
一文概覽2D人體姿態(tài)估計(jì)
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

來自 | 知乎 作者 | 謝一賓
鏈接 | https://zhuanlan.zhihu.com/p/140060196
編輯 | 深度學(xué)習(xí)這件小事公眾號(hào)
本文經(jīng)作者授權(quán)轉(zhuǎn)載,請(qǐng)勿二次轉(zhuǎn)發(fā)
0. 前言
1. 介紹

單人姿態(tài)估計(jì)是基礎(chǔ),在這個(gè)問題中,我們要做的事情就是給我們一個(gè)人的圖片,我們要找出這個(gè)人的所有關(guān)鍵點(diǎn),常用的MPII數(shù)據(jù)集就是單人姿態(tài)估計(jì)的數(shù)據(jù)集。
在多人姿態(tài)估計(jì)中,我們得到的是一張多人的圖,我們需要找出這張圖中的所有人的關(guān)鍵點(diǎn)。對(duì)于這個(gè)問題,一般有自上而下(Top-down)和自下而上(Bottom-up)兩種方法。 Top-down: (從人到關(guān)鍵點(diǎn))先使用detector找到圖片中的所有人的bounding box,然后在對(duì)單個(gè)人進(jìn)行SPPE。這個(gè)方法是Detection+SPPE,往往可以得到更好的精度,但是速度較慢。 Bottom-up: (從關(guān)鍵點(diǎn)到人)先使用一個(gè)model檢測(cè)(locate)出圖片中所有關(guān)鍵點(diǎn),然后把這些關(guān)鍵點(diǎn)分組(group)到每一個(gè)人。這種方法往往速度可以實(shí)時(shí),但是精度較差。
2. 難點(diǎn)
遮擋(自遮擋,被其他人遮擋)
擴(kuò)大感受野,讓網(wǎng)絡(luò)自己去學(xué)習(xí)被遮擋的關(guān)系
人的尺度不一,拍照角度不一
多尺度特征融合
各種各樣的姿態(tài)
考驗(yàn)網(wǎng)絡(luò)的容量,深度
光照
在數(shù)據(jù)預(yù)處理中加入光照變化的因素,對(duì)每個(gè)通道做偏移
3. 方法
3.1. SPPE
DeepPose (Google, 2014)[1]
