
MySQL索引奪命連環(huán)18問!
小伙伴們好,我是蘇三。
今天給大家?guī)砹薓ySQL索引的常考面試題,看看你能答對多少~
本文已同步Github倉庫,歡迎小伙伴star,點擊文末左側(cè)的閱讀原文即可直達倉庫,Github地址:https://github.com/cosen1024/Java-Interview
這是本期的MySQL索引面試題目錄,不會的快快查漏補缺~

1. 索引是什么?
索引是一種特殊的文件(InnoDB數(shù)據(jù)表上的索引是表空間的一個組成部分),它們包含著對數(shù)據(jù)表里所有記錄的引用指針。
索引是一種數(shù)據(jù)結(jié)構(gòu)。數(shù)據(jù)庫索引,是數(shù)據(jù)庫管理系統(tǒng)中一個排序的數(shù)據(jù)結(jié)構(gòu),以協(xié)助快速查詢、更新數(shù)據(jù)庫表中數(shù)據(jù)。索引的實現(xiàn)通常使用B樹及其變種B+樹。更通俗的說,索引就相當(dāng)于目錄。為了方便查找書中的內(nèi)容,通過對內(nèi)容建立索引形成目錄。而且索引是一個文件,它是要占據(jù)物理空間的。
MySQL索引的建立對于MySQL的高效運行是很重要的,索引可以大大提高MySQL的檢索速度。比如我們在查字典的時候,前面都有檢索的拼音和偏旁、筆畫等,然后找到對應(yīng)字典頁碼,這樣然后就打開字典的頁數(shù)就可以知道我們要搜索的某一個key的全部值的信息了。
2. 索引有哪些優(yōu)缺點?
索引的優(yōu)點
可以大大加快數(shù)據(jù)的檢索速度,這也是創(chuàng)建索引的最主要的原因。 通過使用索引,可以在查詢的過程中,使用優(yōu)化隱藏器,提高系統(tǒng)的性能。
索引的缺點
時間方面:創(chuàng)建索引和維護索引要耗費時間,具體地,當(dāng)對表中的數(shù)據(jù)進行增加、刪除和修改的時候,索引也要動態(tài)的維護,會降低增/改/刪的執(zhí)行效率; 空間方面:索引需要占物理空間。
3. MySQL有哪幾種索引類型?
1、從存儲結(jié)構(gòu)上來劃分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。這里所描述的是索引存儲時保存的形式,
2、從應(yīng)用層次來分:普通索引,唯一索引,復(fù)合索引。
普通索引:即一個索引只包含單個列,一個表可以有多個單列索引
唯一索引:索引列的值必須唯一,但允許有空值
復(fù)合索引:多列值組成一個索引,專門用于組合搜索,其效率大于索引合并
聚簇索引(聚集索引):并不是一種單獨的索引類型,而是一種數(shù)據(jù)存儲方式。具體細節(jié)取決于不同的實現(xiàn),InnoDB的聚簇索引其實就是在同一個結(jié)構(gòu)中保存了B-Tree索引(技術(shù)上來說是B+Tree)和數(shù)據(jù)行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
3、根據(jù)中數(shù)據(jù)的物理順序與鍵值的邏輯(索引)順序關(guān)系:聚集索引,非聚集索引。
4. 說一說索引的底層實現(xiàn)?
