
?我當(dāng)面試官,面你 MySQL 原理


言歸正傳,之前MySQL基礎(chǔ)篇的知識(shí)點(diǎn),小伙伴們有熟練掌握嗎?沒(méi)有的話(huà)趕緊來(lái)復(fù)習(xí)一下~????
覺(jué)得已經(jīng)沒(méi)有問(wèn)題,我們就一起來(lái)進(jìn)行第二部分的學(xué)習(xí)吧——MySQL原理篇。
ACID與隔離級(jí)別

那你先來(lái)說(shuō)說(shuō)MySQL的四種隔離級(jí)別吧。


SQL標(biāo)準(zhǔn)定義了4類(lèi)隔離級(jí)別,包括一些具體規(guī)則,用來(lái)限定事務(wù)之間的隔離性。


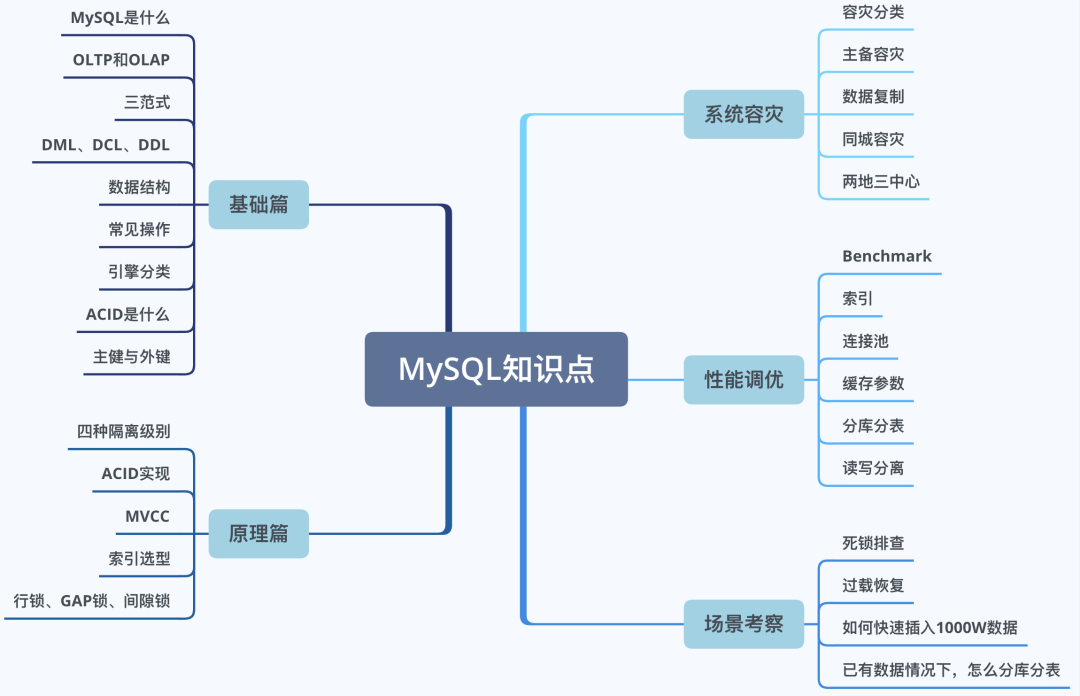
這四種級(jí)別分別是讀未提交、讀已提交、可重復(fù)讀、串型化。

讀未提交,顧名思義,就是可以讀到還沒(méi)有提交的數(shù)據(jù);讀已提交會(huì)讀到其它事務(wù)已經(jīng)提交的數(shù)據(jù);可重復(fù)讀確保了同一事務(wù)中,讀取同一條數(shù)據(jù)時(shí),會(huì)看到同樣的數(shù)據(jù)行;串型化通過(guò)強(qiáng)制事務(wù)排序,使其不可能相互沖突。

