
DETR憶往昔 | 全面回顧DETR目標(biāo)檢測的預(yù)訓(xùn)練方法,讓DETR訓(xùn)練起來更加絲滑
點擊下方卡片,關(guān)注「集智書童」公眾號

受到DETR基于方法在COCO檢測和分割基準(zhǔn)上取得新紀(jì)錄的激勵,最近的許多努力都表現(xiàn)出對如何通過自監(jiān)督方式預(yù)訓(xùn)練Transformer并保持Backbone網(wǎng)絡(luò)不變以進(jìn)一步改進(jìn)DETR方法的興趣增加。一些研究已經(jīng)聲稱在準(zhǔn)確性方面取得了顯著的改進(jìn)。
在本文中,作者對他們的實驗方法進(jìn)行了更詳細(xì)的研究,并檢查他們的方法在最近的H-Deformable-DETR等最先進(jìn)模型上是否仍然有效。作者對COCO目標(biāo)檢測任務(wù)進(jìn)行了全面的實驗,研究了預(yù)訓(xùn)練數(shù)據(jù)集的選擇、定位和分類目標(biāo)生成方案的影響。
不幸的是,作者發(fā)現(xiàn)之前代表性的自監(jiān)督方法,如DETReg,在完整的數(shù)據(jù)范圍上未能提升強大的基于DETR的方法的性能。作者進(jìn)一步分析了原因,并發(fā)現(xiàn)僅僅將更準(zhǔn)確的邊界框預(yù)測器與Objects365基準(zhǔn)相結(jié)合,就可以顯著提高后續(xù)實驗的結(jié)果。
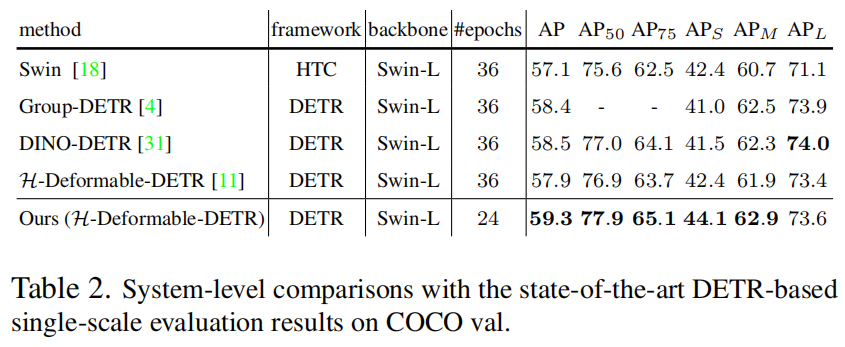
作者通過在COCO驗證集上實現(xiàn)AP=59.3%的強大目標(biāo)檢測結(jié)果來證明作者方法的有效性,這超過了H-Deformable-DETR + Swin-L 1.4%。
最后,作者通過結(jié)合最近的圖像到文本字幕模型(LLaVA)和文本到圖像生成模型(SDXL)生成了一系列合成的預(yù)訓(xùn)練數(shù)據(jù)集。值得注意的是,對這些合成數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練可以顯著提高目標(biāo)檢測性能。展望未來,作者預(yù)計通過擴展合成預(yù)訓(xùn)練數(shù)據(jù)集將獲得實質(zhì)性的優(yōu)勢。
1、簡介
最近,基于DETR的方法在目標(biāo)檢測和分割任務(wù)上取得了顯著進(jìn)展,并推動了前沿研究。例如,DINO-DETR、H-Deformable-DETR和Group-DETRv2在COCO基準(zhǔn)上刷新了目標(biāo)檢測性能的最新成果。MaskDINO進(jìn)一步擴展了DINO-DETR,在COCO實例分割和全景分割任務(wù)上取得了最佳結(jié)果。在某種程度上,這是首次端到端的Transformer方法能夠比基于卷積的常規(guī)高度調(diào)優(yōu)的強檢測器(如Cascade Mask-RCNN和HTC++)實現(xiàn)更好的性能。