Hash索引
基于哈希表實現(xiàn),只有精確匹配索引所有列的查詢才有效,對于每一行數(shù)據(jù),存儲引擎都會對所有的索引列計算一個哈希碼(hash code),并且Hash索引將所有的哈希碼存儲在索引中,同時在索引表中保存指向每個數(shù)據(jù)行的指針。
圖片來源:https://www.javazhiyin.com/40232.html

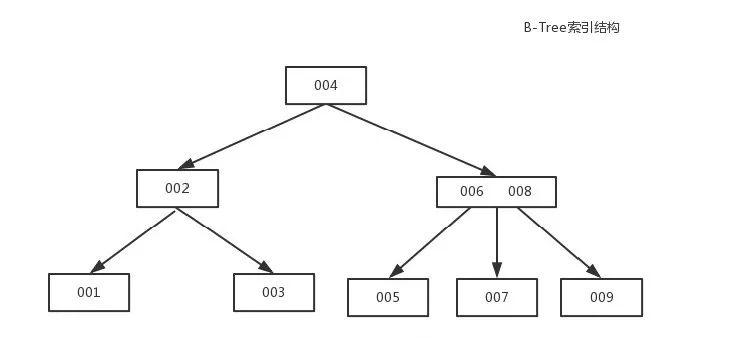
B-Tree索引(MySQL使用B+Tree)
B-Tree能加快數(shù)據(jù)的訪問速度,因為存儲引擎不再需要進行全表掃描來獲取數(shù)據(jù),數(shù)據(jù)分布在各個節(jié)點之中。
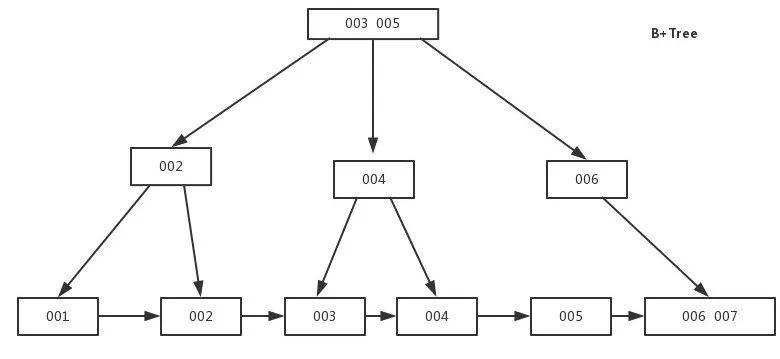
B+Tree索引
是B-Tree的改進版本,同時也是數(shù)據(jù)庫索引索引所采用的存儲結(jié)構(gòu)。數(shù)據(jù)都在葉子節(jié)點上,并且增加了順序訪問指針,每個葉子節(jié)點都指向相鄰的葉子節(jié)點的地址。相比B-Tree來說,進行范圍查找時只需要查找兩個節(jié)點,進行遍歷即可。而B-Tree需要獲取所有節(jié)點,相比之下B+Tree效率更高。
B+tree性質(zhì):
n棵子tree的節(jié)點包含n個關(guān)鍵字,不用來保存數(shù)據(jù)而是保存數(shù)據(jù)的索引。
所有的葉子結(jié)點中包含了全部關(guān)鍵字的信息,及指向含這些關(guān)鍵字記錄的指針,且葉子結(jié)點本身依關(guān)鍵字的大小自小而大順序鏈接。
所有的非終端結(jié)點可以看成是索引部分,結(jié)點中僅含其子樹中的最大(或最小)關(guān)鍵字。
B+ 樹中,數(shù)據(jù)對象的插入和刪除僅在葉節(jié)點上進行。
B+樹有2個頭指針,一個是樹的根節(jié)點,一個是最小關(guān)鍵碼的葉節(jié)點。
5. 為什么索引結(jié)構(gòu)默認使用B+Tree,而不是B-Tree,Hash,二叉樹,紅黑樹?