重點(diǎn)介紹下Repeatable Read吧。

Repeatable Read就是可重復(fù)讀。它確保了在同一事務(wù)中,讀取同一條數(shù)據(jù)時(shí),會(huì)看到同樣的數(shù)據(jù)行。
它也是MyQL的默認(rèn)事務(wù)隔離級(jí)別,這種級(jí)別事務(wù)之間影響很小,通常已經(jīng)能夠滿(mǎn)足日常需要了。
下面我們來(lái)聊聊InnoDB中ACID的實(shí)現(xiàn)吧,先說(shuō)一下原子性是怎么實(shí)現(xiàn)的。
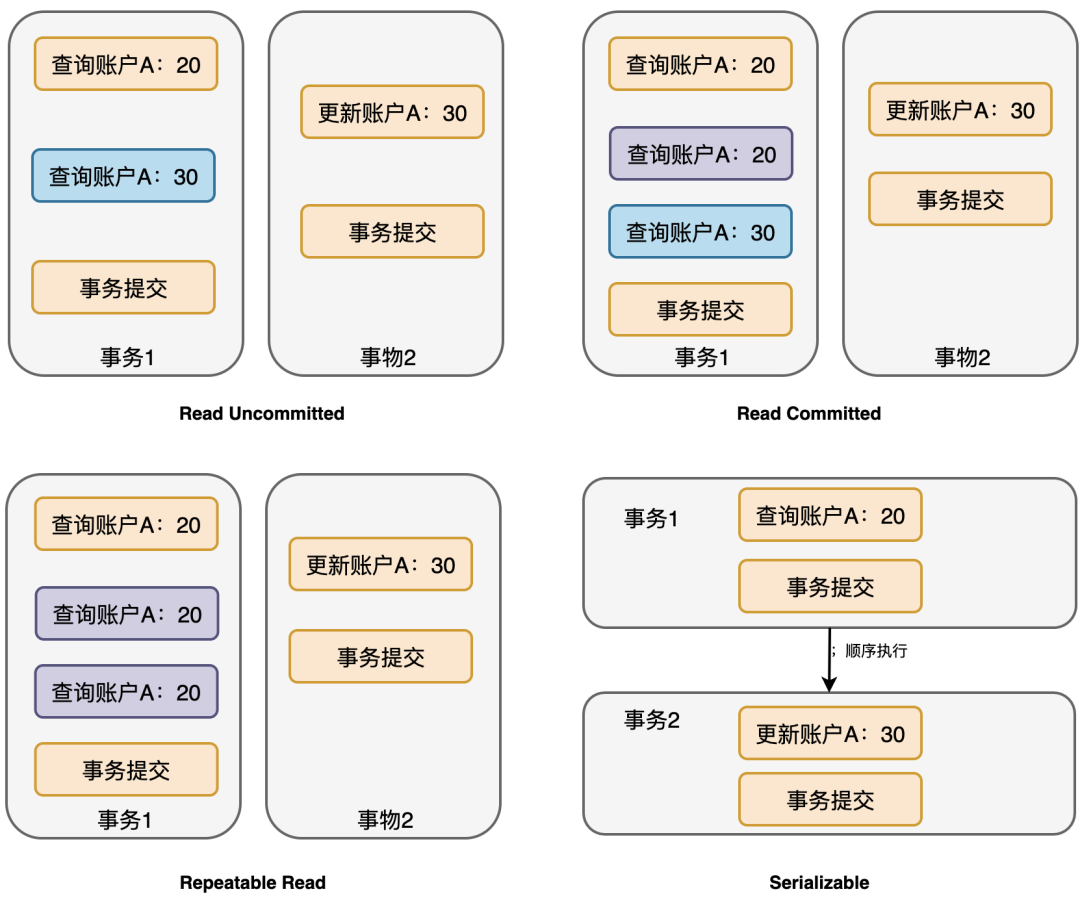
事務(wù)要么失敗,要么成功,不能做一半。聰明的InnoDB,在干活兒之前,先將要做的事情記錄到一個(gè)叫undo log的日志文件中,如果失敗了或者主動(dòng)rollback,就可以通過(guò)undo log的內(nèi)容,將事務(wù)回滾。
那undo log里面具體記錄了什么信息呢?