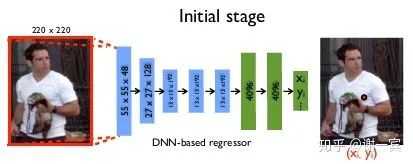
使用AlexNet作為backbone
直接回歸關(guān)節(jié)點(diǎn)的坐標(biāo)
使用級(jí)聯(lián)的結(jié)構(gòu)來refine結(jié)果
Joint training with CNN and Graphical Model(LeCun, 2014)[2]
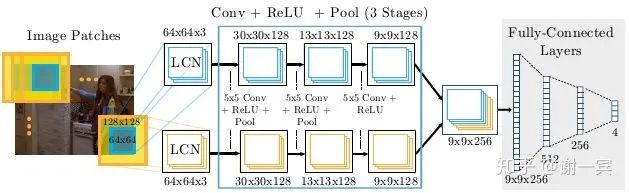
開始使用heatmap
CPM (CMU, 2016)[3]
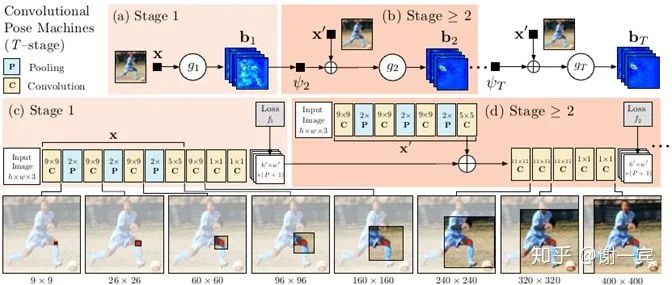
網(wǎng)絡(luò)有多個(gè)stage組成,以第二個(gè)stage為例,他的輸入由兩部分組成,一個(gè)是上一個(gè)stage預(yù)測(cè)出的heatmap,一個(gè)是自己這個(gè)stage中得到的feature map,也就是在每一個(gè)stage都做一次loss計(jì)算,這樣做可以使網(wǎng)絡(luò)收斂更快也有助于提高精度。
上一層預(yù)測(cè)的heatmap可以提供豐富的spatial context,這對(duì)關(guān)節(jié)點(diǎn)的識(shí)別是非常重要的
正式開啟e2e學(xué)習(xí)時(shí)代
Stacked Hourglass Network (Jia Deng組, 2016)[4]
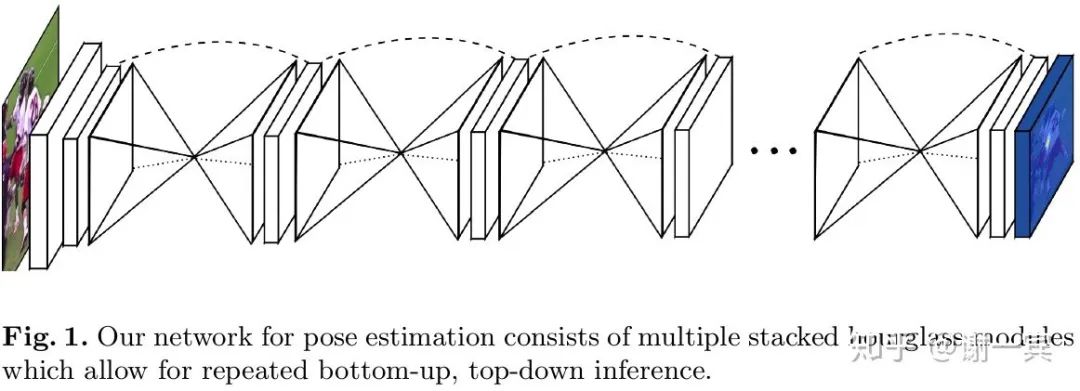
該工作的主要?jiǎng)?chuàng)新在于網(wǎng)絡(luò)結(jié)構(gòu)方面的改進(jìn),從圖中可以看出,形似堆疊的沙漏。
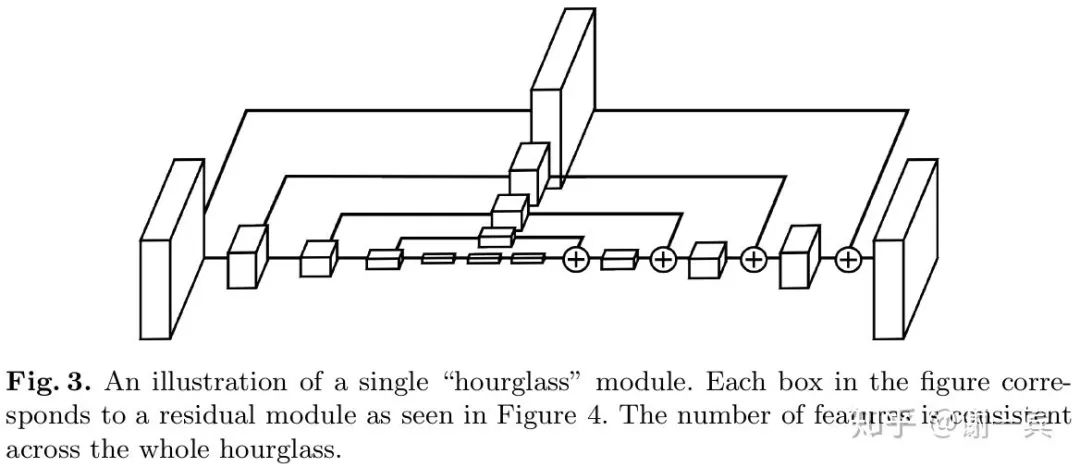
每一個(gè)沙漏模塊包含了對(duì)稱的下采樣和上采樣的過程,每一個(gè)box都代表了一個(gè)有跨層連接的子模塊
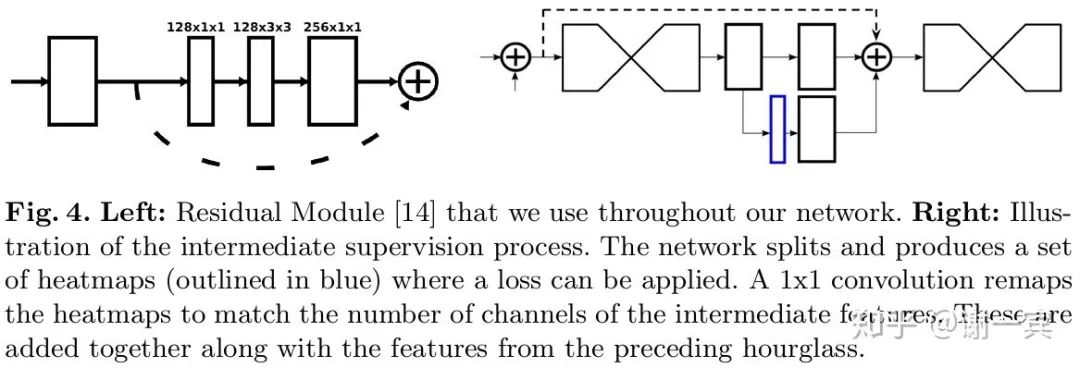
網(wǎng)絡(luò)使用了中間監(jiān)督,也就是圖中的藍(lán)色框是一個(gè)預(yù)測(cè)的heatmap,這加快了網(wǎng)絡(luò)的收斂也提高了實(shí)際效果