B-tree:從兩個方面來回答
B+樹的磁盤讀寫代價更低:B+樹的內(nèi)部節(jié)點并沒有指向關(guān)鍵字具體信息的指針,因此其內(nèi)部節(jié)點相對B(B-)樹更小,如果把所有同一內(nèi)部節(jié)點的關(guān)鍵字存放在同一盤塊中,那么盤塊所能容納的關(guān)鍵字數(shù)量也越多,一次性讀入內(nèi)存的需要查找的關(guān)鍵字也就越多,相對
IO讀寫次數(shù)就降低了。由于B+樹的數(shù)據(jù)都存儲在葉子結(jié)點中,分支結(jié)點均為索引,方便掃庫,只需要掃一遍葉子結(jié)點即可,但是B樹因為其分支結(jié)點同樣存儲著數(shù)據(jù),我們要找到具體的數(shù)據(jù),需要進行一次中序遍歷按序來掃,所以B+樹更加適合在
區(qū)間查詢的情況,所以通常B+樹用于數(shù)據(jù)庫索引。
Hash:
雖然可以快速定位,但是沒有順序,IO復(fù)雜度高;
基于Hash表實現(xiàn),只有Memory存儲引擎顯式支持哈希索引 ;
適合等值查詢,如=、in()、<=>,不支持范圍查詢 ;
因為不是按照索引值順序存儲的,就不能像B+Tree索引一樣利用索引完成排序 ;
Hash索引在查詢等值時非常快 ;
因為Hash索引始終索引的所有列的全部內(nèi)容,所以不支持部分索引列的匹配查找 ;
如果有大量重復(fù)鍵值得情況下,哈希索引的效率會很低,因為存在哈希碰撞問題 。
二叉樹:樹的高度不均勻,不能自平衡,查找效率跟數(shù)據(jù)有關(guān)(樹的高度),并且IO代價高。
紅黑樹:樹的高度隨著數(shù)據(jù)量增加而增加,IO代價高。
6. 講一講聚簇索引與非聚簇索引?
在 InnoDB 里,索引B+ Tree的葉子節(jié)點存儲了整行數(shù)據(jù)的是主鍵索引,也被稱之為聚簇索引,即將數(shù)據(jù)存儲與索引放到了一塊,找到索引也就找到了數(shù)據(jù)。
而索引B+ Tree的葉子節(jié)點存儲了主鍵的值的是非主鍵索引,也被稱之為非聚簇索引、二級索引。
聚簇索引與非聚簇索引的區(qū)別:
非聚集索引與聚集索引的區(qū)別在于非聚集索引的葉子節(jié)點不存儲表中的數(shù)據(jù),而是存儲該列對應(yīng)的主鍵(行號)
對于InnoDB來說,想要查找數(shù)據(jù)我們還需要根據(jù)主鍵再去聚集索引中進行查找,這個再根據(jù)聚集索引查找數(shù)據(jù)的過程,我們稱為回表。第一次索引一般是順序IO,回表的操作屬于隨機IO。需要回表的次數(shù)越多,即隨機IO次數(shù)越多,我們就越傾向于使用全表掃描 。
通常情況下, 主鍵索引(聚簇索引)查詢只會查一次,而非主鍵索引(非聚簇索引)需要回表查詢多次。當(dāng)然,如果是覆蓋索引的話,查一次即可
注意:MyISAM無論主鍵索引還是二級索引都是非聚簇索引,而InnoDB的主鍵索引是聚簇索引,二級索引是非聚簇索引。我們自己建的索引基本都是非聚簇索引。
7. 非聚簇索引一定會回表查詢嗎?
不一定,這涉及到查詢語句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再進行回表查詢。一個索引包含(覆蓋)所有需要查詢字段的值,被稱之為"覆蓋索引"。
舉個簡單的例子,假設(shè)我們在學(xué)生表的成績上建立了索引,那么當(dāng)進行select score from student where score > 90的查詢時,在索引的葉子節(jié)點上,已經(jīng)包含了score 信息,不會再次進行回表查詢。
8. 聯(lián)合索引是什么?為什么需要注意聯(lián)合索引中的順序?
