
DETR目標(biāo)檢測新范式帶來的思考
2020年,Transformer在計(jì)算機(jī)視覺領(lǐng)域大放異彩。Detection Transformer (DETR) [1]就是Transformer在目標(biāo)檢測領(lǐng)域的成功應(yīng)用。利用Transformer中attention機(jī)制能夠有效建模圖像中的長程關(guān)系(long range dependency),簡化目標(biāo)檢測的pipeline,構(gòu)建端到端的目標(biāo)檢測器。然而DETR在目標(biāo)檢測領(lǐng)域帶來的革新遠(yuǎn)遠(yuǎn)不止這些。本文首先對(duì)DETR原文進(jìn)行介紹,隨后總結(jié)DETR這一新范式在目標(biāo)檢測等領(lǐng)域帶來的變革與思考。熟悉DETR的小伙伴可以直接跳到第二部分。
目錄
一、DETR簡介
二、DETR在目標(biāo)檢測領(lǐng)域帶來的新思考
如何有效利用transformer解決圖像中的目標(biāo)檢測問題 Sparse的目標(biāo)檢測方法 新的label assignment機(jī)制 如何構(gòu)建end-to-end的目標(biāo)檢測器 如何更好地將DETR拓展到實(shí)例分割任務(wù)
一、DETR簡介

DETR將目標(biāo)檢測看作一種set prediction問題,并提出了一個(gè)十分簡潔的目標(biāo)檢測pipeline,即CNN提取基礎(chǔ)特征,送入Transformer做關(guān)系建模,得到的輸出通過二分圖匹配算法與圖片上的ground truth做匹配。
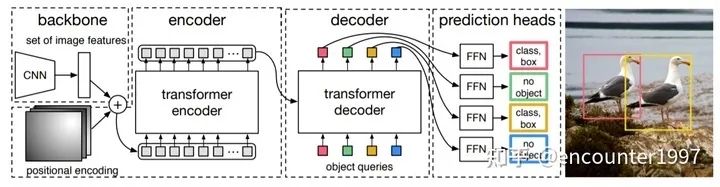
DETR的方法詳情如上圖所示,其關(guān)鍵的設(shè)計(jì)包含:
(1)Transformer
CNN提取的特征拉直(flatten)后加入位置編碼(positional encoding)得到序列特征,作為Transformer encoder的輸入。Transformer中的attention機(jī)制具有全局感受野,能夠?qū)崿F(xiàn)全局上下文的關(guān)系建模,其中encoder和decoder均由多個(gè)encoder、decoder層堆疊而成。每個(gè)encoder層中包含self-attention機(jī)制,每個(gè)decoder中包含self-attention和cross-attention。
(2)object queries