Fast Human Pose (2019)[5]
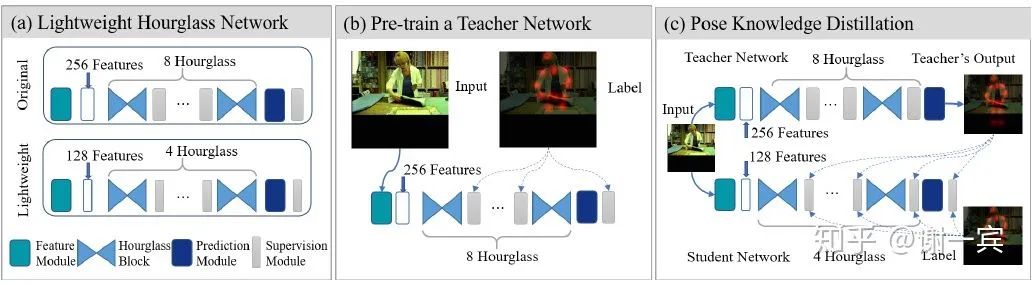
為了追求cost-effective,需要compact的網(wǎng)絡(luò)結(jié)構(gòu)
4-stage hourglass可以取得95%的8-stage的效果
一半的channel數(shù)(128)只會(huì)導(dǎo)致1%的performance drop
使用蒸餾來做監(jiān)督的增強(qiáng),Students learn knowledge from books (dataset) and teachers (advanced networks).
3.2. MPPE
3.2.1. Top-down
G-RMI (Google, 2017)[6]

Faster-RCNN得到bounding box之后進(jìn)行image cropping,使得所有box具有同樣的縱橫比,然后擴(kuò)大box來包含更多圖像上下文
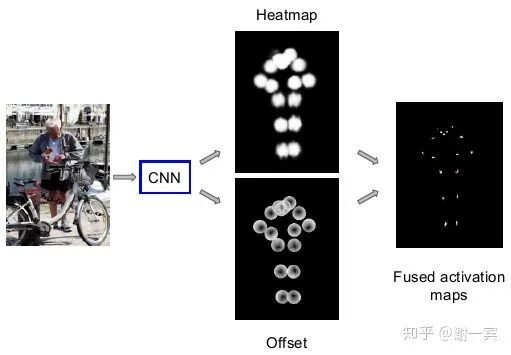
使用ResNet作為backbone來估計(jì)heatmap和offset vector,因?yàn)榈玫絟eatmap之后我們往往還需要一個(gè)argmax的操作才能得到關(guān)節(jié)點(diǎn)的坐標(biāo),而這個(gè)過程中由于網(wǎng)絡(luò)的下采樣過程,heatmap勢(shì)必分辨率比原圖更小,所以得到的坐標(biāo)會(huì)出現(xiàn)偏移,因此又估計(jì)了一個(gè)offset vector來補(bǔ)償?shù)暨@種量化誤差。
OKS-based NMS:基于關(guān)鍵點(diǎn)相似度來衡量?jī)蓚€(gè)候選姿態(tài)的重疊情況,在目標(biāo)檢測(cè)中常基于IoU來做NMS,但是姿態(tài)估計(jì)中輸出的是關(guān)鍵點(diǎn),更適合用這種屬性來衡量。
RMPE (上交盧策吾老師組, 2017)[7]
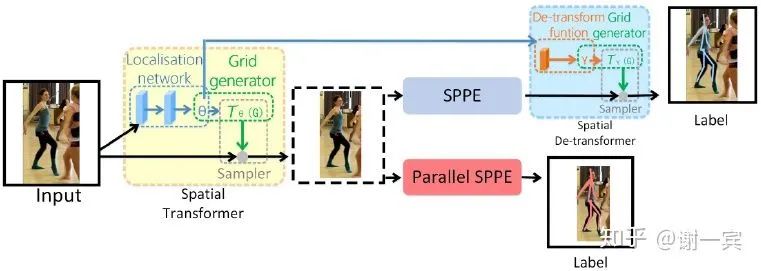