MySQL可以使用多個字段同時建立一個索引,叫做聯(lián)合索引。在聯(lián)合索引中,如果想要命中索引,需要按照建立索引時的字段順序挨個使用,否則無法命中索引。
具體原因為:
MySQL使用索引時需要索引有序,假設(shè)現(xiàn)在建立了"name,age,school"的聯(lián)合索引,那么索引的排序為: 先按照name排序,如果name相同,則按照age排序,如果age的值也相等,則按照school進行排序。
當(dāng)進行查詢時,此時索引僅僅按照name嚴格有序,因此必須首先使用name字段進行等值查詢,之后對于匹配到的列而言,其按照age字段嚴格有序,此時可以使用age字段用做索引查找,以此類推。因此在建立聯(lián)合索引的時候應(yīng)該注意索引列的順序,一般情況下,將查詢需求頻繁或者字段選擇性高的列放在前面。此外可以根據(jù)特例的查詢或者表結(jié)構(gòu)進行單獨的調(diào)整。
9. 講一講MySQL的最左前綴原則?
最左前綴原則就是最左優(yōu)先,在創(chuàng)建多列索引時,要根據(jù)業(yè)務(wù)需求,where子句中使用最頻繁的一列放在最左邊。mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調(diào)整。
=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優(yōu)化器會幫你優(yōu)化成索引可以識別的形式。
10. 講一講前綴索引?
因為可能我們索引的字段非常長,這既占內(nèi)存空間,也不利于維護。所以我們就想,如果只把很長字段的前面的公共部分作為一個索引,就會產(chǎn)生超級加倍的效果。但是,我們需要注意,order by不支持前綴索引 。
流程是:
先計算完整列的選擇性 :select count(distinct col_1)/count(1) from table_1
再計算不同前綴長度的選擇性 :select count(distinct left(col_1,4))/count(1) from table_1
找到最優(yōu)長度之后,創(chuàng)建前綴索引 :create index idx_front on table_1 (col_1(4))
11. 了解索引下推嗎?
MySQL 5.6引入了索引下推優(yōu)化。默認開啟,使用SET optimizer_switch = ‘index_condition_pushdown=off’;可以將其關(guān)閉。
有了索引下推優(yōu)化,可以在減少回表次數(shù)
在InnoDB中只針對二級索引有效
官方文檔中給的例子和解釋如下:
在 people_table中有一個二級索引(zipcode,lastname,firstname),查詢是SELECT * FROM people WHERE zipcode=’95054′ AND lastname LIKE ‘%etrunia%’ AND address LIKE ‘%Main Street%’;
如果沒有使用索引下推技術(shù),則MySQL會通過zipcode=’95054’從存儲引擎中查詢對應(yīng)的數(shù)據(jù),返回到MySQL服務(wù)端,然后MySQL服務(wù)端基于lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’來判斷數(shù)據(jù)是否符合條件
如果使用了索引下推技術(shù),則MYSQL首先會返回符合zipcode=’95054’的索引,然后根據(jù)lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’來判斷索引是否符合條件。如果符合條件,則根據(jù)該索引來定位對應(yīng)的數(shù)據(jù),如果不符合,則直接reject掉。
12. 怎么查看MySQL語句有沒有用到索引?
通過explain,如以下例子:
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | filtered | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | titles | null | const | PRIMARY | PRIMARY | 59 | const,const,const | 10 | 1 |
id:在?個?的查詢語句中每個SELECT關(guān)鍵字都對應(yīng)?個唯?的id ,如explain select * from s1 where id = (select id from s1 where name = 'egon1');第一個select的id是1,第二個select的id是2。有時候會出現(xiàn)兩個select,但是id卻都是1,這是因為優(yōu)化器把子查詢變成了連接查詢 。
select_type:select關(guān)鍵字對應(yīng)的那個查詢的類型,如SIMPLE,PRIMARY,SUBQUERY,DEPENDENT,SNION 。
table:每個查詢對應(yīng)的表名 。
type:
type字段比較重要, 它提供了判斷查詢是否高效的重要依據(jù)依據(jù). 通過type字段, 我們判斷此次查詢是全表掃描還是索引掃描等。如const(主鍵索引或者唯一二級索引進行等值匹配的情況下),ref(普通的?級索引列與常量進?等值匹配),index(掃描全表索引的覆蓋索引) 。
通常來說, 不同的 type 類型的性能關(guān)系如下:ALL < index < range ~ index_merge < ref < eq_ref < const < systemALL 類型因為是全表掃描, 因此在相同的查詢條件下, 它是速度最慢的.
