
一文概覽NLP算法(Python)
一、自然語(yǔ)言處理(NLP)簡(jiǎn)介
NLP,自然語(yǔ)言處理就是用計(jì)算機(jī)來(lái)分析和生成自然語(yǔ)言(文本、語(yǔ)音),目的是讓人類可以用自然語(yǔ)言形式跟計(jì)算機(jī)系統(tǒng)進(jìn)行人機(jī)交互,從而更便捷、有效地進(jìn)行信息管理。
NLP是人工智能領(lǐng)域歷史較為悠久的領(lǐng)域,但由于語(yǔ)言的復(fù)雜性(語(yǔ)言表達(dá)多樣性/歧義/模糊等等),如今的發(fā)展及收效相對(duì)緩慢。比爾·蓋茨曾說(shuō)過,"NLP是 AI 皇冠上的明珠。" 在光鮮絢麗的同時(shí),卻可望而不可及(...)。
為了揭開NLP的神秘面紗,本文接下來(lái)會(huì)梳理下NLP流程、主要任務(wù)及算法,并最終落到實(shí)際NLP項(xiàng)目(經(jīng)典的文本分類任務(wù)的實(shí)戰(zhàn))。順便說(shuō)一句,個(gè)人水平有限,不足之處還請(qǐng)留言指出~~
二、NLP主要任務(wù)及技術(shù)
NLP任務(wù)可以大致分為詞法分析、句法分析、語(yǔ)義分析三個(gè)層面。具體的,本文按照單詞-》句子-》文本做順序展開,并介紹各個(gè)層面的任務(wù)及對(duì)應(yīng)技術(shù)。本節(jié)上半部分的分詞、命名實(shí)體識(shí)別、詞向量等等可以視為NLP基礎(chǔ)的任務(wù)。下半部分的句子關(guān)系、文本生成及分類任務(wù)可以看做NLP主要的應(yīng)用任務(wù)。 這里,貼一張自然語(yǔ)言處理的技術(shù)路線圖,介紹了NLP任務(wù)及主流模型的分支:
這里,貼一張自然語(yǔ)言處理的技術(shù)路線圖,介紹了NLP任務(wù)及主流模型的分支: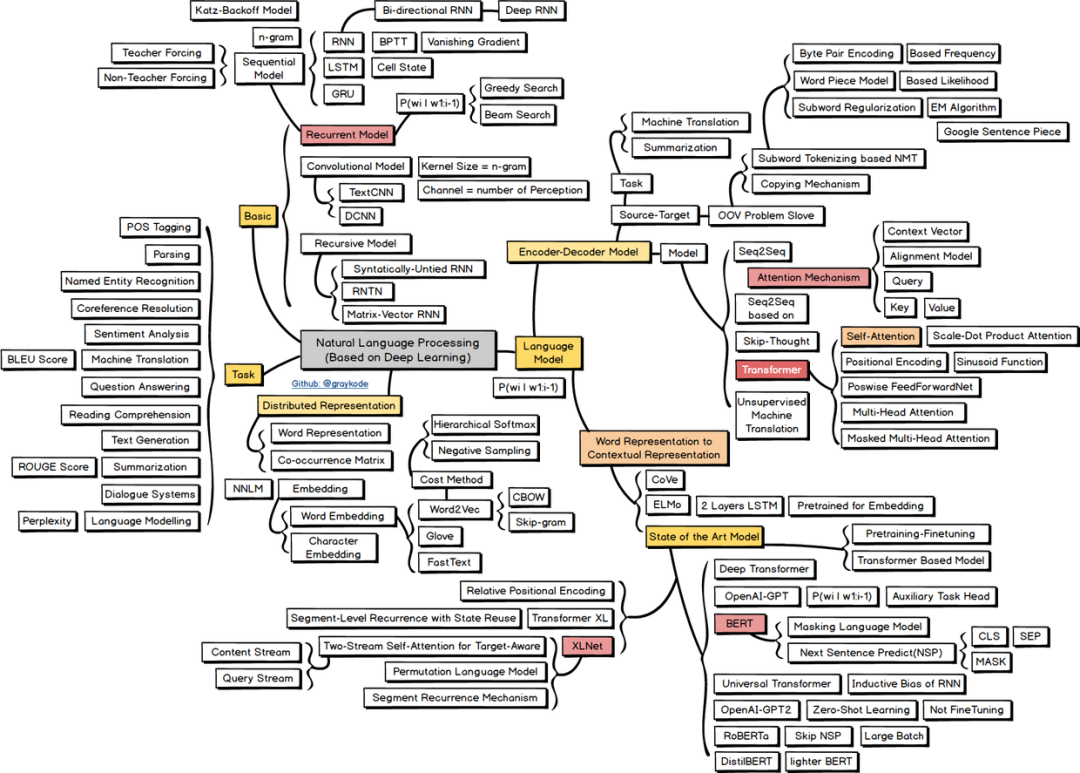
高清圖可如下路徑下載(原作者graykode):https://github.com/aialgorithm/AiPy/tree/master/Ai%E7%9F%A5%E8%AF%86%E5%9B%BE%E5%86%8C/Ai_Roadmap
2.1 數(shù)據(jù)清洗 + 分詞(系列標(biāo)注任務(wù))
數(shù)據(jù)語(yǔ)料清洗。我們拿到文本的數(shù)據(jù)語(yǔ)料(Corpus)后,通常首先要做的是,分析并清洗下文本,主要用正則匹配刪除掉數(shù)字及標(biāo)點(diǎn)符號(hào)(一般這些都是噪音,對(duì)于實(shí)際任務(wù)沒有幫助),做下分詞后,刪掉一些無(wú)關(guān)的詞(停用詞),對(duì)于英文還需要統(tǒng)一下復(fù)數(shù)、語(yǔ)態(tài)、時(shí)態(tài)等不同形態(tài)的單詞形式,也就是詞干/詞形還原。