如上圖所示,transformer解碼器中的序列是object queries。每個(gè)query對(duì)應(yīng)圖像中的一個(gè)物體實(shí)例( 包含背景實(shí)例 ),它通過cross-attention從編碼器輸出的序列中對(duì)特定物體實(shí)例的特征做聚合,又通過self-attention建模該物體實(shí)例域其他物體實(shí)例之間的關(guān)系。最終,F(xiàn)FN基于特征聚合后的object queries做分類的檢測框的回歸。
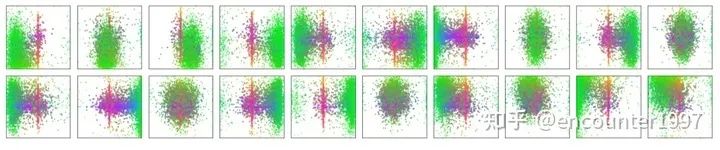
值得一提的是,object queries是可學(xué)習(xí)的embedding,與當(dāng)前輸入圖像的內(nèi)容無關(guān)(不由當(dāng)前圖像內(nèi)容計(jì)算得到)。論文中對(duì)不同object query在COCO數(shù)據(jù)集上輸出檢測框的位置做了統(tǒng)計(jì)(如上圖所示),可以看不同object query是具有一定位置傾向性的。對(duì)object queries的理解可以有多個(gè)角度。首先,它隨機(jī)初始化,并隨著網(wǎng)絡(luò)的訓(xùn)練而更新,因此隱式建模了整個(gè)訓(xùn)練集上的統(tǒng)計(jì)信息。其次,在目標(biāo)檢測中每個(gè)object query可以看作是一種可學(xué)習(xí)的動(dòng)態(tài)anchor,可以發(fā)現(xiàn),不同于Faster RCNN, RetinaNet等方法在特征的每個(gè)像素上構(gòu)建稠密的anchor不同,detr只用少量稀疏的anchor(object queries)做預(yù)測,這也啟發(fā)了后續(xù)的一系列工作[4]。
(3)將目標(biāo)檢測問題看做Set Prediction問題,用二分圖匹配實(shí)現(xiàn)label assignment
DETR中將目標(biāo)檢測問題看做Set Prediction問題,即將圖像中所有感興趣的物體看作是一個(gè)集和,要實(shí)現(xiàn)的目標(biāo)是預(yù)測出這一集和。也就是說在DETR的視角下,目標(biāo)檢測不再是單獨(dú)預(yù)測多個(gè)感興趣的物體,而是從全局上將檢測出所有目標(biāo)所構(gòu)成的整體作為目標(biāo)。對(duì)應(yīng)的,DETR站在全局的視角,用二分圖匹配算法(匈牙利算法)計(jì)算prediction與ground truth之間的最佳匹配,從而實(shí)現(xiàn)label assignment。以上過程中需要定義什么是最佳匹配,也就是對(duì)所有可能的匹配做排序,DETR將一種匹配下模型的總定位和分類損失作為評(píng)判標(biāo)準(zhǔn),損失越低,匹配越佳。注意,該匹配過程是不回傳梯度的。DETR這種從全局的視角來實(shí)現(xiàn)label assignment的范式也啟發(fā)了后續(xù)的一系列工作[5]。
