
DETR:基于 Transformers 的目標(biāo)檢測
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
編輯:我是小將
前言
最近可以說是隨著 ViT 的大火,幾乎可以說是一天就能看到一篇基于 Transformers 的 CV 論文,今天給大家介紹的是另一篇由Facebook 在 ECCV2020 上發(fā)表的一篇基于 Transformers 的目標(biāo)檢測論文,這篇論文也是后續(xù)相當(dāng)多的 Transformers 檢測/分割的 baseline,透過這篇論文我們來了解其套路.
相關(guān)工作
提到目標(biāo)檢測,我們先來簡要回顧一下最基礎(chǔ)的一個(gè)工作 Faster R-CNN
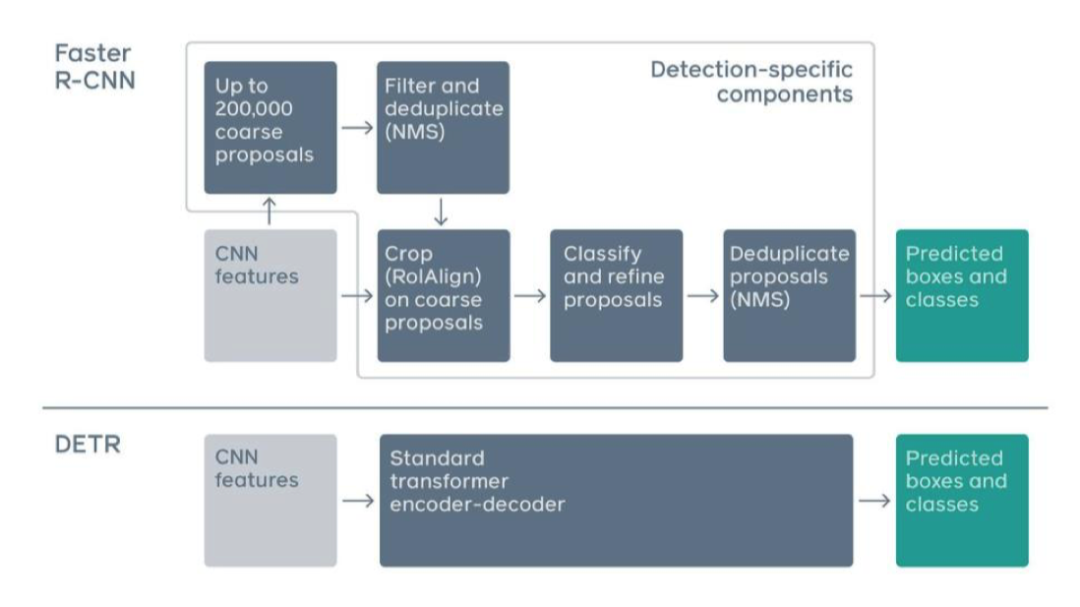
Faster R-CNN第一步是用 CNN 給圖像提特征,再通過非極大值抑制算法提取出候選框,最后預(yù)測每個(gè)候選框的位置和類別,
DETR 的實(shí)現(xiàn)原理
DETR 這篇文章就極大的簡化了這個(gè)過程,他把候選框提取的過程通過一個(gè)標(biāo)準(zhǔn)的 Transformers encoder-decoder 架構(gòu)代替,在 decoder 部分直接預(yù)測出來物體的位置和類別.
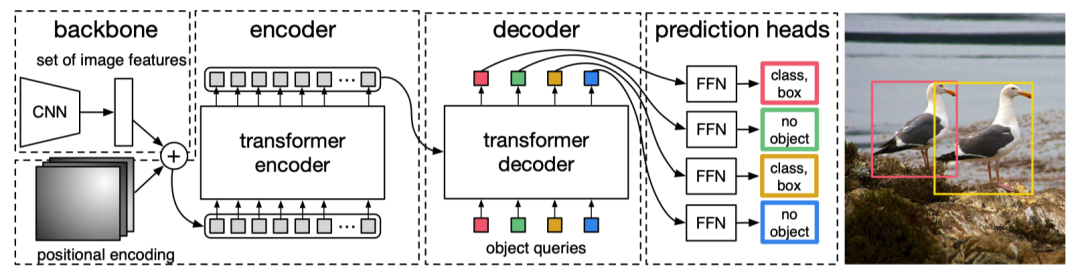
流程分為三步:
CNN 提特征 Transformers 的 encoder-decoder進(jìn)行信息的融合 FFN 預(yù)測 class 和 box
CNN
利用resnet-50網(wǎng)絡(luò),將輸入的圖像 變成尺度為 的特征,再通過一個(gè) 1X1 卷積,將 channel 從 2048 變?yōu)楦?通常 512)
Transformers encoder-decoder
Transformer encoder部分首先將輸入的特征圖降維并flatten 成 d 個(gè) HXW 維的向量,每個(gè)向量作為輸入的 token,由于Self-attention 是置換不變形的,所以為了體現(xiàn)每個(gè) token 在原圖中的順序關(guān)系,我們給每個(gè) token 加上一個(gè) positional encodings.輸出這是對(duì)應(yīng)Decoder 部分的 V 和 K.