SSTN(Symmetric Spatial Transformer Network):在不準(zhǔn)確的bounding box中提取擔(dān)任區(qū)域
STN來選擇RoI
SPPE幫助STM得到準(zhǔn)確的區(qū)域
PNMS(Parametric Pose Non-Maximum-Suppression)來去除冗余的姿態(tài)
PGPG(Pose-Guided Proposals Generator)
Compositional Human Pose Regression (MSRA, 2018)[8]
CPN (曠視,2018)[9]
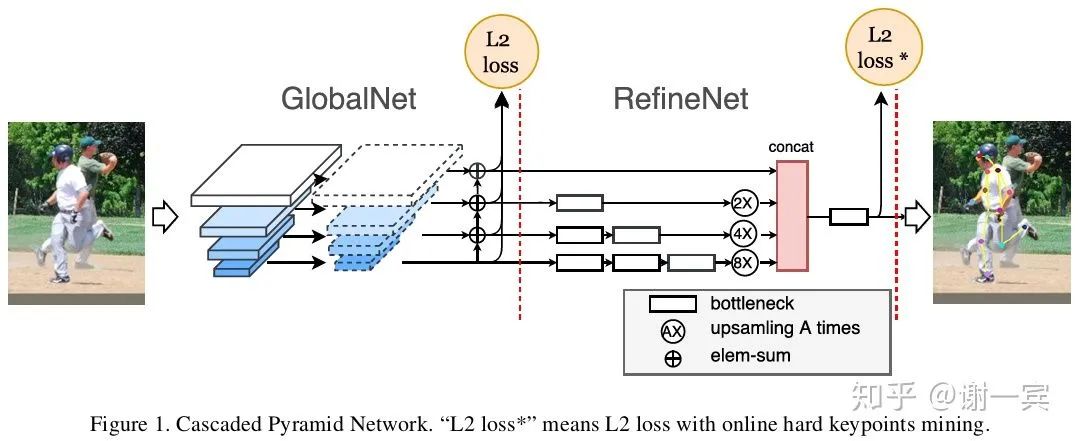
多尺度特征信息的融合是網(wǎng)絡(luò)設(shè)計(jì)的一個(gè)很大的目標(biāo),作者使用 GlobalNet (global pyramid network, U-Shape)來處理easy keypoints,GlobalNet中包含了下采樣和上采樣(插值非轉(zhuǎn)置卷積)的過程。
使用RefineNet (pyramid refined network)來處理hard keypoints
OHKM(online hard keypoints mining)用來找出hard keypoints,類似于檢測(cè)中的OHEM
MSPN (曠視,2018)[10]
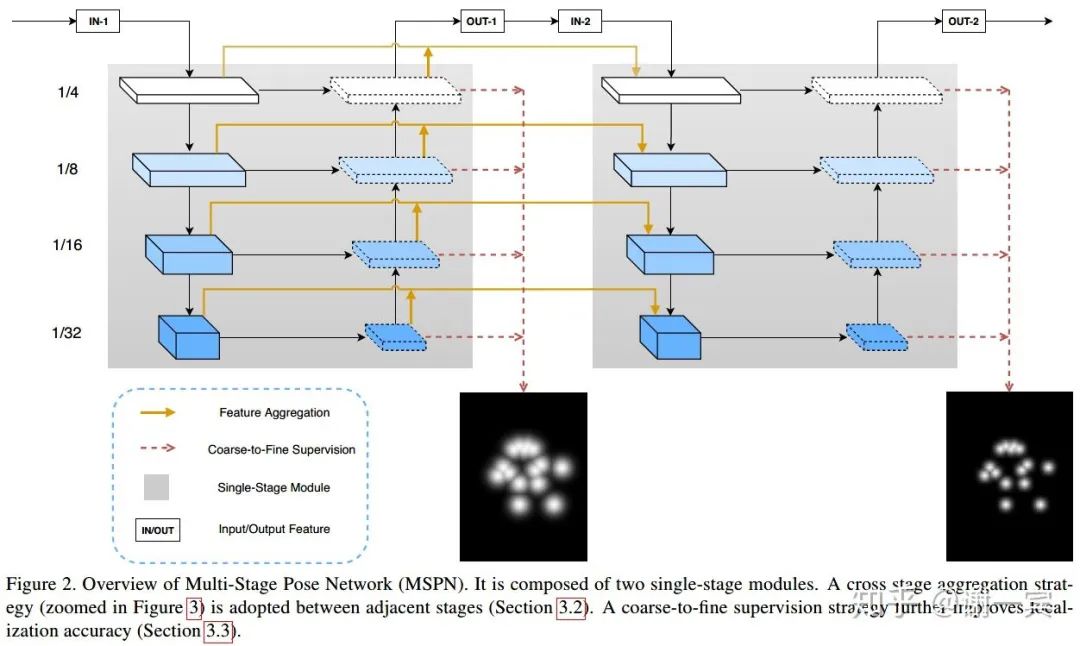
網(wǎng)絡(luò)結(jié)構(gòu)方面的改進(jìn)
Simple Baseline (MSRA, 2018)[11]
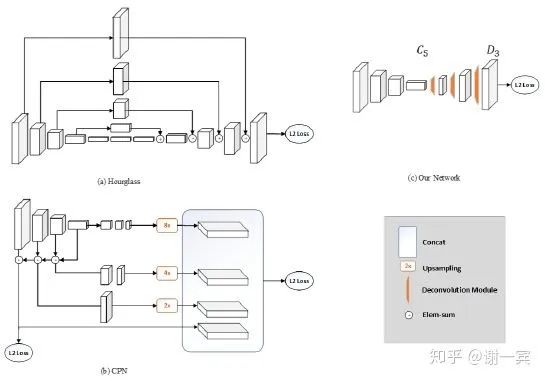
從圖中不難看出,這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)非常簡(jiǎn)潔,作者使用Deconvolution來做上采樣,網(wǎng)絡(luò)中也沒有不同特征層之間的跨層連接,和經(jīng)典的網(wǎng)絡(luò)結(jié)構(gòu)Hourglass和CPN相比都十分簡(jiǎn)潔。
MultiPoseNet (2018)[12]