這些基于DETR的方法取得了巨大的成功,但它們?nèi)匀贿x擇隨機初始化Transformer,因此未能充分發(fā)揮像《 Aligning pretraining for detection via object-level contrastive learning》這樣完全預(yù)訓(xùn)練的檢測架構(gòu)的潛力,該架構(gòu)已經(jīng)驗證了將預(yù)訓(xùn)練架構(gòu)與下游架構(gòu)對齊的好處。
圖1a和1b說明了基于ResNet50 Backbone網(wǎng)的標(biāo)準(zhǔn)Deformable-DETR網(wǎng)絡(luò)中參數(shù)數(shù)量和GFLOPs的分布情況。作者可以看到,Transformer編碼器和解碼器占據(jù)了65%的GFLOPs和34%的參數(shù),這意味著在DETR內(nèi)部進(jìn)行Transformer部分的預(yù)訓(xùn)練路徑上存在著很大的改進(jìn)空間。

近期有幾項研究通過在Transformer編碼器和解碼器上進(jìn)行自監(jiān)督預(yù)訓(xùn)練,并凍結(jié)Backbone網(wǎng)絡(luò),改善了基于DETR的目標(biāo)檢測模型(請參見圖2的流程)。例如,UP-DETR 將Transformer預(yù)訓(xùn)練為檢測圖像中的隨機Patch,DETReg 將Transformer預(yù)訓(xùn)練為將對象位置和特征與從選擇性搜索方案生成的先驗匹配,最近,Siamese DETR使用從不同視角的對應(yīng)框中提取的查詢特征定位目標(biāo)框。
然而,這些方法要么使用基本的DETR模型(AP=42.1%),要么使用Deformable-DETR變種(AP=45.2%)。當(dāng)在最新的、更強大的DETR模型(如H-Deformable-DETR,AP=49.6%)上進(jìn)行預(yù)訓(xùn)練時,它們的結(jié)果明顯不及預(yù)期,無法在COCO上達(dá)到較好的目標(biāo)檢測性能。(以DETReg為例,在圖1c中,所有結(jié)果都是使用SwAV初始化的ResNet50 Backbone網(wǎng)獲得)