分詞。即劃分為詞單元(token),是一個(gè)常見的序列標(biāo)注任務(wù)。對(duì)于英文等拉丁語(yǔ)系的語(yǔ)句分詞,天然可以通過空格做分詞,
 對(duì)于中文語(yǔ)句,由于中文詞語(yǔ)是連續(xù)的,可以用結(jié)巴分詞(基于trie tree+維特比等算法實(shí)現(xiàn)最大概率的詞語(yǔ)切分)等工具實(shí)現(xiàn)。
對(duì)于中文語(yǔ)句,由于中文詞語(yǔ)是連續(xù)的,可以用結(jié)巴分詞(基于trie tree+維特比等算法實(shí)現(xiàn)最大概率的詞語(yǔ)切分)等工具實(shí)現(xiàn)。
import?jieba
jieba.lcut("我的地址是上海市松江區(qū)中山街道華光藥房")
>>>?['我',?'的',?'地址',?'是',?'上海市',?'松江區(qū)',?'中山',?'街道',?'華光',?'藥房']
英文分詞后的詞干/詞形等還原(去除時(shí)態(tài) 語(yǔ)態(tài)及復(fù)數(shù)等信息,統(tǒng)一為一個(gè)“單詞”形態(tài))。這并不是必須的,還是根據(jù)實(shí)際任務(wù)是否需要保留時(shí)態(tài)、語(yǔ)態(tài)等信息,有WordNetLemmatizer、 SnowballStemmer等方法。
分詞及清洗文本后,還需要對(duì)照前后的效果差異,在做些微調(diào)。這里可以統(tǒng)計(jì)下個(gè)單詞的頻率、句長(zhǎng)等指標(biāo),還可以通過像詞云等工具做下可視化~
from?wordcloud?import?WordCloud
ham_msg_cloud?=?WordCloud(width?=520,?height?=260,max_font_size=50,?background_color?="black",?colormap='Blues').generate(原文本語(yǔ)料)
plt.figure(figsize=(16,10))
plt.imshow(ham_msg_cloud,?interpolation='bilinear')
plt.axis('off')?#?turn?off?axis
plt.show()

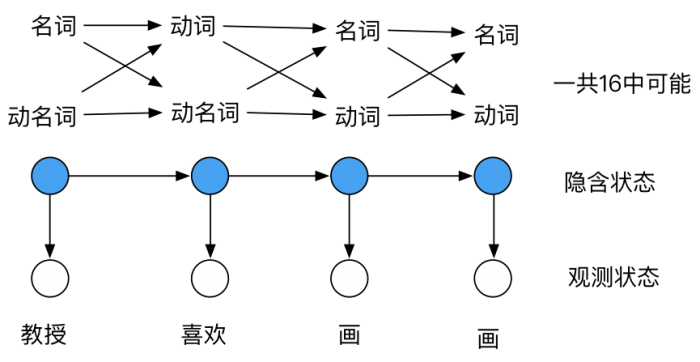
2.2 詞性標(biāo)注(系列標(biāo)注任務(wù))
詞性標(biāo)注是對(duì)句子中的成分做簡(jiǎn)單分析,區(qū)分出分名詞、動(dòng)詞、形容詞之類。對(duì)于句法分析、信息抽取的任務(wù),經(jīng)過詞性標(biāo)注后的文本會(huì)帶來(lái)很大的便利性(其他方面的應(yīng)用好像比較少)。