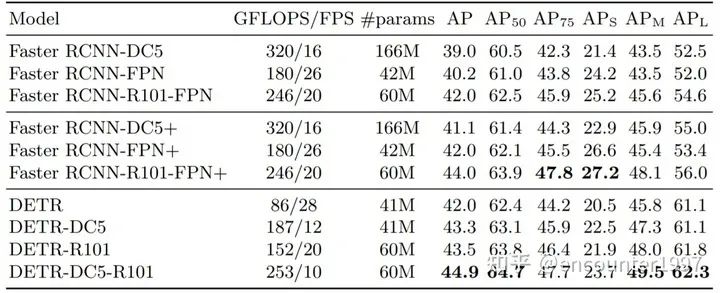
在訓(xùn)練過程中,DETR采用了deep supervision做為輔助損失,即在每個(gè)decoder layer的輸出上都做預(yù)測和監(jiān)督。DETR一般需要更長的訓(xùn)練時(shí)間達(dá)到收斂,例如在coco上需要300-500個(gè)周期收斂到比較好的結(jié)果。在性能上DETR相比于faster rcnn這類檢測器能夠在大物體上實(shí)現(xiàn)更好的檢測,而對(duì)于小物體而言性能較差,具體性能如下表所示。
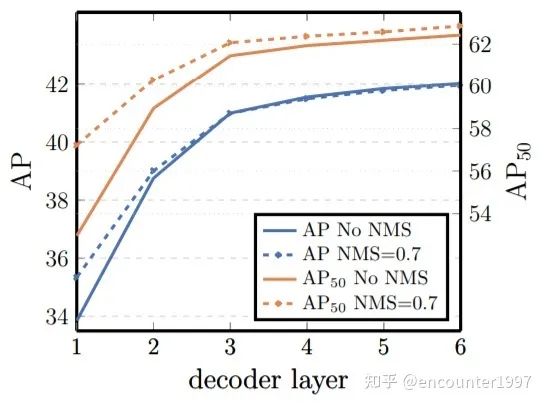
將目標(biāo)檢測看作set prediction問題,使用稀疏的object queries做預(yù)測,并采用二分圖匹配做label assignment,DETR避免了預(yù)測時(shí)產(chǎn)生大量的重復(fù)檢測(duplicates),因此不需要非極大值抑制(NMS)等后處理操作。下圖對(duì)比了DETR中是否采用NMS的對(duì)性能的影響,可以看到到Decoder層數(shù)增加,NMS對(duì)模型性能的積極影響逐漸消失。
(4)拓展到全景分割
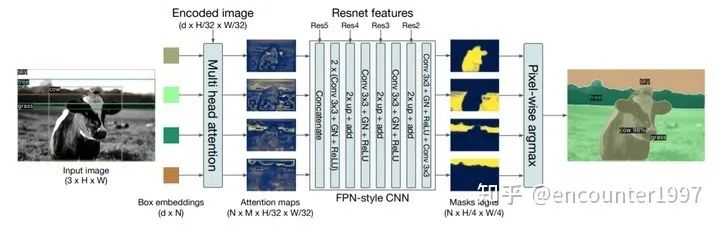
事實(shí)上DETR可以很容易的拓展到全景分割任務(wù)上,類比于Mask RCNN在Faster RCNN基礎(chǔ)上加入mask預(yù)測分支實(shí)現(xiàn)實(shí)例分割。作者在DETR的Prediction Head分支上添加mask分支來實(shí)現(xiàn)全景分割。作者基于object query的attention map做mask分支預(yù)測,并結(jié)合CNN backbone的層級(jí)特征構(gòu)建類似FPN結(jié)構(gòu)的mask預(yù)測分支,如上圖所示。
盡管本文introduction的寫作是從構(gòu)建端到端目標(biāo)檢測器,去除現(xiàn)有目標(biāo)檢測框架中復(fù)雜的手工設(shè)計(jì)這一角度出發(fā)的,但本文的意義遠(yuǎn)不止如此,下面將介紹DETR為目標(biāo)檢測社區(qū)帶來的新思考。
二、DETR在目標(biāo)檢測領(lǐng)域帶來的新思考
1、如何有效利用transformer解決圖像中的目標(biāo)檢測問題
(1)Deformable DETR [2]