在這項工作中,作者首先仔細(xì)研究了以DETReg為代表的自監(jiān)督預(yù)訓(xùn)練方法對COCO目標(biāo)檢測基準(zhǔn)上不斷增強的DETR架構(gòu)的改進(jìn)程度。作者的調(diào)查揭示了DETReg在應(yīng)用于通過SwAV預(yù)訓(xùn)練的Backbone網(wǎng)絡(luò)、Deformable-DETR中的可變形技術(shù)以及H-Deformable-DETR中固有的混合匹配方案等功能強大的DETR網(wǎng)絡(luò)上時效果的顯著局限性(見圖1c)。
作者將問題的關(guān)鍵點確定為由無監(jiān)督方法(如選擇性搜索)生成的不可靠的proposals框,這導(dǎo)致生成了噪聲預(yù)訓(xùn)練目標(biāo),并且通過特征重建引入了弱語義信息,進(jìn)一步惡化了問題。這些缺點使得無監(jiān)督預(yù)訓(xùn)練方法在應(yīng)用于已經(jīng)強大的DETR模型時變得無效。
為了解決這個問題,作者提出使用COCO目標(biāo)檢測器來獲得更準(zhǔn)確的偽框,并使用信息豐富的偽類別標(biāo)簽。通過廣泛的消融實驗,作者強調(diào)了3個關(guān)鍵因素的影響:
-
預(yù)訓(xùn)練數(shù)據(jù)集的選擇(ImageNet與Objects365) -
定位預(yù)訓(xùn)練目標(biāo)的選擇(選擇性搜索提案與偽框預(yù)測) -
分類預(yù)訓(xùn)練目標(biāo)的選擇(對象嵌入損失與偽類別預(yù)測)
這些因素對改進(jìn)方法的效果產(chǎn)生了重要影響。作者的研究結(jié)果表明,在各種情況下,一個簡單的自訓(xùn)練方案,使用偽框和偽類別預(yù)測作為預(yù)訓(xùn)練目標(biāo),優(yōu)于DETReg方法。值得注意的是,即使在沒有訪問預(yù)訓(xùn)練基準(zhǔn)的真實標(biāo)簽的情況下,這種簡單的設(shè)計也能顯著提升最先進(jìn)的DETR網(wǎng)絡(luò)的預(yù)訓(xùn)練效果。
例如,使用ResNet50 Backbone網(wǎng)絡(luò)和Objects365預(yù)訓(xùn)練數(shù)據(jù)集,簡單的自訓(xùn)練將H-Deformable-DETR上DETReg的COCO目標(biāo)檢測結(jié)果提高了3.6%。此外,作者還觀察到了Swin-L Backbone網(wǎng)絡(luò)的出色性能,取得了59.3%。
2、本文方法
2.1 DETR預(yù)訓(xùn)練方案