常用的詞性標(biāo)注有基于規(guī)則、統(tǒng)計(jì)以及深度學(xué)習(xí)的方法,像HanLP、結(jié)巴分詞等工具都有這個(gè)功能。
2.3 命名實(shí)體識(shí)別(系列標(biāo)注任務(wù))
命名實(shí)體識(shí)別(Named Entity Recognition,簡(jiǎn)稱NER)是一個(gè)有監(jiān)督的系列標(biāo)注任務(wù),又稱作“專名識(shí)別”,是指識(shí)別文本中具有特定意義的實(shí)體,主要包括人名、地名、機(jī)構(gòu)名、時(shí)間、專有名詞等關(guān)鍵信息。 通過NER識(shí)別出一些關(guān)鍵的人名、地名就可以很方便地提取出“某人去哪里,做什么事的信息”,很方便信息提取、問答系統(tǒng)等任務(wù)。NER主流的模型實(shí)現(xiàn)有BiLSTM-CRF、Bert-CRF,如下一個(gè)簡(jiǎn)單的中文ner項(xiàng)目:https://github.com/Determined22/zh-NER-TF
通過NER識(shí)別出一些關(guān)鍵的人名、地名就可以很方便地提取出“某人去哪里,做什么事的信息”,很方便信息提取、問答系統(tǒng)等任務(wù)。NER主流的模型實(shí)現(xiàn)有BiLSTM-CRF、Bert-CRF,如下一個(gè)簡(jiǎn)單的中文ner項(xiàng)目:https://github.com/Determined22/zh-NER-TF
2.4 詞向量(表示學(xué)習(xí))
對(duì)于自然語(yǔ)言文本,計(jì)算機(jī)無(wú)法理解詞后面的含義。輸入模型前,首先要做的就是詞的數(shù)值化表示,常用的轉(zhuǎn)化方式有2種:One-hot編碼、詞嵌入分布式方法。
One-hot編碼:最簡(jiǎn)單的表示方法某過于onehot表示,每個(gè)單詞是否出現(xiàn)就用一位數(shù)單獨(dú)展示。進(jìn)一步,句子的表示也就是累加每個(gè)單詞的onehot,也就是常說(shuō)的句子的詞袋模型(bow)表示。
##?詞袋表示
from?sklearn.feature_extraction.text?import?CountVectorizer
bow?=?CountVectorizer(
????????????????analyzer?=?'word',
????????????????strip_accents?=?'ascii',
????????????????tokenizer?=?[],
????????????????lowercase?=?True,
????????????????max_features?=?100,?
????????????????)