undo log屬于邏輯日志,它記錄的是sql執(zhí)行相關(guān)的信息。當(dāng)發(fā)生回滾時(shí),InnoDB會(huì)根據(jù)undo log的內(nèi)容做與之前相反的工作,使數(shù)據(jù)回到之前的狀態(tài)。。。
那持久性又是怎么實(shí)現(xiàn)的?
持久性是用來(lái)保證一旦給客戶(hù)返回成功,數(shù)據(jù)就不會(huì)消失,持久存在。最簡(jiǎn)單的做法,是每次寫(xiě)完磁盤(pán)落地之后,再給客戶(hù)返回成功。但如果每次讀寫(xiě)數(shù)據(jù)都需要磁盤(pán)IO,效率就會(huì)很低。
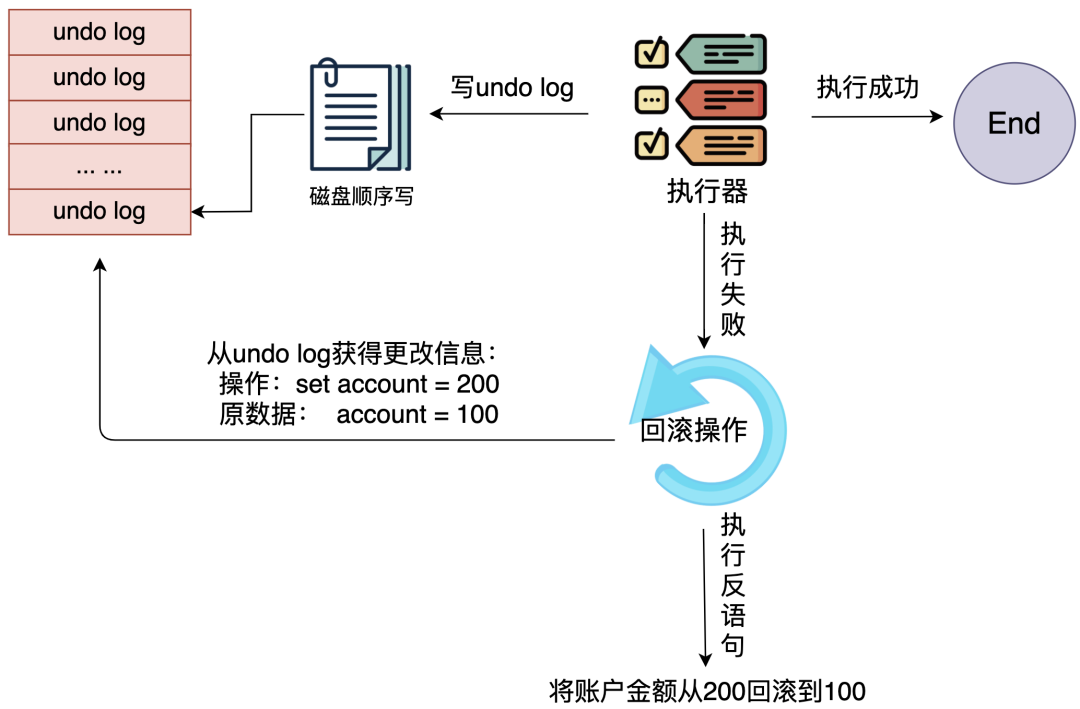
為此,追求極致的InnoDB提供了緩沖。當(dāng)向數(shù)據(jù)庫(kù)寫(xiě)入數(shù)據(jù)時(shí),會(huì)首先寫(xiě)入緩沖池,緩沖池中修改的數(shù)據(jù)會(huì)定期刷新到磁盤(pán)中,這一過(guò)程稱(chēng)為刷臟。
如果MySQL宕機(jī),那此時(shí)Buffer Pool中修改的數(shù)據(jù)不是丟失了嗎?