傳統(tǒng)的DETR由兩個網(wǎng)絡(luò)模塊組成(圖2),包括提取通用圖像特征的Backbone網(wǎng)絡(luò)和獲取檢測特定特征以及預(yù)測目標(biāo)位置和類別的Transformer。Transformer進(jìn)一步由編碼器和解碼器模塊組成,這些模塊由多個線性神經(jīng)網(wǎng)絡(luò)層構(gòu)建而成。編碼器應(yīng)用自注意力機制來提取更好的圖像特征,而解碼器查詢編碼器的特征并預(yù)測所需的信息作為任務(wù)目標(biāo)。
現(xiàn)有的自監(jiān)督方法針對預(yù)訓(xùn)練Transformer組件采用了與圖2中所示相似的預(yù)訓(xùn)練方案。它們選擇ImageNet作為大規(guī)模預(yù)訓(xùn)練基準(zhǔn),并且僅訪問輸入圖像來建立自監(jiān)督模式。精心設(shè)計的預(yù)訓(xùn)練任務(wù)通常包括定位任務(wù),用于預(yù)測無監(jiān)督的偽框提案,以及特征重構(gòu)任務(wù),以保留Transformer的特征判別能力。
為了保護Backbone網(wǎng)絡(luò)的通用特征提取能力,使其不受預(yù)訓(xùn)練任務(wù)的損害,它們凍結(jié)了使用普通ImageNet預(yù)訓(xùn)練或更強的自監(jiān)督預(yù)訓(xùn)練(稱為SwAV)初始化的Backbone網(wǎng)絡(luò)權(quán)重。Transformer的編碼器和解碼器在預(yù)訓(xùn)練期間是隨機初始化和更新的。在微調(diào)階段,Backbone網(wǎng)絡(luò)加載未更改的ImageNet預(yù)訓(xùn)練權(quán)重,而Transformer加載更新后的權(quán)重。然后,在目標(biāo)檢測數(shù)據(jù)集的真實標(biāo)簽監(jiān)督下,所有模型權(quán)重一起進(jìn)行調(diào)優(yōu)。其中一個代表性的自監(jiān)督方法是DETReg。
DETReg使用選擇性搜索作為無監(jiān)督方法來創(chuàng)建用于定位預(yù)訓(xùn)練的框提案。選擇性搜索在不知道對象的語義類別的情況下,生成可能對象周圍的框。為了彌補缺乏類別信息,它還學(xué)習(xí)重構(gòu)框的特征(也稱為對象特征),這些特征是從裁剪后的輸入圖像中提取的,并使用固定的SwAVBackbone網(wǎng)絡(luò)。通過這種方式,DETReg使得檢測器能夠同時對其位置和分類能力進(jìn)行預(yù)訓(xùn)練,使用3個預(yù)測頭部分別預(yù)測框的位置、指示框內(nèi)是否存在目標(biāo)的二進(jìn)制類別以及相關(guān)的目標(biāo)特征。
2.2 簡單自訓(xùn)練