詞嵌入分布式表示:自然語(yǔ)言的單詞數(shù)是成千上萬(wàn)的,One-hot編碼會(huì)有高維、詞語(yǔ)間無(wú)聯(lián)系的缺陷。這時(shí)有一種更有效的方法就是——詞嵌入分布式表示,通過神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)構(gòu)造一個(gè)低維、稠密,隱含詞語(yǔ)間關(guān)系的向量表示。常見有Word2Vec、Fasttext、Bert等模型學(xué)習(xí)每個(gè)單詞的向量表示,在表示學(xué)習(xí)后相似的詞匯在向量空間中是比較接近的。 
#?Fasttext?embed模型
from?gensim.models?import?FastText,word2vec
model?=?FastText(text,??size=100,sg=1,?window=3,?min_count=1,?iter=10,?min_n=3,?max_n=6,word_ngrams=1,workers=12)
print(model.wv['hello'])?#?詞向量
model.save('./data/fasttext100dim')
特別地,正因?yàn)锽ert等大規(guī)模自監(jiān)督預(yù)訓(xùn)練方法,又為NLP帶來(lái)了春天~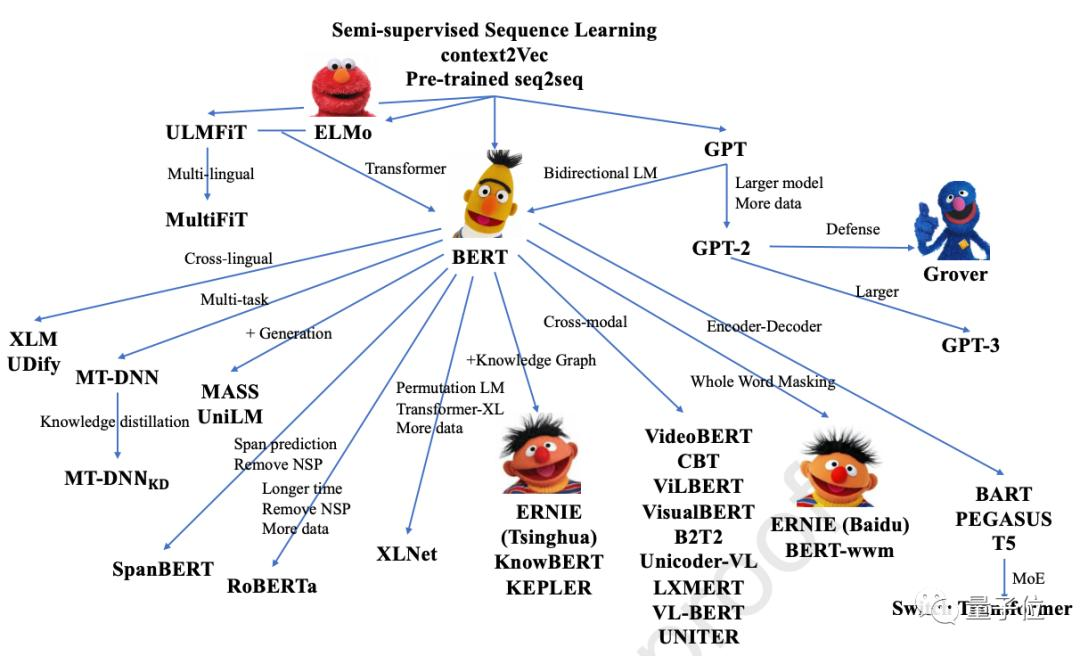
對(duì)于學(xué)習(xí)后的詞表示向量,還可以通過重要程度進(jìn)行特征加權(quán),合適的加權(quán)方法對(duì)于任務(wù)可以有不錯(cuò)的提升效果。常用的有卡方chi2、TF-IDF等加權(quán)方法。TF-IDF是一種基于統(tǒng)計(jì)的方法,其核心思想是假設(shè)字詞的重要性與其在某篇文章中出現(xiàn)的比例成正比,與其在其他文章中出現(xiàn)的比例成反比。 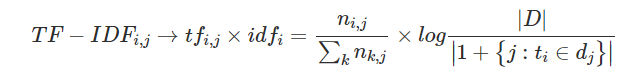
#?TF-IDF可以直接調(diào)用sklearn
from?sklearn.feature_extraction.text?import?TfidfTransformer
2.5 句法、語(yǔ)義依存分析
句法、語(yǔ)義依存分析是傳統(tǒng)自然語(yǔ)言的基礎(chǔ)句子級(jí)的任務(wù),語(yǔ)義依存分析是指在句子結(jié)構(gòu)中分析實(shí)詞和實(shí)詞之間的語(yǔ)義關(guān)系,這種關(guān)系是一種事實(shí)上或邏輯上的關(guān)系,且只有當(dāng)詞語(yǔ)進(jìn)入到句子時(shí)才會(huì)存在。語(yǔ)義依存分析的目的即回答句子的”Who did what to whom when and where”的問題。例如句子“張三昨天告訴李四一個(gè)秘密”,語(yǔ)義依存分析可以回答四個(gè)問題,即誰(shuí)告訴了李四一個(gè)秘密,張三告訴誰(shuí)一個(gè)秘密,張三什么時(shí)候告訴李四一個(gè)秘密,張三告訴李四什么。
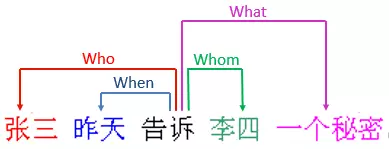
傳統(tǒng)的自然語(yǔ)言處理多是參照了語(yǔ)言學(xué)家對(duì)于自然語(yǔ)言的歸納總結(jié),通過句法、語(yǔ)義分析可以挖掘出詞語(yǔ)間的聯(lián)系(主謂賓、施事受事等關(guān)系),用于制定文本規(guī)則、信息抽取(如正則匹配疊加語(yǔ)義規(guī)則應(yīng)用于知識(shí)抽取或者構(gòu)造特征)。可以參考spacy庫(kù)、哈工大NLP的示例:http://ltp.ai/demo.html