Deformable DETR對(duì)DETR的兩處缺陷(收斂速度慢和對(duì)小物體的檢測性能不佳)進(jìn)行分析和改進(jìn),作者指出這兩點(diǎn)缺陷事實(shí)上源自相同的原因:Transformer在處理圖像特征時(shí)存在缺陷。具體來說,在初始化時(shí)transformer中每個(gè)query對(duì)所有位置給予幾乎相同的權(quán)重,這使得網(wǎng)絡(luò)需要經(jīng)過長時(shí)間的訓(xùn)練將attention收斂到特定的區(qū)域。同時(shí),由于transformer中attention機(jī)制隨著圖像中像素?cái)?shù)目的增加呈平方增長,使用大的特征圖輸入encoder的代價(jià)極其高昂。因此,DETR只采用32倍下采樣的特征圖作為輸入,導(dǎo)致其對(duì)小物體的檢測性能不佳。
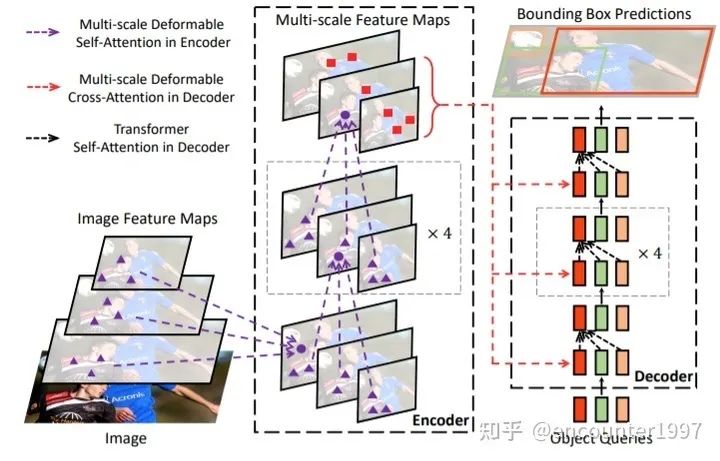
既然模型最終是要關(guān)注到稀疏的注意力區(qū)域,為什么不在一開始就讓模型只關(guān)注稀疏的區(qū)域呢?作者提出Deformable Attention,在attention操作中對(duì)密集的key做稀疏采樣,隨后在query和稀疏的key之間做attention運(yùn)算。由于模型只需要關(guān)注稀疏的采樣點(diǎn),其收斂速度顯著提升。同時(shí),由于每個(gè)query只需要對(duì)稀疏的key做聚合,模型的運(yùn)算量和顯存消耗顯著下降,這使得Deformable Attention能夠在可控的計(jì)算消耗下利用圖像的多尺度特征。由此,得到的模型DeformableDETR如下圖所示。
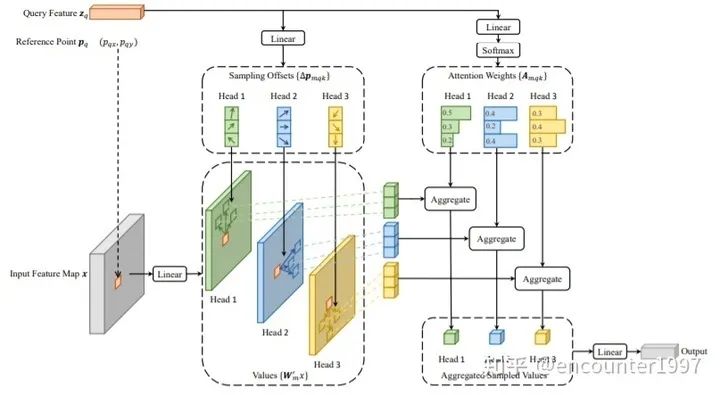
Deformable Attn示意圖如下。值得一提的是,Deformable Attention中attention權(quán)重并非由query和稀疏的key之間做相似性計(jì)算得到的,而是直接由query經(jīng)過projection得到。作者解釋這是因?yàn)椴捎们罢叩姆绞接?jì)算的attention權(quán)重存在退化問題,即最后得到的attention權(quán)重與并沒有隨key的變化而變化。因此,這兩種計(jì)算attention權(quán)重的方式最終得到的結(jié)果相當(dāng),而后者耗時(shí)更短、計(jì)算代價(jià)更小,所以作者選擇直接對(duì)query做projection得到attention權(quán)重。具體的討論請(qǐng)參見 Deformable DETR OpenReview(https://openreview.net/forum?id=gZ9hCDWe6ke¬eId=x1VT5henOtF)
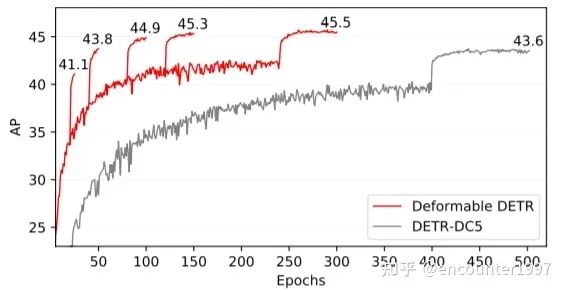
