大數(shù)據(jù)文摘授權(quán)轉(zhuǎn)載自數(shù)據(jù)派THU
作者:Andrew Udell
翻譯:王闖(Chuck)、校對:廖倩穎
基于Kaggle上的Wish數(shù)據(jù)集,這篇文章用Python演示了隨機(jī)森林回歸預(yù)測商品銷量的方法,對于讀者分析和解決此類問題是很好的借鑒。
數(shù)據(jù)集
為了演示隨機(jī)森林回歸,我們這里會用到當(dāng)下非常流行的Wish(“美版拼多多”)的電商銷售數(shù)據(jù)集。數(shù)據(jù)集來自Kaggle,僅包含夏季服裝的銷售信息。其屬性包括產(chǎn)品說明,評價,是否使用了廣告宣傳,是否在產(chǎn)品列表中添加了“手慢無”標(biāo)語以及已售出的商品數(shù)量等。我們采用隨機(jī)森林回歸這一利器來預(yù)測商品的銷量。一個好的,準(zhǔn)確的預(yù)測不但對于庫存計劃人員的工作有非常大的價值,因為他們需要估計訂購或者生產(chǎn)多少產(chǎn)品,而且對于銷售人員理解產(chǎn)品在電商平臺的表現(xiàn)也是至關(guān)重要的。數(shù)據(jù)導(dǎo)入和清理
所有數(shù)據(jù)的導(dǎo)入和操作都將通過python及其pandas和numpy庫來完成。import pandas as pdimport numpy as np
# import the data saved as a csvdf = pd.read_csv("Summer_Sales_08.2020.csv")
前兩行分別導(dǎo)入pandas和numpy庫。最后一行讀入前先保存過并重命名為“ Summer_Sales_08.2020”的CSV文件,并創(chuàng)建了一個數(shù)據(jù)框。df["has_urgency_banner"] = df["has_urgency_banner"].fillna(0)
df["discount"]?=?(df["retail_price"]?-?df["price"])/df["retail_price"]
“has_urgency_banner”這一列表示產(chǎn)品列表中是否使用了“手慢無”標(biāo)語,在查看數(shù)據(jù)時發(fā)現(xiàn)這一列的編碼方式不是很合適。這里并沒有采用通常的1和0編碼,而是在沒有使用標(biāo)語時留空。代碼第一行我們用0填充這些空白。代碼第二行創(chuàng)建名為“折扣”的新的一列,該列計算實際銷售價和建議零售價之間的折扣。df [“ rating_five_percent”] = df [“ rating_five_count”] / df [“ rating_count”] df [“ rating_four_percent”] = df [“ rating_four_count”] / df [“ rating_count”] df [“ rating_three_percent”] = df [“ rating_three_count“] / df [” rating_count“] df [” rating_two_percent“] = df [” rating_two_count“] / df [” rating_count“] df [” rating_one_percent“] = df [” rating_one_count“] / df [” rating_count“]
原始數(shù)據(jù)集包括幾個專門用于產(chǎn)品評價的列。除了平均評分之外,它還包括評價總數(shù)以及五,四,三,二和一星評價的數(shù)量。由于已經(jīng)考慮了評價的總數(shù),因此最好分別計算出各星級評價數(shù)占總評價數(shù)的百分比,這樣就可以在產(chǎn)品之間進(jìn)行直接比較。上面的幾行代碼簡單地創(chuàng)建了五個新的列,為數(shù)據(jù)集中的每種產(chǎn)品給出了五,四,三,二和一星級評價的百分比。ratings = [ "rating_five_percent", "rating_four_percent", "rating_three_percent", "rating_two_percent", "rating_one_percent"]