隨著深度學(xué)習(xí)技術(shù)RNN/LSTM等強(qiáng)大的時(shí)序模型(sequential modeling)和詞嵌入方法的普及,能夠在一定程度上刻畫句子的隱含語(yǔ)法結(jié)構(gòu),學(xué)習(xí)到上下文信息,已經(jīng)逐漸取代了詞法、句法等傳統(tǒng)自然語(yǔ)言處理流程。
2.6 相似度算法(句子關(guān)系的任務(wù))
自然語(yǔ)言處理任務(wù)中,我們經(jīng)常需要判斷兩篇文檔的相似程度(句子關(guān)系),比如檢索系統(tǒng)輸出最相關(guān)的文本,推薦系統(tǒng)推薦相似的文章。文本相似度匹配常用到的方法有:文本編輯距離、WMD、 BM2.5、詞向量相似度 、Approximate Nearest Neighbor以及一些有監(jiān)督的(神經(jīng)網(wǎng)絡(luò))模型判斷文本間相似度。
2.7 文本分類任務(wù)
文本分類是經(jīng)典的NLP任務(wù),就是將文本系列對(duì)應(yīng)預(yù)測(cè)到類別。
一種是輸入序列輸出這整個(gè)序列的類別,如短信息、微博分類、意圖識(shí)別等。 另一種是輸入序列輸出序列上每個(gè)位置的類別,上文提及的系列標(biāo)注可以看做為詞粒度的一種分類任務(wù),如實(shí)體命名識(shí)別。
分類任務(wù)使用預(yù)訓(xùn)練+(神經(jīng)網(wǎng)絡(luò))分類模型的端對(duì)端學(xué)習(xí)是主流,深度學(xué)習(xí)學(xué)習(xí)特征的表達(dá)然后進(jìn)行分類,大大減少人工的特征。但以實(shí)際項(xiàng)目中的經(jīng)驗(yàn)來(lái)看,對(duì)于一些困難任務(wù)(任務(wù)的噪聲大),加入些人工的特征工程還是很有必要的。
2.8 文本生成任務(wù)
文本生成也就是由類別生成序列 或者 由序列到序列的預(yù)測(cè)任務(wù)。按照不同的輸入劃分,文本自動(dòng)生成可包括文本到文本的生成(text-to-text ?generation)、意義到文本的生成(meaning-to-text ?generation)、數(shù)據(jù)到文本的生成(data-to-text ?generation)以及圖像到文本的生成(image-to-text generation)等。具體應(yīng)用如機(jī)器翻譯、文本摘要理解、閱讀理解、閑聊對(duì)話、寫作、看圖說(shuō)話。常用的模型如RNN、CNN、seq2seq、Transformer。
同樣的,基于大規(guī)模預(yù)訓(xùn)練模型的文本生成也是一大熱門,可見《A Survey of Pretrained Language Models Based Text Generation》
三、垃圾短信文本分類實(shí)戰(zhàn)
3.1 讀取短信文本數(shù)據(jù)并展示
本項(xiàng)目是通過有監(jiān)督的短信文本,學(xué)習(xí)一個(gè)垃圾短信文本分類模型。數(shù)據(jù)樣本總的有5572條,label有spam(垃圾短信)和ham兩種,是一個(gè)典型類別不均衡的二分類問題。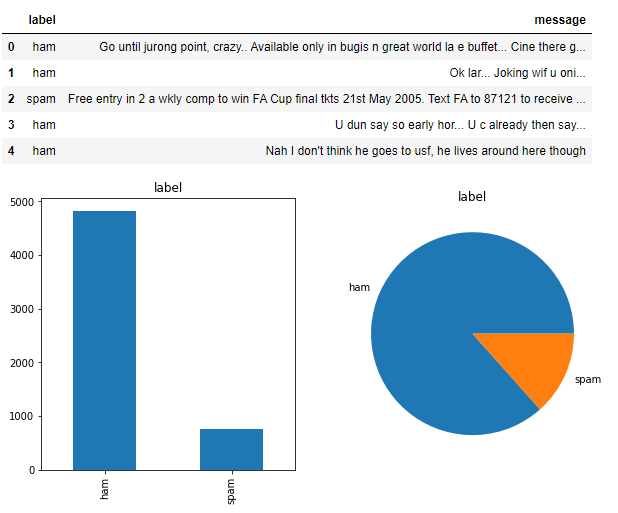
#?源碼可見https://github.com/aialgorithm/Blog
import?pandas?as?pd
import?numpy?as?np
import??matplotlib.pyplot?as?plt