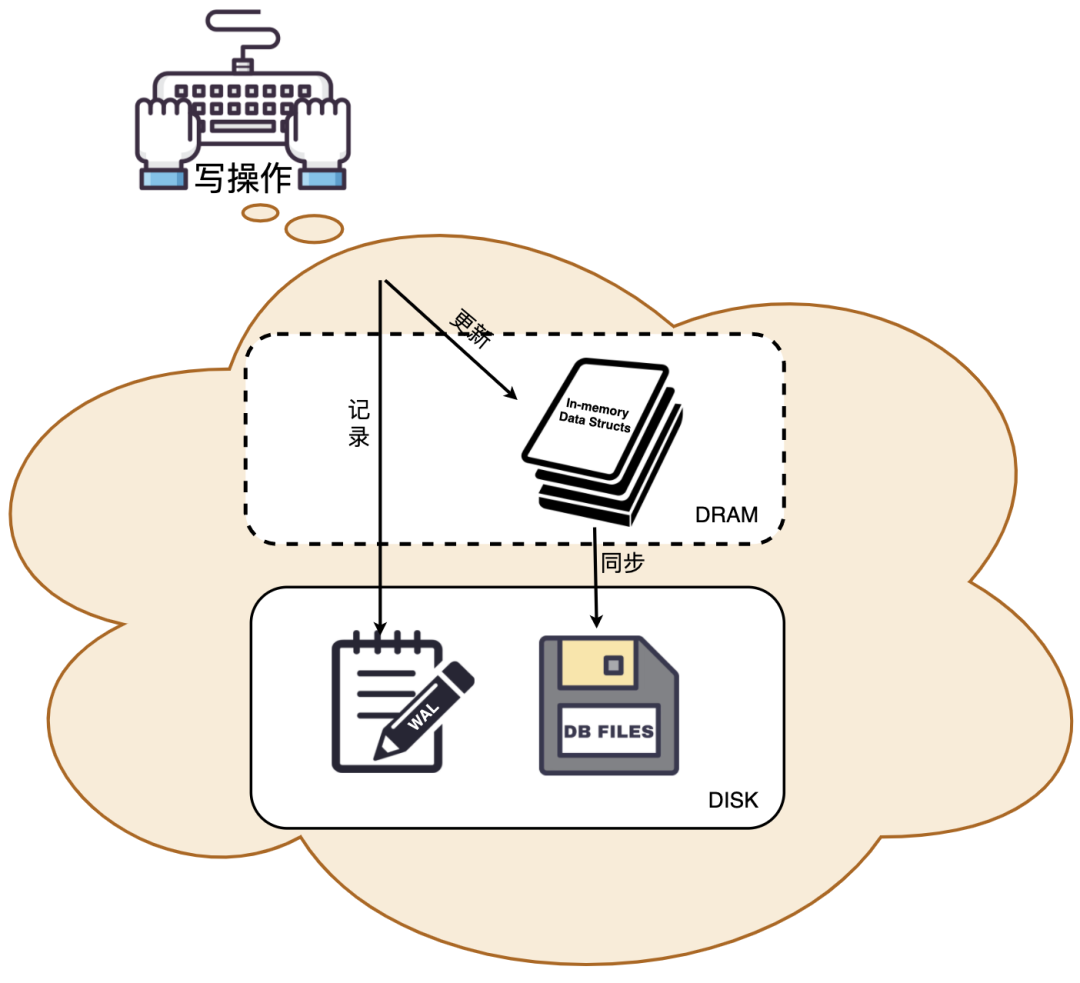
Innodb引入了redo log來(lái)解決這個(gè)問(wèn)題。當(dāng)數(shù)據(jù)修改時(shí),會(huì)先在redo log記錄這次操作,然后再修改緩沖池中的數(shù)據(jù),當(dāng)事務(wù)提交時(shí),會(huì)調(diào)用fsync接口對(duì)redo log進(jìn)行刷盤(pán)。
如果MySQL宕機(jī),重啟時(shí)可以讀取redo log中的數(shù)據(jù),對(duì)數(shù)據(jù)庫(kù)進(jìn)行恢復(fù)。由于redo log是WAL日志,也就是預(yù)寫(xiě)式日志,所有修改先寫(xiě)入日志,所以保證了數(shù)據(jù)不會(huì)因MySQL宕機(jī)而丟失,從而滿(mǎn)足了持久性要求。
按你所說(shuō),redo log 也需要寫(xiě)磁盤(pán),為什么不直接將數(shù)據(jù)寫(xiě)磁盤(pán)呢?