而 index 類型的查詢雖然不是全表掃描, 但是它掃描了所有的索引, 因此比 ALL 類型的稍快.
possible_key:查詢中可能用到的索引*(可以把用不到的刪掉,降低優(yōu)化器的優(yōu)化時間)* 。
key:此字段是 MySQL 在當(dāng)前查詢時所真正使用到的索引。
filtered:查詢器預(yù)測滿足下一次查詢條件的百分比 。
rows 也是一個重要的字段. MySQL 查詢優(yōu)化器根據(jù)統(tǒng)計信息, 估算 SQL 要查找到結(jié)果集需要掃描讀取的數(shù)據(jù)行數(shù). 這個值非常直觀顯示 SQL 的效率好壞, 原則上 rows 越少越好。
extra:表示額外信息,如Using where,Start temporary,End temporary,Using temporary等。
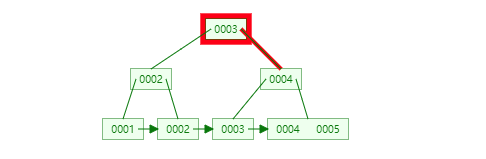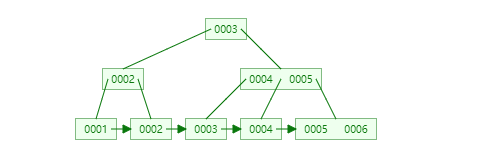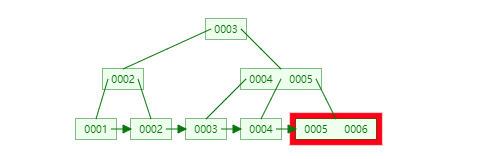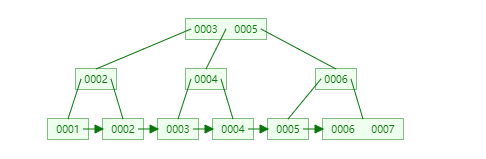
13. 為什么官方建議使用自增長主鍵作為索引?
結(jié)合B+Tree的特點,自增主鍵是連續(xù)的,在插入過程中盡量減少頁分裂,即使要進行頁分裂,也只會分裂很少一部分。并且能減少數(shù)據(jù)的移動,每次插入都是插入到最后。總之就是減少分裂和移動的頻率。
插入連續(xù)的數(shù)據(jù):
圖片來自:https://www.javazhiyin.com/40232.html
插入非連續(xù)的數(shù)據(jù):

14. 如何創(chuàng)建索引?
創(chuàng)建索引有三種方式。
1、 在執(zhí)行CREATE TABLE時創(chuàng)建索引
CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
2、 使用ALTER TABLE命令去增加索引。
ALTER TABLE table_name ADD INDEX index_name (column_list);
ALTER TABLE用來創(chuàng)建普通索引、UNIQUE索引或PRIMARY KEY索引。
其中table_name是要增加索引的表名,column_list指出對哪些列進行索引,多列時各列之間用逗號分隔。
索引名index_name可自己命名,缺省時,MySQL將根據(jù)第一個索引列賦一個名稱。另外,ALTER TABLE允許在單個語句中更改多個表,因此可以在同時創(chuàng)建多個索引。3、 使用CREATE INDEX命令創(chuàng)建。
CREATE INDEX index_name ON table_name (column_list);
15. 創(chuàng)建索引時需要注意什么?