spam_df?=?pd.read_csv('./data/spam.csv',?header=0,?encoding="ISO-8859-1")
#?數(shù)據(jù)展示
_,?ax?=?plt.subplots(1,2,figsize=(10,5))
spam_df['label'].value_counts().plot(ax=ax[0],?kind="bar",?rot=90,?title='label');
spam_df['label'].value_counts().plot(ax=ax[1],?kind="pie",?rot=90,?title='label',?ylabel='');
print("Dataset?size:?",?spam_df.shape)
spam_df.head(5)
3.2 數(shù)據(jù)清洗預(yù)處理
數(shù)據(jù)清洗在于去除一些噪聲信息,這里對(duì)短信文本做按空格分詞,統(tǒng)一大小寫,清洗非英文字符,去掉停用詞并做了詞干還原。考慮到短信文本里面的數(shù)字位數(shù)可能有一定的含義,這里將數(shù)字替換為‘x’的處理。最后,將標(biāo)簽統(tǒng)一為數(shù)值(0、1)是否垃圾短信。
#?導(dǎo)入相關(guān)的庫(kù)
import?nltk
from?nltk?import?word_tokenize
from?nltk.corpus?import?stopwords
from?nltk.data?import?load
from?nltk.stem?import?SnowballStemmer
from?string?import?punctuation
import?re??#?正則匹配
stop_words?=?set(stopwords.words('english'))
non_words?=?list(punctuation)
#?詞形、詞干還原
#?from?nltk.stem?import?WordNetLemmatizer
#?wnl?=?WordNetLemmatizer()
stemmer?=?SnowballStemmer('english')
def?stem_tokens(tokens,?stemmer):
????stems?=?[]
????for?token?in?tokens:
????????stems.append(stemmer.stem(token))
????return?stems
###?清除非英文詞匯并替換數(shù)值x
def?clean_non_english_xdig(txt,isstem=True,?gettok=True):
????txt?=?re.sub('[0-9]',?'x',?txt)?#?去數(shù)字替換為x
????txt?=?txt.lower()?#?統(tǒng)一小寫
????txt?=?re.sub('[^a-zA-Z]',?'?',?txt)?#去除非英文字符并替換為空格
????word_tokens?=?word_tokenize(txt)?#?分詞
????if?not?isstem:?#是否做詞干還原
????????filtered_word?=?[w?for?w?in?word_tokens?if?not?w?in?stop_words]??#?刪除停用詞
????else:
????????filtered_word?=?[stemmer.stem(w)?for?w?in?word_tokens?if?not?w?in?stop_words]???#?刪除停用詞及詞干還原
????if?gettok:???#返回為字符串或分詞列表
????????return?filtered_word
????else:
????????return?"?".join(filtered_word)