1.對(duì)Buffer Pool進(jìn)行刷臟是隨機(jī)IO,因?yàn)槊看涡薷牡臄?shù)據(jù)位置隨機(jī),但寫(xiě)redo log是追加操作,屬于順序IO;
2.刷臟是以數(shù)據(jù)頁(yè)為單位,MySQL默認(rèn)頁(yè)大小是16KB,一個(gè)Page上一個(gè)小修改都要整頁(yè)寫(xiě)入,所以積累一些數(shù)據(jù)一并寫(xiě)入會(huì)大大提升性能;而redo log中只包含真正需要寫(xiě)入的部分,無(wú)效IO比較少。
那隔離性怎么實(shí)現(xiàn)呢?
我先說(shuō)鎖吧。事務(wù)在讀取某數(shù)據(jù)的瞬間,必須先對(duì)其加行級(jí)共享鎖,直到事務(wù)結(jié)束才釋放;事務(wù)在更新某數(shù)據(jù)的瞬間,必須先對(duì)其加行級(jí)排他鎖,直到事務(wù)結(jié)束才釋放;
為了防止幻讀,還會(huì)有間隙鎖進(jìn)行區(qū)間排它鎖定。
然后是MVCC,多版本并發(fā)控制,主要是為了實(shí)現(xiàn)可重復(fù)讀,雖然鎖也可以,但是為了更高性能考慮,使用了這種多版本快照的方式。
因?yàn)槭强煺眨砸粋€(gè)事務(wù)針對(duì)同一條Sql查詢(xún)語(yǔ)句的結(jié)果,不會(huì)受其它事務(wù)影響。
索引原理

索引的底層實(shí)現(xiàn)是什么?


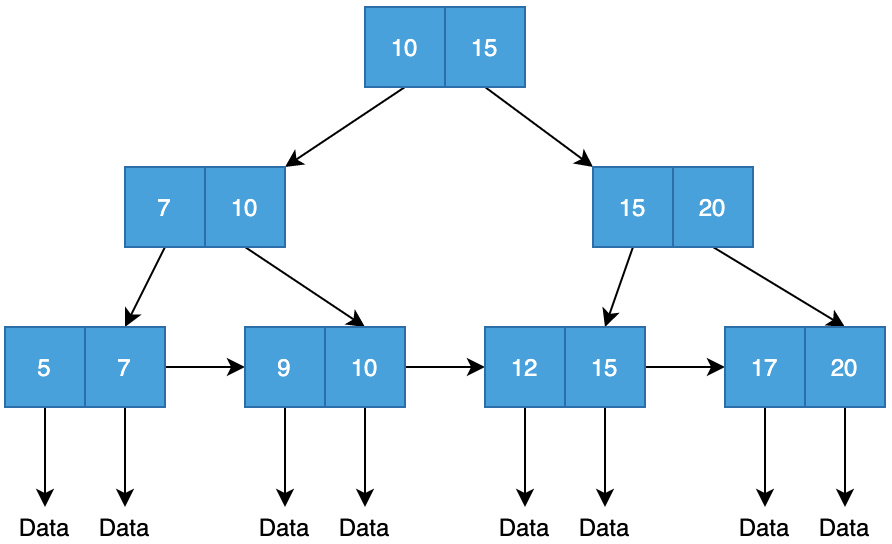
用的B+樹(shù),它是一個(gè)N叉排序樹(shù),每個(gè)節(jié)點(diǎn)通常有多個(gè)子節(jié)點(diǎn)。節(jié)點(diǎn)種類(lèi)有普通節(jié)點(diǎn)和葉子節(jié)點(diǎn)。根節(jié)點(diǎn)可能是一個(gè)葉子節(jié)點(diǎn), 也可能是個(gè)普通節(jié)點(diǎn)。

B+樹(shù)
那MySQL為什么用樹(shù)做索引?
