
做時間序列預(yù)測沒必要深度學(xué)習(xí)!GBDT性能超DNN
在深度學(xué)習(xí)方法應(yīng)用廣泛的今天,所有領(lǐng)域是不是非它不可呢?其實未必,在時間序列預(yù)測任務(wù)上,簡單的機器學(xué)習(xí)方法能夠媲美甚至超越很多 DNN 模型。

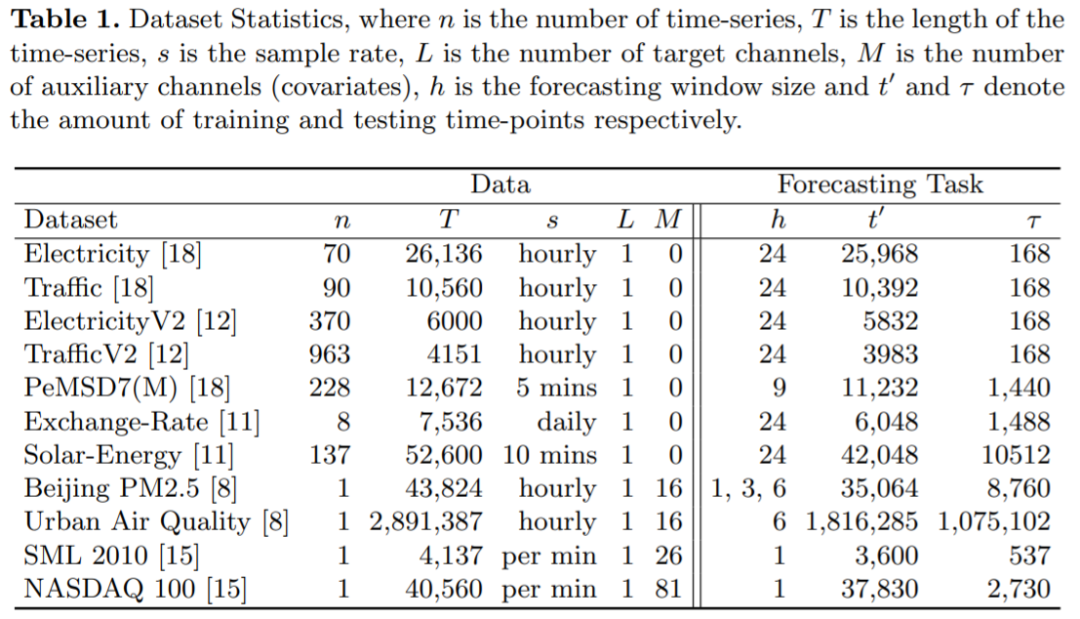
對于用于時間序列預(yù)測的基于窗口的學(xué)習(xí)框架來說,精心配置 GBRT 模型的輸入和輸出結(jié)構(gòu)有什么效果?