for rating in ratings: df[rating] = df[rating].apply(lambda x: x if x>= 0 and x<= 1 else 0)
雖然Rating_count == 0的情況下,但在分析數(shù)據(jù)時會出現(xiàn)問題。在本例中,在上一步進(jìn)行計算時,評價數(shù)為0的產(chǎn)品會出現(xiàn)問題。上面一段代碼遍歷了所有新創(chuàng)建的列,并檢查輸入的值是否介于0和1之間(包括0和1)。如果不是,則將它們替換為0,該替換足以解決問題。數(shù)據(jù)探索
import seaborn as sns
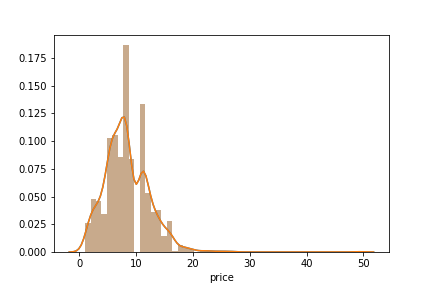
# Distribution plot on pricesns.distplot(df['price'])
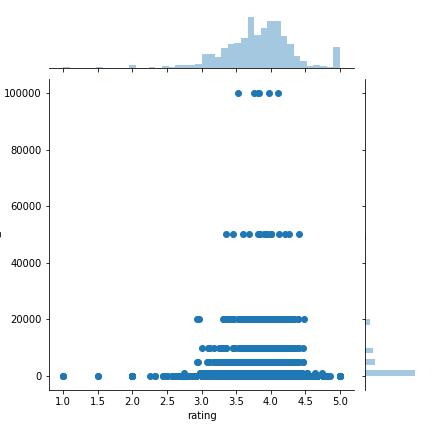
上面的代碼生成了數(shù)據(jù)集中所有產(chǎn)品的價格分布圖。最明顯和最有趣的發(fā)現(xiàn)是,沒有任何產(chǎn)品的價格為10歐元。這可能是商家為使他們的產(chǎn)品進(jìn)入“10歐元及以下”的清單故意為之。sns.jointplot(x =“ rating”,y =“ units_sold”,data = df,kind =“ scatter”)
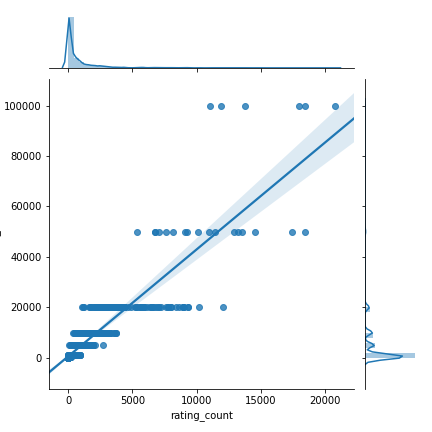
評分與銷量之間關(guān)系的散點圖。圖由作者制作。從上圖可以看出,絕大部分的銷售都是由三星到四星半的產(chǎn)品貢獻(xiàn)的。圖中還顯示大多數(shù)產(chǎn)品的銷量少于20,000,而少數(shù)產(chǎn)品的銷量分別達(dá)到了60,000和100,000。順便說一句,散點圖呈直線排列的趨勢證明了銷量更有可能是估計值而不是實際值。sns.jointplot(x =“ rating_count”,y =“ units_sold”,data = df,kind =“ reg”)
評價數(shù)量和銷量之間關(guān)系的散點圖。圖由作者制作。此圖展示了評價的另一面。評價數(shù)量與產(chǎn)品銷量之間存在著松散的正相關(guān)關(guān)系。這可能是因為消費者在考慮購買商品時會同時參考總體評分和評價數(shù)量,或者是因為暢銷產(chǎn)品自然會產(chǎn)生更多評價。由于沒有關(guān)于購買時間和評價時間的額外數(shù)據(jù),在沒有額外領(lǐng)域知識的情況下很難辨別其相關(guān)原因。什么是隨機(jī)森林回歸?
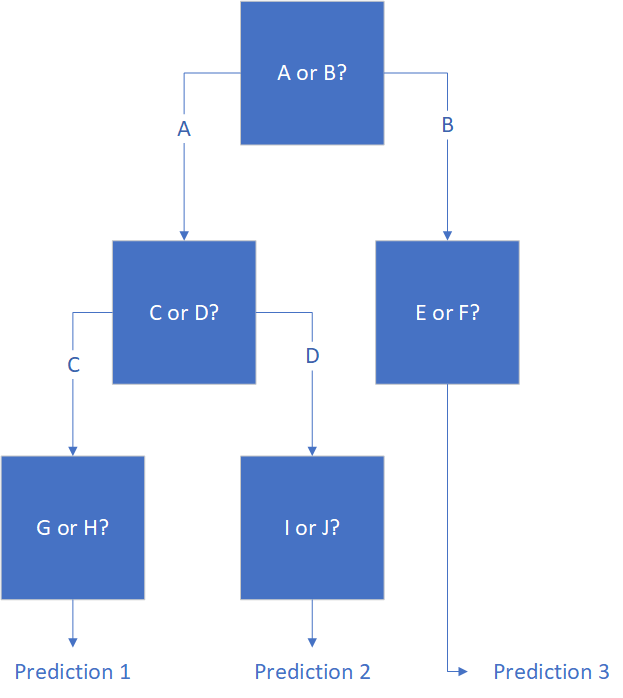
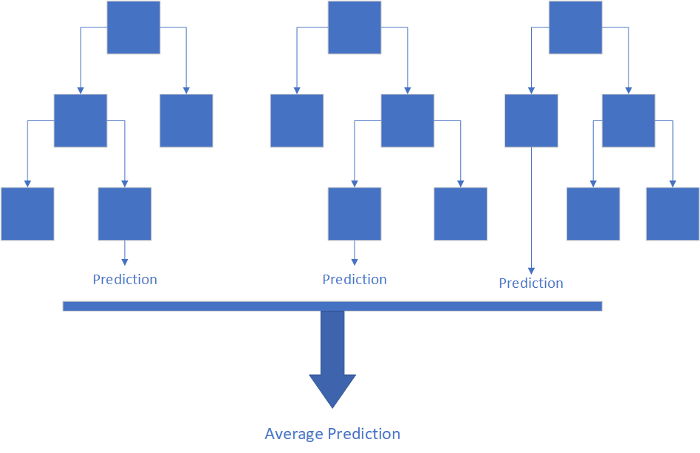
簡而言之,隨機(jī)森林回歸是一系列決策樹的平均結(jié)果。決策樹就像流程圖一樣,它提出一些問題并根據(jù)這些問題的答案做出預(yù)測。例如,試圖預(yù)測一個網(wǎng)球玩家是否會去球場的決策樹可能會問:下雨了嗎?如果是的,球場在室內(nèi)嗎?如果不是,玩家可以找到玩伴嗎?然后,決策樹將在做出預(yù)測之前回答所有這些問題。盡管比其他機(jī)器學(xué)習(xí)技術(shù)更容易理解,而且據(jù)一些專家稱,決策樹比其他機(jī)器學(xué)習(xí)更好地模擬實際的人類行為,但它們通常會使數(shù)據(jù)過擬合,這意味著它們通常會在相似的數(shù)據(jù)集上得出截然不同的結(jié)果。