非空字段:應(yīng)該指定列為NOT NULL,除非你想存儲NULL。在mysql中,含有空值的列很難進行查詢優(yōu)化,因為它們使得索引、索引的統(tǒng)計信息以及比較運算更加復(fù)雜。你應(yīng)該用0、一個特殊的值或者一個空串代替空值; 取值離散大的字段:(變量各個取值之間的差異程度)的列放到聯(lián)合索引的前面,可以通過count()函數(shù)查看字段的差異值,返回值越大說明字段的唯一值越多字段的離散程度高; 索引字段越小越好:數(shù)據(jù)庫的數(shù)據(jù)存儲以頁為單位一頁存儲的數(shù)據(jù)越多一次IO操作獲取的數(shù)據(jù)越大效率越高。
16. 建索引的原則有哪些?
1、最左前綴匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調(diào)整。
2、=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優(yōu)化器會幫你優(yōu)化成索引可以識別的形式。
3、盡量選擇區(qū)分度高的列作為索引,區(qū)分度的公式是count(distinct col)/count(*),表示字段不重復(fù)的比例,比例越大我們掃描的記錄數(shù)越少,唯一鍵的區(qū)分度是1,而一些狀態(tài)、性別字段可能在大數(shù)據(jù)面前區(qū)分度就是0,那可能有人會問,這個比例有什么經(jīng)驗值嗎?使用場景不同,這個值也很難確定,一般需要join的字段我們都要求是0.1以上,即平均1條掃描10條記錄。
4、索引列不能參與計算,保持列“干凈”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是數(shù)據(jù)表中的字段值,但進行檢索時,需要把所有元素都應(yīng)用函數(shù)才能比較,顯然成本太大。所以語句應(yīng)該寫成create_time = unix_timestamp(’2014-05-29’)。
5、盡量的擴展索引,不要新建索引。比如表中已經(jīng)有a的索引,現(xiàn)在要加(a,b)的索引,那么只需要修改原來的索引即可。
17. 使用索引查詢一定能提高查詢的性能嗎?
通常通過索引查詢數(shù)據(jù)比全表掃描要快。但是我們也必須注意到它的代價。
索引需要空間來存儲,也需要定期維護, 每當(dāng)有記錄在表中增減或索引列被修改時,索引本身也會被修改。這意味著每條記錄的I* NSERT,DELETE,UPDATE將為此多付出4,5 次的磁盤I/O。因為索引需要額外的存儲空間和處理,那些不必要的索引反而會使查詢反應(yīng)時間變慢。使用索引查詢不一定能提高查詢性能,索引范圍查詢(INDEX RANGE SCAN)適用于兩種情況:
基于一個范圍的檢索,一般查詢返回結(jié)果集小于表中記錄數(shù)的30%。 基于非唯一性索引的檢索。
18. 什么情況下不走索引(索引失效)?
1、使用!= 或者 <> 導(dǎo)致索引失效
2、類型不一致導(dǎo)致的索引失效
3、函數(shù)導(dǎo)致的索引失效
如:
SELECT * FROM `user` WHERE DATE(create_time) = '2020-09-03';
如果你的索引字段使用了索引,對不起,他是真的不走索引的。
4、運算符導(dǎo)致的索引失效
SELECT * FROM `user` WHERE age - 1 = 20;
如果你對列進行了(+,-,*,/,!), 那么都將不會走索引。
5、OR引起的索引失效
SELECT * FROM `user` WHERE `name` = '張三' OR height = '175';
OR導(dǎo)致索引是在特定情況下的,并不是所有的OR都是使索引失效,如果OR連接的是同一個字段,那么索引不會失效,反之索引失效。
6、模糊搜索導(dǎo)致的索引失效
SELECT * FROM `user` WHERE `name` LIKE '%冰';
當(dāng)%放在匹配字段前是不走索引的,放在后面才會走索引。
7、NOT IN、NOT EXISTS導(dǎo)致索引失效
End
整理不易,點個贊唄!小伙伴們,下期再見~
巨人的肩膀
https://blog.csdn.net/ThinkWon/article/details/104778621
https://www.javazhiyin.com/40232.html
https://juejin.cn/post/6844904039860142088
https://blog.csdn.net/ThinkWon/article/details/104778621
https://segmentfault.com/a/1190000008131735