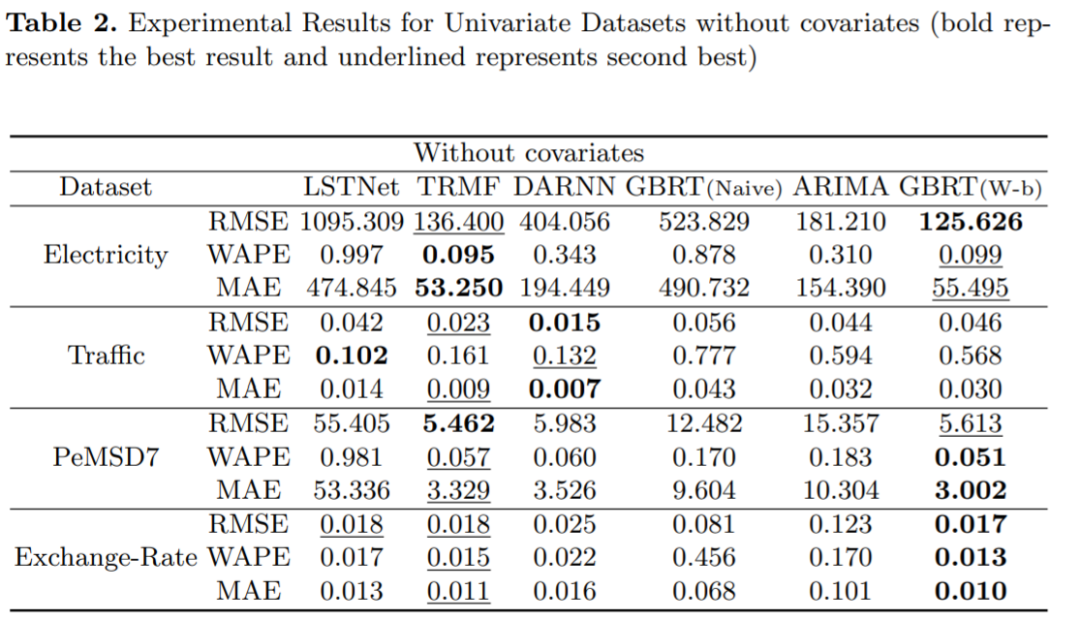
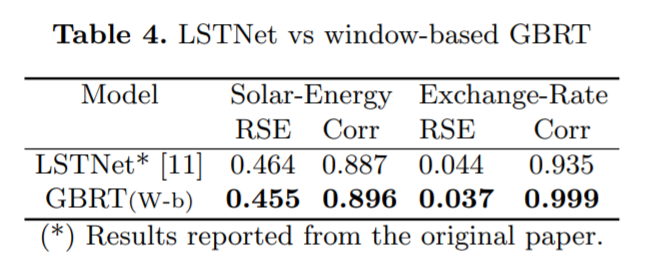
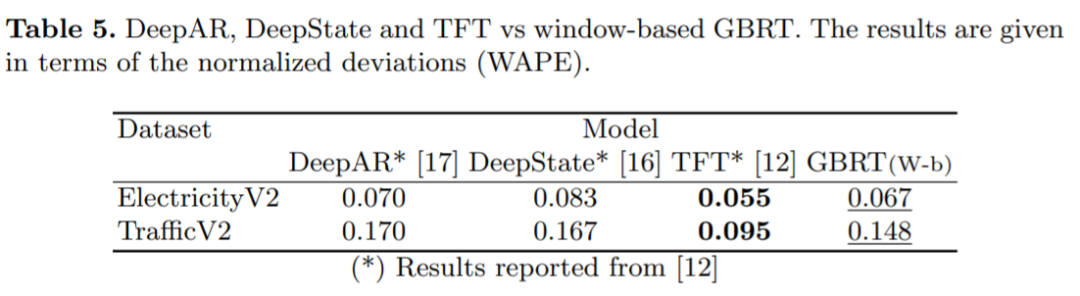
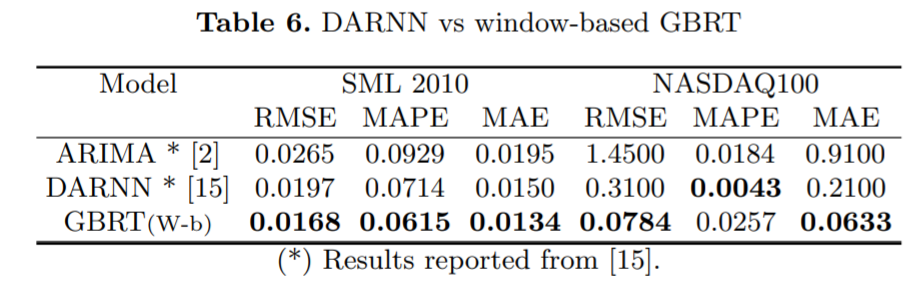
一個雖簡單但配置良好的 GBRT 模型與 SOTA 深度學(xué)習(xí)時間序列預(yù)測框架相比如何?