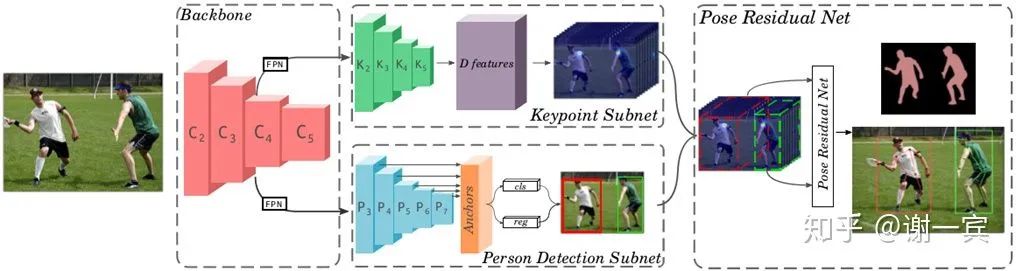
backbone也就是用來提取特征的部分采用的是resnet和兩個(gè)FPN(用兩個(gè)的原因是因?yàn)楹竺嬉觾蓚€(gè)subnet)
keypoint subnet用來輸出keypoint和segmentation的heatmap
person detect subnet用來檢測(cè)人體,使用的是RetinaNet作為detector
pose residual network輸出最終的pose,說是在學(xué)習(xí)了data的pose structures之后可以有效應(yīng)對(duì)遮擋的問題
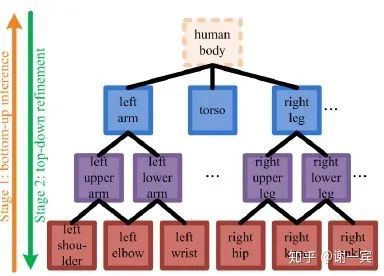
Deeply learned compositional models (2019)[13]
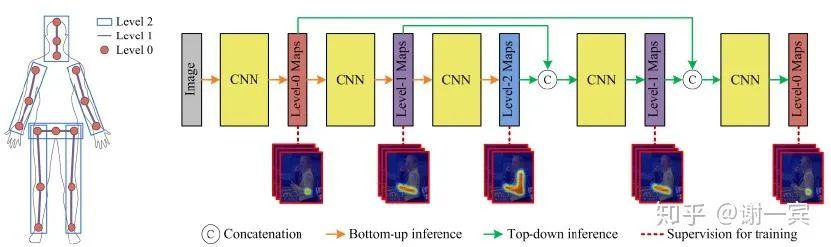
compositional models
HRNet (MSRA, 2019)[14]
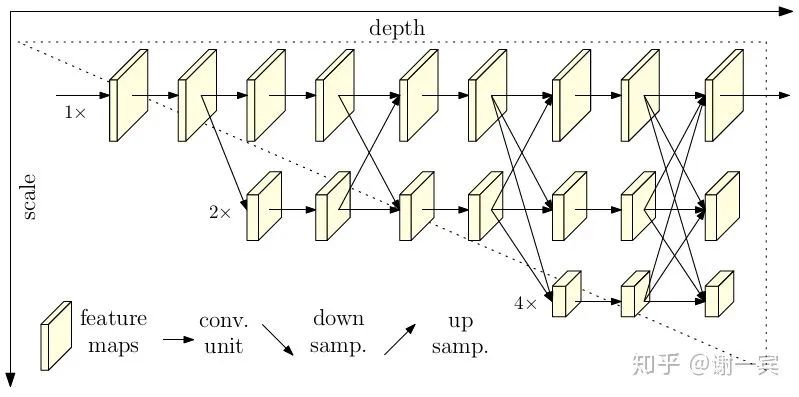
各個(gè)scale之間互相fuse,并不是一個(gè)串聯(lián)的下采樣過程,這樣保留了原分辨率的feature,會(huì)有很好的spatial信息。
Enhanced Channel-wise and Spatial Information (字節(jié)跳動(dòng), 2019)[15]
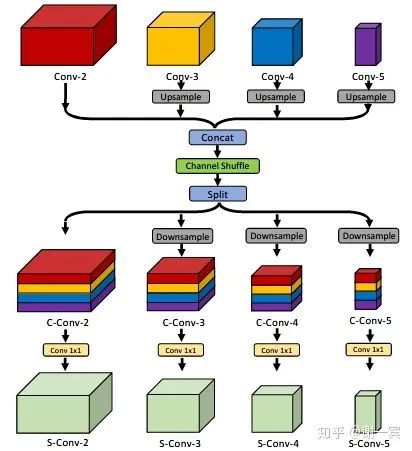
Channel Shuffle Module (CSM): reshape-transpose-reshape, 經(jīng)過這一通操作之后,希望feature能夠和通道的上下文信息相關(guān)。

spatial attention: (feature level)希望網(wǎng)絡(luò)對(duì)于特征圖是pay attention to task-related regions而不是整張圖片。
Channel-wise Attention: (channel level) 從SE-Net中借鑒來,主要包含GAP和Sigmoid兩個(gè)步驟,希望網(wǎng)絡(luò)可以選擇更好的通道來detect pattern。