最終,DefomableDETR能夠在以十分之一的迭代次數(shù)得到比DETR更好的性能。
(2)UP-DETR [3]
DETR存在的一個(gè)顯著問題是模型收斂慢,訓(xùn)練周期長,這主要是因?yàn)殡S機(jī)初始化的Transformer需要很長的訓(xùn)練時(shí)間才能收斂。那么我們能否利用無監(jiān)督的預(yù)訓(xùn)練來提升DETR中Transformer的收斂速度呢?為了實(shí)現(xiàn)這一目標(biāo),UP-DETR提出一個(gè)新的pretext task——multi-query localization(如圖所示)來預(yù)訓(xùn)練DETR中的object query,以此來預(yù)訓(xùn)練Transformer的定位能力。同時(shí),作者固定CNN backbone,并利用特征重建損失來保留特征的語義性,從而避免對(duì)定位的預(yù)訓(xùn)練傷害檢測模型的分類能力。
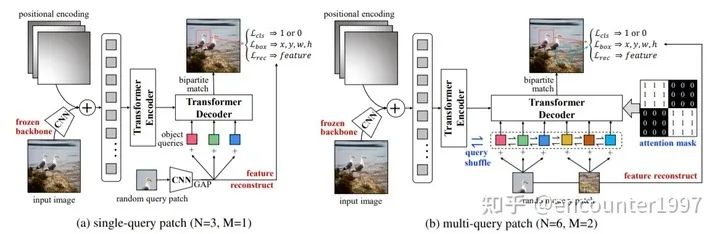
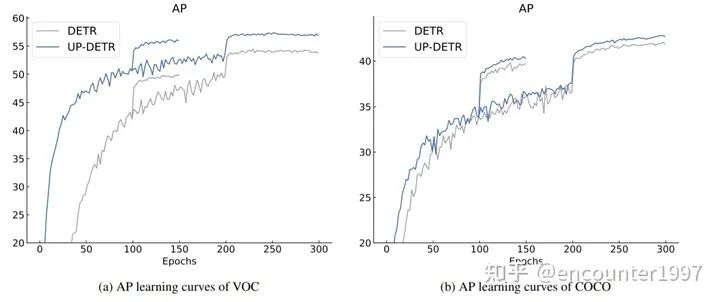
在完成預(yù)訓(xùn)練后,UP-DETR可以在檢測任務(wù)上fine-tune,該fine-tuning過程與DETR原文的訓(xùn)練過程一致。如圖,可以看出經(jīng)過預(yù)訓(xùn)練后,UP-DETR能夠取得比DETR更快的收斂速度以及更由的檢測性能。
更詳細(xì)的介紹請(qǐng)參見原作者的知乎回答:
如何評(píng)價(jià)華南理工和微信AI提出的無監(jiān)督預(yù)訓(xùn)練檢測器UP-DETR?
https://www.zhihu.com/question/432321109/answer/1606004872
2、Sparse的目標(biāo)檢測方法
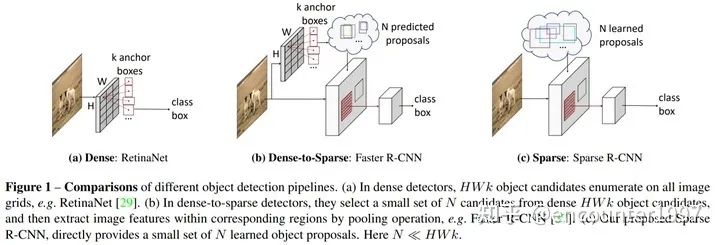
在DETR之前,主流的目標(biāo)檢測算法都依賴于稠密的anchor box或者anchor point。如上圖所示,(a) 一階段檢測器如RetinaNet往往基于稠密的候選框做預(yù)測,(b) 二階段目標(biāo)檢測器如faster rcnn則通過RPN從dense的候選框中篩選出稀疏的候選框,對(duì)比之下,DETR只將少量的(稀疏的)object queries作為目標(biāo)檢測的候選。受到這種sparse檢測候選范式的啟發(fā),Sparse RCNN [4]提出僅用少量的(稀疏的)可學(xué)習(xí)的proposal作為候選框,并基于此提出一種基于RCNN的端到端目標(biāo)檢測方法。