主題:只考慮時間序列預(yù)測領(lǐng)域的研究;
數(shù)據(jù)結(jié)構(gòu):專用數(shù)據(jù)類型,但如異步時間序列和概念化為圖形的數(shù)據(jù)被排除在外;
可復(fù)現(xiàn):數(shù)據(jù)、源代碼應(yīng)公開。如果源代碼不可用,但實驗設(shè)置有清晰的文檔,研究也可以從實驗中復(fù)制結(jié)果;
計算的可行性:研究中得出的結(jié)果能夠以易于處理的方式復(fù)現(xiàn),并在合理的時間內(nèi)可計算。
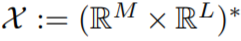 和一個集合
和一個集合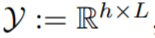 ,經(jīng)過一系列假設(shè)后,得到如下期望損失最小化模型:
,經(jīng)過一系列假設(shè)后,得到如下期望損失最小化模型: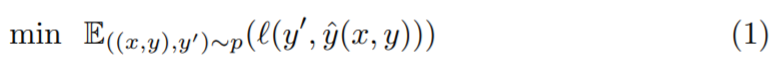
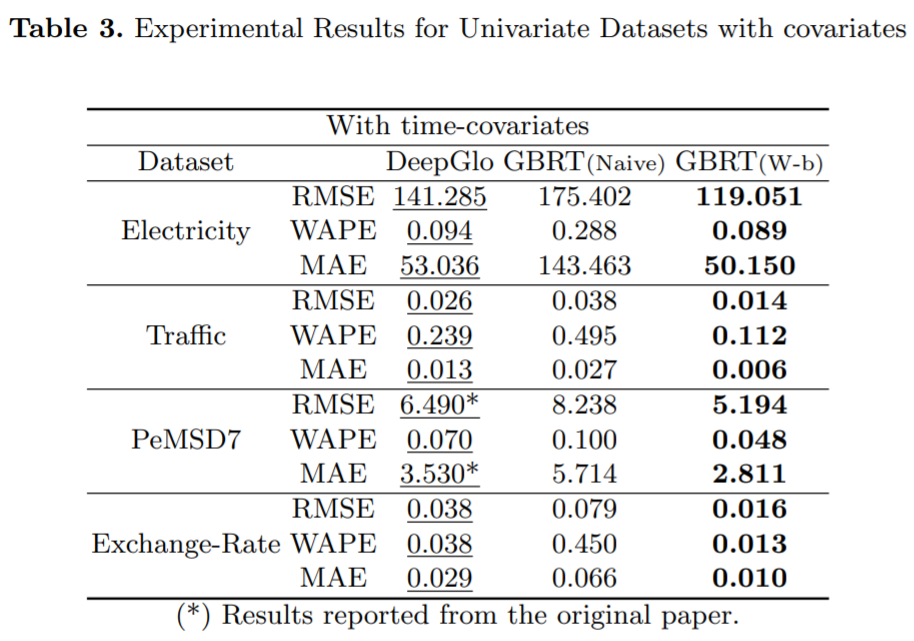
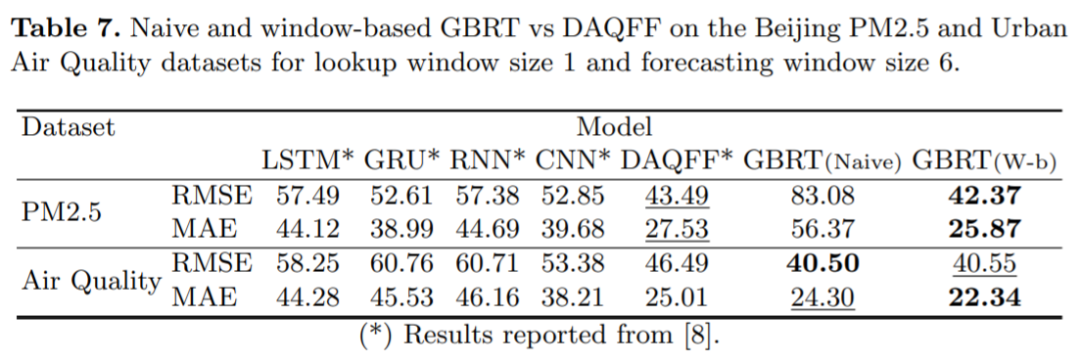
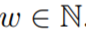 。這種基于窗口的 GBRT 模型輸入設(shè)置如圖 1 所示:
。這種基于窗口的 GBRT 模型輸入設(shè)置如圖 1 所示: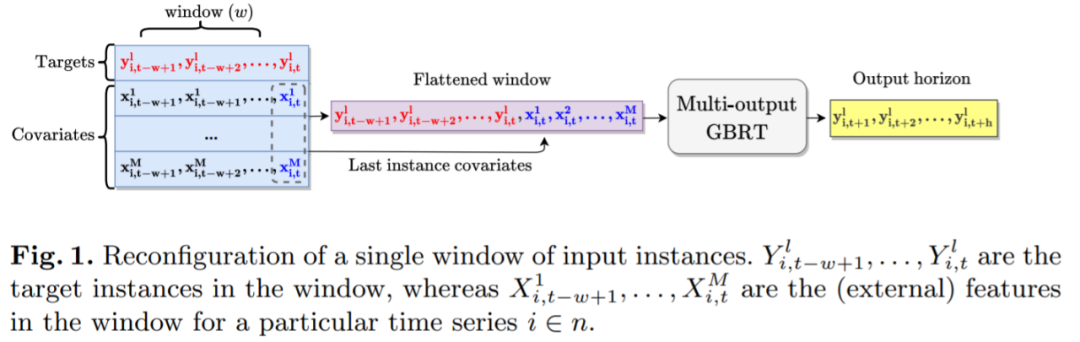