一般而言,能做索引的,要么Hash,要么樹(shù),要么就是比較特殊的跳表。Hash不支持范圍查詢(xún),跳表不適合這種磁盤(pán)場(chǎng)景,而樹(shù)支持范圍查詢(xún),且多種多樣,很多樹(shù)適合磁盤(pán)存儲(chǔ)。所以MySQL選擇了樹(shù)來(lái)做索引。
那你能說(shuō)說(shuō)為什么是B+樹(shù),而不是平衡二叉樹(shù)、紅黑樹(shù)或者B-樹(shù)嗎?
平衡二叉樹(shù)追求絕對(duì)平衡,條件比較苛刻,實(shí)現(xiàn)起來(lái)比較麻煩,每次插入新節(jié)點(diǎn)之后需要旋轉(zhuǎn)的次數(shù)不能預(yù)知。
同時(shí),B+樹(shù)優(yōu)勢(shì)在于每個(gè)節(jié)點(diǎn)能存儲(chǔ)多個(gè)信息,這樣深度比平衡二叉樹(shù)會(huì)淺很多,減少數(shù)據(jù)查找的次數(shù)。
平衡二叉樹(shù)
紅黑樹(shù)放棄了追求完全平衡,只追求大致平衡,在與平衡二叉樹(shù)的時(shí)間復(fù)雜度相差不大的情況下,保證每次插入最多只需要三次旋轉(zhuǎn)就能達(dá)到平衡,實(shí)現(xiàn)起來(lái)也更為簡(jiǎn)單。
但是紅黑樹(shù)多用于內(nèi)部排序,即全放在內(nèi)存中,而B(niǎo)+樹(shù)多用于外存上時(shí),B+也被稱(chēng)為一個(gè)磁盤(pán)友好的數(shù)據(jù)結(jié)構(gòu)。
同時(shí),紅黑樹(shù)和平衡二叉樹(shù)有相同缺點(diǎn),即每個(gè)節(jié)點(diǎn)存儲(chǔ)一個(gè)關(guān)鍵詞,數(shù)據(jù)量大時(shí),導(dǎo)致它們的深度很深,MySQL每次讀取時(shí)都會(huì)消耗大量IO。
那B+樹(shù)相比B-樹(shù)有什么優(yōu)點(diǎn)呢?