在這項工作中,作者發(fā)現(xiàn)自監(jiān)督預(yù)訓(xùn)練方法只能為下游任務(wù)帶來輕微的改進(jìn),特別是當(dāng)DETR架構(gòu)的原始準(zhǔn)確性較高時。
例如,在圖1c的DeformableDETR架構(gòu)上,DETReg預(yù)訓(xùn)練方法提高了0.3,但在更強的H-Deformable-DETR架構(gòu)上降低了0.1的性能。
作者提出了一個簡單的自訓(xùn)練方案,不僅可以緩解這個問題,還可以使預(yù)訓(xùn)練模型在最先進(jìn)的DETR架構(gòu)上有所提升。
其思路是用經(jīng)過訓(xùn)練的目標(biāo)檢測器預(yù)測的更準(zhǔn)確的proposals框替換定位預(yù)訓(xùn)練中的低質(zhì)量無監(jiān)督proposals框。雖然特征重構(gòu)對于分類預(yù)訓(xùn)練有助于防止網(wǎng)絡(luò)判別能力的退化,但作者通過將其替換為由訓(xùn)練的檢測器預(yù)測的偽類標(biāo)簽來進(jìn)一步增強容量。
這種修改引入了語義信息到預(yù)訓(xùn)練中。盡管簡單的自訓(xùn)練并不屬于自監(jiān)督方法,但它僅訪問預(yù)訓(xùn)練數(shù)據(jù)集的圖像,而由訓(xùn)練的檢測器引入的監(jiān)督是來自下游任務(wù)數(shù)據(jù)集,作者假設(shè)該數(shù)據(jù)集已經(jīng)可用。
與傳統(tǒng)的自訓(xùn)練方案不同,傳統(tǒng)方案依賴于采用復(fù)雜的數(shù)據(jù)增強策略來提高偽標(biāo)簽的質(zhì)量,并且需要仔細(xì)調(diào)整非極大值抑制(NMS)閾值,并迭代地基于微調(diào)模型生成更準(zhǔn)確的偽標(biāo)簽。
相比之下,作者的方法直接一次性生成偽標(biāo)簽,無需使用這些技巧,偽標(biāo)簽只包含了一定數(shù)量的最可信的預(yù)測結(jié)果,因此被稱為簡單自訓(xùn)練。
為了生成偽標(biāo)簽,作者首先在COCO數(shù)據(jù)集上訓(xùn)練一個目標(biāo)檢測模型,然后使用該模型在預(yù)訓(xùn)練基準(zhǔn)數(shù)據(jù)集(如ImageNet)上進(jìn)行偽邊界框和偽類標(biāo)簽的預(yù)測。然后,使用帶有偽標(biāo)簽的基準(zhǔn)數(shù)據(jù)集對所選的基于DETR的網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練。
