
用python爬蟲 爬取梨視頻并下載!

引言
利用python爬蟲進行視頻下載,本次文章將對梨視頻網(wǎng)站的視頻進行爬取,由于爬蟲本身介于一個灰色與敏感的地帶,所以建議大家在使用爬蟲的時候先對網(wǎng)站的限制了解。在此之前作者已經(jīng)了解,可放心使用。
爬取流程分析
第一步:分析url
這次是對梨視頻網(wǎng)站的視頻進行爬取(https://www.pearvideo.com/)
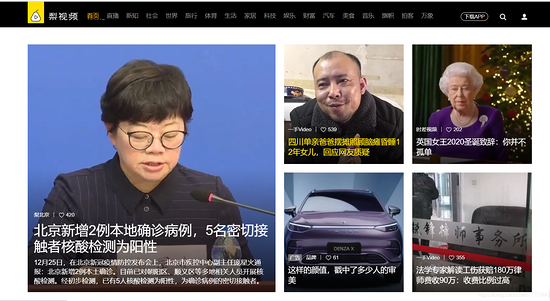
在此頁面下有許多小視頻,隨便點擊一個查看視頻網(wǎng)頁的url(https://www.pearvideo.com/video_1713546)

網(wǎng)站視頻具有時效性,依據(jù)網(wǎng)頁更新即可。在此頁面下按F12,查看網(wǎng)頁代碼,會發(fā)現(xiàn)找不到視頻的url。但點擊播放,視頻的url就彈出來了(https://video.pearvideo.com/mp4/adshort/20201226/cont-1713546-15547701_adpkg-ad_hd.mp4)自此url也就找出來了。
第二步:對url發(fā)起get請求
由于這里出現(xiàn)三個url,在這里三個url都有所用處,詳見代碼。
第三步:數(shù)據(jù)獲取
有兩個,一個是視頻的url獲取,另外一個是下載視頻的url獲取。
第四步:保存數(shù)據(jù)
在這里我們可以直接使用python文件操作的方式進行存儲,直接命名帶后綴MP4即可。
代碼實現(xiàn)
終于到了激動人心的時刻了。老實說,當晚爬出視頻的時候確實挺開心的,本人還是python爬蟲的初學者,實屬不易。
第一步:導入包
import requests
import re
from bs4 import BeautifulSoup
from selenium import webdriver
第二步:對url發(fā)起get請求
def get_url(url,i):
txt = requests.get(url).text
soup = BeautifulSoup(txt, 'lxml')
txt1 = soup.find_all('a')
con = re.findall(r', str(txt1))
url1 = url + con[i]
print(url1)
return url1
解釋一下,參數(shù)url是指視頻網(wǎng)站url,i是指第幾個視頻。而代碼的意思就是通過獲取視頻的代號編碼,然后與url進行拼接形成視頻url。之前分析url也能看出,視頻url與網(wǎng)站的url也就相差了video-xxxxx。
第三步:獲取視頻數(shù)據(jù)
def get_mp4(url1):
browser = webdriver.Chrome('chromedriver')
browser.get(url1)
button = browser.find_element_by_tag_name('i')
button.click()
soup = BeautifulSoup(browser.page_source, 'lxml')
sp1 = soup.find_all('video')
mp4_url = re.findall(r'',
str(sp1))
mp4 = requests.get(mp4_url[0])
return mp4.content
由于在之前查看開發(fā)者工具時,發(fā)現(xiàn)需要點擊播放才可以顯示下載視頻的url,所以使用模擬瀏覽器的方法。當然如果你有更好的方法可以留言給我,非常感謝。自此視頻數(shù)據(jù)已獲取完畢。
保存視頻
url1 = get_url(url,1)
with open('second.mp4', 'wb') as f:
mp4 = get_mp4(url1)
f.write(mp4)
在這里文件的格式可以看到是使用了‘wb’的方法進行存儲。運行快慢視網(wǎng)速快慢而定。
結(jié)果

掃下方二維碼加老師微信
或是搜索老師微信號:XTUOL1988【切記備注:學習Python】
領取Python web開發(fā),Python爬蟲,Python數(shù)據(jù)分析,人工智能等學習教程。帶你從零基礎系統(tǒng)性的學好Python!
也可以加老師建的Python技術學習教程qq裙:245345507,二者加一個就可以!

歡迎大家點贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
萬水千山總是情,點個【在看】行不行
*聲明:本文于網(wǎng)絡整理,版權(quán)歸原作者所有,如來源信息有誤或侵犯權(quán)益,請聯(lián)系我們刪除或授權(quán)事宜