少量可學(xué)習(xí)的proposal反映了圖像中物體位置的統(tǒng)計(jì)信息,然而僅使用4位的位置向量作為proposal無法反映物體的形狀、姿態(tài)等細(xì)粒度的特征。相比之下,DETR中的object queries采用256維的嵌入向量來反映物體的特征,受此啟發(fā),作者在可學(xué)習(xí)的proposal基礎(chǔ)上引入proposal feature來編碼物體的精細(xì)特征,其與proposal數(shù)量相等,并存在一一對(duì)應(yīng)關(guān)系。為了有效利用proposal feature,并為每個(gè)物體實(shí)例學(xué)習(xí)特異性的預(yù)測頭,作者提出dynamic head,如下圖所示。
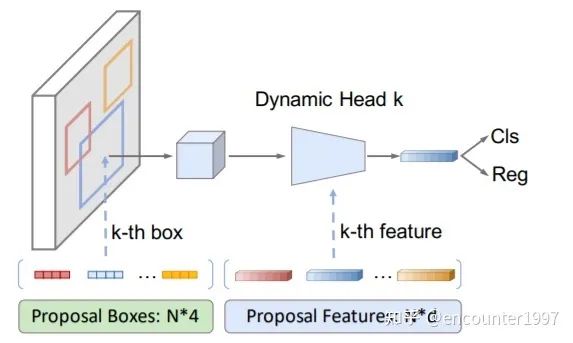
該算法流程的偽代碼如下圖所示,proposal feature經(jīng)過映射后得到1x1卷積核的參數(shù)(動(dòng)態(tài)網(wǎng)絡(luò)),與輸入的物體實(shí)例特征做交互并輸出。

值得一提的是,Sparse RCNN將Sparse這一特性應(yīng)當(dāng)同時(shí)包含(1)稀疏的檢測候選,而不是遍歷特征上的每個(gè)像素位置;(2)檢測候選與圖像特征之間只需要稀疏的交互,而非與圖像特征的每個(gè)像素位置做交互。顯然DETR滿足第一條,而不滿足第二條(Decoder中cross attention從整個(gè)圖像特征序列中聚合信息),從這個(gè)意義上來說,DETR不完全是sparse的,而Deformable DETR和Sparse RCNN則滿足sparse的特性。
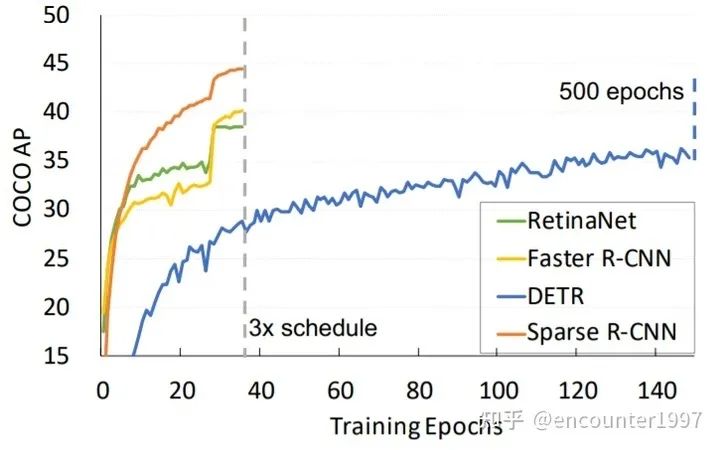
最終,如圖所示,Sparse RCNN能夠在較短的訓(xùn)練周期下到達(dá)比500個(gè)周期訓(xùn)練的DETR更好的實(shí)驗(yàn)結(jié)果,并且性能優(yōu)于Faster RCNN和RetinaNet等經(jīng)典算法。
3、新的label assignment機(jī)制
對(duì)于圖像分類、語義分割等問題,我們很容易建立輸入圖像和標(biāo)簽之之間的關(guān)聯(lián)。例如,對(duì)于分類而言,模型只需要將輸入與Ground Truth類別向量對(duì)應(yīng)起來即可;而對(duì)于語義分割而言,由于模型輸入和Ground Truth分割圖之間存在空間對(duì)應(yīng)關(guān)系,可以很容易的將原圖上的像素與Ground Truth上相同像素位置的標(biāo)簽對(duì)應(yīng)起來。對(duì)比之下,目標(biāo)檢測中輸入圖像和輸出標(biāo)簽之間沒有直接的對(duì)應(yīng)關(guān)系:一張圖片可能包含一個(gè)物體,也可能包含多個(gè)物體;一個(gè)像素可能在零個(gè)/一個(gè)檢測框內(nèi),也可能在多個(gè)檢測框內(nèi)。