比如說我們一開始輸入的圖片是 512*512,那么d 應(yīng)該是256.
Transformers decoder 部分是輸入是 100 個(gè) Object queries,比如說我們數(shù)據(jù)集總共有100個(gè)類別的物體需要預(yù)測,那么這 100 object queries 經(jīng)過Transformers decoder 之后會(huì)預(yù)測出若干類別的物體和位置信息.
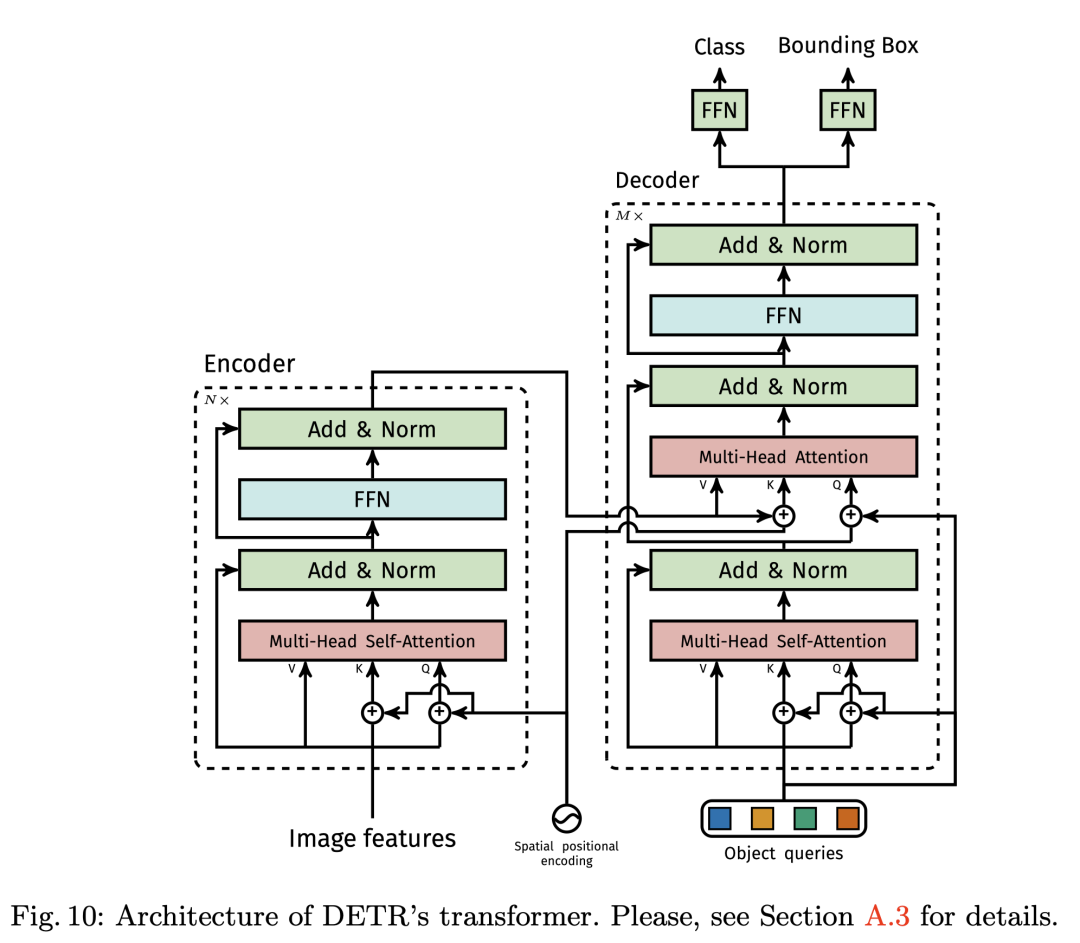
作者發(fā)現(xiàn)在訓(xùn)練過程中在decoder 中使用auxiliary losses很有幫助,特別是有助于模型輸出正確數(shù)量的每個(gè)類的對(duì)象。
FFN
DETR在每個(gè)解碼器層之后添加預(yù)測FFN和Hungarian loss,所有預(yù)測FFN共享其參數(shù)。我們使用附加的共享層范數(shù)來標(biāo)準(zhǔn)化來自不同解碼器層的預(yù)測FFN的輸入,FFN 是一個(gè)最簡單的多層感知機(jī)模塊,對(duì) Transformers decoder 的輸出預(yù)測每個(gè) object query的類別和位置信息.在實(shí)際訓(xùn)練的過程中,通過匈牙利算法匹配預(yù)測和標(biāo)簽最小的損失,僅適用配對(duì)上的query 計(jì)算 loss回傳梯度.
