
零樣本/少樣本學(xué)習(xí)介紹及最新進(jìn)展調(diào)研
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


作者|楊浩
來源 | 知乎
地址 |?https://zhuanlan.zhihu.com/p/161233926
本文僅作學(xué)術(shù)分享,若侵權(quán)請(qǐng)聯(lián)系后臺(tái)刪文處理
損失函數(shù):
二元分類,交叉熵
訓(xùn)練過程:

Matching Networks for One Shot Learning 2016
論文地址:
papers.nips.cc/paper/63
簡(jiǎn)介:
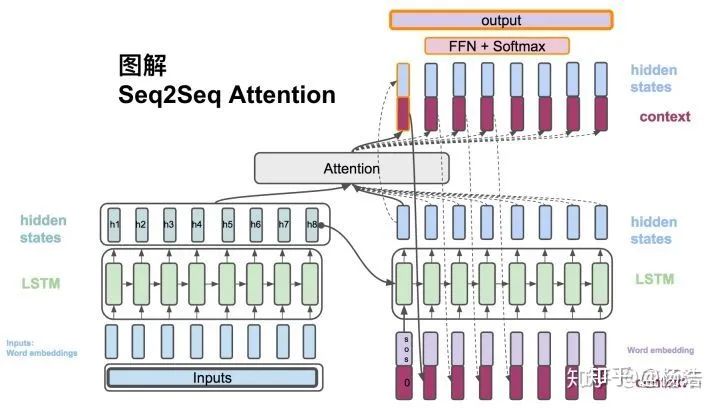
queryset的樣本判斷是supportset的哪個(gè)類別,是個(gè)knn的問題,本文訓(xùn)練了一個(gè)端到端的類似于nearest neighbor的分類器,思想就是借鑒seq2seq+attention。利用bi-lstm對(duì)supportset的樣本編碼(可能是為了將各個(gè)類別的樣本作為序列輸入到LSTM中,是為了模型縱觀所有的樣本去自動(dòng)選擇合適的特征去度量),然后queryset的樣本進(jìn)行k步attention編碼,取最后一個(gè)隱藏層當(dāng)做編碼,最后和之前的supportset的編碼做softmax得到類別。
網(wǎng)絡(luò)結(jié)構(gòu):
損失函數(shù):
多元,交叉熵。
Prototypical Networks for Few-shot Learning 2017
論文地址:
arxiv.org/pdf/1703.0517
簡(jiǎn)介:
對(duì)于分類問題,原型網(wǎng)絡(luò)將其看做在語(yǔ)義空間中尋找每一類的原型中心。針對(duì)Few-shot的任務(wù)定義,原型網(wǎng)絡(luò)訓(xùn)練時(shí)學(xué)習(xí)如何擬合中心。學(xué)習(xí)一個(gè)度量函數(shù),該度量函數(shù)可以通過少量的幾個(gè)樣本找到所屬類別在該度量空間的原型中心。測(cè)試時(shí),用支持集(Support Set)中的樣本來計(jì)算新的類別的聚類中心,再利用最近鄰分類器的思路進(jìn)行預(yù)測(cè)。
算法流程:

距離的度量屬于Bregman散度,其中就包括平方歐氏距離和Mahalanobis距離,文中利用了平方歐氏距離。和Prototypical Networks 在few-shot的場(chǎng)景下不同,在one-shot時(shí)等價(jià)。
損失函數(shù):多元,交叉熵
Relation Network for Few-Shot Learning 2018
論文地址:
arxiv.org/pdf/1711.0602
簡(jiǎn)介:
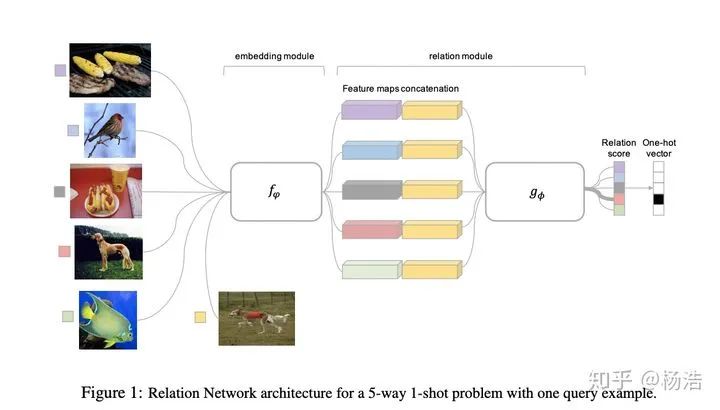
關(guān)系網(wǎng)絡(luò)的做法是將query set的特征表示和support set的特征表示concat一起,然后走mlp網(wǎng)絡(luò),最后softmax得到分類結(jié)果。當(dāng)few-shot的情況,將同一類的feature_map進(jìn)行相加。
網(wǎng)絡(luò)結(jié)構(gòu):
Few-Shot Text Classification with Induction Network 2018
論文地址:
arxiv.org/pdf/1902.1048
簡(jiǎn)介:
總體來說是原型網(wǎng)絡(luò)變型,其中原型網(wǎng)絡(luò)借助膠囊網(wǎng)絡(luò),一個(gè)膠囊網(wǎng)絡(luò)通過使用執(zhí)行動(dòng)態(tài)路由的“膠囊”來編碼個(gè)體和整體之間的內(nèi)在空間關(guān)系從而構(gòu)成視點(diǎn)不變的知識(shí)。
網(wǎng)絡(luò)結(jié)構(gòu):
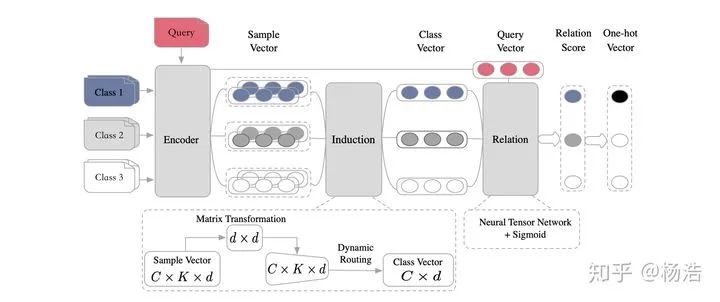
編碼器模塊:bi-lstm,然后self-attention變成固定長(zhǎng)度的向量,ht。
歸納模塊:

關(guān)系模塊:
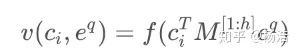
損失函數(shù):回歸
Dynamic Memory Induction Networks for Few-Shot Text Classification acl 2020
論文地址:
arxiv.org/pdf/2005.0572
簡(jiǎn)介:和Few-Shot Text Classification with Induction Network區(qū)別是編碼模塊使用bert-base,增加了pretrained的監(jiān)督學(xué)習(xí)階段。
網(wǎng)絡(luò)結(jié)構(gòu):

Pre-trained Encoder:
預(yù)訓(xùn)練+監(jiān)督學(xué)習(xí)到類別向量,當(dāng)做memory,后面跟著finetune。
Dynamic Memory Module:
運(yùn)行memory對(duì)supportset的sample進(jìn)行編碼

Query-enhanced Induction Module:
將上步驟生成的supportset的sample編碼當(dāng)做memory,利用queryset的sample,生成類別向量。
Similarity Classifier:

損失函數(shù):多元交叉熵
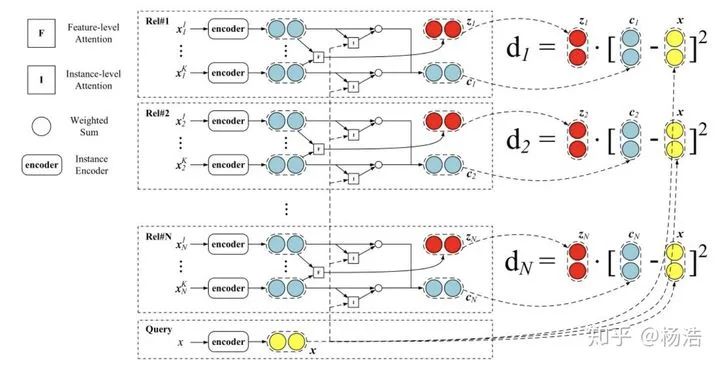
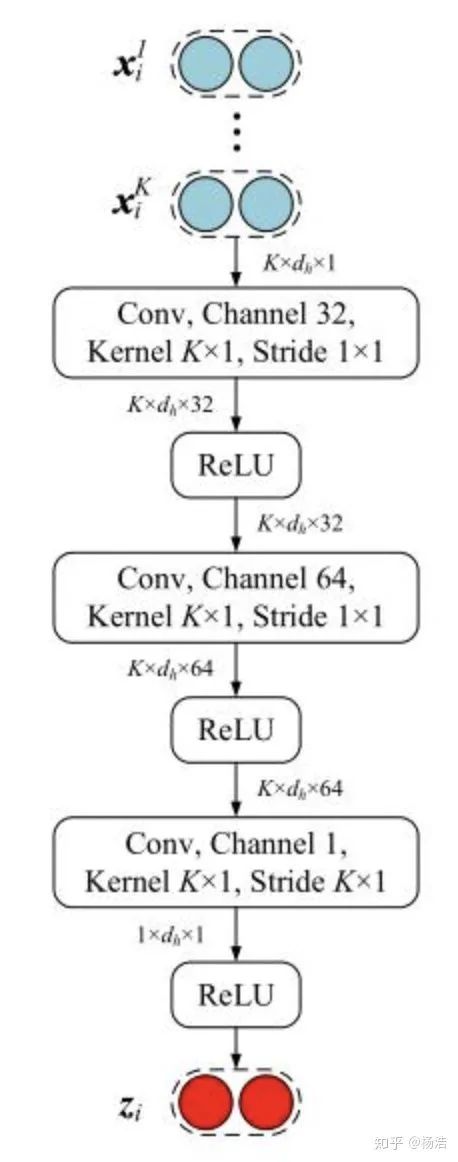
Hybrid attention-based prototypical networks for noisy few-shot relation classification 2019
簡(jiǎn)介:
先前研究論證了距離函數(shù)的選擇會(huì)影響這個(gè)網(wǎng)絡(luò)的能力。小樣本數(shù)據(jù)集意味著特征是稀疏的,簡(jiǎn)單的歐式距離能力不足。雖然特征空間是稀疏的,但總會(huì)有些維度有更強(qiáng)的區(qū)分能力,所以需要特征層面的注意力機(jī)制,將該類別下面的sample多次卷積得到特征attention。
網(wǎng)絡(luò)結(jié)構(gòu):
Few-shot text classification with distributional signatures 2019
論文地址:
arxiv.org/pdf/1908.0603
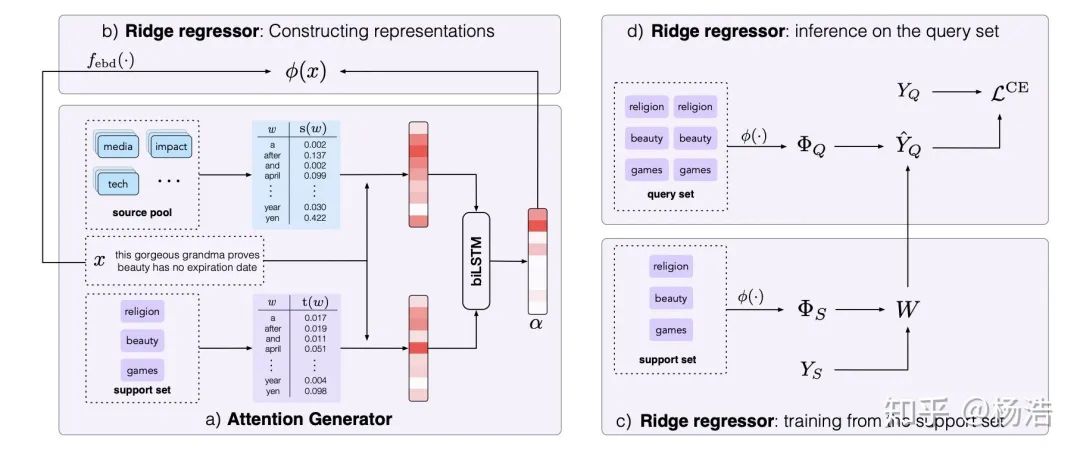
簡(jiǎn)介:
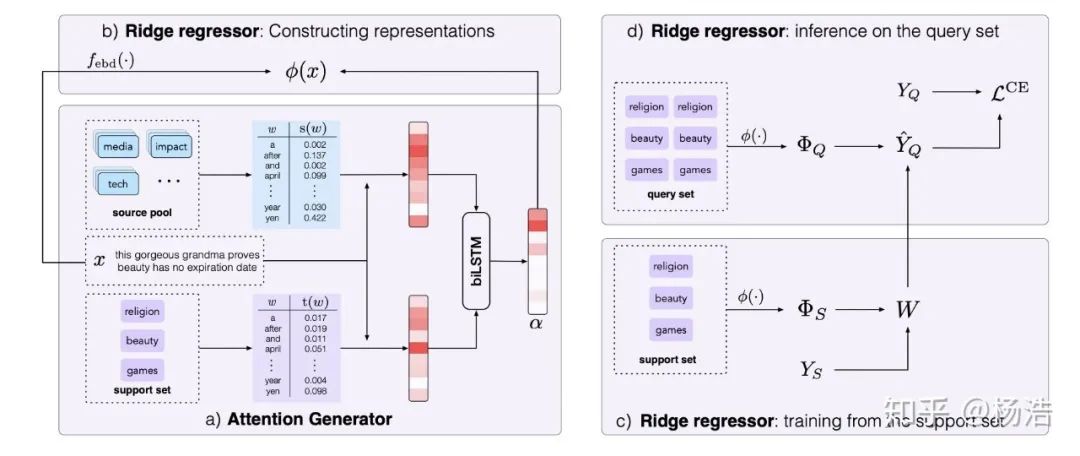
本文提出的方法可以很好地找到最重要的詞,從而判斷正確的類別,實(shí)現(xiàn)就是attention。增加了source pool,具體地,在元學(xué)習(xí)訓(xùn)練時(shí),對(duì)每個(gè)訓(xùn)練段,我們把所有沒被選擇的類的數(shù)據(jù)作為source pool;在元學(xué)習(xí)測(cè)試階段,source pool包括所有類的訓(xùn)練數(shù)據(jù)。
網(wǎng)絡(luò)結(jié)構(gòu):
對(duì)于嶺回歸器,我們首先得到樣本的表示:
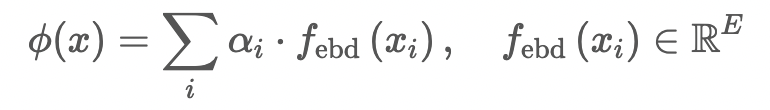