為了解決此問題,從同一數(shù)據(jù)集中提取多個決策樹,然后裝袋(bagged),并返回結(jié)果的平均值。這被稱為隨機(jī)森林回歸。它的主要優(yōu)點是可以對高度非線性的數(shù)據(jù)進(jìn)行準(zhǔn)確的預(yù)測。在Wish數(shù)據(jù)集中,我們在評價中看到了非線性關(guān)系。雖然不是強(qiáng)相關(guān),不會輕易察覺到,但還是清晰可見評分在三顆星以下,四顆半以上的分界線。隨機(jī)森林回歸可以識別此模式并將其納入結(jié)果。然而,在更傳統(tǒng)的線性回歸中,這只會混淆其預(yù)測。此外,隨機(jī)森林分類器效率很高,可以處理諸多輸入變量,而且通常可以進(jìn)行準(zhǔn)確的預(yù)測。這是一個功能極其強(qiáng)大的工具,不需要太多的代碼即可實現(xiàn)。隨機(jī)森林回歸的實現(xiàn)
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressor
# Divide the data between units sold and influencing factorsX = df.filter([ "price", "discount", "uses_ad_boosts", "rating", "rating_count", "rating_five_percent", "rating_four_percent", "rating_three_percent", "rating_two_percent", "rating_one_percent", "has_urgency_banner", "merchant_rating", "merchant_rating_count", "merchant_has_profile_picture"])
Y = df["units_sold"]
# Split the data into training and testing setsX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state = 42)
在運行任何模型之前,前兩行將引入相關(guān)的庫。接下來幾行創(chuàng)建兩個變量X和Y,然后將數(shù)據(jù)集分為訓(xùn)練集和測試集。測試集大小賦值為0.33,這可以確保大約三分之二的數(shù)據(jù)集將用于訓(xùn)練數(shù)據(jù),三分之一將用于測試數(shù)據(jù)的準(zhǔn)確性。# Set up and run the modelRFRegressor = RandomForestRegressor(n_estimators = 20)RFRegressor.fit(X_train, Y_train)
接下來,初始化模型并開始運行。注意,參數(shù)n_estimators表示要使用的決策樹的數(shù)量。#?Set?up?and?run?the?modelRFRegressor = RandomForestRegressor(n_estimators = 20)RFRegressor.fit(X_train, Y_train)
最后,將新擬合的隨機(jī)森林回歸模型應(yīng)用在測試數(shù)據(jù)上,利用其差值生成誤差數(shù)組。到這就大功告成了!
總結(jié)
Wish數(shù)據(jù)集就像數(shù)字試驗田,可以用來解決真實世界的實際問題。隨機(jī)森林回歸只需進(jìn)行很少的數(shù)據(jù)操作,已被證明是分析此類數(shù)據(jù)的寶貴工具,效果顯著。原文鏈接:
https://towardsdatascience.com/predicting-e-commerce-sales-with-a-random-forest-regression-3f3c8783e49b