哈哈,我覺(jué)得這就屬于同門(mén)師兄較勁兒了。B+樹(shù)非葉子節(jié)點(diǎn)只存儲(chǔ)key值,而B(niǎo)-樹(shù)存儲(chǔ)key值和data值,這樣B+樹(shù)的層級(jí)更少,查詢(xún)效率更高;
MySQL進(jìn)行區(qū)間訪問(wèn)時(shí),由于B+樹(shù)葉子節(jié)點(diǎn)之間用指針相連,只需要遍歷所有的葉子節(jié)點(diǎn)即可,而B(niǎo)-樹(shù)則需要中序遍歷一遍。

接下來(lái)講講聚簇索引和二級(jí)索引吧。
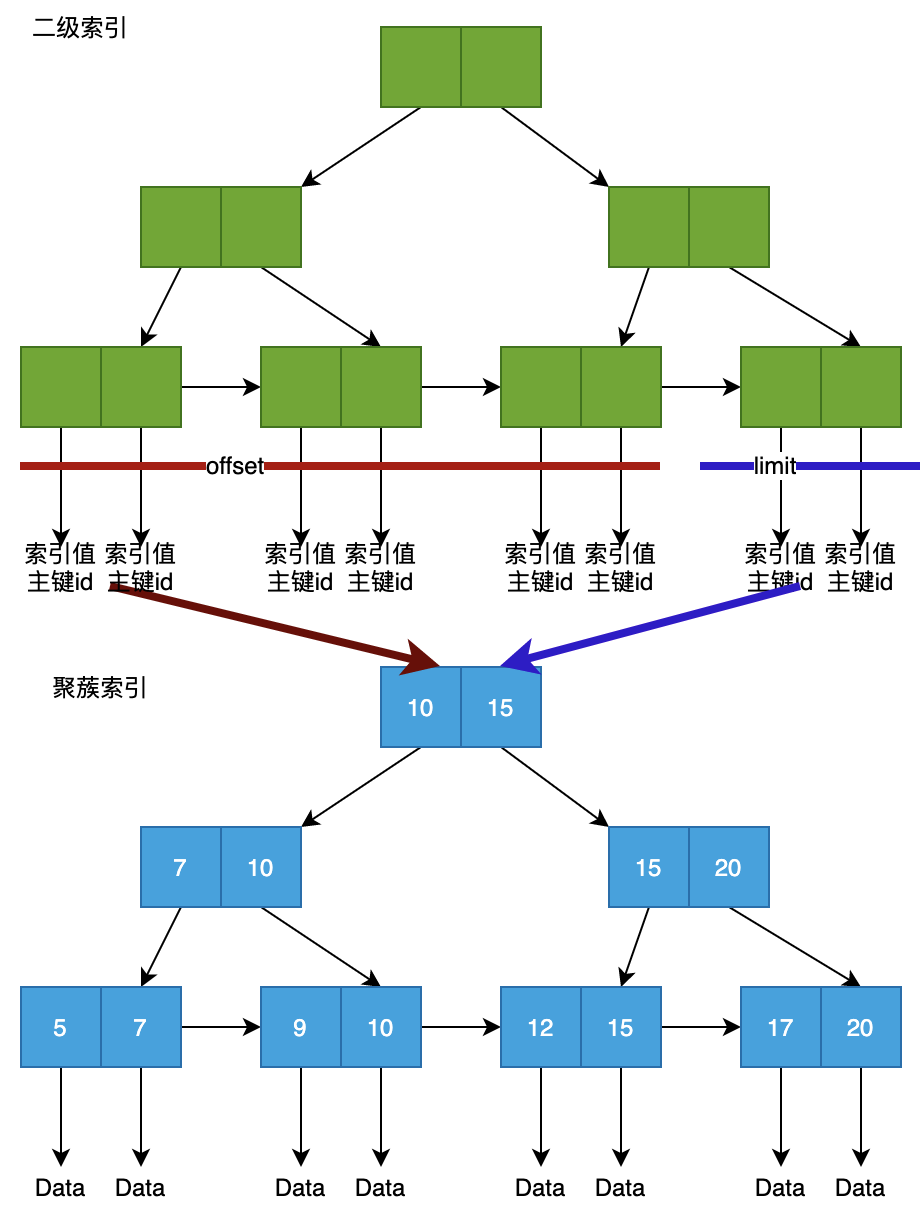
聚簇索引是主鍵上的索引,二級(jí)索引是非主鍵字段的索引。這兩者相同點(diǎn)是都是基于B+樹(shù)實(shí)現(xiàn)。
區(qū)別在于,二級(jí)索引的葉子結(jié)點(diǎn)只存儲(chǔ)索引本身內(nèi)容,以及主鍵ID,聚簇索引的葉子結(jié)點(diǎn),會(huì)存儲(chǔ)完整的行數(shù)據(jù)。在一定程度上,可以說(shuō)二級(jí)索引就是主鍵索引的索引。
鎖

下面講講MySQL鎖的分類(lèi)吧。


MySQL從鎖粒度粒度上講,有表級(jí)鎖、行級(jí)鎖。從強(qiáng)度上講,又分為意向共享鎖、共享鎖、意向排它鎖和排它鎖。


那select操作會(huì)加鎖嗎?