在DETR之前,大部分基于目標(biāo)檢測器根據(jù)像素(或anchor)與Ground Truth之間的局部空間位置關(guān)系(如IoU)來實(shí)現(xiàn)標(biāo)簽的分配(也因此造成了很多重復(fù)檢測的存在)。而DETR采用二分圖匹配方式,從全局的視角,在模型輸出與標(biāo)簽之間建立一一對(duì)應(yīng)的關(guān)系。
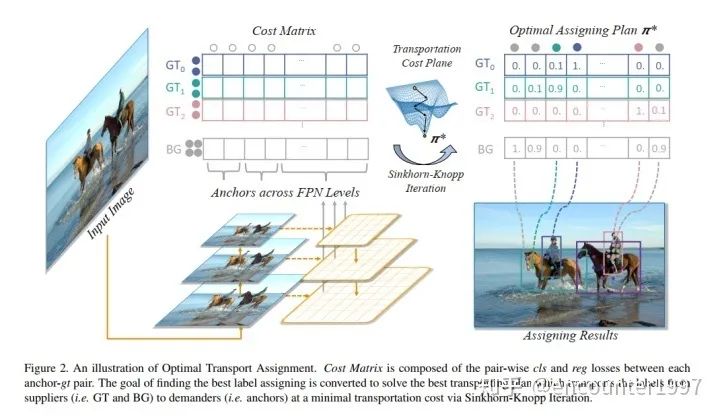
受到這一做法的啟發(fā),OTA(Optimal Transport Assignment)[5] 提出從全局的視角來實(shí)現(xiàn)label assignment。具體來說,它將每個(gè)GT instance看作一個(gè)supplier,將每個(gè)anchor看作一個(gè)demander,利用分類和定位損失計(jì)算一個(gè)supplier到一個(gè)demander的傳輸距離(即將一個(gè)GT分配給一個(gè)特定anchor的損失),隨后利用Sinkhorn-Knopp計(jì)算GT到anchor之間的最優(yōu)傳輸(即最佳的label assignment)。整個(gè)OTA算法流程如下圖所示:

個(gè)人認(rèn)為OTA與DETR中利用二分圖匹配實(shí)現(xiàn)label assignment沒有顯著區(qū)別,不過將GT和anchor分別理解為supplier和demander,并用最優(yōu)傳輸理論來解釋整個(gè)標(biāo)簽分配過程還是讓人覺得耳目一新。
4、如何構(gòu)建end-to-end的目標(biāo)檢測器
DETR基于Transformer提出首個(gè)端到端的目標(biāo)檢測方法,那么很自然的問題就是:(1)基于CNN的目標(biāo)檢測方法能否做到端到端?(2)哪些因素是實(shí)現(xiàn)端到端目標(biāo)檢測的關(guān)鍵?以下三篇文章對(duì)這兩個(gè)問題展開了探討:
OneNet: Towards End-to-End One-Stage Object Detection
https://arxiv.org/abs/2012.05780
End-to-End Object Detection with Fully Convolutional Network
https://arxiv.org/abs/2012.03544
What Makes for End-to-End Object Detection?
