
用隱馬爾科夫模型來(lái)預(yù)測(cè)股價(jià)走勢(shì)

一、初識(shí)HMM
隱馬爾科夫模型(Hidden Markov Model,簡(jiǎn)稱(chēng)HMM)是用來(lái)描述隱含未知參數(shù)的統(tǒng)計(jì)模型,HMM已經(jīng)被成功于語(yǔ)音識(shí)別、文本分類(lèi)、生物信息科學(xué)、故障診斷和壽命預(yù)測(cè)等領(lǐng)域。
HMM可以由三個(gè)要素組成: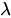 ?=(A,B,II),其中A為狀態(tài)轉(zhuǎn)移概率矩陣,B為觀測(cè)狀態(tài)概率矩陣,II為隱藏狀態(tài)初始概率分布。
?=(A,B,II),其中A為狀態(tài)轉(zhuǎn)移概率矩陣,B為觀測(cè)狀態(tài)概率矩陣,II為隱藏狀態(tài)初始概率分布。
HMM有兩個(gè)基本假設(shè),一是齊次馬爾可夫性假設(shè),隱馬爾可夫鏈t的狀態(tài)只和t-1狀態(tài)有關(guān);二是觀測(cè)獨(dú)立性假設(shè),觀測(cè)只和當(dāng)前時(shí)刻狀態(tài)有關(guān)。
HMM解決的三個(gè)問(wèn)題:
一是概率計(jì)算問(wèn)題,已知模型和觀測(cè)序列,計(jì)算觀測(cè)序列出現(xiàn)的概率,該問(wèn)題求解的方法為向前向后法;
二是學(xué)習(xí)問(wèn)題,已知觀測(cè)序列,估計(jì)模型的參數(shù),該問(wèn)題求解的方法為鮑姆-韋爾奇算法
三是預(yù)測(cè)問(wèn)題(解碼問(wèn)題),已知模型和觀測(cè)序列,求解狀態(tài)序列,該問(wèn)題求解的方法為動(dòng)態(tài)規(guī)劃的維特比算法。
HMM的實(shí)現(xiàn):python的hmmlearn類(lèi),按照觀測(cè)狀態(tài)是連續(xù)狀態(tài)還是離散狀態(tài),可以分為兩類(lèi)。GaussianHMM和GMMHMM是連續(xù)觀測(cè)狀態(tài)的HMM模型;MultinomialHMM是離散觀測(cè)狀態(tài)的模型。
二、實(shí)例分析
(1)問(wèn)題描述:股票預(yù)測(cè)問(wèn)題,觀測(cè)值為股票的漲幅值(當(dāng)天收盤(pán)價(jià)-前一天收盤(pán)價(jià))和成交量2種,隱藏狀態(tài)假定為平、跌和漲3種,根據(jù)股票的歷史數(shù)據(jù)構(gòu)建HMM,并進(jìn)一步預(yù)測(cè)股票的收盤(pán)價(jià)。
(2)數(shù)據(jù)預(yù)處理:從原始數(shù)據(jù)中提取有用的列,并做異常值處理操作,得到模型的數(shù)據(jù)數(shù)據(jù),原始數(shù)據(jù)為某支股票2013-2019的記錄數(shù)據(jù),如下圖所示。

import?datetime
import?numpy?as?np
import?pandas?as?pd
from?matplotlib?import?cm,?pyplot?as?plt
from?hmmlearn.hmm?import?GaussianHMM
#數(shù)據(jù)處理
df?=?pd.read_excel("601668.SH.xlsx",?header=0)
print("原始數(shù)據(jù)的大小:",?df.shape)
print("原始數(shù)據(jù)的列名",?df.columns)
df['日期']?=?pd.to_datetime(df['日期'])
df.reset_index(inplace=True,?drop=False)
df.drop(['index','交易日期','開(kāi)盤(pán)價(jià)','最高價(jià)','最低價(jià)'?,'市值',?'換手率',?'pe',?'pb'],?axis=1,?inplace=True)
df['日期']?=?df['日期'].apply(datetime.datetime.toordinal)
print(df.head())
dates?=?df['日期'][1:]
close_v?=?df['收盤(pán)價(jià)']
volume?=?df['成交量'][1:]
diff?=?np.diff(close_v)
#獲得輸入數(shù)據(jù)
X?=?np.column_stack([diff,?volume])
print("輸入數(shù)據(jù)的大小:",?X.shape)???#(1504,?2)
(3)異常值的處理:
min?=?X.mean(axis=0)[0]?-?8*X.std(axis=0)[0]???#最小值
max?=?X.mean(axis=0)[0]?+?8*X.std(axis=0)[0]??#最大值
X?=?pd.DataFrame(X)
#異常值設(shè)為均值
for?i?in?range(len(X)):??#dataframe的遍歷
????if?(X.loc[i,?0]0]?>?max):
????????????X.loc[i,?0]?=?X.mean(axis=0)[0]
(4)模型的構(gòu)建:
#數(shù)據(jù)集的劃分
X_Test?=?X.iloc[:-30]
X_Pre?=?X.iloc[-30:]
print("訓(xùn)練集的大小:",?X_Test.shape)?????#(1474,?2)
print("測(cè)試集的大小:",?X_Pre.shape)??????#(30,?2)
#模型的搭建
model?=?GaussianHMM(n_components=3,?covariance_type='diag',?n_iter=1000)?
model.fit(X_Test)
print("隱藏狀態(tài)的個(gè)數(shù)",?model.n_components)??#
print("均值矩陣")
print(model.means_)
print("協(xié)方差矩陣")
print(model.covars_)
print("狀態(tài)轉(zhuǎn)移矩陣--A")
print(model.transmat_)
均值矩陣:共三行,每一行代表一種隱藏層狀態(tài)(狀態(tài)0、1、2),每一行的兩個(gè)元素分別代表漲幅值的均值和成交量的均值。由于該股票的變化不是特別大,因此結(jié)果不是特別明顯,但可以觀察到狀態(tài)0均值為負(fù)值,可以解釋為“跌”;狀態(tài)1均值最小,接近0,可以解釋為“平”,狀態(tài)2均值為正,可以解釋為“漲”。