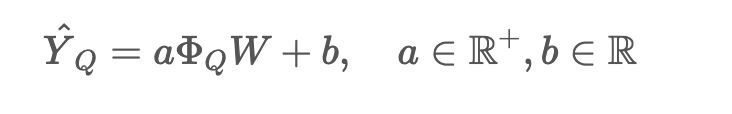
損失函數(shù):交叉熵
Diversity Transfer Network for Few-Shot Learning AAAI2020
論文地址:
arxiv.org/pdf/1912.1318
網(wǎng)絡(luò)結(jié)構(gòu):
輸入有三種圖,Query Image和 Support Image就是標(biāo)注的episode設(shè)置,在此基礎(chǔ)上額外加了一組Reference Image,它由H組類別相同的圖片對(duì)組成。那么首先這些所有的圖都會(huì)過一個(gè)Feature Extractor進(jìn)行特征提取(特征會(huì)經(jīng)過Norm),然后一組Reference Image 圖片對(duì)的輸出feature會(huì)相減和Support Image的feature再相加送入到一個(gè)Generator里面進(jìn)行encoding,那么作者認(rèn)為這個(gè)Encoding之后的feature和原始的support image的feature表征的是同一類物體(畢竟相同類別的兩張圖相減了嘛),作者通過這樣的操作把intra-class的diversity顯式的encode到網(wǎng)絡(luò)的訓(xùn)練過程中,希望模型可以學(xué)習(xí)到這種多樣性,至于meta class的分類就和protonet一樣了, 只是proxy的計(jì)算是H個(gè)encoding的feature再加上原始的support image的feature取平均。