loss 包括 Box loss 和 class loss
Box Loss 包括 IOUloss 和 L1loss,這個(gè)原理很簡單.
where are hyperparameters and is the generalized IoU [38]:
class loss就是最簡單的交叉熵了.
匈牙利匹配
匈牙利匹配算法是離散數(shù)學(xué)中圖論部分的一個(gè)經(jīng)典算法,描述的問題是一個(gè)二分圖的最大匹配.換成人話來說就是這個(gè)二分圖分成兩部分,一部分是我們對(duì) 100 種 object query 預(yù)測的結(jié)果,另一部分是實(shí)際的標(biāo)簽,由于我們一開始是不知道這100 個(gè) object query 輸入的時(shí)候應(yīng)該預(yù)測那些類別的物體,有可能一開始第一個(gè) token 預(yù)測的是 A 物體,第二個(gè) token 預(yù)測的是 C 物體,總而言之是無序的,我們就要根據(jù)實(shí)際的 label,找到預(yù)測結(jié)果中和他最接近的計(jì)算 loss.其他沒匹配上的則不計(jì)算 loss回傳梯度.下面這張圖一目了然:

通過對(duì)比 ViT 思考 DETR
其實(shí)筆者在閱讀這篇文章的時(shí)候更加重點(diǎn)的是對(duì)比 ViT 在一些實(shí)現(xiàn)細(xì)節(jié)上的不同之處,
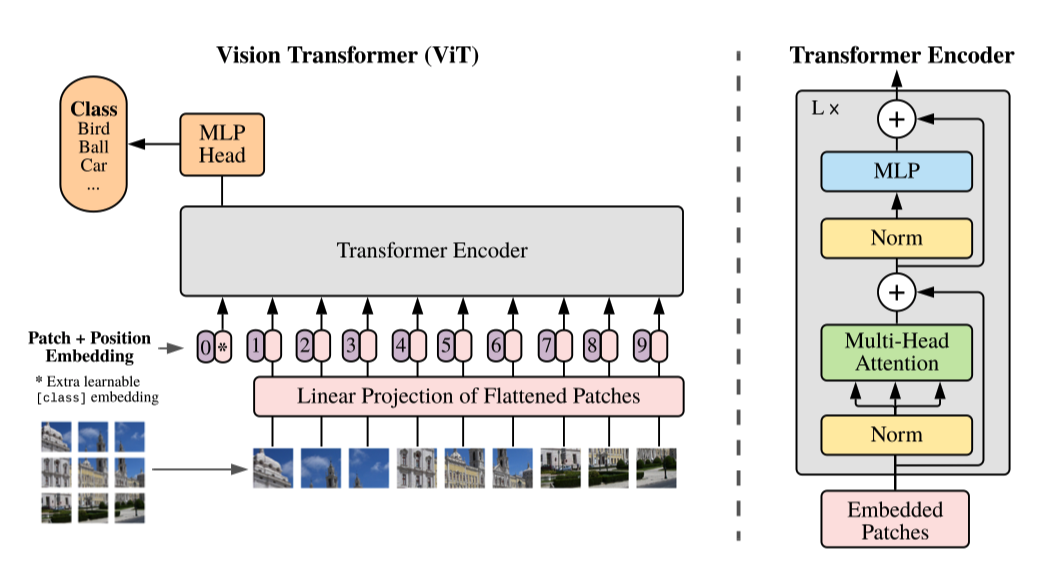
首先 ViT 是沒有使用 CNN 的,而 DETR 是先用 CNN 提取了圖像的特征 ViT 只使用了Transformers-encoder,在 encoder 的時(shí)候額外添加了一個(gè) Class token 來預(yù)測圖像類型,而 DETR 的 object token 則是通過 Decoder 學(xué)習(xí)的. DETR 和 VIT 中的Transformers 在 encoder 部分都使用了Position Embedding,但是使用的并不一樣,而 VIT 在使用的 Position Embedding 也是筆者一開始閱讀文獻(xiàn)的疑惑所在. DETR 的 Transformers encoder使用的feature 的每一個(gè)pixel作為token embeddings輸入,而ViT 則是直接把圖像切成 16*16 個(gè) Patch,每個(gè) patch 直接拉平作為token embeddings 相比較 VIT,DETR 更接近原始的 Transformers 架構(gòu).