協(xié)方差矩陣:共三個(gè)協(xié)方差矩陣,分別對(duì)應(yīng)三種隱藏層狀態(tài)。對(duì)角線(xiàn)的值為該狀態(tài)下的方差,方差越大,代表該狀態(tài)的預(yù)測(cè)不可信。狀態(tài)0的方差約為0.00255,方差最小,預(yù)測(cè)非常可信;狀態(tài)1的方差約為0.0157,可信度居中;狀態(tài)2的方差為0.1232,方差最大,最不可信。
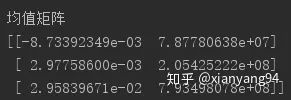
狀態(tài)轉(zhuǎn)移矩陣:代表三個(gè)隱藏層狀態(tài)的轉(zhuǎn)移概率。可以看出對(duì)角線(xiàn)的數(shù)值較大,即狀態(tài)0、1、2都傾向保持當(dāng)前的狀態(tài),意味該股票較穩(wěn)。
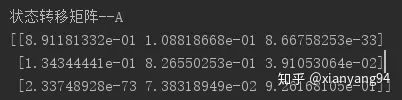
(5)隱藏狀態(tài)劃分結(jié)果:
#訓(xùn)練數(shù)據(jù)的隱藏狀態(tài)劃分
X_pic?=?np.column_stack([dates[:-30],?hidden_states,?X_Test])
for?i?in?range(len(X_pic)):
????if?X_pic[i,?1]?==?0:
????????plt.plot_date(x=X_pic[i,?0],y=X_pic[i,2],color='r')
????elif?X_pic[i,?1]?==?1:
????????plt.plot_date(x=X_pic[i,?0],y=X_pic[i,2],color='purple')
????else:plt.plot_date(x=X_pic[i,?0],y=X_pic[i,2],color?='y')
plt.show()
(6)預(yù)測(cè)值計(jì)算:
將預(yù)測(cè)數(shù)據(jù)的第一組作為初始數(shù)據(jù),預(yù)測(cè)下一時(shí)段的股票漲幅值,以此類(lèi)推預(yù)測(cè)該股票后三十組的價(jià)格。
expected_returns_volumes?=?np.dot(model.transmat_,?model.means_)
expected_returns?=?expected_returns_volumes[:,0]????????
predicted_price?=?[]??#預(yù)測(cè)值
current_price?=?close_v.iloc[-30]
for?i?in?range(len(X_Pre)):
????hidden_states?=?model.predict(X_Pre.iloc[i].values.reshape(1,2))??#將預(yù)測(cè)的第一組作為初始值
????predicted_price.append(current_price+expected_returns[hidden_states])
????current_price?=?predicted_price[i]
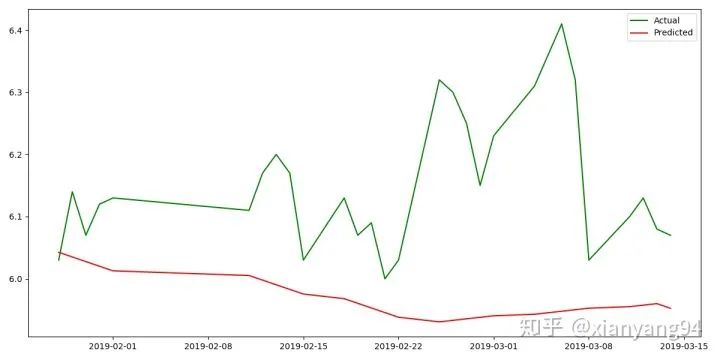
(7)預(yù)測(cè)結(jié)果展示:
x?=?dates[-29:?]
y_act?=?close_v[-29:]
y_pre?=?pd.Series(predicted_price[:-1])
plt.figure(figsize=(8,6))
plt.plot_date(x,?y_act,linestyle="-",marker="None",color='g')
plt.plot_date(x,?y_pre,linestyle="-",marker="None",color='r')
plt.legend(['Actual',?'Predicted'])
plt.show()
三、小結(jié)
可以看出,該預(yù)測(cè)結(jié)果的趨勢(shì)與真實(shí)值一致,但預(yù)測(cè)結(jié)果不佳。可以通過(guò)增加訓(xùn)練的數(shù)據(jù)量,并進(jìn)行模型參數(shù)調(diào)優(yōu)來(lái)提高預(yù)測(cè)的精度。HMM應(yīng)用場(chǎng)景:研究問(wèn)題是基于序列的,比如時(shí)間序列或狀態(tài)序列;存在兩種狀態(tài)的意義,一種是觀測(cè)序列,一種是隱藏狀態(tài)序列。相比于RNN、LSTM等神經(jīng)網(wǎng)絡(luò)序列模型,HMM進(jìn)行預(yù)測(cè)的效果可能較劣,總之股市有風(fēng)險(xiǎn),投資需謹(jǐn)慎。
參考資料:hmmlearn官方文檔
https://hmmlearn.readthedocs.io/en/latest/
本文由作者:xianyang94,zhihu.com/p/166552799 投稿
長(zhǎng)按掃碼添加Python小助手進(jìn)入?
Python 中 文 社 區(qū) 俱 樂(lè) 部 微 信 群
▼點(diǎn)擊成為社區(qū)會(huì)員? ?喜歡就點(diǎn)個(gè)在看吧