在這項工作中,作者旨在研究代表性的自監(jiān)督方法DETReg和作者的簡單自訓(xùn)練方法中兩個關(guān)鍵組件的影響:定位預(yù)訓(xùn)練目標(biāo)的選擇和分類預(yù)訓(xùn)練目標(biāo)的選擇。此外,在割離研究中,作者強調(diào)了預(yù)訓(xùn)練基準(zhǔn)選擇對預(yù)訓(xùn)練性能的重要性。
2.3 定位預(yù)訓(xùn)練目標(biāo)
在自監(jiān)督的預(yù)訓(xùn)練方法中使用了幾種unsupervised box proposal algorithms,例如UP-DETR中的隨機塊、DETReg中的選擇性搜索和Siamese DETR中的EdgeBoxes。關(guān)于定位預(yù)訓(xùn)練目標(biāo),作者的討論將圍繞DETReg使用的選擇性搜索框(圖4a)和簡單自訓(xùn)練中使用的經(jīng)過訓(xùn)練的目標(biāo)檢測器生成的偽邊界框預(yù)測(圖4c)展開。
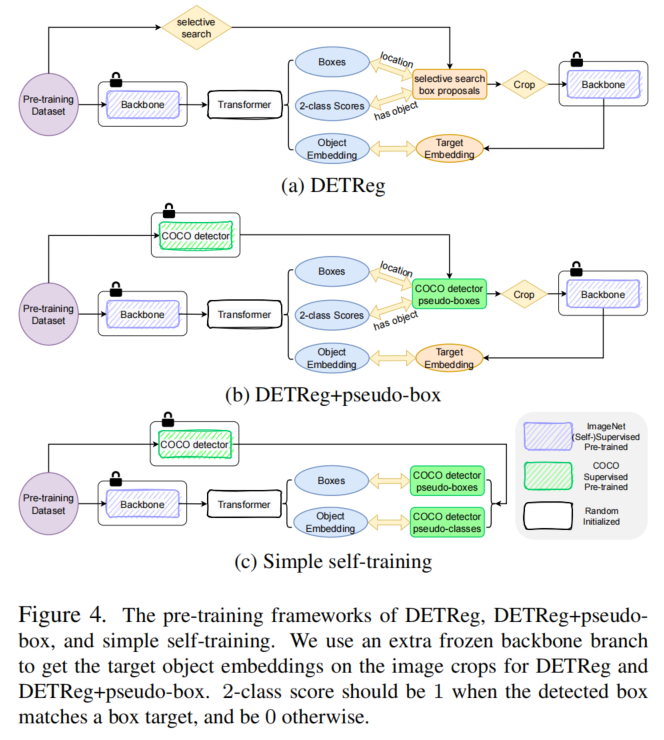
1、選擇性搜索框
在深度學(xué)習(xí)領(lǐng)域,選擇性搜索是在深度學(xué)習(xí)時代之前最具影響力的區(qū)域提議生成方法之一,其在召回率方面表現(xiàn)出色。選擇性搜索的靈感來自于圖像本身具有的層次性,它采用了一種分層分組算法作為基礎(chǔ),通過使用FH算法生成初始區(qū)域,并利用貪婪算法根據(jù)顏色、紋理、大小和形狀的相似性迭代地將區(qū)域組合成更大的區(qū)域。最終生成的區(qū)域形成了一組候選對象提議,每個提議對應(yīng)于圖像中可能包含感興趣對象的區(qū)域。
與DETReg方法類似,作者將保留置信度最高的約30個proposals框作為基于選擇性搜索的定位預(yù)訓(xùn)練目標(biāo)。
2、偽邊界框預(yù)測
對于偽邊界框預(yù)測方案,作者直接選擇了幾個現(xiàn)成的經(jīng)過良好訓(xùn)練的COCO目標(biāo)檢測器來預(yù)測用于預(yù)訓(xùn)練基準(zhǔn)的偽邊界框。
具體而言,作者選擇了一種名為H-Deformable-DETR的強大的基于DETR的網(wǎng)絡(luò)作為作者的目標(biāo)檢測器,并選擇了兩種不同的Backbone網(wǎng)絡(luò),包括ResNet50和Swin-L。這兩個檢測器在COCO數(shù)據(jù)集上具有顯著的檢測性能差異,這是由于它們的Backbone網(wǎng)絡(luò)能力和訓(xùn)練時長不同:
-
H-Deformable-DETR + ResNet50訓(xùn)練12個epoch(AP=48.7%)
-