DETR 還能做分割
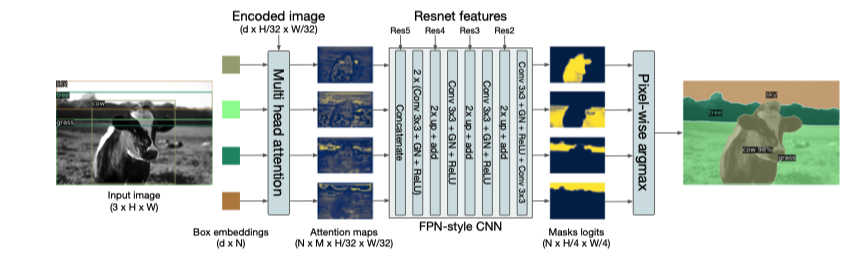
首先檢測 box 對(duì)每個(gè) box 做分割 為每個(gè)像素的類別投票
作者在這篇論文在并沒有詳細(xì)講實(shí)現(xiàn)細(xì)節(jié),但是今年 CVPR2021 上發(fā)表的 SETR 則是重點(diǎn)講如何利用 Transformers 做分割,我們下次細(xì)講.
實(shí)驗(yàn)結(jié)果分析
Comparison Study
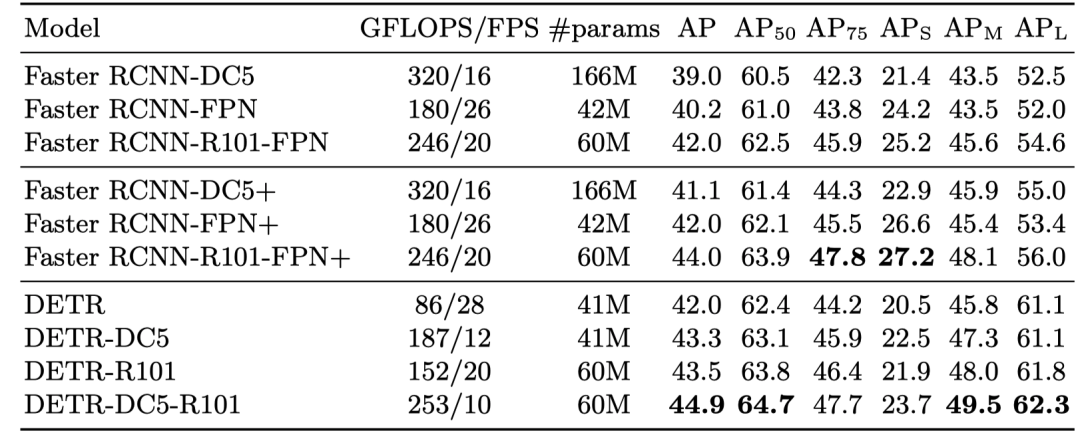
對(duì)比的是檢測領(lǐng)域最經(jīng)典的 Faster R-CNN,可以看得出來了在同等參數(shù)兩的情況下,在大目標(biāo)物體的檢測結(jié)果優(yōu)于 Faster R-CNN,道理嘛作者說是 Transformers 可以更關(guān)注全局信息.