對(duì)于普通select語(yǔ)句,InnoDB 不會(huì)加任何鎖。但是select語(yǔ)句,也可以顯示指定加鎖。有兩種模式,一種是LOCK IN SHARE MODE是加共享鎖,還有Select ... for updates是加排它鎖。
什么情況下會(huì)發(fā)生死鎖?
嗯。。。比如事務(wù)A鎖住了資源1,然后去申請(qǐng)資源2,但事務(wù)B已經(jīng)占據(jù)了資源2,需要資源1,誰(shuí)都不退讓?zhuān)退梨i了。對(duì)于MySQL,最常見(jiàn)的情況,就是資源1、資源2分別對(duì)應(yīng)一個(gè)排它鎖。
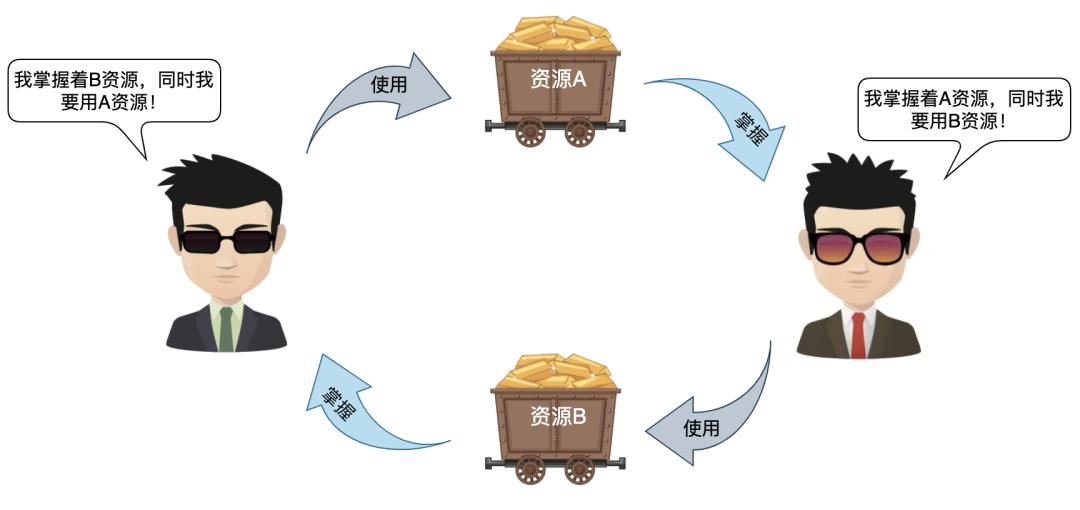
那間隙鎖你有了解么?
間隙鎖就是對(duì)索引行進(jìn)行加鎖操作,不僅鎖住其本身,還會(huì)鎖住周?chē)徑姆秶鷧^(qū)間。間隙鎖的目的是為了解決幻影讀,但也因此帶來(lái)了更大的死鎖隱患。
比如,一個(gè)任務(wù)表里面有個(gè)狀態(tài)字段,是一個(gè)非唯一索引,有一個(gè)任務(wù)id,是唯一索引。
一個(gè)sql將狀態(tài)處于執(zhí)行中的任務(wù)設(shè)置為等待中,另一個(gè)sql正好通過(guò)任務(wù)id更新在范圍內(nèi)的一條任務(wù)信息。那么因?yàn)槭窃诓煌饕渔i的,所以都能成功。但是最后去更新主鍵數(shù)據(jù)的時(shí)候,就會(huì)死鎖。