spam_df['token']?=?spam_df.message.apply(lambda?x:clean_non_english_xdig(x))
spam_df.head(3)
#?數(shù)據(jù)清洗
spam_df['token']?=?spam_df.message.apply(lambda?x:clean_non_english_xdig(x))
#?標(biāo)簽整數(shù)編碼
spam_df['label']?=?(spam_df.label=='spam').astype(int)
spam_df.head(3)

3.3 fasttext詞向量表示學(xué)習(xí)
我們需要將單詞文本轉(zhuǎn)化為數(shù)值的詞向量才能輸入模型。詞向量表示常用的詞袋、fasttext、bert等方法,這里訓(xùn)練的是fasttext,模型的主要輸入?yún)?shù)是,輸入分詞后的語(yǔ)料(通常訓(xùn)練語(yǔ)料越多越好,當(dāng)現(xiàn)有語(yǔ)料有限時(shí)候,直接拿github上合適的大規(guī)模預(yù)訓(xùn)練模型來(lái)做詞向量也是不錯(cuò)的選擇),詞向量的維度size(一個(gè)經(jīng)驗(yàn)的詞向量維度設(shè)定是,dim > 8.33 logN, N為詞匯表的大小,當(dāng)維度dim足夠大才能表達(dá)好這N規(guī)模的詞匯表的含義。可參考《# 最小熵原理(六):詞向量的維度應(yīng)該怎么選擇?By 蘇劍林》)。語(yǔ)料太大的時(shí)候可以使用workers開啟多進(jìn)程訓(xùn)練(其他參數(shù)及詞表示學(xué)習(xí)原理后續(xù)會(huì)專題介紹,也可以自行了解)。
#?訓(xùn)練詞向量?Fasttext?embed模型
from?gensim.models?import?FastText,word2vec
fmodel?=?FastText(spam_df.token,??size=100,sg=1,?window=3,?min_count=1,?iter=10,?min_n=3,?max_n=6,word_ngrams=1,workers=12)
print(fmodel.wv['hello'])?#?輸出hello的詞向量
#?fmodel.save('./data/fasttext100dim')

按照句子所有的詞向量取平均,為每一句子生成句向量。
fmodel?=?FastText.load('./data/fasttext100dim')
#對(duì)每個(gè)句子的所有詞向量取均值,來(lái)生成一個(gè)句子的vector
def?build_sentence_vector(sentence,w2v_model,size=100):
????sen_vec=np.zeros((size,))
????count=0
????for?word?in?sentence:
????????try:
????????????sen_vec+=w2v_model[word]#.reshape((1,size))
????????????count+=1
????????except?KeyError:
????????????continue
????if?count!=0:
????????sen_vec/=count
????return?sen_vec
#?句向量
sents_vec?=?[]
for?sent?in?spam_df['token']:
????sents_vec.append(build_sentence_vector(sent,fmodel,size=100))
????????