Cross Attention Network for Few-shot Classification
論文地址:
papers.nips.cc/paper/86
簡(jiǎn)介:提出了cross attention ,其實(shí)就是兩個(gè)sample的embedding之間進(jìn)行attention
網(wǎng)絡(luò)結(jié)構(gòu):
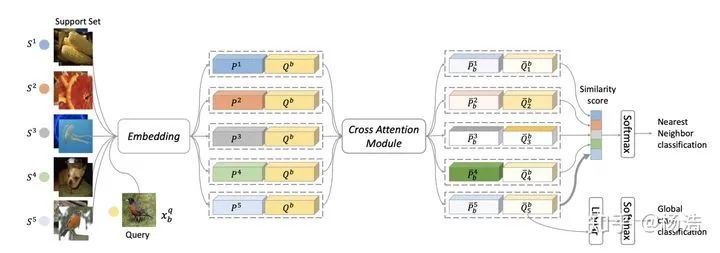
其中Cross Attention Module:

2.?optimizers-base learning(優(yōu)化器改進(jìn))
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 2017
論文地址:
arxiv.org/pdf/1703.0340
簡(jiǎn)介:
support set參與第一次參數(shù)更新。這里的參數(shù)更新并沒有直接作用于原模型,我們可以理解為先copy了一下模型,用來計(jì)算新參數(shù)。利用第一輪更新后的參數(shù),通過query set計(jì)算第二輪梯度,這一輪的梯度才是模型真正用于更新參數(shù)的梯度。至于這樣的方法,為什么比“直接使用theta在各個(gè)task上的loss之和來做梯度下降”效果更好,這里有兩篇論文從理論或數(shù)學(xué)上做了一些對(duì)MAML的分析。事實(shí)上,“直接使用theta在各個(gè)task上的loss之和來做梯度下降”相當(dāng)于直接做transfer learning,思路和預(yù)訓(xùn)練imagenet類似,只能最小化在across tasks的經(jīng)驗(yàn)風(fēng)險(xiǎn),不能做到task-specific。
arxiv.org/pdf/1803.0299
researchgate.net/public
算法流程:

Reptile: a Scalable Metalearning Algorithm
簡(jiǎn)介:
maml有對(duì)梯度二階求導(dǎo),Reptile是一種一階MAML。
論文地址:
d4mucfpksywv.cloudfront.net
算法流程:

Model-agnostic meta-learning for relation classification with limited supervision. 2019
論文地址:
aclweb.org/anthology/P1
簡(jiǎn)介:MAML改進(jìn),其實(shí)就是Reptile
算法流程:

Adaptive Cross-Modal Few-shot Learning 2019
論文地址:
arxiv.org/pdf/1902.0710
簡(jiǎn)介:
圖文和視頻多模融合,conbine通過系數(shù)(自適應(yīng)混合系數(shù),其實(shí)就是文本側(cè)的embeddng通過sigmod得到的),整體利用原型網(wǎng)絡(luò)。
網(wǎng)絡(luò)結(jié)構(gòu):

Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification
論文地址:aclweb.org/anthology/P1
簡(jiǎn)介:
首先對(duì)queryset的每一個(gè)instance和support的所有instance成詞級(jí)別的embedding矩陣,做交互attention,最后將attention結(jié)果和原來的矩陣進(jìn)行拼接,降為原來維度。求class embedding和原型網(wǎng)絡(luò)不通的是每一個(gè)類的權(quán)重是由queryset的實(shí)例attention得到的,然后得到class embedding,關(guān)系網(wǎng)絡(luò)做matchclass,得到結(jié)果。
網(wǎng)絡(luò)結(jié)構(gòu):

3. models-base learning(模型結(jié)構(gòu)改進(jìn))
Meta-Learning with Memory-Augmented Neural Networks 2016
論文地址:
web.stanford.edu/class/
簡(jiǎn)介:
針對(duì)傳統(tǒng)基于梯度的神經(jīng)網(wǎng)絡(luò)處理one-shot時(shí),遇到新的數(shù)據(jù)需要重新學(xué)習(xí)參數(shù),不能高效快速地適應(yīng)新數(shù)據(jù),此論文提出的模型可以快速編碼和檢索以往數(shù)據(jù)。
網(wǎng)絡(luò)結(jié)構(gòu):
使用序列輸入,每個(gè)輸入伴隨上一個(gè)標(biāo)記,防止模型僅僅學(xué)到映射關(guān)系
在不同數(shù)據(jù)集間,標(biāo)記被打亂,迫使模型必須學(xué)到保留一些樣本信息,供下次檢索使用


Meta Networks 2017
論文地址:
arxiv.org/pdf/1703.0083
簡(jiǎn)介:
Meta Networks跟MANN類似,也有一個(gè)外部的記憶模塊。三個(gè)主要過程:meta information的獲取、以及fast weight的生成和slow weight的優(yōu)化,由base learner和meta learner共同執(zhí)行。
算法流程:

A Simple Neural Attentive Meta-Learner 2018
論文地址:
arxiv.org/pdf/1707.0314
簡(jiǎn)介:
將meta-learning形式化為一個(gè)序列到序列的問題,使用一種新的時(shí)序卷積(TC)和注意力機(jī)制(Attention)的組合。通過將 TC 層與 Attention 層交錯(cuò),SNAIL可以高效的利用過去的經(jīng)驗(yàn),并且不限制其可以有效使用的經(jīng)驗(yàn)量。通過在多個(gè)階段使用注意力端到端訓(xùn)練的模型中的,SNAIL它可以利用時(shí)序卷積層在過去收集的經(jīng)驗(yàn)中了解要挑選特定的信息片段。模型的輸入序列是由帶標(biāo)簽的少量樣本和一個(gè)需要預(yù)測(cè)的樣本組成,它可以從序列中利用用要預(yù)測(cè)的樣本之前的有先驗(yàn)信息或標(biāo)簽信息來對(duì)序列的最后一個(gè)樣本預(yù)測(cè),有一種消息傳遞的思想。
模型結(jié)構(gòu):
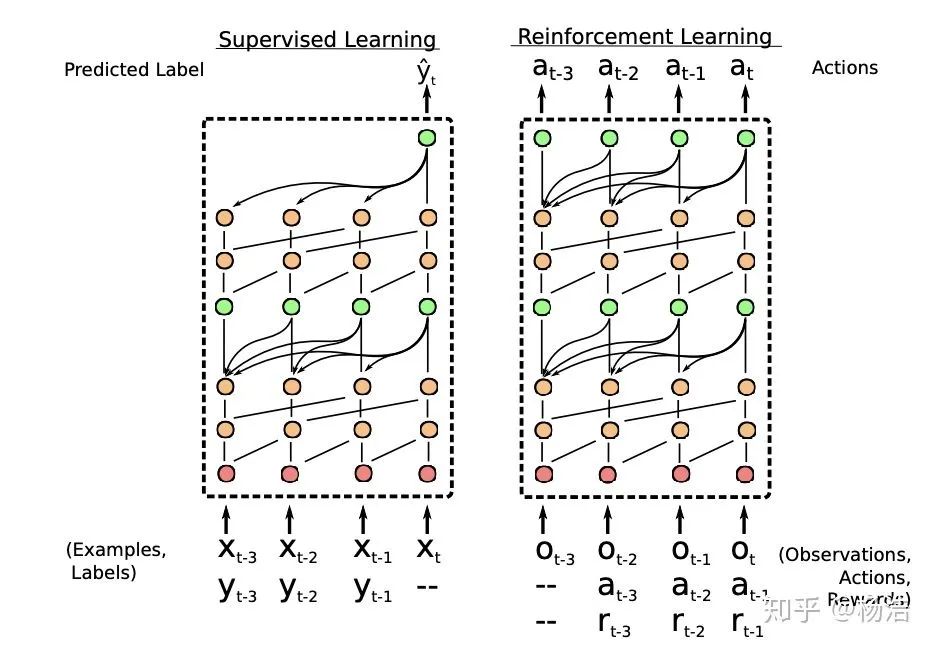
TC:
由一系列空洞卷積組成,這些dense block的膨脹率 R
呈指數(shù)級(jí)增長(zhǎng)
ATT:
LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning
論文地址:
arxiv.org/pdf/1905.0633
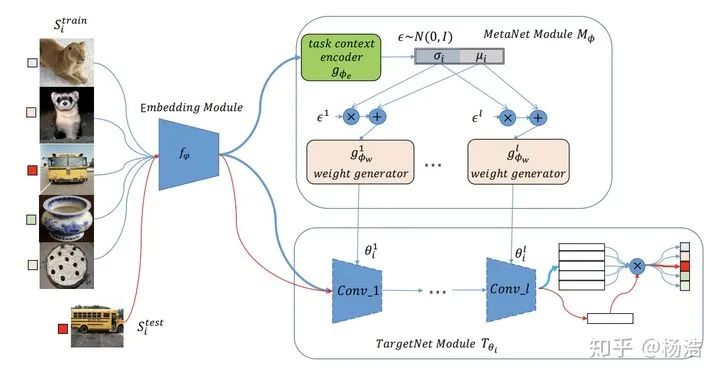
簡(jiǎn)介:model-based方法,訓(xùn)練網(wǎng)絡(luò)(bilstm)生成match network的參數(shù)
網(wǎng)絡(luò)結(jié)構(gòu):
Few-Shot Representation Learning for Out-Of-Vocabulary Words
論文地址:aclweb.org/anthology/P1
簡(jiǎn)介:
對(duì)預(yù)訓(xùn)練的詞表,統(tǒng)計(jì)出現(xiàn)次數(shù)較多的詞當(dāng)訓(xùn)練樣本,本質(zhì)是一個(gè)回歸問題(將OOV的上下文和細(xì)粒度特征同時(shí)作為輸入,輸入它的近似詞向量,使得這個(gè)近似詞向量與它的在嵌入空間中“應(yīng)該”的真實(shí)詞向量比較接近),maml解決小樣本過擬合點(diǎn)的問題。每一輪訓(xùn)練結(jié)束,更新訓(xùn)練oov。
網(wǎng)絡(luò)結(jié)構(gòu):

Metagan: An adversarial approach to few-shot learning 2018
論文地址:papers.nips.cc/paper/75
簡(jiǎn)介:
MetaGAN算法能夠從有標(biāo)簽和無標(biāo)簽的例子中學(xué)習(xí)推斷特定于任務(wù)的數(shù)據(jù)分布,在有監(jiān)督和半有監(jiān)督的情況下,證明了MetaGAN在流行的小樣本圖像分類基準(zhǔn)上的有效性
算法流程:
loss:
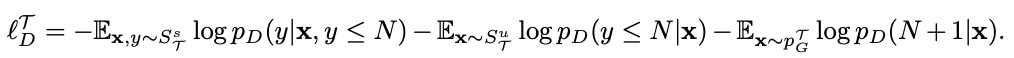
判別器:可以是關(guān)系網(wǎng)絡(luò)
生成器:
將supportset的所有sample encode成vector,在加上隨機(jī)擾動(dòng)。
Few-shot learning with graph neural network 2017
論文地址:
arxiv.org/pdf/1711.0404
簡(jiǎn)介:
利用圖卷積獲取sample表示之間的高階特征組合,幾層代表幾階鄰居。圖模型小樣本學(xué)習(xí)的目的是將標(biāo)簽信息從有標(biāo)簽的樣本傳播到無標(biāo)簽的查詢圖像。這種信息傳播可以形式化為對(duì)輸入圖像和標(biāo)簽確定的圖形模型的后驗(yàn)推理。
網(wǎng)絡(luò)結(jié)構(gòu):

