用 isin 快速解決
isin 實(shí)戰(zhàn)
首先在判斷號碼歸屬運(yùn)營商時需要借助一個表
對!各運(yùn)營商對應(yīng)的號段表
這個號段在網(wǎng)上應(yīng)該都能查到,另外,需要注意還有一些運(yùn)營商對應(yīng)的虛擬號段
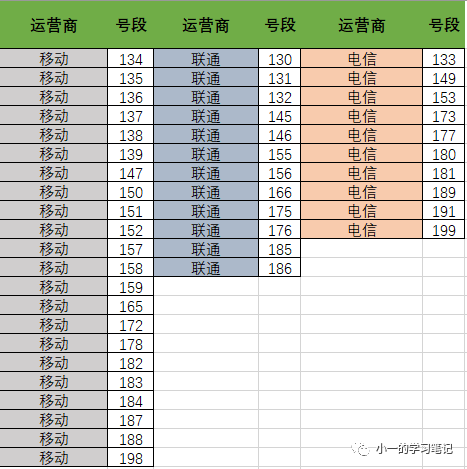
根據(jù)號段去確定每個用戶號碼的運(yùn)營商歸屬即可
具體實(shí)現(xiàn)代碼如下:
#?獲取移動運(yùn)營商的號段
mobile_list?=?df_data.loc[df_data['運(yùn)營商']?==?'移動',?'號段'].drop_duplicates().tolist()
#?根據(jù)移動號段匹配所有移動用戶
df_data_mobile?=?df_data.loc[df_data['號段'].str.slice(0,?3).isin(mobile_list),?:]
#?獲取聯(lián)通運(yùn)營商的號段
unicom_list?=?df_data.loc[df_data['運(yùn)營商']?==?'聯(lián)通',?'號段'].drop_duplicates().tolist()
#?根據(jù)聯(lián)通號段匹配所有聯(lián)通用戶
df_data_unicom?=?df_data.loc[df_data['號段'].str.slice(0,?3).isin(unicom_list),?:]
#?匹配電信用戶
df_data_net?=?df_data.loc[~df_data['號段'].str.slice(0,?3).isin(mobile_list)?&
??????????????????????????~df_data['號段'].str.slice(0,?3).isin(unicom_list)
??????????????????????????,?:]
【左右滑動查看更多】
代碼中通過 isin 方法和 loc 結(jié)合,實(shí)現(xiàn)了對 DataFrame 的過濾篩選。
稍微解釋一下:首先根據(jù)移動號段確定移動用戶,其次根據(jù)聯(lián)通號段確定聯(lián)通用戶,最后通過 isin 的反方法確定非移動和聯(lián)通的號段,即電信號段,確定電信用戶。
需要注意,isin 方法的反方法是在其前面加上 ~,不存在 isnotin 方法,
寫在后面的話
巧用 isin 方法,可以極大的提高數(shù)據(jù)處理效率,還能提高打工人的代碼素養(yǎng)。
另外,類似的方法還有 where、cut 等,都可直接進(jìn)行矢量化操作,下次遇到具體案例了再分享。

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」