print(len(sents_vec))
3.4 訓(xùn)練文本分類模型
示例采用的fasttext embedding + lightgbm的二分類模型,類別不均衡使用lgb代價(jià)敏感學(xué)習(xí)解決(即class_weight='balanced'),超參數(shù)是手動(dòng)簡(jiǎn)單配置的,可以自行搜索下較優(yōu)超參數(shù)。
###?訓(xùn)練文本分類模型
from?sklearn.model_selection?import?train_test_split
from?lightgbm?import?LGBMClassifier
from?sklearn.linear_model?import?LogisticRegression
train_x,?test_x,?train_y,?test_y?=?train_test_split(sents_vec,?spam_df.label,test_size=0.2,shuffle=True,random_state=42)
result?=?[]
clf?=?LGBMClassifier(class_weight='balanced',n_estimators=300,?num_leaves=64,?reg_alpha=?1,reg_lambda=?1,random_state=42)
#clf?=?LogisticRegression(class_weight='balanced',random_state=42)
clf.fit(train_x,train_y)
import?pickle
#?保存模型
pickle.dump(clf,?open('./saved_models/spam_clf.pkl',?'wb'))
#?加載模型
model?=?pickle.load(open('./saved_models/spam_clf.pkl',?'rb'))
3.5 模型評(píng)估
訓(xùn)練集測(cè)試集按0.2劃分,分布驗(yàn)證訓(xùn)練集測(cè)試集的AUC、F1score等指標(biāo),均有不錯(cuò)的表現(xiàn)。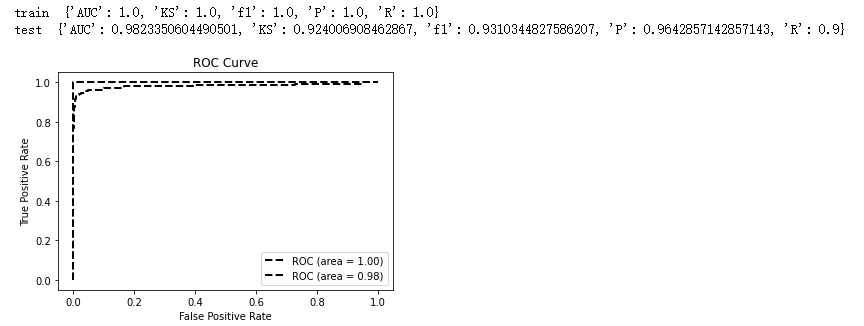
from?sklearn.metrics?import?auc,roc_curve,f1_score,precision_score,recall_score
def?model_metrics(model,?x,?y,tp='auc'):
????"""?評(píng)估?"""
????yhat?=?model.predict(x)
????yprob?=?model.predict_proba(x)[:,1]
????fpr,tpr,_?=?roc_curve(y,?yprob,pos_label=1)
????metrics?=?{'AUC':auc(fpr,?tpr),'KS':max(tpr-fpr),
???????????????'f1':f1_score(y,yhat),'P':precision_score(y,yhat),'R':recall_score(y,yhat)}
????
????roc_auc?=?auc(fpr,?tpr)
????plt.plot(fpr,?tpr,?'k--',?label='ROC?(area?=?{0:.2f})'.format(roc_auc),?lw=2)
????plt.xlim([-0.05,?1.05])??#?設(shè)置x、y軸的上下限,以免和邊緣重合,更好的觀察圖像的整體
????plt.ylim([-0.05,?1.05])
????plt.xlabel('False?Positive?Rate')
????plt.ylabel('True?Positive?Rate')??#?可以使用中文,但需要導(dǎo)入一些庫(kù)即字體
????plt.title('ROC?Curve')
????plt.legend(loc="lower?right")
????return?metrics
print('train?',model_metrics(clf,??train_x,?train_y,tp='ks'))
print('test?',model_metrics(clf,?test_x,test_y,tp='ks'))
-?推薦閱讀-
深度學(xué)習(xí)系列機(jī)器學(xué)習(xí)系列
文末,粉絲福利來(lái)了!!關(guān)注【算法進(jìn)階】??
后臺(tái)回復(fù)【課程】,即可免費(fèi)領(lǐng)取Python|機(jī)器學(xué)習(xí)|AI 精品課程大全
 機(jī)??器學(xué)習(xí)算法交流群,邀您加入!!!
機(jī)??器學(xué)習(xí)算法交流群,邀您加入!!!入群:提問求助、認(rèn)識(shí)行業(yè)內(nèi)同學(xué)、交流進(jìn)步、共享資源...
掃描??下方二維碼,備注“加群”