標(biāo)簽one-hot形式拼接
圖神經(jīng)網(wǎng)絡(luò):
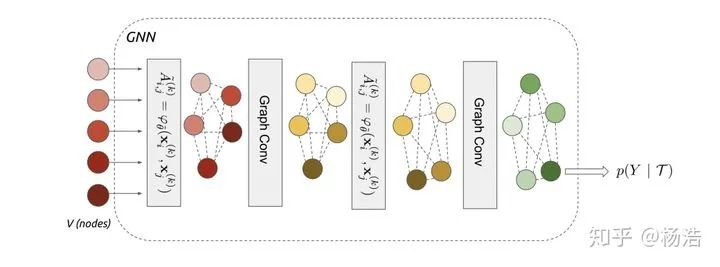
圖卷積:
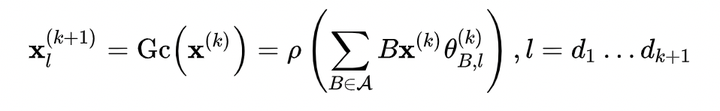
梳理論文發(fā)展思路,僅僅個(gè)人觀點(diǎn):
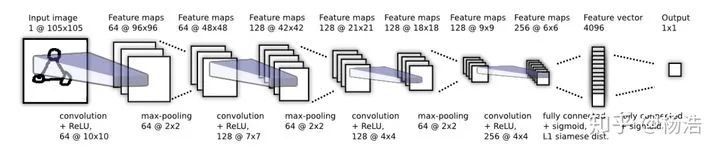
1.Siamese Neural Networks for One-shot Image Recognition 2015
之前的小樣本學(xué)習(xí)方案需要特定的先驗(yàn)知識(shí)先驗(yàn)知識(shí)或者特定的推理過程,不具有通用性、魯棒性且算法較為復(fù)雜(例如在Omniglot數(shù)據(jù)集上,之前的方法HBPL就要借助字母的順序)需要尋找一個(gè)通用的算法。 借助神經(jīng)網(wǎng)絡(luò)進(jìn)行自動(dòng)化的特征提取,神經(jīng)網(wǎng)絡(luò)具有很多層的非線性能夠捕捉到輸入空間中的不變性(投影到一個(gè)度量空間,相當(dāng)于壓縮模型假設(shè)空間)。 第一個(gè)將深度卷積孿生網(wǎng)絡(luò)用來解決One-Shot Learning問題,訓(xùn)練好孿生網(wǎng)絡(luò)以后,不需要經(jīng)過再訓(xùn)練即可用于One-Shot Learning任務(wù)。
2.Matching Networks for One Shot Learning 2016
目前一個(gè)標(biāo)準(zhǔn)的小樣本學(xué)習(xí)方法是訓(xùn)練一個(gè)線性分類器比如svm,但是這需要對(duì)模型參數(shù)優(yōu)化,需要訓(xùn)練樣本。另一個(gè)非參數(shù)的方法是利用knn,可以立即使用最近鄰居對(duì)新類進(jìn)行分類,而無需進(jìn)行任何優(yōu)化,但是依賴于度量的選擇,比如l2等。 核心想法:訓(xùn)練一個(gè)end-to-end最鄰近分類器(attention用到了cos距離)。
3.Prototypical Networks for Few-shot Learning 2017
借鑒matching network解決one-shot,原型網(wǎng)絡(luò)解決few-shot問題,根據(jù)zero-shot的方法,構(gòu)建對(duì)于類別的高level表示,通過相同類別的樣本embedding相加解決(減少bais),最后使用歐幾里得距離判斷類別。 通過以往工作和本文實(shí)驗(yàn)得出,使用歐幾里得距離來作為距離度量會(huì)明顯的優(yōu)于使用余弦距離作為距離度量。 以往的實(shí)驗(yàn)發(fā)現(xiàn),在訓(xùn)練和測(cè)試時(shí)保持相同的episode設(shè)置往往會(huì)得出較好的結(jié)果。例如,我們?cè)跍y(cè)試時(shí)期望使用5-way-1-shot的方式,那么我們訓(xùn)練時(shí)就要使得episode的設(shè)置為Nc為5、Ns為1,其中Nc代表從episode中選擇的類別的個(gè)數(shù),Ns代表每個(gè)類別中被選擇為支持樣例的個(gè)數(shù)。然而,在我們的實(shí)驗(yàn)中發(fā)現(xiàn),使用比測(cè)試時(shí)更高的Nc(“way”)對(duì)模型是有益的。
4.Learning to Compare: Relation Network for Few-Shot Learning 2018
針對(duì)小樣本情況學(xué)習(xí)一個(gè)end-to-end模型,讓模型學(xué)會(huì)比較,感覺像是mn和pn的結(jié)合,mn適用one-shot(對(duì)于每個(gè)類別多個(gè)樣本沒法解決),pn適用few-shot(還需要指定度量方式)
5.Few-Shot Text Classification with Induction Network 2018
本質(zhì)解決類別向量有偏問題。之前pn求類別向量的話。因?yàn)槊總€(gè)類別的樣本數(shù)量比較少,容易產(chǎn)生噪音,導(dǎo)致類別向量有偏。通過引入Induction模塊,將同類別下的樣本進(jìn)行交互,根據(jù)交互后的權(quán)重來求得class-wise類別向量,使得類別泛化能力更強(qiáng)。
6.Dynamic Memory Induction Networks for Few-Shot Text Classification 2020
本質(zhì)還是解決怎么學(xué)習(xí)更好的類別向量的問題,類別向量表示在不同Meta task之間切換時(shí)候容易丟失主要的信息,可以利用記憶增強(qiáng)來解決。 由于同種類別的不同樣本是多樣性的,導(dǎo)致很難學(xué)到一個(gè)穩(wěn)定的類別表示向量,通過quert_set和support_set的交互可以緩解此問題。
7.Hybrid attention-based prototypical networks for noisy few-shot relation 2019
