
分布式訓(xùn)練 | Pytorch的主流做法詳解

來源 | 九點(diǎn)澡堂子
編輯 | 極市平臺(tái)
極市導(dǎo)讀
前段時(shí)間工作涉及到修改分布式訓(xùn)練代碼,在自研的工具庫里直接調(diào)用簡單的幾行代碼就可以,很多復(fù)雜的東西都封裝起來了,但總感覺還是盡可能多了解下背后的東西比較好,原理和Pytorch的類似,就直接以torch來分析記錄了。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
Pytorch 分布式訓(xùn)練主要有兩種方式:
torch.nn.DataParallel ==> 簡稱 DP
torch.nn.parallel.DistributedDataParallel ==> 簡稱DDP
本文結(jié)合源碼了解下Pytorch的這兩個(gè)方法,本文主要記錄DP和DDP的使用方式。
DP 只用于單機(jī)多卡,DDP 可以用于單機(jī)多卡也可用于多機(jī)多卡,后者現(xiàn)在是Pytorch分布式訓(xùn)練的主流用法。
DP寫法比較簡單,但即使在單機(jī)多卡情況下也比 DDP 慢。具體可參考:
https://pytorch.org/docs/stable/nn.html#dataparallel-layers-multi-gpu-distributed 。
DP
在DP中,只有一個(gè)主進(jìn)程完成整體操作,大致用法:
import torchimport torch.nn as nn
# 1. 構(gòu)造模型
net = model(imput_size, output_size)
# 2. 模型、數(shù)據(jù)放在GPU上
net = net.cuda()
inputs, labels = inputs.cuda(), labels.cuda()
# 3. 調(diào)用DP
net=nn.DataParallel(net)
# 4. 前向計(jì)算
result = net(inputs)
# 5. 其他和正常模型訓(xùn)練無差別
關(guān)于DataParallel的使用, 摘取主要源碼:
class DataParallel(Module):
def __init__(self, module, device_ids=None, output_device=None, dim=0):
super(DataParallel, self).__init__()
# 如果沒有GPU可用,直接返回
if not torch.cuda.is_available():
self.module = module
self.device_ids = []
return
# 如果有GPU,但沒有指定的話,device_ids為所有可用GPU
if device_ids is None:
device_ids = list(range(torch.cuda.device_count()))
# 默認(rèn)輸出在0號(hào)卡上
if output_device is None:
output_device = device_ids[0]
由代碼可知,如果不設(shè)定好要使用的device_ids的話, 程序會(huì)自動(dòng)找到這個(gè)機(jī)器上面可以用的所有的顯卡用于訓(xùn)練。
如果想要限制使用的顯卡數(shù),怎么辦呢?
那就在代碼最前面使用:
# 限制代碼能看到的GPU個(gè)數(shù),這里表示指定只使用實(shí)際的0號(hào)和5號(hào)卡
# 注意:這里的賦值必須是字符串,list會(huì)報(bào)錯(cuò)
os.environ['CUDA_VISIBLE_DEVICES'] == '0,5'
# 這時(shí)候device_count = 2
device_ids = range(torch.cuda.device_count())
# device_ids = [0,1] 這里的0就是上述指定的'0'號(hào)卡,1對應(yīng)'5'號(hào)卡。
net = nn.DataParallel(net,device_ids)
# !!!模型和數(shù)據(jù)都由主gpu(0號(hào)卡)分發(fā)。
值得注意的是,在使用
os.environ['CUDA_VISIBLE_DEVICES']
對可以使用的顯卡進(jìn)行限定之后, 顯卡的實(shí)際編號(hào)和程序看到的編號(hào)應(yīng)該是不一樣的。
例如上面我們設(shè)定的是:
os.environ['CUDA_VISIBLE_DEVICES']='0,5'
但是程序看到的顯卡編號(hào)應(yīng)該被改成了'0,1'。
也就是說程序所使用的顯卡編號(hào)實(shí)際上是經(jīng)過了一次映射之后才會(huì)映射到真正的顯卡編號(hào)上面的, 例如這里的程序看到的'1'對應(yīng)實(shí)際的'5'。
但是Dataparallel會(huì)帶來顯存的使用不平衡,具體分析見參考鏈接[2],而且碰到大的任務(wù),時(shí)間和能力上都很受限。
DDP
為了彌補(bǔ)Dataparallel的不足,有了torch.nn.parallel.DistributedDataParallel,這也是現(xiàn)在Pytorch分布式訓(xùn)練主推的。
DDP支持單機(jī)多卡和多機(jī)多卡,和DP只有一個(gè)主進(jìn)程不一樣,DDP每張卡都有一個(gè)進(jìn)程,這就涉及到進(jìn)程通信,多進(jìn)程通信初始化,是使用DDP最繁瑣的地方。
主要涉及下面這個(gè)方法:
#詳見:https://pytorch.org/docs/stable/distributed.html
torch.distributed.init_process_group( )
常用參數(shù):