H-Deformable-DETR + Swin-L訓(xùn)練36個epoch(AP=57.8%)
然后,通過對預(yù)訓(xùn)練基準(zhǔn)進(jìn)行推理,作者得到了偽邊界框的預(yù)測結(jié)果,并保留置信度最高的約30個邊界框預(yù)測。
3、討論
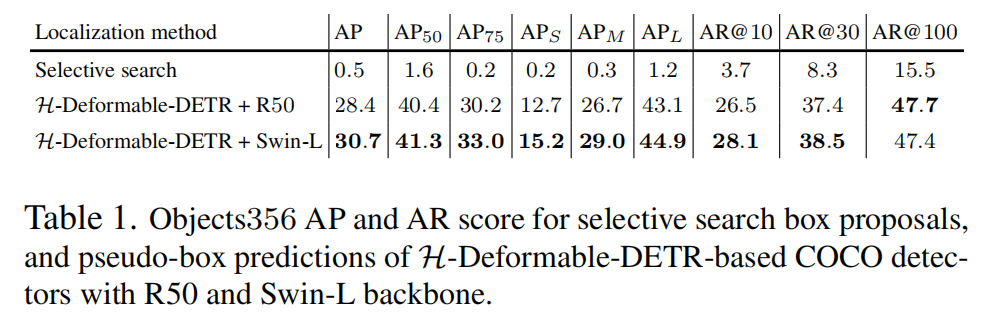
表格1比較了各種proposals框方法在預(yù)訓(xùn)練基準(zhǔn)數(shù)據(jù)集Objects365上的邊界框質(zhì)量,作者報告了類別無關(guān)的精確度和召回率。可以看出,H-Deformable-DETR預(yù)測的偽邊界框比無監(jiān)督的選擇性搜索方法更準(zhǔn)確。
為了了解質(zhì)量差異,作者在圖3中可視化了Objects365上兩個檢測器的真實邊界框、選擇性搜索邊界框和偽邊界框預(yù)測結(jié)果。

2.4 預(yù)訓(xùn)練目標(biāo)分類
作者討論了兩種生成分類預(yù)訓(xùn)練目標(biāo)的方法,其中包括特征重建方法(由DETReg的目標(biāo)嵌入損失代表,圖4a)和簡單自訓(xùn)練中使用的偽類別預(yù)測(圖4c)。
1、對象嵌入損失
為了將每個邊界框與明確的語義類別意義相關(guān)聯(lián),DETReg在解碼器中的每個查詢嵌入上應(yīng)用了一個目標(biāo)嵌入頭,以回歸一個目標(biāo)嵌入,其中包含了與相關(guān)邊界框內(nèi)的語義意義編碼相關(guān)的信息。DETReg通過將使用SwAV預(yù)訓(xùn)練的Backbone網(wǎng)絡(luò)的圖像區(qū)域(由proposals框進(jìn)行裁剪)饋送到其中來獲得目標(biāo)嵌入,如圖4a所示。
然后,它計算預(yù)測的對象嵌入與相應(yīng)目標(biāo)嵌入之間的L1損失作為目標(biāo)嵌入損失。在DETReg中,用于提取目標(biāo)嵌入的Backbone網(wǎng)絡(luò)以及基于DETReg的主要網(wǎng)絡(luò)中的Backbone網(wǎng)絡(luò)是固定的,只有Transformer編碼器、解碼器和預(yù)測頭在預(yù)訓(xùn)練期間進(jìn)行更新。
2、偽類別預(yù)測
作者還可以利用前述COCO目標(biāo)檢測器的類別預(yù)測作為每個邊界框目標(biāo)對應(yīng)的分類目標(biāo),其中包含更精細(xì)和更豐富的語義信息。