為了解決few-shot learning 中易受噪聲實(shí)例影響這一問題(由于任務(wù)的背景是在few-shot學(xué)習(xí)中,用來計(jì)算類原形的樣本數(shù)量往往很少。如果出現(xiàn)錯(cuò)誤實(shí)例或者是和常規(guī)句子語(yǔ)義偏差較大的正確實(shí)例的話,對(duì)于類原形的影響是非常的巨大),該論文提出了一種基于原形網(wǎng)絡(luò)的混合attention網(wǎng)絡(luò)。該模型設(shè)計(jì)了實(shí)例級(jí)別和特征級(jí)別的attention機(jī)制,分別的突出模型中關(guān)鍵樣本實(shí)例和關(guān)鍵特征。 instance level attention: 普通的protype network針對(duì)支撐集中各個(gè)樣本進(jìn)行直接平均,作者認(rèn)為這樣會(huì)噪聲特別大,因此引入加權(quán)平均的思想(利用實(shí)例attention來選擇support集中最有價(jià)值的樣本,來緩解噪聲樣本對(duì)模型的影響)。 feature level attention: 原始的prototype network直接利用簡(jiǎn)單的歐氏距離作為距離函數(shù),而本文作者認(rèn)為在利用支撐集中樣例對(duì)測(cè)試樣例進(jìn)行分類時(shí),某些feature可能對(duì)分類至關(guān)重要,因此在feature這個(gè)層級(jí)也要考慮注意力機(jī)制(利用特征attention來突出特征空間中重要的特征維度,來緩解特征稀疏問題),具體做法對(duì)同類樣本做三次卷積得到。
8.Few-shot text classification with distributional signatures 2020
不同Meta task之間切換時(shí)候容易丟失主要的信息,例如有些詞匯對(duì)于當(dāng)前類別比較重要,但是對(duì)于其他類別不是很重要。為了解決這個(gè)問題,通過引入tf-idf等信息。
9.Cross Attention Network for Few-shot Classification 2019
訓(xùn)練集和測(cè)試集的類別是不重合的,在一部分類別上進(jìn)行訓(xùn)練,然后在另一部分類別中測(cè)試。這樣存在一個(gè)問題:在訓(xùn)練階段識(shí)別的是人和椅子,在測(cè)試階段實(shí)際預(yù)測(cè)的是窗簾,由于窗簾在訓(xùn)練階段沒有出現(xiàn)過,因此在預(yù)測(cè)的時(shí)候通常把注意力放在了人和椅子上面,注意力很難在目標(biāo)物體上。針對(duì)這個(gè)問題,論文中提出了CAN(cross attention network)。 針對(duì)樣本非常少的問題,引進(jìn)直推式推理算法去緩解小樣本問題,將一些無標(biāo)簽的但是置信度較高的樣本加入到訓(xùn)練樣本中。
10.Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 2017
在高容量的分類器中的基于梯度的優(yōu)化算法需要 在大量樣本上進(jìn)行大量的迭代步驟 以取得良好的表現(xiàn)。為了解決利用先驗(yàn)知識(shí)優(yōu)化給定假設(shè)空間中最優(yōu)假設(shè)的搜索的問題,提出一種用于元學(xué)習(xí)的簡(jiǎn)單模型和與任務(wù)無關(guān)的算法,該算法可訓(xùn)練模型的參數(shù),尋找一個(gè)模型的初始值,以使少量的梯度更新可快速學(xué)習(xí)新任務(wù)。不會(huì)擴(kuò)展學(xué)習(xí)參數(shù)的數(shù)量(lstm),也不會(huì)需要對(duì)模型空間進(jìn)行約束(孿生網(wǎng)絡(luò))。
11.Optimization as a model for few-shot learning 2017
梯度優(yōu)化算法無法在幾步之內(nèi)完成優(yōu)化,特別是非凸問題,各種超參的選取無法保證收斂的速度。不同任務(wù)隨機(jī)初始化會(huì)影響任務(wù)收斂到好的解上。盡管遷移學(xué)習(xí)能緩解這個(gè)問題,但新數(shù)據(jù)與原始數(shù)據(jù)偏差較大時(shí),遷移學(xué)習(xí)的性能就會(huì)大大降低。LSTM內(nèi)部的更新非常類似于梯度下降的更新,因此利用LSTM的結(jié)構(gòu)訓(xùn)練一個(gè)meta-learner模型,用于學(xué)習(xí)另一個(gè)神經(jīng)網(wǎng)絡(luò)的參數(shù),既學(xué)習(xí)優(yōu)化參數(shù)規(guī)則,也學(xué)習(xí)權(quán)重初始化。 元學(xué)習(xí)優(yōu)化器能夠在給定一系列分類器在訓(xùn)練集的梯度和損失下,為分類器生成一系列更新,從而使分類器達(dá)到較好的表現(xiàn)。每一步迭代t,基于lstm的元學(xué)習(xí)器都接受到分類器傳來的梯度,損失等信息,元學(xué)習(xí)器基于此計(jì)算學(xué)習(xí)率和忘記門的值,并返回給分類器要更新的參數(shù)的值,每迭代T步,分類器的損失在測(cè)試集上計(jì)算出來返回給元學(xué)習(xí)器,用來訓(xùn)練元學(xué)習(xí)器,更新元學(xué)習(xí)器的參數(shù)。元學(xué)習(xí)器既考慮一個(gè)任務(wù)的短期記憶,同時(shí)也考慮全部任務(wù)的長(zhǎng)期記憶。 一是SGD的優(yōu)化方法在非凸情況下表現(xiàn)得不好,同行需要大量迭代才有好的結(jié)果。第二是,對(duì)于不同的數(shù)據(jù)集。網(wǎng)絡(luò)的每次訓(xùn)練都得隨機(jī)初始化參數(shù)。雖然遷移學(xué)習(xí)通過預(yù)訓(xùn)練能緩解這個(gè)問題,但是由于模型任務(wù)目標(biāo)的分散,遷移學(xué)習(xí)的優(yōu)勢(shì)也不明顯。因此迫切需要一個(gè)通用的初始化方法,使得在訓(xùn)練不同數(shù)據(jù)集時(shí)有一個(gè)較好的開始點(diǎn)而不是隨機(jī)初始化參數(shù)。