Related Parts Help (2019)[16]
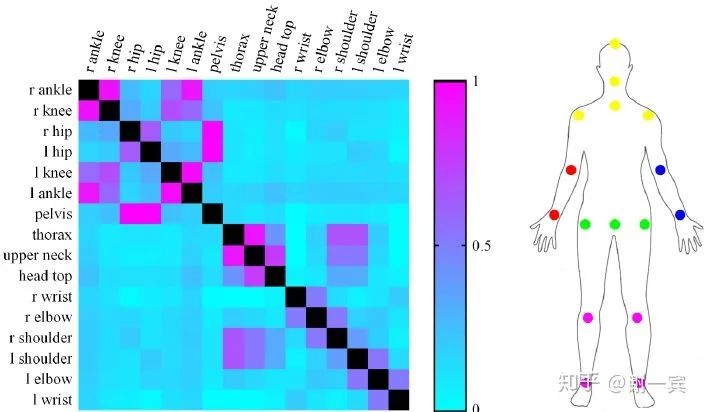
Related body parts 把keypoint分成多個(gè)group,根據(jù)mutual information
Part-based branching network (PBN) learn specific features for each group of related parts
Crowd Pose (上交盧策吾老師組,2019)[17]

在擁擠場(chǎng)景下,在同一個(gè)box內(nèi),我們可能需要處理很多其他人的關(guān)鍵點(diǎn),該項(xiàng)工作設(shè)計(jì)了joints candidate loss來估計(jì)multi-peak heatmaps,讓所有可能的關(guān)節(jié)點(diǎn)都作為候選。
Person-joint Graph: joint node是通過關(guān)節(jié)點(diǎn)間的距離來建立,person node通過檢測(cè)的human proposals來建立,兩者之間的edge通過看是否有contribution來建立。由此建立了一個(gè)人-關(guān)節(jié)的graph,也就轉(zhuǎn)化到了圖論問題上,目標(biāo)就是最大化二分圖中的邊權(quán)重。使用updated Kuhn-Munkres解決這個(gè)問題。
Single-Stage Multi-Person Pose Machines (NUS, 2019)[18]
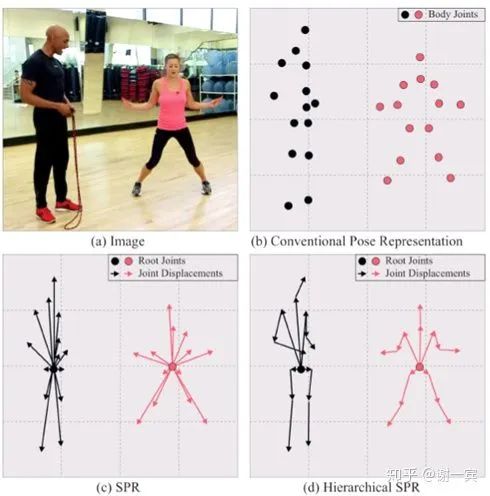
Hierarchical SPR
A unique root for each person
Several joint displacements for each joint
heatmap for root joint (L2 loss)
dense displacement map for each joint (smooth L1 loss)
3.2.2. Bottom-up