由于檢測器是在COCO上訓(xùn)練的,它所預(yù)測的偽類別標(biāo)簽就是COCO的80個類別。作為預(yù)訓(xùn)練基準(zhǔn)類別的子集,它可以幫助實現(xiàn)高效的預(yù)訓(xùn)練效果。由于COCO偽類別還包含了下游基準(zhǔn)(COCO和PASCAL VOC)的類別,它縮小了預(yù)訓(xùn)練和下游任務(wù)之間的差距。
由于每個偽類別預(yù)測都被分配給了目標(biāo)檢測器中的一個偽邊界框,作者無法將其與選擇性搜索定位目標(biāo)一起使用。圖4展示了剩余3種定位和分類預(yù)訓(xùn)練目標(biāo)的研究結(jié)果,它們分別是原始的DETReg方法、通過COCO檢測器的偽邊界框增強的DETReg方法,以及簡單的自訓(xùn)練方法。
3、實驗
3.1 Comparison to the State-of-the-art
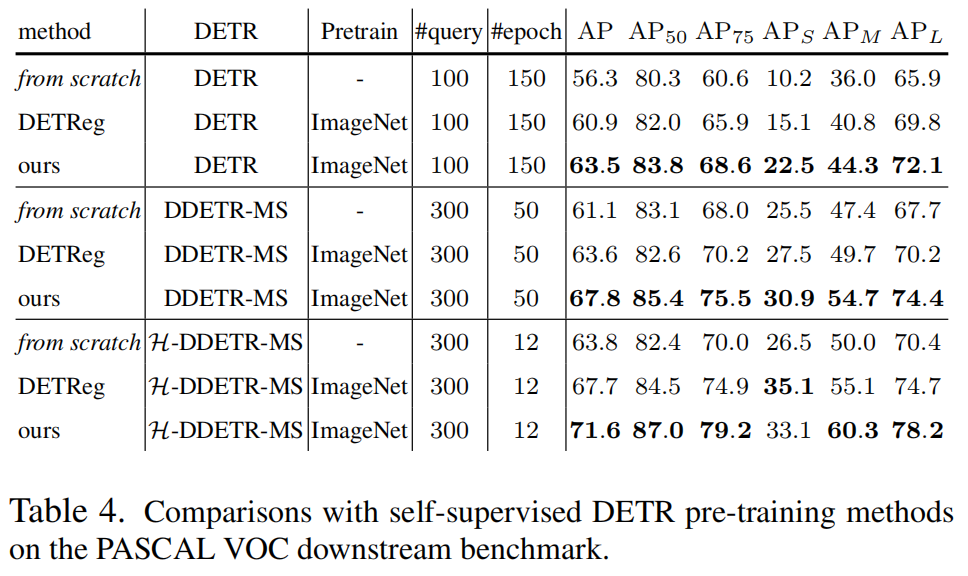
3.2 不同的DETR結(jié)構(gòu)的研究結(jié)果

3.3 消融實驗
3.3.1 預(yù)訓(xùn)練數(shù)據(jù)集的選擇
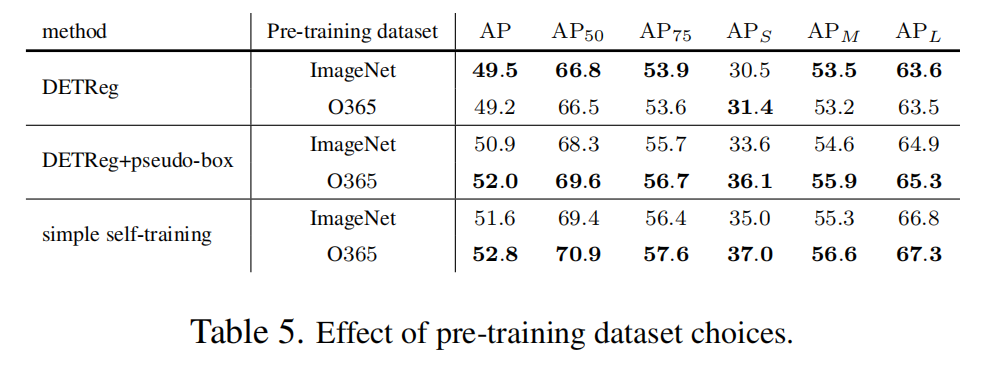
3.3.2 預(yù)訓(xùn)練方法
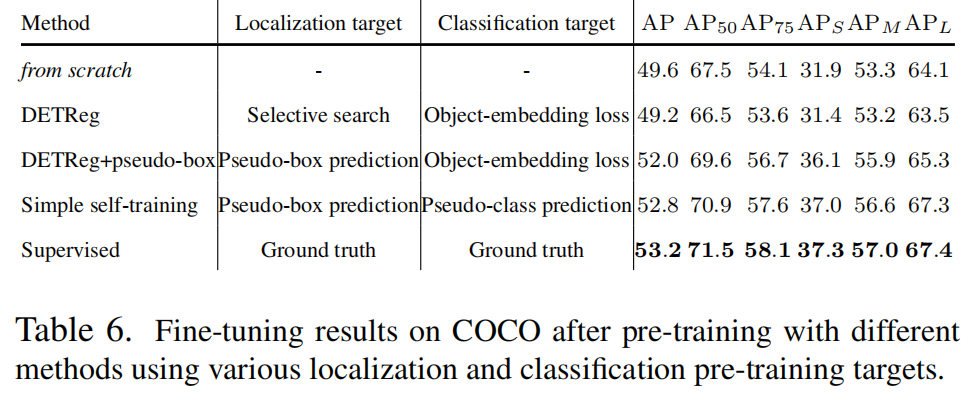
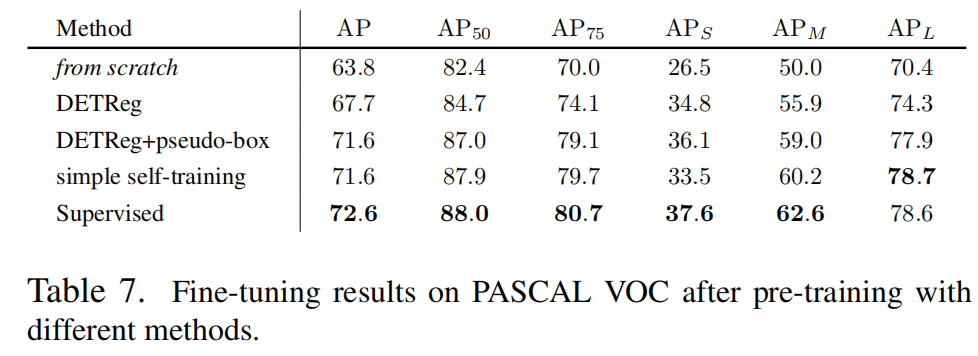
3.3.3 pseudo-box數(shù)量

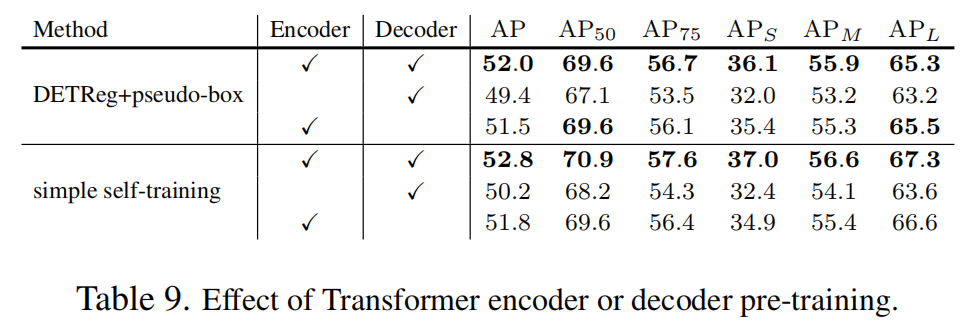
3.3.4 編碼器和解碼器預(yù)訓(xùn)練
3.3.5 Fine-tuning數(shù)據(jù)集大小
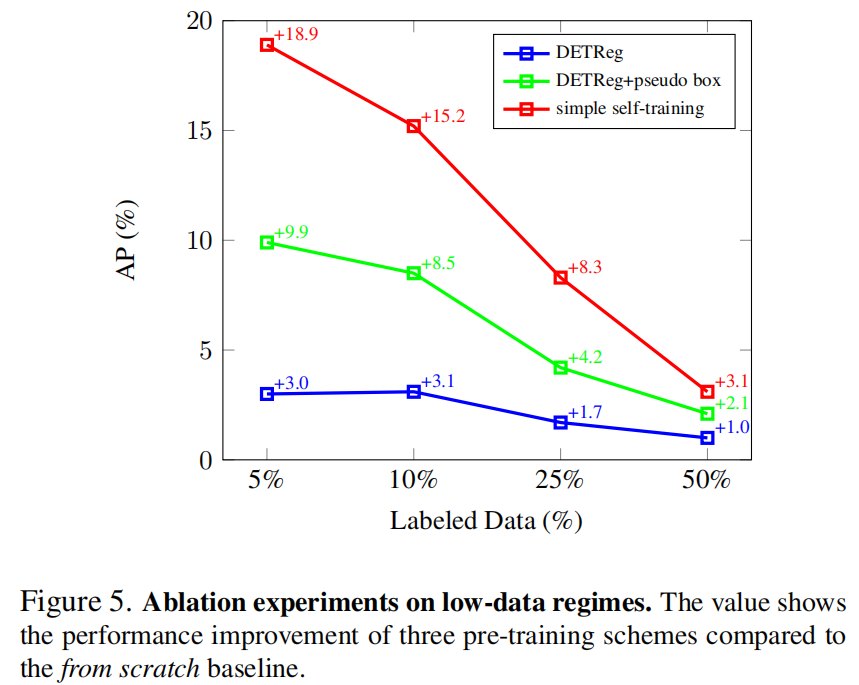
3.3.6 定性分析


3.4 通過T2I生成的合成數(shù)據(jù)的結(jié)果

4、參考
[1].Revisiting DETR Pre-training for Object Detection.
5、推薦閱讀
訓(xùn)練Backbone你還用EMA?ViT訓(xùn)練的大殺器EWA升級來襲
ADAS落地 | 自動駕駛的硬件加速
Fast-BEV的CUDA落地 | 5.9ms即可實現(xiàn)環(huán)視BEV 3D檢測落地!代碼開源
掃碼加入??「集智書童」交流群
(備注:方向+學(xué)校/公司+昵稱)




前沿AI視覺感知全棧知識??「分類、檢測、分割、關(guān)鍵點、車道線檢測、3D視覺(分割、檢測)、多模態(tài)、目標(biāo)跟蹤、NerF」
歡迎掃描上方二維碼,加入「集智書童-知識星球」,日常分享論文、學(xué)習(xí)筆記、問題解決方案、部署方案以及全棧式答疑,期待交流!