backend: 后端, 實(shí)際上是多個(gè)機(jī)器之間交換數(shù)據(jù)的協(xié)議,官方和很多用戶都強(qiáng)烈推薦'nccl'作為backend。但是nccl的接口只有5個(gè),如果有其他訴求nccl比較受限,mpi也可考慮。 init_method: 機(jī)器之間交換數(shù)據(jù)需要指定一個(gè)主節(jié)點(diǎn), 這個(gè)參數(shù)用來指定主節(jié)點(diǎn)的。 world_size: 參與job的進(jìn)程數(shù), 實(shí)際就是GPU的個(gè)數(shù); rank: 進(jìn)程組中每個(gè)進(jìn)程的唯一標(biāo)識(shí)符。比如一個(gè)節(jié)點(diǎn)8張卡,world_size為8,每張卡的rank是對應(yīng)的0-7的連續(xù)整數(shù)。 順便解釋下local_rank: 假設(shè)有兩個(gè)節(jié)點(diǎn)/機(jī)器,每個(gè)節(jié)點(diǎn)有8張卡,總共16張卡,對應(yīng)16個(gè)進(jìn)程。global_rank是指0-15,對于節(jié)點(diǎn)1,local_rank為0-7,對于節(jié)點(diǎn)2,local_rank也是0-7。
初始化init_method的方法有兩種:
使用TCP進(jìn)行初始化; 使用共享文件系統(tǒng)進(jìn)行初始化。
Pytorch作者推薦TCP,說是最簡單的方式:
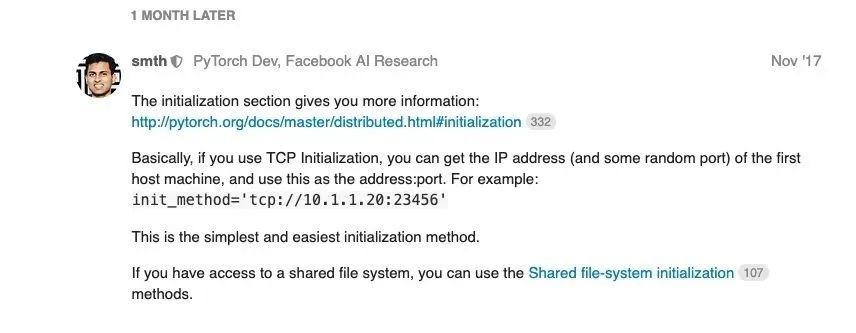
我們平常在集群上操作,可以通過os.environ獲取每個(gè)進(jìn)程的節(jié)點(diǎn)ip信息,全局rank以及l(fā)ocal rank。
關(guān)于獲取節(jié)點(diǎn)信息的詳細(xì)代碼:
import os
# 可用作world size
os.environ['SLURM_NTASKS']
# node id
os.environ['SLURM_NODEID']
# 可用作全局rank
os.environ['SLURM_PROCID']
# local_rank
os.environ['SLURM_LOCALID']
#從中取得一個(gè)ip作為通訊ip
os.environ['SLURM_NODELIST']
因此,torch中DDP的使用如下方式:
import os
import re
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.nn.parallel
import DistributedDataParallel as DDP
#1. 獲取環(huán)境信息
rank = int(os.environ['SLURM_PROCID'])
world_size = int(os.environ['SLURM_NTASKS'])
local_rank = int(os.environ['SLURM_LOCALID'])
node_list = str(os.environ['SLURM_NODELIST'])
#2. 對ip進(jìn)行操作
node_parts = re.findall('[0-9]+', node_list)
host_ip = '{}.{}.{}.{}'.format(node_parts[1], node_parts[2], node_parts[3], node_parts[4])
#3. 設(shè)置端口號(hào),注意端口一定要沒有被使用
port = "23456"
#4. 使用TCP初始化方法
init_method = 'tcp://{}:{}'.format(host_ip, port)
#5. 多進(jìn)程初始化通信環(huán)境
dist.init_process_group("nccl", init_method=init_method,
world_size=world_size, rank=rank)
#6. 指定當(dāng)前device
# 作用類似于os.environ['CUDA_VISIBLE_DEVICES']
# 官方推薦用CUDA_VISIBLE_DEVICES
# https://pytorch.org/docs/stable/cuda.html
torch.cuda.set_device(local_rank)
#7. 模型數(shù)據(jù)放到GPU上
model = model.cuda()
input = input.cuda()
#8. 指定模型所在local_rank
model = DDP(model, device_ids=[local_rank])
#9.前向計(jì)算
output = model(input)
#10. 此后訓(xùn)練流程與普通模型無異
最近官方表述中加了一個(gè)store參數(shù),更新了下使用方法,大差不差。具體參考:
https://pytorch.org/docs/stable/distributed.html
使用TCP進(jìn)行初始化,需要讀取ip,我們在集群上通過os.environ可以很方便完成初始化。平常在集群提交任務(wù)的srun指令這樣寫:
# 單機(jī)多卡# 8個(gè)任務(wù)對應(yīng)8個(gè)進(jìn)程,每個(gè)節(jié)點(diǎn)上跑8個(gè)任務(wù)
srun -n8 --gres=gpu:8 --ntasks-per-node=8 python train.py
#多機(jī)多卡
#16個(gè)任務(wù)對應(yīng)16個(gè)進(jìn)程,每個(gè)節(jié)點(diǎn)最多跑8個(gè)任務(wù)/進(jìn)程,每張卡占滿8個(gè)GPU
#因此這里是申請了16/8=2個(gè)節(jié)點(diǎn),即在兩個(gè)機(jī)器上跑。
srun -n16 --gres=gpu:8 --ntasks-per-node=8 python train.py
參考鏈接
[1]https://blog.csdn.net/weixin_40087578/article/details/87186613
[2]https://zhuanlan.zhihu.com/p/86441879
[3]https://zhuanlan.zhihu.com/p/68717029
如果覺得有用,就請分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“CVPR21檢測”獲取CVPR2021目標(biāo)檢測論文下載~

# CV技術(shù)社群邀請函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