Ablation Study

Decoder 比 Encoder 重要 Decoder具有隱含的“錨”,這對(duì)檢測至關(guān)重要 Encoder僅幫助聚合同一對(duì)象的像素,減輕decoder 的負(fù)擔(dān)
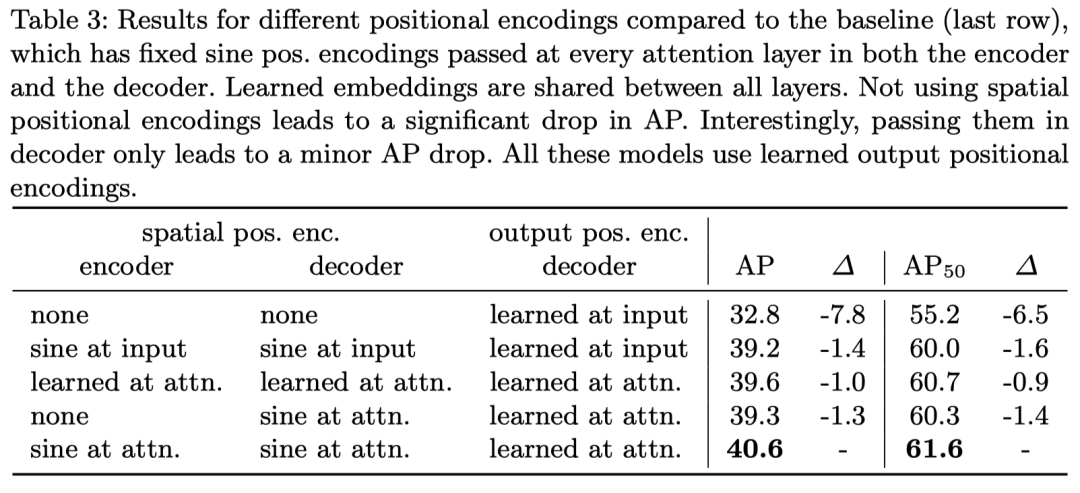
在位置編碼部分,作者對(duì)比了可學(xué)習(xí)的位置編碼和基于 Sincos 函數(shù)的位置編碼方法(也就是原始 Transformers 的位置編碼方法)可以看得出來效果是 Sincos 的更好,但是都顯著好于不加位置編碼,因?yàn)樽髡咭苍谠闹蠸elf-Attention 是并行的,他如果不加位置編碼的話是置換不變性的(這個(gè)看 Attention is All you Need 原文)
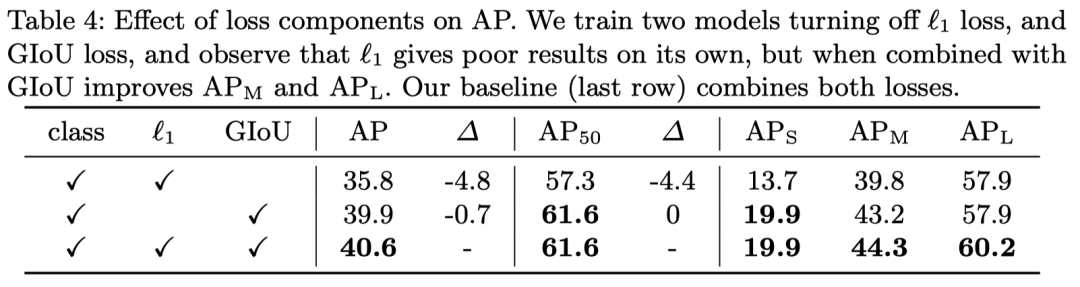
這個(gè)嘛,就是很簡單的實(shí)驗(yàn)了,驗(yàn)證一下 loss 每個(gè)部分的作用,基本上就是格式化的東西.
簡易代碼
作者最后在附錄部分貼上了簡易的代碼實(shí)現(xiàn)細(xì)節(jié)
import torch
from torch
import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone=nn.Sequential(
*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers,
num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos =nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs) h = self.conv(x)
H,W=h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ],
dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos +
h.flatten(2).permute(2, 0,1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
結(jié)論
一篇很簡單的 Transformers 在目標(biāo)檢測上的應(yīng)用,也是最近大火的 Transformers 系列必引的一篇論文,我覺得他和 VIT 代表了 CV 對(duì) Transformers 架構(gòu)的兩種看法吧,VIT 是只用 Encoder,這也是目前最主流的做法,而 DETR 則是運(yùn)用了 CNN 和 Transformers encoder-decoder 的結(jié)合,從 motivation 上來說我個(gè)人更喜歡 DETR,這段時(shí)間也基本上把 Transformers 一系列都讀完了,會(huì)以一個(gè)系列調(diào)幾篇好的論文講解(水文實(shí)在是太多了)。
推薦閱讀
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
"未來"的經(jīng)典之作ViT:transformer is all you need!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
SWA:讓你的目標(biāo)檢測模型無痛漲點(diǎn)1% AP
CondInst:性能和速度均超越Mask RCNN的實(shí)例分割模型
mmdetection最小復(fù)刻版(十一):概率Anchor分配機(jī)制PAA深入分析
MMDetection新版本V2.7發(fā)布,支持DETR,還有YOLOV4在路上!
無需tricks,知識(shí)蒸餾提升ResNet50在ImageNet上準(zhǔn)確度至80%+
不妨試試MoCo,來替換ImageNet上pretrain模型!
mmdetection最小復(fù)刻版(七):anchor-base和anchor-free差異分析
mmdetection最小復(fù)刻版(四):獨(dú)家yolo轉(zhuǎn)化內(nèi)幕
機(jī)器學(xué)習(xí)算法工程師
一個(gè)用心的公眾號(hào)