https://icml.cc/Conferences/2021/Schedule?showEvent=8868
事實(shí)上,構(gòu)建端到端的目標(biāo)檢測器與label assignment息息相關(guān),這里不做展開介紹,感興趣的小伙伴可以參考論文原文和作者的知乎介紹。
https://zhuanlan.zhihu.com/p/336016003
https://zhuanlan.zhihu.com/p/332281368
5、如何更好地將DETR拓展到實(shí)例分割任務(wù)
DETR論文中效仿Mask RCNN,添加mask分支來實(shí)現(xiàn)全景分割,同樣的方法也可以被運(yùn)用在實(shí)例分割任務(wù)上。然而DETR的mask分支十分復(fù)雜,需要使用復(fù)雜的網(wǎng)絡(luò),并利用類似FPN的結(jié)構(gòu)來融合CNN特征。這主要是由于mask的輸出空間較為復(fù)雜,不同于分類和定位只需要輸出向量來表示類別和回歸值,mask的預(yù)測需要輸出2D的map。
SOLQ [6]在DETR基礎(chǔ)上提出利用統(tǒng)一的類別、位置和mask特征表示UQR(Unified query representation)來實(shí)現(xiàn)端到端的實(shí)例分割。
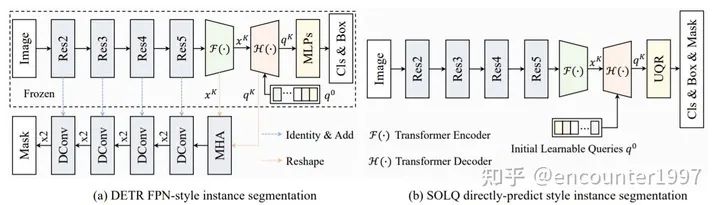
具體來說,SOLQ提出對(duì)mask進(jìn)行可逆的壓縮編碼,這樣在訓(xùn)練時(shí)模型的mask分支只需要將query的映射與低維的mask編碼作比較、計(jì)算損失;而在預(yù)測時(shí),通過解碼將預(yù)測出的低維mask編碼解碼為2D的分割map,如下圖所示。
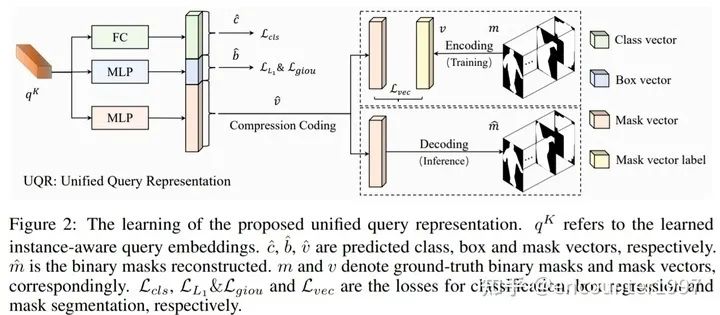
這樣利用統(tǒng)一的query特征表示來實(shí)現(xiàn)分類、定位和分割三個(gè)任務(wù)使得模型,不僅大大簡化了DETR做實(shí)例分割的整體流程,還能夠充分利用多任務(wù)訓(xùn)練的好處。實(shí)驗(yàn)表明,采用UQR不僅能夠同時(shí)也能夠提升目標(biāo)檢測的精度。
總結(jié)
本文主要介紹了DETR在目標(biāo)檢測領(lǐng)域帶來的變革與思考。由于涉及的文章數(shù)量較多,沒有全部展開介紹,感興趣的小伙伴還請(qǐng)參見論文原文。一個(gè)全新的目標(biāo)檢測框架能夠?yàn)檎麄€(gè)社區(qū)帶來這么多新的思考,不經(jīng)讓人感慨。個(gè)人認(rèn)為一個(gè)很鍛煉科研思維的方法就是嘗試站在某篇代表性文章剛剛發(fā)表的時(shí)間節(jié)點(diǎn)(先不看其后續(xù)工作),思考自己能夠從這篇文章中得到哪些啟發(fā),會(huì)考慮從哪些角度做進(jìn)一步的研究。再拿自己的思考與后續(xù)研究者的工作做比較,在這個(gè)過程中提升自己的科研直覺和判斷力。
由于筆者能力有限,如有敘述不當(dāng)之處,歡迎不吝賜教。
[1] End-to-End Object Detection with Transformers
[2] Deformable DETR: Deformable Transformers for End-to-End Object Detection
[3] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
[4] Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
[5] OTA: Optimal Transport Assignment for Object Detection
[6] SOLQ: Segmenting Objects by Learning Queries
[7] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
[8] Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers
——The End——

讀者,你好!我們建立了學(xué)習(xí)交流群,歡迎大家掃碼進(jìn)群討論!
微商和廣告請(qǐng)繞道,謝謝合作!

如果覺得有用,就請(qǐng)分享到朋友圈吧!
<b id="afajh"><abbr id="afajh"></abbr></b>