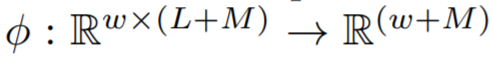 將典型的 2D 訓(xùn)練實例(時間序列輸入窗口)變換為適合 GBRT 的 1D 形狀向量(扁平窗口)。該函數(shù)將所有 w 實例的目標(biāo)值 y_i 連接起來,然后將最后一個時間點實例 t 的協(xié)變量向量附加到輸入窗口 w 中,表示為?
將典型的 2D 訓(xùn)練實例(時間序列輸入窗口)變換為適合 GBRT 的 1D 形狀向量(扁平窗口)。該函數(shù)將所有 w 實例的目標(biāo)值 y_i 連接起來,然后將最后一個時間點實例 t 的協(xié)變量向量附加到輸入窗口 w 中,表示為?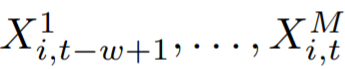 。
。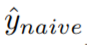 是一個簡單的逐點回歸模型,將時間點?
是一個簡單的逐點回歸模型,將時間點? 的協(xié)變量作為輸入,預(yù)測單一目標(biāo)值 Y_i、j 為同一時間點訓(xùn)練損失如下:
的協(xié)變量作為輸入,預(yù)測單一目標(biāo)值 Y_i、j 為同一時間點訓(xùn)練損失如下: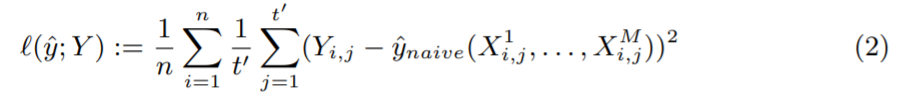
往期精彩:
《機器學(xué)習(xí) 公式推導(dǎo)與代碼實現(xiàn)》隨書PPT示例
?時隔一年!深度學(xué)習(xí)語義分割理論與代碼實踐指南.pdf第二版來了!
評論
圖片
表情