DeepCut (Germany, 2016)[19]

pipeline(Bottom-up)
detect 檢測(cè)人體關(guān)鍵點(diǎn)(Adapted Fast R-CNN)并且把他們表示為graph中的節(jié)點(diǎn)
label 使用人體關(guān)節(jié)點(diǎn)類別給檢測(cè)出的關(guān)鍵點(diǎn)分類,比如arm, leg
partition 將關(guān)鍵點(diǎn)分組到同一個(gè)人
使用pairwise terms來做優(yōu)化
Associative Embedding (Jia Deng組,2016)[20]
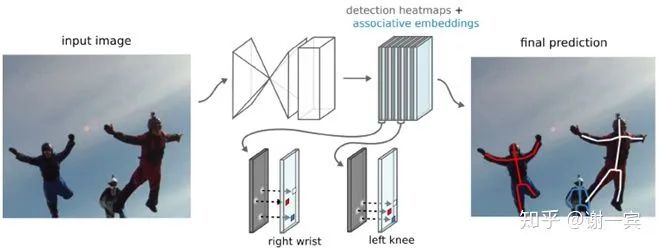
produce detection heatmaps and associate embedding tags together (bottom-up but single-stage) and then match detections to others that share the same embedding tag
主要的工作在于提出了associate embedding tag,也就是說預(yù)測(cè)每個(gè)關(guān)節(jié)點(diǎn)的時(shí)候也同時(shí)預(yù)測(cè)這個(gè)關(guān)節(jié)點(diǎn)的tag值,具有相同tag值的就是同一個(gè)人的關(guān)節(jié)點(diǎn)
DeeperCut (Germany, 2017)[21]
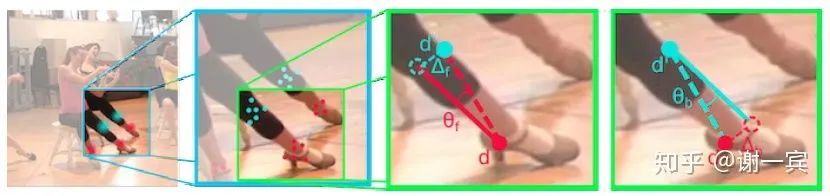
使用深層的ResNet架構(gòu)來檢測(cè)body part
使用image-conditioned pairwise terms來做優(yōu)化,可以將眾多候選節(jié)點(diǎn)減少,通過候選節(jié)點(diǎn)之間的距離來判斷該節(jié)點(diǎn)是否重要
OpenPose (CMU, 2017)[22]