12.One-shot Learning with Memory-Augmented Neural Networks 2016
標(biāo)準(zhǔn)深度神經(jīng)網(wǎng)絡(luò)缺乏不斷學(xué)習(xí)或不斷學(xué)習(xí)新概念的能力,而不會(huì)忘記或破壞以前學(xué)習(xí)的模式。
針對(duì)小樣本問題,傳統(tǒng)的基于梯度的網(wǎng)絡(luò)需要大量的數(shù)據(jù)去學(xué)習(xí),通常需要經(jīng)過大量廣泛的迭代訓(xùn)練。當(dāng)給模型輸入新數(shù)據(jù)時(shí),模型必須低效的重新學(xué)習(xí)其參數(shù)從而充分的融入新的信息,并不會(huì)造成較大的干擾影響。具有增強(qiáng)記憶能力的網(wǎng)絡(luò)結(jié)構(gòu),例如NTMs具有快速編碼新信息的能力,因此能消除傳統(tǒng)模型的缺點(diǎn)。這里,我們證明了記憶增強(qiáng)神經(jīng)網(wǎng)絡(luò)(具有快速吸收新數(shù)據(jù)知識(shí)的能力,并且能利用這些吸收了的數(shù)據(jù),在少量樣本的基礎(chǔ)上做出準(zhǔn)確的預(yù)測(cè)。
13.Meta Networks 2017
深度神經(jīng)網(wǎng)絡(luò)在大量應(yīng)用中表現(xiàn)出了巨大的成功,但是需要大量的數(shù)據(jù),此外標(biāo)準(zhǔn)的深度神經(jīng)網(wǎng)絡(luò)缺乏不斷學(xué)習(xí)或不斷學(xué)習(xí)新概念而不會(huì)忘記或破壞以前學(xué)習(xí)的模式的能力。 MetaNet由兩部分組成:基學(xué)習(xí)器(Base Learner)和帶有額外記憶模塊的元學(xué)習(xí)器(Meta Learner)。學(xué)習(xí)也在連個(gè)分離的空間內(nèi)進(jìn)行,基學(xué)習(xí)器在輸入任務(wù)空間,而元學(xué)習(xí)在與任務(wù)無關(guān)的元空間,基學(xué)習(xí)器向元學(xué)習(xí)提供一種由高階的元信息構(gòu)成的反饋,用于解釋他在當(dāng)前任務(wù)空間內(nèi)的狀況。此外,MetaNet的權(quán)重還涉及不同的時(shí)間尺度:快速權(quán)重(Fast Weight)和慢速權(quán)重(Slow Weight),在訓(xùn)練過程中,快速權(quán)重是利用另一個(gè)網(wǎng)絡(luò)根據(jù)梯度信息生成的,而慢速權(quán)重則需要利用SGD方法進(jìn)行更新得到。
14.Knowledge Guided Metric Learning for Few-Shot Text Classification 2020
人類能從相關(guān)的任務(wù)知識(shí)來學(xué)習(xí)新的任務(wù),我們使用知識(shí)圖譜來自模仿人類知識(shí),輔助更好的學(xué)習(xí)。
15.Prototype Rectification for Few-Shot Learning 2019
傳統(tǒng)的原型網(wǎng)絡(luò)是將support集里面每個(gè)類的所有樣本的特征的平均作為該類的原型representation,通過query集合的特征representation與support集中每個(gè)類別的原型representation進(jìn)行歐式距離計(jì)算,在經(jīng)過softmax得出最后所屬類別。簡(jiǎn)單的求平均會(huì)產(chǎn)生很大的bias,因此提出了對(duì)原型網(wǎng)絡(luò)進(jìn)行修正,從兩個(gè)角度:intra-class bias和cross-class bias。 Intra-Class Bias:類似于半監(jiān)督,將置信度高的樣本加入。Cross-Class Bias:指support集中的平均樣本特征與query集中的平均樣本特征間存在差異,對(duì)每個(gè)歸一化的query 數(shù)據(jù)加上這個(gè)差異。
16.Hierarchical Attention Prototypical Networks for Few-Shot Text Classification 2019
原型網(wǎng)絡(luò)因?yàn)闃颖旧俣鴰碓胍舻挠绊懀岢鰧哟蝍ttention原型網(wǎng)絡(luò),從特征,詞和實(shí)例不同的角度緩解這個(gè)問題。
推薦閱讀
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!