網(wǎng)絡(luò)結(jié)構(gòu)基于CPM改進(jìn),網(wǎng)絡(luò)包含兩個(gè)分支,一個(gè)分支預(yù)測(cè)heatmap,另一個(gè)分支預(yù)測(cè)paf(part affine field),paf也是這項(xiàng)工作的關(guān)鍵所在。
paf是兩個(gè)關(guān)節(jié)點(diǎn)連接的向量場(chǎng),可以把它看做肢體,以paf為基礎(chǔ),把group的問題轉(zhuǎn)化文二分圖匹配(bipartite graph)的問題,使用匈牙利算法求解。
PersonLab (2018)[23]
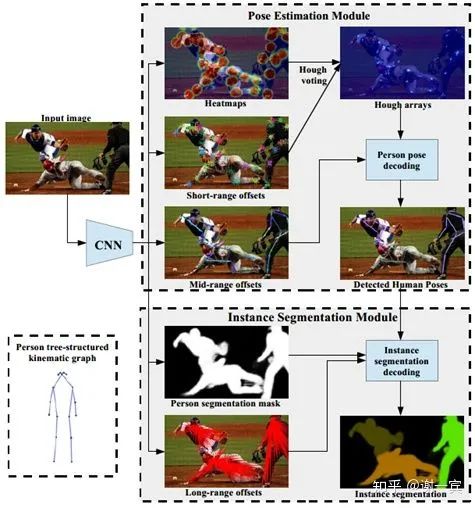
short-range offsets to refine heatmaps
mid-range to predict pairs of keypoints
greedy decoding to group keypoints into instances
PifPaf (EPFL, 2019)[24]
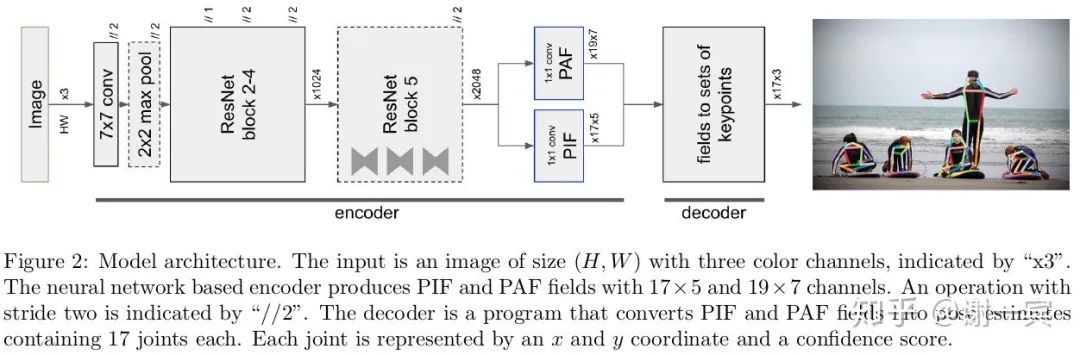
從圖中可以看出,網(wǎng)絡(luò)基于ResNet,encoder最后輸出兩個(gè)分支,PIF和PAF向量場(chǎng)。
PIF向量場(chǎng)是17x5,其中17是關(guān)節(jié)數(shù),5表示用于優(yōu)化heatmap的值。
PAF向量場(chǎng)是19x7,其中19代表了19種肢體連接,7表示了confidence和offset來優(yōu)化肢體向量的值。
關(guān)鍵點(diǎn)由PIF給出,關(guān)鍵點(diǎn)之間的連接由PAF給出,接下來就是使用Greedy Decoding進(jìn)行g(shù)roup的過程了。
HigherHRNet (字節(jié)跳動(dòng),2020)[25]
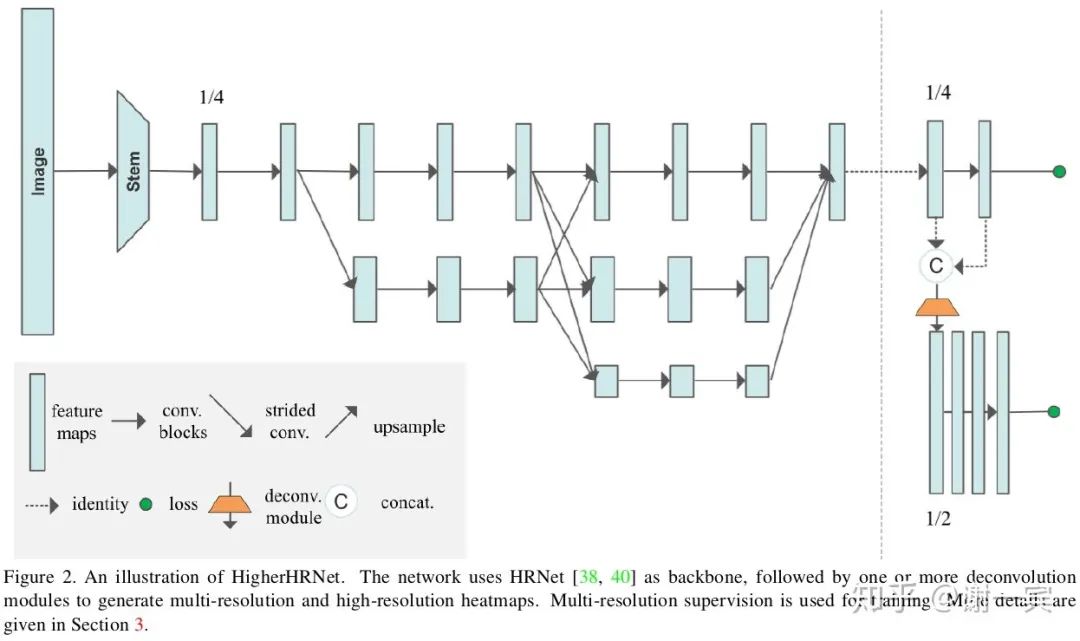
HRNet在bottom-up方法中的嘗試,associative embedding加上更強(qiáng)大的網(wǎng)絡(luò)。
4. 總結(jié)
好消息!
小白學(xué)視覺知識(shí)星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~